Author: Denis Avetisyan
A new framework, AutoSpec, uses machine learning to discover and optimize iterative algorithms for solving complex linear algebra problems.
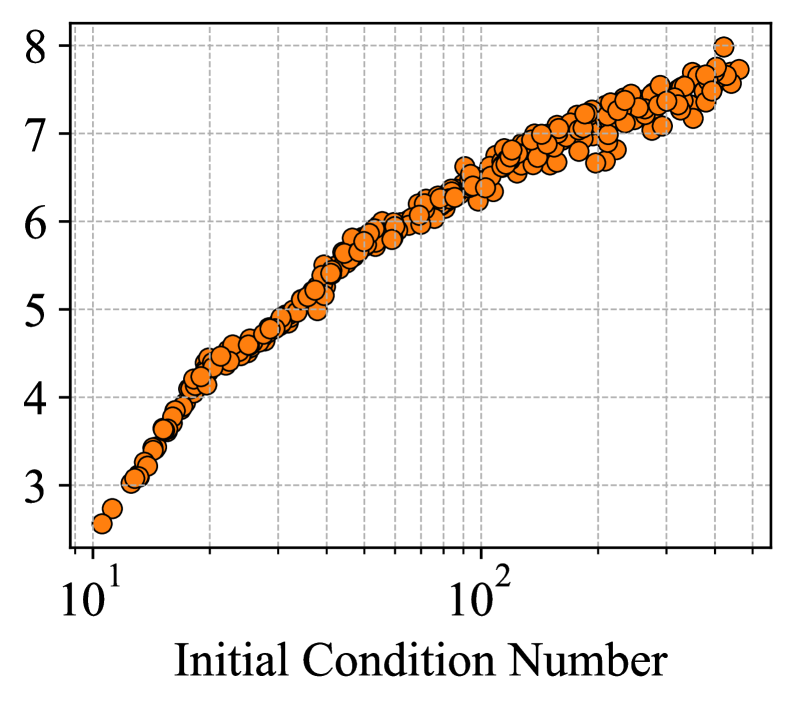
AutoSpec learns to adapt to the spectral properties of input operators, offering a novel approach to algorithm discovery and polynomial preconditioning.
Designing efficient numerical algorithms often requires expert knowledge and problem-specific tuning, a limitation addressed by the novel approach presented in ‘Learning to Discover Iterative Spectral Algorithms’. This work introduces AutoSpec, a neural network framework that learns to construct iterative algorithms tailored to the spectral properties of input operators, effectively automating algorithm discovery for tasks in numerical linear algebra and optimization. By training on small problems and transferring knowledge to large-scale systems, AutoSpec predicts recurrence coefficients that yield algorithms demonstrating orders-of-magnitude improvements in accuracy and efficiency-often mirroring the behavior of classical Chebyshev polynomials. Could this framework ultimately enable the automated design of optimal numerical methods across a broader range of scientific computing challenges?
The Inherent Limitations of Conventional Linear Solvers
The resolution of large systems of linear equations forms a cornerstone of modern computation, underpinning simulations and analyses across diverse fields like structural mechanics, fluid dynamics, and machine learning. However, conventional iterative approaches – while theoretically sound – frequently encounter limitations when scaling to the immense datasets characteristic of these applications. The computational burden and memory requirements increase dramatically with problem size, often leading to unacceptable processing times or even outright failure. This struggle stems from the inherent complexities of these systems, where the number of unknowns can easily reach millions or even billions, demanding algorithms that are not only accurate but also highly efficient in terms of both computation and memory usage. Consequently, researchers continually seek novel techniques to overcome these scalability bottlenecks and unlock the full potential of numerical simulations.
Traditional iterative methods for solving linear equations, while conceptually straightforward, frequently demand substantial manual intervention to achieve optimal performance. The efficacy of techniques like conjugate gradient or GMRES is heavily influenced by parameters that require careful, problem-specific tuning – a process demanding both significant expertise and considerable computational resources. Furthermore, these methods often necessitate preconditioning, where the original system is transformed into an equivalent, but more easily solvable, form. Selecting and implementing an effective preconditioner is itself a complex undertaking, adding to the overall computational cost and demanding a deep understanding of the underlying mathematical properties of the system being solved. This reliance on hand-tuning and preconditioning introduces a practical barrier to widespread adoption, particularly for large-scale problems where automated optimization strategies are crucial for efficient computation.
