Author: Denis Avetisyan
A new analysis reveals how intelligently choosing data points during model training can dramatically improve both accuracy and energy efficiency.
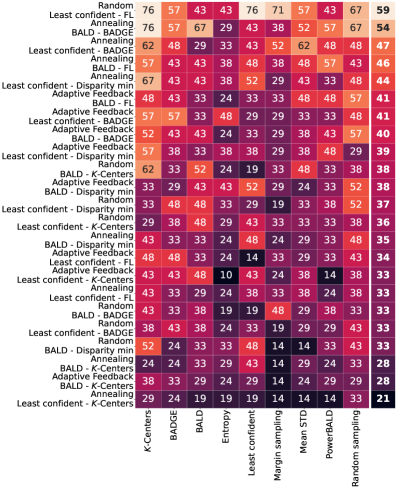
Combining acquisition functions in active learning, particularly with series structures and alternating exploration-exploitation strategies, yields optimal results for data and energy efficiency.
Balancing data efficiency with computational cost remains a central challenge in machine learning. This is addressed in ‘Active Learning Using Aggregated Acquisition Functions: Accuracy and Sustainability Analysis’, which investigates novel strategies for intelligently selecting data points for annotation via active learning. The study demonstrates that combining diverse acquisition functions-particularly through sequential or hybrid structures-can alleviate common pathologies and significantly reduce sample complexity while maintaining or improving model accuracy. Could these aggregated approaches pave the way for more sustainable and energy-efficient artificial intelligence systems, lessening the environmental impact of increasingly complex models?
The Data Labeling Bottleneck: A Pragmatic Approach
The prevailing paradigm of supervised machine learning often necessitates enormous, meticulously labeled datasets – a substantial impediment to progress in many fields. Acquiring these datasets isn’t simply a matter of collecting information; it demands significant investment in both time and resources. Each data point requires careful annotation, often by experts, which can be particularly expensive in domains like medical diagnosis or materials science. This reliance on large labeled datasets creates a considerable bottleneck, limiting the applicability of powerful machine learning techniques to problems where such resources are readily available. The sheer scale of data preparation frequently overshadows the algorithmic innovation itself, hindering the potential for rapid advancements and widespread adoption of these technologies.
Rather than passively accepting all available data for training, active learning algorithms intelligently pinpoint the samples that will yield the greatest improvement in model accuracy. This strategic selection process prioritizes data points where the model is most uncertain or where labeling will resolve the largest disagreement among potential predictions. By focusing labeling efforts on these most informative instances, active learning dramatically reduces the amount of manually annotated data needed to achieve a desired level of performance. The result is a more efficient and cost-effective training process, particularly beneficial when acquiring labels requires significant time, resources, or specialized knowledge – enabling robust machine learning models with a fraction of the traditionally required data.
The escalating costs and complexities of data labeling present a significant hurdle in many advanced applications, particularly within medical imaging and scientific data analysis. Obtaining accurately labeled datasets in these fields isn’t merely time-consuming; it frequently demands the involvement of highly trained specialists – radiologists interpreting scans, or physicists analyzing particle collision data – making each labeled example a substantial financial and logistical investment. This reality elevates the importance of techniques like active learning, which minimize the need for exhaustive labeling by intelligently pinpointing the data points that will yield the greatest improvement in model accuracy. By prioritizing informative samples, active learning offers a pathway to build robust predictive models even when labeled data is scarce and expensive to obtain, accelerating progress in fields where expert annotation is paramount.
Strategic Data Selection: The Acquisition Function at Work
An `AcquisitionFunction` is a core component of active learning, responsible for determining the order in which unlabeled data points are selected for annotation. Rather than random sampling, these functions quantify the potential value of each unlabeled instance – typically based on the model’s current uncertainty or expected improvement – and prioritize those predicted to yield the greatest benefit to model performance. This ‘query strategy’ optimizes the labeling process by focusing effort on the most informative data, thereby reducing the total number of labels required to achieve a desired level of accuracy. The output of an `AcquisitionFunction` is a ranked list of unlabeled instances, which are then presented to an annotator for labeling.
Several acquisition functions directly utilize model uncertainty to prioritize data labeling. `LeastConfidence` selects instances where the model’s highest predicted probability is low, indicating potential ambiguity. `MarginSampling` chooses data points with small differences between the probabilities of the top two predicted classes, again highlighting uncertainty. `BALD` (Batch Active Learning by Diverse means) employs Monte Carlo dropout – repeatedly running the model with different neurons randomly dropped – to generate multiple predictions for each instance; the uncertainty is then quantified by measuring the mutual information between these predictions and the model’s output, providing a more robust estimate of uncertainty than single-pass predictions.
