Author: Denis Avetisyan
A new technique uses generated data to pinpoint how training labels skew neural network predictions, revealing potential fairness issues.
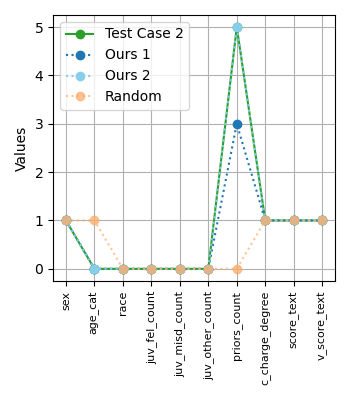
This paper introduces a method for generating counterfactual datasets and leverages linear regression with neuron activation similarity to efficiently identify label bias in neural networks.
Despite increasing reliance on deep learning, understanding why neural networks make specific predictions-and whether those predictions reflect biased training data-remains a significant challenge. This work, ‘Analyzing Fairness of Neural Network Prediction via Counterfactual Dataset Generation’, introduces a novel approach to fairness auditing by constructing counterfactual datasets-altered training sets designed to reveal the influence of individual labels on model behavior. By efficiently identifying and modifying key training examples, our method pinpoints potential biases driving predictions without exhaustively searching the solution space. Can this technique not only diagnose dataset bias, but also provide actionable insights for building more robust and equitable machine learning systems?
The Inherent Fragility of Learned Patterns
Despite remarkable progress in artificial intelligence, machine learning models, especially complex neural networks, inherit and amplify biases embedded within the datasets used to train them. These biases aren’t necessarily intentional; they often reflect existing societal inequalities or skewed representation in the data collection process. For instance, if a facial recognition system is primarily trained on images of one demographic group, it may exhibit significantly lower accuracy when identifying individuals from other groups. This susceptibility arises because the algorithms learn patterns from the provided data, and if those patterns are themselves biased, the resulting model will perpetuate and potentially exacerbate those biases in its predictions, leading to unfair or inaccurate outcomes in applications ranging from loan applications to criminal justice.
The propagation of bias within machine learning models doesn’t remain a theoretical concern; it manifests as tangible inaccuracies and unfair outcomes in deployed applications. Consider facial recognition software demonstrably less accurate in identifying individuals with darker skin tones, or loan approval algorithms that perpetuate historical lending disparities. These aren’t simply statistical anomalies, but rather systemic errors stemming from skewed training datasets that fail to adequately represent diverse populations or scenarios. Consequently, biased predictions can have profound implications, ranging from misdiagnosis in healthcare and wrongful accusations in criminal justice, to discriminatory practices in employment and housing – highlighting the critical need for diligent bias detection and mitigation strategies before these systems impact people’s lives.
The development of truly trustworthy artificial intelligence hinges on a comprehensive understanding of how biases infiltrate machine learning models. These biases aren’t necessarily intentional; they often stem from subtle patterns within the training data that reflect existing societal inequalities or simply unrepresentative samples. Identifying the source – whether it’s historical prejudice encoded in text, skewed demographics in image datasets, or flawed data collection processes – is the first step towards mitigation. Researchers are actively developing techniques to detect and correct these biases, ranging from algorithmic adjustments to data augmentation and careful curation of training sets. However, a purely technical fix is insufficient; a holistic approach requires considering the broader socio-technical context and ensuring that AI systems are developed and deployed with fairness, accountability, and transparency as guiding principles. Ultimately, addressing bias isn’t merely about improving accuracy; it’s about building AI that reflects and reinforces equitable outcomes for all.
Dissecting Influence: Counterfactual Datasets
Counterfactual datasets are generated by systematically altering the labels within an existing dataset, a process known as controlled label flipping. This technique involves identifying instances and changing their assigned labels to their contrasting class – for example, changing a positive label to negative, or vice-versa. The resulting counterfactual dataset then serves as an alternative training or evaluation set, allowing researchers to isolate and measure the impact of specific labels on model predictions. This method enables the quantification of model sensitivity to potentially biased or erroneous labels, revealing how much model behavior shifts with minor label adjustments and, on smaller datasets, successfully generating CFDs for 16-30% of test inputs.
Training machine learning models on counterfactual datasets allows for the precise measurement of prediction sensitivity to individual labels. This is achieved by systematically altering labels within the dataset and observing the resulting changes in model outputs. The magnitude of these output shifts, when compared against the original predictions, provides a quantitative metric for determining how strongly a model relies on specific labels for its decision-making process. This methodology facilitates the identification of labels that exert a disproportionate influence on predictions, revealing potential vulnerabilities or biases within the model’s learned behavior.