AutoSpec: Algorithm Discovery Through Principled Learning
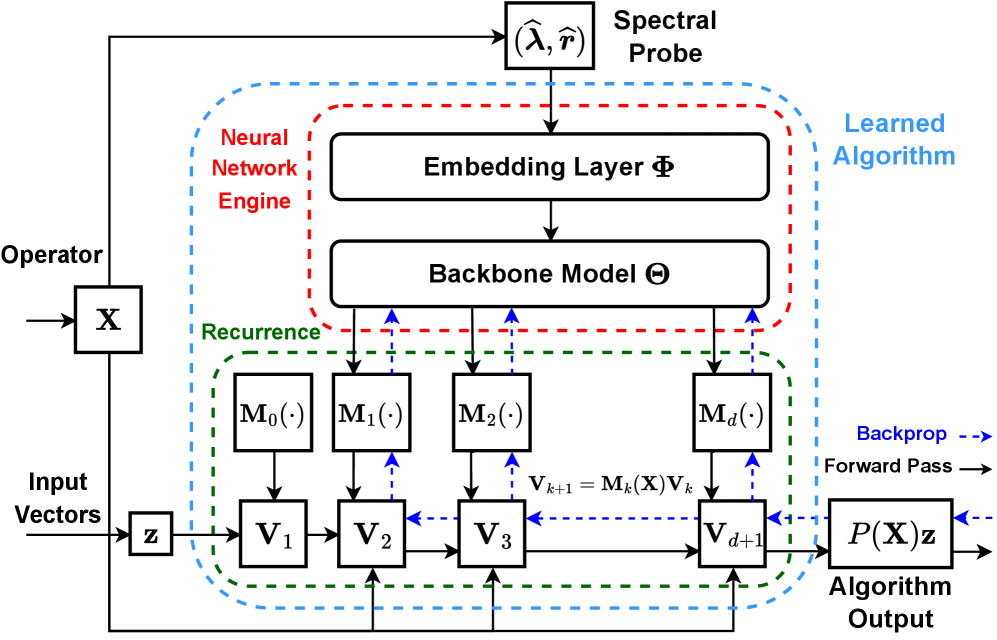
AutoSpec presents a new framework for the automated discovery of iterative spectral methods using deep learning techniques. Traditional algorithm development for solving linear systems requires substantial manual effort in design and parameter tuning; AutoSpec aims to circumvent this process by learning algorithms directly from problem characteristics. The system employs a neural network trained to generate iterative schemes based on spectral probes, which are approximations of eigenvalues and residual norms that quantify the properties of the underlying operator. This approach enables the creation of customized solvers without requiring explicit human expertise in numerical linear algebra or iterative method construction, potentially leading to algorithms tailored for specific problem structures and improved performance.
The AutoSpec framework employs a Neural Network Engine to algorithmically construct iterative methods by interpreting spectral probes. These probes consist of approximate eigenvalues and residual norms calculated from the problem being solved, providing data characterizing the underlying linear operator. The engine learns to map these spectral characteristics to algorithm parameters, effectively discovering iterative schemes tailored to the problem’s structure without requiring explicit, manual design. This learning process allows the network to identify suitable preconditioners and iteration operators based solely on observed spectral properties, enabling automated algorithm discovery and optimization.
The AutoSpec engine constructs iterative schemes by representing algorithms as Operator Polynomials, which are linear combinations of operators applied to the initial residual. These polynomials, denoted as P(A), approximate the inverse of the operator A, enabling efficient solution of linear systems. The network learns the coefficients of these polynomials directly from spectral probes – specifically, eigenvalues and residual norms – characterizing the problem’s underlying structure. By optimizing these coefficients, AutoSpec effectively discovers algorithms that minimize the residual norm with each iteration, leading to convergence without requiring pre-defined algorithmic templates or manual tuning of polynomial parameters.
Harnessing the Power of Spectral Analysis
AutoSpec leverages the eigenspectrum – the distribution of eigenvalues – of a matrix to optimize iterative solution methods. Analyzing the eigenvalues and eigenvectors reveals inherent properties of the problem, such as conditioning and dominant modes. This analysis informs the construction of customized iterative strategies; for instance, methods can be preconditioned or accelerated by focusing computational effort on eigenvectors associated with large eigenvalues. By adapting to the specific spectral characteristics of the matrix, AutoSpec avoids the use of one-size-fits-all approaches and constructs solvers tailored to the problem’s inherent structure, improving convergence rates and reducing computational cost. The framework effectively exploits the relationship between the eigenspectrum and the behavior of iterative methods, enabling automated optimization of solver performance.