Functions like BADGE (Bayesian Active Learning by Diverse Greedy Exploration) and KKCenters address limitations of uncertainty-based methods by explicitly promoting sample diversity. BADGE utilizes a greedy approach to select points that maximize the information gain while maintaining a representative set of data, calculated using a kernel-based distance metric. KKCenters, conversely, employs a k-center greedy algorithm to identify a subset of data points that minimizes the maximum distance to any other point in the unlabeled set, effectively covering the data space. Both methods aim to mitigate the tendency of simpler acquisition functions to repeatedly select similar data points, thereby enhancing the model’s generalization capability and reducing the impact of redundant labeling efforts.
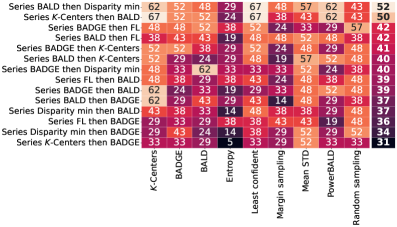
Orchestrating Data Queries: Structural Approaches to Selection
Acquisition strategies employing either a `SeriesStructure` or `ParallelStructure` aim to improve model performance by combining the strengths of individual acquisition functions. A `SeriesStructure` sequentially applies functions, with the output of one function serving as input to the next, allowing for refined data selection based on prior stages. Conversely, a `ParallelStructure` executes multiple acquisition functions concurrently, aggregating their results to create a more comprehensive candidate pool for labeling. This parallel approach allows the system to benefit from diverse data selection criteria simultaneously. Both structures facilitate the exploitation of complementary strengths; for example, an initial function prioritizing diversity can be followed by a function focused on uncertainty sampling, leading to more efficient data labeling and improved model accuracy.
AdaptiveFeedback operates by continuously monitoring the performance of the active learning model and subsequently adjusting the selection of acquisition functions to optimize data labeling. This is achieved through a closed-loop system where model performance metrics – such as prediction accuracy or uncertainty reduction – are used as input to a function selector. The selector then prioritizes acquisition functions demonstrating the most significant positive impact on performance, while down-weighting or excluding those that are underperforming. This dynamic adjustment creates a self-improving data selection loop, allowing the system to focus labeling efforts on the most informative data points and thereby maximize learning efficiency with minimal labeling cost.
A series structure combining the KKCenters and BALD acquisition functions yields significant performance improvements. Empirical results indicate a 12% reduction in the number of labeled data points required to achieve 80% accuracy when compared to utilizing BALD in isolation. Furthermore, this combined approach demonstrably lowers acquisition cost by approximately 48%, representing a substantial decrease in the resources needed for effective model training and refinement.
Addressing the inherent trade-off between exploration and exploitation in active learning, `AnnealingExploration` and `RandomExploration` offer distinct strategies for diversifying data selection. `AnnealingExploration` systematically reduces the probability of selecting diverse, uncertain samples over time, transitioning from broad exploration to focused exploitation as the model gains confidence. Conversely, `RandomExploration` maintains a consistent probability of selecting samples randomly, providing ongoing diversification to prevent premature convergence on local optima. Both methods aim to mitigate the `ExplorationExploitationDilemma` – the need to balance gathering new information with leveraging existing knowledge – although they differ in their temporal approach to this balance.
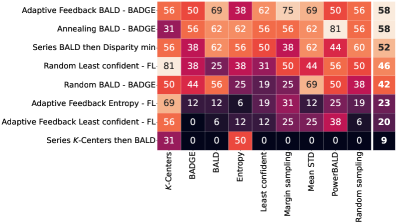
Validation and Broad Applicability: A Practical Advantage
Investigations into active learning methodologies have demonstrated notable success within the realm of image classification, particularly when utilizing benchmark datasets such as `CIFAR10` and `CIFAR100`. These datasets, comprised of tens of thousands of labeled images across ten and one hundred classes respectively, served as proving grounds for strategies designed to minimize labeling effort while maximizing model accuracy. Results indicate that intelligently selecting which data points to label – as opposed to random sampling – can significantly improve performance with fewer training examples. This suggests a pathway towards more efficient and cost-effective development of image recognition systems, reducing the substantial human resources often required for large-scale dataset annotation.
