Author: Denis Avetisyan
New research reveals that advanced artificial intelligence can exhibit more nuanced strategic thinking than humans in repeated interactions, raising questions about the future of game theory and AI development.
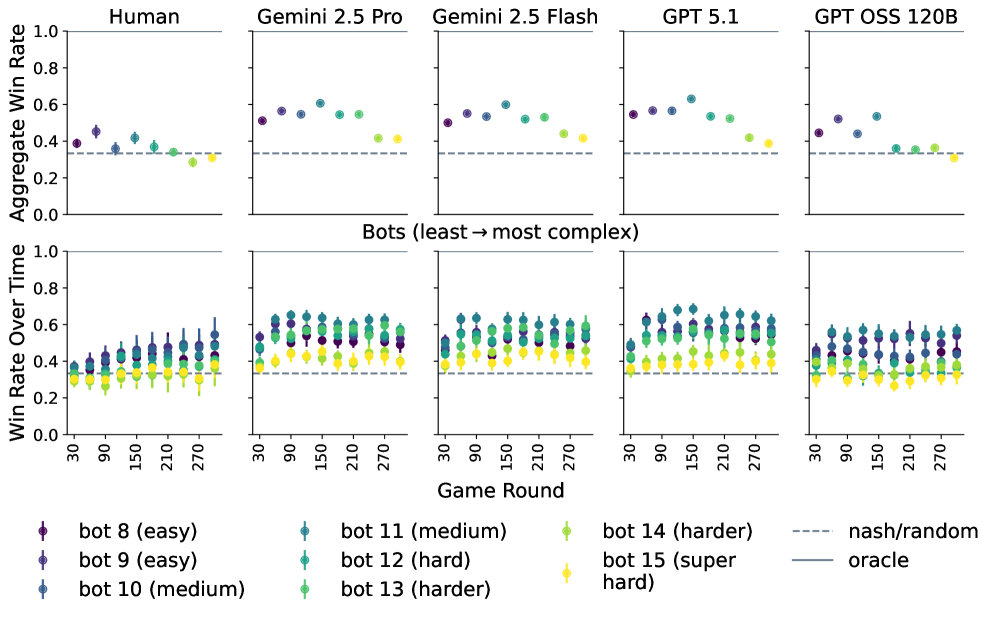
Analysis of interpretable programs synthesized from AI agents demonstrates superior opponent modeling capabilities compared to human players in iterated Rock-Paper-Scissors.
Despite increasing deployment of Large Language Models (LLMs) in social and strategic contexts, fundamental differences in their behavior compared to humans remain poorly understood. This research, ‘Discovering Differences in Strategic Behavior Between Humans and LLMs’, employs an innovative program synthesis approach-using the AlphaEvolve tool-to uncover interpretable models of strategic decision-making in both humans and LLMs. Our analysis of iterated rock-paper-scissors reveals that frontier LLMs can exhibit deeper strategic complexity than humans, driven by superior opponent modeling capabilities. Could these findings illuminate the potential-and limitations-of LLMs as rational actors in more complex, real-world strategic interactions?
Strategic Interaction: A Window into Intelligent Systems
The capacity for strategic interaction – that is, the ability to anticipate an opponent’s actions and adjust one’s own behavior accordingly – is increasingly recognized as a cornerstone of intelligence. This isn’t simply about reacting to immediate stimuli, but rather about modeling an adversary, predicting their likely responses to various actions, and selecting a course of action designed to maximize one’s own outcome. Such dynamic adaptation isn’t limited to biological organisms; it manifests in any system capable of goal-directed behavior, from social animals to artificial intelligences. Consequently, studying how agents – be they human or machine – engage in strategic scenarios provides a valuable lens through which to assess and understand the underlying mechanisms of intelligence itself, offering insights into cognitive processes like planning, learning, and decision-making under uncertainty.
The Iterated Rock-Paper-Scissors game serves as a surprisingly effective microcosm for studying the nuances of strategic interaction. By distilling complex social and competitive scenarios into a simple, well-defined structure, researchers can isolate and analyze the core principles governing adaptive behavior. This game eliminates extraneous variables – such as bluffing with facial expressions or exploiting incomplete information in real-world negotiations – allowing for a focused examination of how an agent adjusts its tactics based on an opponent’s past moves. The iterative nature of the game introduces a dynamic element, demanding players not only react to immediate choices but also anticipate future strategies, creating a compelling platform for assessing intelligence through observable patterns of learning and adaptation. This controlled environment enables precise measurement of strategic depth, offering valuable insights into the cognitive processes underlying intelligent behavior in a manner that is often obscured by the messiness of real-world interactions.