AutoSpec incorporates Matrix-Free Methods to significantly reduce computational costs and memory requirements. These methods circumvent the need to explicitly form, store, and apply matrices, instead relying on matrix-vector products computed through function evaluations or specialized operators. This approach is particularly beneficial for large-scale problems where matrix storage becomes prohibitive and explicit matrix operations are computationally expensive. By avoiding these operations, AutoSpec enhances scalability, enabling the solution of problems with dimensions far exceeding available memory and processing capabilities, while also improving overall computational efficiency.
AutoSpec employs Minimax Approximation to determine optimal iterative methods by directly minimizing the maximum error, denoted as ||x - x^<i>||_{\in fty}, where x is the approximate solution and x^</i> is the true solution. This is achieved by encouraging Equiripple Behavior in the residual, meaning the error oscillates between a maximum positive and negative value with equal amplitude. This controlled oscillation ensures that no single element of the residual dominates the error, resulting in a solution that is demonstrably robust to perturbations and exhibits consistent accuracy across all dimensions of the problem space. By prioritizing the minimization of the maximum error rather than average error, AutoSpec avoids scenarios where a few large errors significantly degrade the overall solution quality.
Beyond Replication: Towards Algorithmic Innovation
AutoSpec’s capacity to independently rediscover established algorithms, such as the Conjugate Gradient method, serves as a critical validation of its underlying principles. This isn’t merely a replication of known solutions, but rather an independent derivation, confirming the system’s ability to identify and implement high-performance approaches without prior knowledge. The successful rediscovery demonstrates that AutoSpec doesn’t rely on chance or memorization; instead, it effectively navigates the algorithmic landscape to arrive at efficient solutions. This capability is foundational, providing confidence that the framework can not only replicate existing techniques but venture beyond them to discover genuinely novel and improved methods for solving complex computational problems.
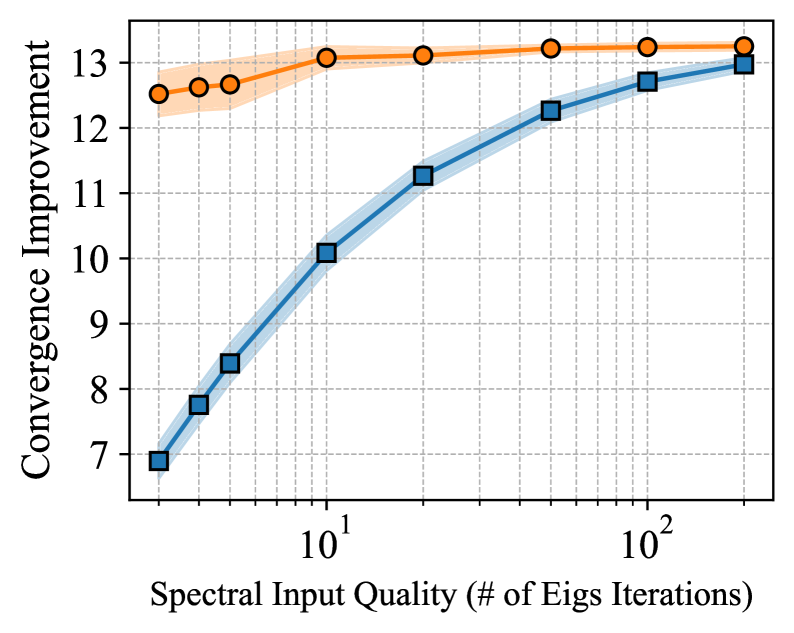
AutoSpec’s capacity extends beyond merely rediscovering existing algorithms; it actively generates novel methods that, in specific computational scenarios, significantly surpass the performance of established techniques. These newly discovered approaches aren’t incremental improvements, but demonstrate enhancements achieving improvements in convergence speed measured in orders of magnitude – a difference representing factors of ten or more. This leap in efficiency isn’t limited to theoretical gains; practical implementations reveal substantial acceleration in solving complex problems, suggesting AutoSpec possesses a genuine capacity for innovation and the potential to redefine the boundaries of algorithmic performance in targeted applications. The framework isn’t just optimizing what’s known, but forging pathways to solutions previously considered unattainable within reasonable timeframes.
The AutoSpec framework is designed for continued evolution through the integration of advanced algorithm discovery techniques. Researchers are now exploring the use of Reinforcement Learning (RL) and Large Language Models (LLMs) to automate and enhance the process of algorithm design itself. By framing algorithm creation as a search problem, RL agents can iteratively refine algorithms based on performance feedback, while LLMs offer the potential to generate novel algorithmic structures from high-level specifications. This synergy promises to move beyond simply rediscovering existing methods, enabling the creation of algorithms tailored to specific problem landscapes with minimal human intervention and potentially unlocking solutions previously considered intractable. The framework’s adaptability in this regard positions it as a dynamic tool for ongoing innovation in computational methods.