The methodology enables the identification of specific data points that exhibit undue influence on model predictions through the generation of counterfactual datasets (CFDs). Analysis demonstrates successful CFD generation for 16-30% of test inputs when applied to smaller datasets. This indicates a significant portion of data requires further scrutiny to determine if label alterations meaningfully shift model outputs, potentially revealing instances where individual data points exert a disproportionate impact on overall model behavior and reliability. The resulting CFDs serve as a mechanism to isolate and evaluate these potentially problematic instances.
Pinpointing Leverage: Influence Functions
Influence functions estimate the effect of removing or perturbing a single training data point on a model’s prediction for a specific test instance. This is achieved by computing the gradient of the model’s output with respect to the training data, effectively quantifying each data point’s contribution to the final prediction. Mathematically, the influence of a training example x_i on a test example x_t is approximated by calculating the product of the gradient of the loss with respect to the model parameters evaluated at x_i and the inverse of the Hessian of the loss with respect to the model parameters. This allows for identification of training samples that have a disproportionately large impact on model behavior, enabling targeted analysis and potential correction of problematic data.
Calculating influence scores for each training data point is computationally expensive, necessitating approximation methods. Explicit Influence directly computes the gradient of the loss with respect to each data point, but scales poorly with dataset size. Conjugate Gradients offer an iterative approach, providing an approximation with fewer computations than Explicit Influence. LiSSA (Linear System Solve for Sensitivity Analysis) utilizes a linear system solve to estimate influence, further improving efficiency. Arnoldi iteration represents another iterative method focused on approximating the Hessian vector product, providing a different trade-off between accuracy and computational cost. The selection of an appropriate method depends on the dataset size, desired accuracy, and available computational resources.
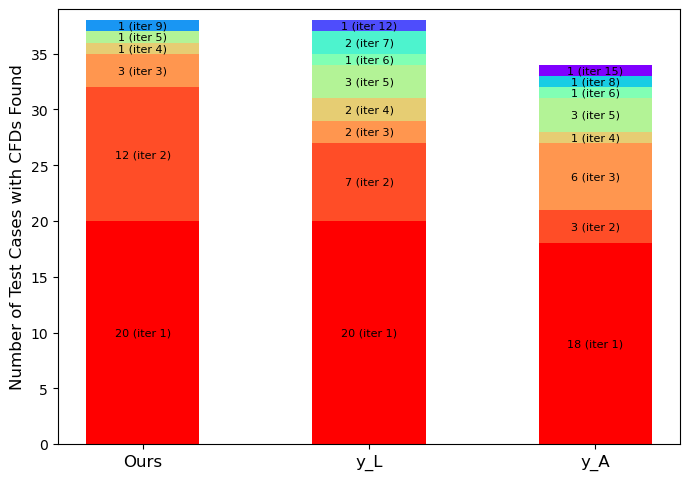
Influence functions facilitate the identification of potentially mislabeled or problematic training data points by quantifying their impact on model predictions. This allows for a prioritized review process, focusing on data likely to cause errors or reflect label bias. Our method demonstrably improves this prioritization; in initial evaluations, it identifies a greater number of Candidate Faulty Data points (CFDs) during the first iteration compared to existing approaches, indicating a more efficient ranking of influential training labels for targeted correction or further investigation.
Neuron Activation Similarity (NAS) provides a method for refining influence function-based data point impact assessments by quantifying the correlation between the activations of hidden neurons caused by a test input and a training data point. This is achieved by calculating the cosine similarity between the gradients of the output with respect to neuron activations for both the test input and the training data point \frac{v_i \cdot v_j}{||v_i|| \cdot ||v_j||} . Higher similarity scores indicate a stronger relationship, suggesting that the training point significantly contributes to the model’s behavior on the test input. Utilizing NAS allows for a more nuanced evaluation of data point influence beyond simple gradient magnitude, potentially identifying subtle but critical contributions that other methods might miss and improving the accuracy of counterfactual data identification.