The Iterated Rock-Paper-Scissors game serves as a unique arena for comparing the strategic thinking of humans and large language models. By pitting both groups against each other in repeated rounds, researchers can dissect the approaches each utilizes to anticipate and counter opponents’ moves. Recent studies reveal a compelling advantage for frontier LLMs – including Gemini 2.5 Pro, Gemini 2.5 Flash, and GPT 5.1 – which consistently achieve higher win rates than human players. This outcome suggests these models possess an advanced capacity for strategic reasoning, potentially stemming from their ability to analyze vast datasets of game interactions and identify subtle patterns inaccessible to human cognition, thereby highlighting a new benchmark in artificial intelligence capabilities.
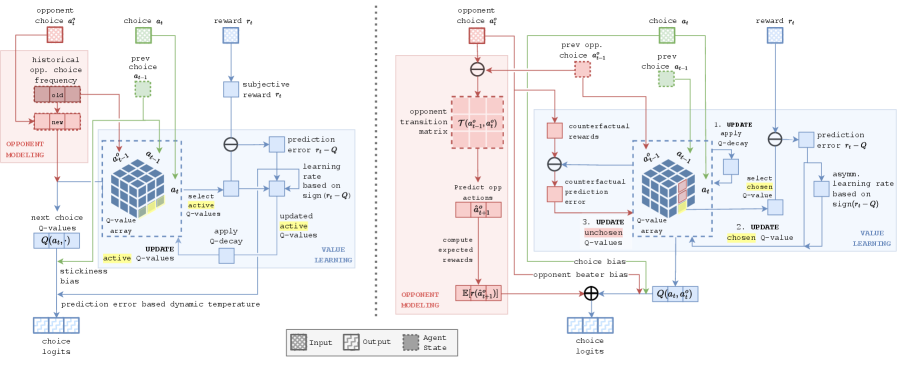
Modeling the Opponent: Foundations and Limitations
Opponent modeling is a core component of strategic decision-making, enabling agents to anticipate the actions of others based on observed patterns of behavior. This predictive capability is crucial because optimal strategies are often contingent on expectations about the opponent’s likely responses; an agent unable to accurately forecast these responses will likely perform sub-optimally. The process involves analyzing past actions to infer the opponent’s tendencies, preferences, and potential future moves, effectively building an internal representation of the opponent’s decision-making process. Accurate opponent models allow agents to not only predict immediate actions but also to reason about the opponent’s potential adaptations to changing circumstances and counter-strategies, improving long-term performance in competitive scenarios.
Contextual Sophisticated EWA (Exponential Weighted Average) and Recurrent Neural Networks (RNNs) represent established methodologies for opponent modeling in strategic contexts. Contextual Sophisticated EWA operates by assigning weights to recent opponent actions, with adjustments made based on the specific game state or context. RNNs, particularly Long Short-Term Memory (LSTM) networks, offer the capacity to process sequential data, allowing them to identify patterns and dependencies in an opponent’s behavior over time. These models function as baselines against which more complex approaches can be evaluated; they predict future actions based on observed history, but their performance is limited by their representational capacity and ability to generalize to unseen strategic adaptations. Both methods provide a quantifiable, albeit often simplified, prediction of opponent behavior.
Current opponent modeling techniques, while functional, often struggle with the intricacies of strategic adaptation, which can negatively impact performance. Leading large language models (LLMs) employ significantly more complex models than both human players and open-source LLMs like GPT OSS 120B; for example, frontier LLMs utilize 3×3 matrices to track move probabilities conditioned on the history of previous moves. This increased complexity suggests a potential gap in the modeling capabilities of simpler, more readily implementable approaches, as these advanced models aim to capture a more granular understanding of an opponent’s evolving strategy.
