Author: Denis Avetisyan
A new deep learning system automatically identifies and analyzes singing inaccuracies, paving the way for personalized vocal coaching.
This research details a framework for automatic mistake detection in Indian Art Music, utilizing time series analysis and a novel dataset to enhance teacher-learner interaction.
Effective music pedagogy often relies on nuanced, individualized feedback, a process difficult to scale with traditional methods. This paper, ‘Automatic Detection and Analysis of Singing Mistakes for Music Pedagogy’, introduces a deep learning framework-supported by a novel dataset of teacher-learner vocal interactions-designed to automatically identify errors in singing performance, specifically within the context of Indian Art Music. Experiments demonstrate that these learning-based methods surpass rule-based approaches in accurately detecting mistakes, offering a new evaluation methodology for such systems. Could this automated analysis ultimately provide personalized, scalable support for music learners and reveal deeper insights into effective teaching practices?
The Architecture of Sound: Raga, Tala, and the Guru-Shishya Parampara
Indian art music, in its diverse forms such as Hindustani and Carnatic traditions, isn’t simply a collection of songs, but a sophisticated and interconnected system of sound. At its core lie the concepts of raga and tala, which function as fundamental building blocks. A raga is more than a scale; it’s a melodic framework with prescribed ascending and descending patterns, characteristic phrases, and emotive qualities – a musical personality, if you will. Simultaneously, tala provides the rhythmic structure, defining the cyclical patterns of beats and emphasizing specific points within the cycle. These aren’t independent elements; instead, improvisation within a raga is deeply intertwined with the rhythmic possibilities of the tala, creating a dynamic interplay between melody and rhythm that forms the heart of Indian musical expression. The complexity arises not just from the numerous ragas and talas, but from the subtle ornamentation, microtonal nuances, and improvisational freedom permitted within these frameworks, demanding years of dedicated study and practice to master.
For generations, the intricacies of Indian art music have been preserved and transmitted through the Guru-Shishya Parampara, a deeply personal and immersive mentorship system. This tradition extends far beyond the mere teaching of notes and scales; it centers on the direct, one-on-one transfer of musical knowledge, aesthetic sensibilities, and performance subtleties from a master musician, or Guru, to a dedicated student, or Shishya. Emphasis lies not just on what to play, but how – the delicate ornamentation, the microtonal inflections, and the emotive resonance that collectively define a performance. Students often reside with their Gurus for years, absorbing the musical lineage through observation, imitation, and rigorous practice, fostering a holistic understanding unattainable through purely academic study. This intimate setting allows for immediate feedback and correction, cultivating a nuanced musicality and a profound connection to the art form’s cultural heritage.
The centuries-old Guru-Shishya tradition, while deeply effective in transmitting the intricacies of Indian art music, inherently presents limitations in a contemporary context. Its reliance on one-on-one instruction restricts accessibility and makes widespread dissemination of knowledge difficult. Furthermore, assessment within this system is largely subjective, guided by the Guru’s individual experience and aesthetic judgment, and lacks the objective, standardized error analysis crucial for systematic improvement. This necessitates the exploration of computational approaches- leveraging technologies like machine learning and signal processing-to not only preserve these rich musical traditions but also to create scalable, verifiable methods for learning, practicing, and evaluating performance with greater precision and consistency.