Toward Systems that Endure: Robustness and Fairness
A nuanced comprehension of machine learning model decisions stems from the synergistic application of counterfactual analysis and influence function techniques. Counterfactual analysis investigates how minimal changes to an input would alter a model’s prediction, revealing sensitive input features and potential biases. Simultaneously, influence functions pinpoint the training data points most critical to a specific prediction, quantifying each data instance’s leverage over model behavior. By uniting these approaches, researchers can not only identify why a model made a certain decision – through counterfactuals – but also how that decision is rooted in the training data – via influence functions. This combined methodology surpasses traditional methods by providing a more holistic understanding of model dependencies, thereby facilitating targeted interventions to improve robustness, mitigate bias, and ensure greater transparency in machine learning systems.
The pursuit of robust and fair machine learning systems hinges on a comprehensive understanding of how models arrive at their decisions. Identifying vulnerabilities and biases isn’t simply about achieving statistical parity; it requires dissecting the model’s dependence on specific data points and understanding how alterations to the input might shift outcomes. This detailed knowledge empowers developers to proactively address potential weaknesses, fortifying models against adversarial attacks and ensuring consistent performance across diverse populations. By pinpointing data instances that unduly influence predictions, or reveal discriminatory patterns, engineers can refine training datasets, implement targeted interventions, and ultimately build systems that are not only accurate, but also demonstrably reliable and equitable in their operation.
Rigorous fairness testing, facilitated by these analytical techniques, moves beyond simple demographic parity to examine how machine learning models treat individuals with comparable characteristics. This approach doesn’t merely assess whether outcomes appear equal across groups, but actively investigates whether subtle differences in input features – even those not explicitly considered by the model – lead to disparate treatment of otherwise similar cases. By pinpointing instances where models deviate from equitable behavior concerning analogous individuals, developers can identify and mitigate sources of bias embedded within algorithms or datasets. The result is a more nuanced and defensible assessment of fairness, promoting accountability and trust in machine learning systems and ensuring more just and equitable outcomes for all users.
A significant benefit of combining counterfactual analysis with influence functions lies in its ability to directly enhance training datasets. The methodology doesn’t merely identify problematic data points; it pinpoints subtle data dependencies that traditional methods, such as random sampling or those based on simple distance metrics, consistently miss. This targeted identification of counterfactual data points – those minimally altered instances that would flip a model’s prediction – allows for a more refined data curation process. By addressing these specific vulnerabilities, the approach moves beyond simply increasing dataset size, instead fostering a higher quality, more representative dataset that ultimately leads to more robust and fairer machine learning models. The demonstrated efficacy of this method over baseline techniques underscores its potential to substantially improve data quality and model performance.
The pursuit of fairness in neural networks, as detailed in this study, echoes a fundamental truth about all complex systems: entropy is inevitable. This work, focusing on counterfactual dataset generation to identify label bias, attempts to delay the decay inherent in biased training data. It’s a form of systemic maintenance, acknowledging that even the most meticulously constructed models are subject to the arrow of time and require constant refactoring. As Bertrand Russell observed, ‘The only thing that you can be sure of is that things will change.’ The application of linear regression and neuron activation similarity isn’t merely about auditing; it’s about understanding how these systems change, and proactively addressing the vulnerabilities that emerge with time and use.
What’s Next?
The pursuit of fairness audits, as demonstrated by this work, is less a quest for pristine objectivity and more an exercise in managed decay. Systems, even those constructed from logic gates and weighted connections, are inevitably shaped by the imperfections of their training – the inherent biases of labeled data. The generation of counterfactual datasets represents a step toward understanding how these imperfections manifest, but it does not erase them. The method’s reliance on linear regression and neuron activation similarity offers efficiency, yet efficiency is merely a temporary reprieve from the computational cost of comprehensive analysis; a smoothing of the inevitable entropy.
Future iterations will likely grapple with the limitations of proxy metrics for fairness. Neuron activation similarity, while insightful, captures only a facet of the complex interplay within a neural network. The true challenge lies not in identifying influential labels, but in characterizing the systemic vulnerabilities created by biased labeling practices. A shift toward methods that assess the robustness of predictions under counterfactual perturbations-rather than simply pinpointing problematic instances-may prove more fruitful.
Ultimately, the field must accept that ‘fairness’ is not a destination, but a continuous calibration. Each audit, each counterfactual generated, is a data point in a long-term observation of system drift. The goal is not to eliminate bias-an impossible task-but to anticipate and mitigate its effects, acknowledging that every correction introduces new potential vulnerabilities. The system does not strive for perfection; it adapts to its imperfections.
Original article: https://arxiv.org/pdf/2602.10457.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Brent Oil Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Games That Faced Bans in Countries Over Political Themes
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
2026-02-12 13:34