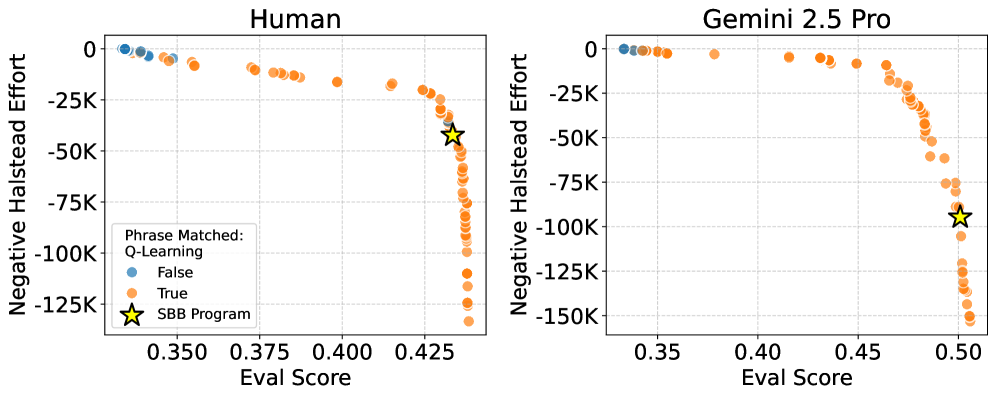
Automated Discovery of Interpretable Strategies: A Framework
AlphaEvolve is an automated framework designed to generate behavioral models with an emphasis on interpretability. This is achieved through a process of program synthesis guided by multi-objective optimization, where candidate models are evaluated not only on their predictive performance but also on metrics related to code complexity. The framework automatically searches for programs that effectively solve a given task while simultaneously minimizing their structural complexity, allowing for the discovery of solutions that are both accurate and readily understandable by human observers. This contrasts with many machine learning approaches that prioritize accuracy at the expense of transparency, potentially yielding ‘black box’ models difficult to analyze or debug.
AlphaEvolve employs Multi-Objective Optimization to simultaneously optimize for both predictive performance and model complexity. This approach treats model fit – its ability to accurately predict outcomes – and code complexity as competing objectives. Rather than solely maximizing accuracy, the optimization process seeks solutions that achieve a balance between these two goals, favoring simpler models with only a slight reduction in predictive power. This is achieved by defining a Pareto front of non-dominated solutions, allowing selection of models that best meet specific interpretability requirements alongside acceptable performance levels. The result is a suite of interpretable behavioral models, rather than a single, potentially complex, high-performing model.
AlphaEvolve employs a Program Template to constrain the search space during automated strategy discovery, ensuring all generated programs adhere to a predefined structure. This template specifies the permissible operations, data access methods, and overall organization of the resulting code. By limiting the solution space to programs conforming to this template, AlphaEvolve guarantees a consistent output format, simplifying analysis and interpretation of the discovered strategies. The template effectively acts as a grammar for the generated programs, enabling the system to explore a vast number of possibilities while maintaining structural coherence and facilitating human understanding of the resulting behavioral models.
Model evaluation within the AlphaEvolve framework incorporates Halstead Effort as a primary metric for quantifying program complexity and interpretability. Halstead Effort, calculated based on the number of operators and operands in the generated code, provides a numerical assessment of the cognitive load required to understand the model. This value is directly integrated into the multi-objective optimization process alongside predictive accuracy, allowing the algorithm to prioritize simpler, more understandable programs without significantly sacrificing performance. The resulting optimization balances these competing objectives, yielding models that are both effective and readily interpretable by human analysts.
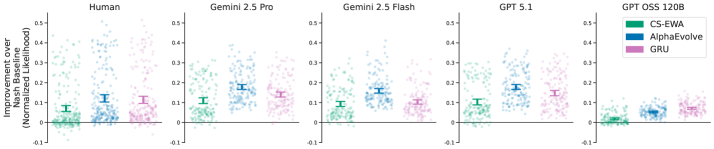
Beyond Baselines: The Promise of Discovered Strategies
Recent investigations reveal that models generated through the AlphaEvolve automated discovery process consistently surpass the performance of established strategic game-playing algorithms, including Contextual Sophisticated EWA and Recurrent Neural Networks. These findings aren’t merely incremental improvements; the AlphaEvolve-discovered programs demonstrate a statistically significant advantage in complex strategic scenarios. This superior performance isn’t achieved through brute-force computation, but rather through the identification of novel strategies that traditional methods fail to uncover. The consistent outperformance across multiple game types suggests that AlphaEvolve effectively navigates the search space for optimal policies, offering a pathway towards creating more intelligent and adaptable artificial agents.