Objectifying Musicality: The M3 Dataset
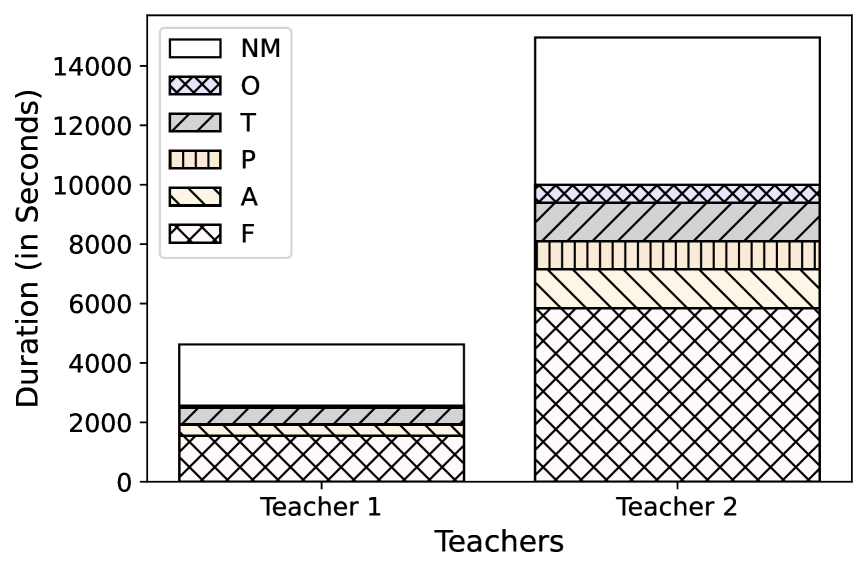
The M3 Dataset is a resource designed to facilitate objective evaluation of singing performance. It comprises synchronized audio recordings of teachers and learners engaged in vocal practice. These recordings were specifically collected to provide a basis for computational analysis of singing quality, moving beyond subjective grading methods. The dataset includes multiple instances of paired teacher and learner performances, enabling comparative analysis and the development of algorithms aimed at identifying discrepancies between expert and novice vocal delivery. Data was gathered with the explicit intention of creating a standardized benchmark for research in vocal pedagogy and automated assessment systems.
The M3 Dataset contains detailed annotations identifying specific error types within learner singing performances. Each recording segment is labeled to indicate the presence and type of mistakes, categorized into four distinct classes: frequency errors, representing pitch inaccuracies; amplitude errors, denoting issues with loudness or dynamic control; pronunciation errors, capturing deviations from correct articulation of lyrics; and rhythm errors, which highlight timing discrepancies or deviations from the established tempo. These annotations are time-aligned with the audio, allowing for precise identification of error occurrences and durations within each performance.
The M3 Dataset’s detailed annotations – specifically identifying instances of frequency, amplitude, pronunciation, and rhythm errors in singing performances – facilitate the creation of computational models for automated error detection and classification. These models utilize the annotated data as ground truth for supervised learning, enabling the development of algorithms capable of pinpointing error types and potentially quantifying their severity. The resulting automated analysis provides a scalable method for studying vocal learning, tracking progress, and identifying common error patterns, offering insights beyond those achievable through manual assessment and providing a basis for personalized feedback systems.
From Rigid Rules to Adaptive Systems: Modeling Musical Error
Early automated music error detection systems relied on a Rule-Based Method, which operated by establishing predetermined, fixed thresholds for acceptable variations in pitch and amplitude. These systems would flag any performance data point falling outside these defined boundaries as an error. For instance, a pitch deviation exceeding ±0.5 semitones, or an amplitude fluctuation exceeding 10dB, might be considered an error. While straightforward to implement, this approach proved inflexible and unable to account for natural performance variations, expressive nuances, or the context of musical phrasing, leading to a high rate of both false positives and false negatives.
Early error detection systems relying on fixed thresholds for pitch and amplitude exhibited significant limitations when applied to actual musical performances. These rule-based methods failed to account for intentional performance variations, such as vibrato, portamento, and dynamic expression, frequently misidentifying them as errors. Furthermore, the systems struggled with variations in timbre, articulation, and the complex interplay between individual notes within a musical phrase. Consequently, the rigid nature of these fixed thresholds resulted in a high rate of false positives and a reduced ability to accurately assess the quality of a musical performance beyond simple, isolated errors.
Convolutional Neural Networks (CNNs) and Convolutional Recurrent Neural Networks (CRNNs) represented an advancement over rule-based systems for error detection, demonstrating increased accuracy in identifying deviations in musical performance. However, both architectures exhibited limitations when processing extended sequences of musical data. CNNs, while effective at capturing local patterns, lack inherent mechanisms to model temporal relationships extending beyond their receptive field. CRNNs, combining CNNs with Recurrent Neural Networks (RNNs), addressed this partially, but standard RNNs, including LSTMs and GRUs, often struggle with vanishing or exploding gradients when processing very long sequences, hindering their ability to effectively learn long-range temporal dependencies crucial for accurate error identification in musical performance.