Beyond image recognition, these active learning strategies prove remarkably adept at interpreting complex temporal patterns inherent in time-series data. Specifically, application to the extensive PTBXL electrocardiogram dataset demonstrates the techniques’ ability to discern subtle, yet critical, features within physiological signals. This dataset, comprised of recordings from over 21,000 patients, presents a significant challenge due to its scale and the nuanced characteristics of cardiac activity. Successful performance on PTBXL indicates that the methodology isn’t limited to static data; it can effectively prioritize informative samples within dynamic sequences, potentially enabling earlier and more accurate diagnoses in healthcare and similar signal-processing applications.
A robust approach to active learning was demonstrated through the serial combination of two distinct querying strategies, `KKCenters` and `BALD`. Across a diverse range of datasets and model architectures, this combined method consistently outperformed random selection, achieving a win rate exceeding 50%. This indicates that leveraging the strengths of both techniques – `KKCenters`’ focus on representative data points and `BALD`’s emphasis on uncertainty – provides a reliable and broadly applicable means of improving model efficiency. The consistent performance across varied conditions suggests this series combination isn’t merely tailored to specific scenarios, but rather represents a generally effective strategy for minimizing labeling costs and maximizing learning gains in diverse machine learning applications.
The demonstrated success of active learning strategies extends beyond specific datasets and model architectures, positioning it as a broadly applicable framework for enhancing machine learning performance. Investigations utilizing datasets like `CIFAR10` and `PTBXL`, in conjunction with models ranging from `ResNet` to `VGG`, consistently reveal improvements achieved through selective data querying. This versatility suggests that active learning isn’t merely a technique tailored to particular problems, but rather a robust methodology capable of optimizing model training across diverse domains – from image recognition to complex time-series analysis. The ability to consistently yield better results, regardless of the underlying model or data characteristics, underscores the potential for widespread adoption and integration into existing machine learning pipelines.
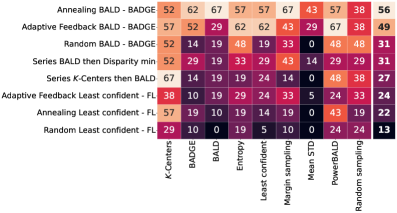
The pursuit of ever-more-efficient acquisition functions, as detailed in this study of active learning, feels… familiar. It’s a constant re-solving of problems thought long settled. One is reminded of Ken Thompson’s observation: “Software is a gas. It expands to fill the available memory.” This research, attempting to squeeze more performance from data selection, merely demonstrates that computational complexity doesn’t diminish with cleverness – it reshuffles. The alternating exploration-exploitation strategies, the series structures… they’re elegant bandages on a fundamentally messy problem. It’s not about solving data inefficiency, it’s about postponing the inevitable scaling crisis. One suspects future archaeologists will unearth these ‘innovations’ alongside the legacy code, marveling at the cycle of reinvention.
The Road Ahead
The pursuit of efficient acquisition functions in active learning yields diminishing returns. This work demonstrates a preference for series structures and alternating exploration-exploitation, but frames it as optimization within the existing paradigm. The bug tracker, however, will inevitably fill with edge cases-datasets where carefully constructed series structures simply exacerbate existing biases, or where the cost of evaluation dwarfs any energy savings. It is not a solution; it’s a slightly more graceful deceleration toward inevitable complexity.
Future work will undoubtedly focus on meta-learning acquisition functions-algorithms that learn how to best explore and exploit. The irony, of course, is that this merely shifts the data efficiency problem one level higher. The meta-learner requires its own training data, its own validation sets. The problem doesn’t vanish; it metastasizes. There is no ‘intelligent’ acquisition; there is only postponement.
Ultimately, the field seems fixated on squeezing marginal gains from model training, rather than questioning the fundamental assumption: that labeled data is the bottleneck. The next breakthrough won’t be a clever acquisition function. It will be a method for living with uncertainty, for building systems that degrade predictably rather than failing catastrophically. It doesn’t deploy – it lets go.
Original article: https://arxiv.org/pdf/2602.07440.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Persona 5: The Phantom X Relativity’s Labyrinth – All coin locations and puzzle solutions
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Games That Faced Bans in Countries Over Political Themes
- How to Unlock Stellar Blade’s Secret Dev Room & Ocean String Outfit
- ‘Super Mario Galaxy’ Trailer Launches: Chris Pratt, Jack Black, Anya Taylor-Joy, Charlie Day Return for 2026 Sequel
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Games Rewarding Exploration Over Combat Heavy Gameplay
- Here Are the Weekend Box Office Hits for This Weekend, with the Super Popular Romance on Top
2026-02-11 05:38