The AutoSpec framework incorporates Polynomial Preconditioning, a technique rooted in Chebyshev Polynomials, to significantly refine the performance of discovered algorithms. This method strategically reshapes the problem space, accelerating convergence and minimizing error during optimization. By applying these polynomials, the framework effectively reduces the condition number of the system, thereby mitigating the propagation of errors and achieving a minimax error remarkably close to the theoretical optimum. This optimization isn’t merely incremental; it represents a substantial step towards solutions that approach the fundamental limits of accuracy dictated by the problem itself, ensuring that discovered algorithms aren’t just novel, but also demonstrably efficient and robust.
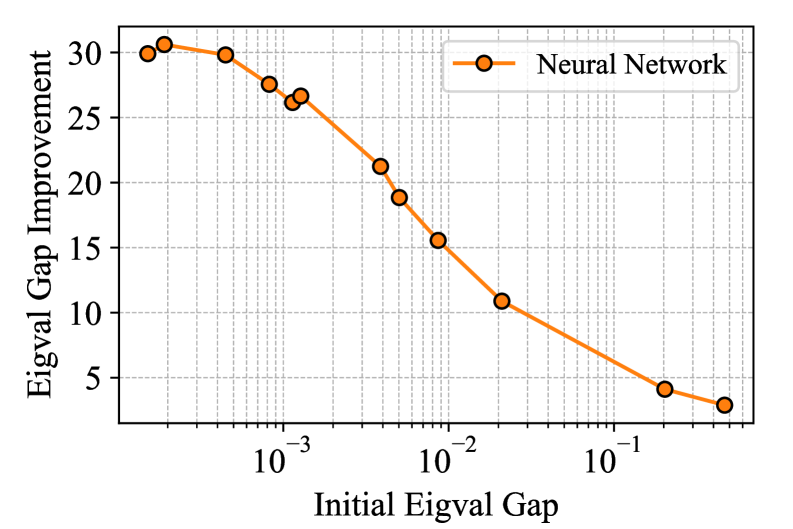
The pursuit of efficient algorithms, as demonstrated by AutoSpec, resonates with a sentiment expressed by Carl Friedrich Gauss: “If other mathematicians had only been as careful in their methods as I am, we would have advanced much further.” AutoSpec’s neural network framework meticulously learns to adapt to the spectral properties of operators, effectively minimizing redundancy and maximizing performance in iterative algorithms. This careful adaptation, driven by spectral approximation and polynomial preconditioning, embodies Gauss’s dedication to rigorous mathematical purity. The framework doesn’t simply aim for a ‘working’ solution; it strives for an optimal, provable algorithm, mirroring a dedication to correctness above all else.
What Lies Ahead?
The emergence of AutoSpec represents a departure from the traditionally hand-crafted nature of iterative algorithms. However, the true test of this approach resides not merely in replicating existing methods, but in surpassing them. Current performance, while promising, remains tethered to the limitations of the training data-a reliance on known spectral characteristics. A genuine breakthrough will necessitate algorithms that exhibit robustness to operator classes not explicitly encountered during training, demanding a level of generalization currently absent.
Further exploration must address the inherent opacity of these learned algorithms. Demonstrating provable convergence-establishing guarantees on the algorithm’s behavior-is paramount. Simply observing empirical success on a suite of test problems is insufficient; mathematical rigor is the only acceptable metric. The field should shift focus from simply finding an algorithm to understanding why that particular algorithm functions effectively – a pursuit of elegance beyond mere expediency.
Ultimately, the question is not whether neural networks can discover algorithms, but whether they can reveal fundamentally new algorithmic principles. The current work suggests a path towards automating the tedious aspects of algorithm design, but the ascent to true innovation demands a commitment to mathematical purity-a focus on asymptotic behavior and scalability, not merely on achieving faster runtimes on contrived benchmarks.
Original article: https://arxiv.org/pdf/2602.09530.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Persona 5: The Phantom X Relativity’s Labyrinth – All coin locations and puzzle solutions
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Silver Rate Forecast
- How to Unlock Stellar Blade’s Secret Dev Room & Ocean String Outfit
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- ‘Super Mario Galaxy’ Trailer Launches: Chris Pratt, Jack Black, Anya Taylor-Joy, Charlie Day Return for 2026 Sequel
2026-02-12 05:12