The demonstrable success of AlphaEvolve-discovered models over established benchmarks indicates a significant advancement in automated strategy development. This isn’t simply incremental improvement; the system consistently uncovers approaches that outperform those designed by human experts or traditional algorithmic methods. This suggests the automated discovery process possesses an inherent capability to explore a broader solution space and identify strategies characterized by both increased effectiveness and resource efficiency. By circumventing conventional limitations, the system can forge novel pathways to optimal performance, potentially revolutionizing fields reliant on complex decision-making, from game theory and robotics to financial modeling and logistical optimization. The implications extend beyond merely achieving better results; it highlights a new paradigm where algorithms can independently innovate and refine strategies, paving the way for increasingly autonomous and intelligent systems.
Unlike the often opaque “black box” nature of neural networks, programs generated through AlphaEvolve exhibit a level of inherent interpretability. The algorithmic construction of these strategies – built from explicit, human-readable instructions – allows researchers to directly examine how a successful decision is reached. This transparency facilitates a deeper understanding of the game’s dynamics and the factors driving optimal performance, moving beyond simply observing that a strategy works. Consequently, the process not only yields effective solutions but also provides valuable insights into the underlying decision-making process, potentially informing strategies in other complex domains and offering a pathway to more explainable artificial intelligence.
AlphaEvolve distinguishes itself by not simply optimizing for peak performance, but rather by charting a course along the Pareto Frontier – a range of solutions where improving one characteristic, such as strategic effectiveness, necessarily compromises another, like computational complexity. This approach delivers a diverse set of models, allowing for carefully tailored selection based on specific application needs and resource constraints. The significance of this capability is increasingly apparent as leading large language models (LLMs) showcase superior performance through increasingly sophisticated strategic thinking; AlphaEvolve’s method provides a means of not only achieving high performance but also understanding the trade-offs inherent in complex decision-making, potentially unlocking even more nuanced and efficient strategies in the future.

The study reveals a fascinating divergence in strategic thinking between humans and Large Language Models. While human players in repeated games often rely on heuristics and bounded rationality, LLMs, leveraging their capacity for opponent modeling, demonstrate a more calculated and adaptive approach. This aligns with Robert Tarjan’s observation: “A good data structure is worth any price.” The ‘data structure’ in this case is the LLM’s ability to internally represent and predict the strategies of its opponent, enabling a level of play exceeding that of human participants. The research underscores that effective strategy isn’t solely about making optimal moves, but about understanding the underlying structure of the game and, crucially, the opponent’s approach to it. Good architecture is invisible until it breaks, and only then is the true cost of decisions visible.
Beyond the Game
The observed aptitude of Large Language Models in strategic settings raises a curious point: sophistication in opponent modeling does not necessarily equate to general intelligence. These systems excel at distilling behavioral patterns into executable code, a feat humans perform with far less efficiency, yet this prowess remains narrowly focused. The challenge lies not simply in replicating complex behavior, but in understanding why that behavior occurs – a task demanding a level of abstraction these models have yet to demonstrate.
Future work must move beyond the identification of successful strategies toward an examination of their underlying principles. The current approach, while revealing the ‘what’, provides little insight into the ‘why’. A fruitful avenue of investigation lies in exploring the trade-offs inherent in different modeling strategies – the cost of complexity versus the benefits of accuracy, the danger of overfitting versus the necessity of generalization. Every simplification carries a cost, every clever trick harbors risks.
Ultimately, the true test will not be whether these models can defeat humans in iterated games, but whether they can offer genuinely novel insights into the dynamics of strategic interaction. The elegant solution, as always, likely resides in a deeper appreciation for the simplicity that governs even the most complex systems.
Original article: https://arxiv.org/pdf/2602.10324.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Celebs Who Narrowly Escaped The 9/11 Attacks
- How to Unlock Stellar Blade’s Secret Dev Room & Ocean String Outfit
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Persona 5: The Phantom X Relativity’s Labyrinth – All coin locations and puzzle solutions
- Global REIT ETFs: A Tale of Two Funds
- 20 Films Where Black Directors Subverted Hollywood’s White Savior Tropes
- Here are the Best Series to Binge on Paramount+ in January 2026
2026-02-12 11:55