The Temporal Convolutional Network (TCN) model demonstrated superior performance in error detection by effectively modeling long-range temporal dependencies within musical performances. Unlike prior deep learning approaches such as CNNs and CRNNs, the TCN architecture utilizes causal and dilated convolutions to process sequential data, enabling it to consider a wider context without the vanishing gradient problems common in recurrent networks. Quantitative results consistently showed the TCN model outperforming both rule-based error detection systems and other deep learning models in identifying both frequency and amplitude deviations, establishing it as a state-of-the-art solution for this task.
Refining the System: Robustness and Real-World Accuracy
Addressing the challenge of limited training data, researchers strategically implemented data augmentation techniques to artificially expand the dataset’s size and diversity. This involved creating modified versions of existing examples – subtly altered to represent a wider range of possible inputs – without introducing entirely new, labeled instances. Such transformations helped the model generalize more effectively to unseen data, preventing overfitting to the nuances of the original, smaller dataset. The result was a measurable improvement in F1-scores, a key metric reflecting the model’s precision and recall, demonstrating the augmentation’s success in bolstering the model’s robustness and real-world performance.
The study addressed a common challenge in error annotation datasets – class imbalance – by implementing a Weighted Binary Cross-Entropy Loss function. This technique assigns differing weights to each class during training, effectively penalizing the model more heavily for misclassifying the minority class – in this case, rarer error types. By focusing on these underrepresented errors, the model becomes more sensitive to their presence and improves its ability to accurately identify them, leading to a more balanced and robust performance across all error categories. This weighting strategy ensures the model doesn’t simply prioritize learning from the dominant class, which could result in overlooking crucial, yet infrequent, error events.
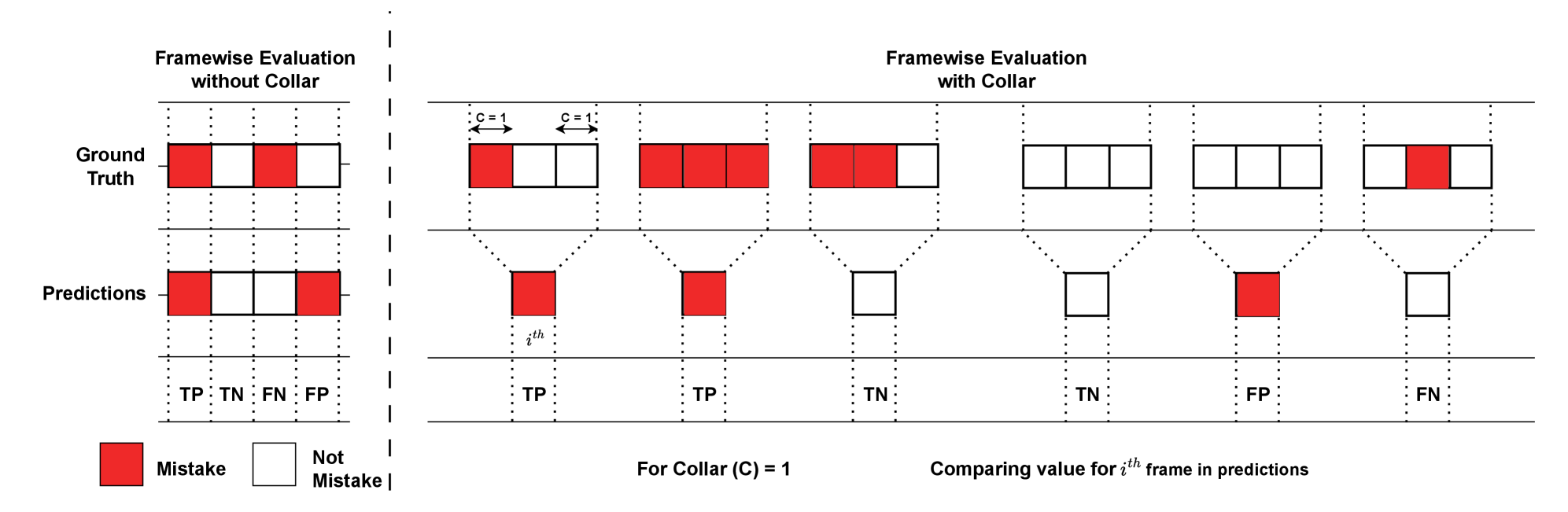
Traditional evaluation of music information retrieval systems often assumes perfect ground truth, a simplification rarely found in real-world error annotation. To address this, a Collared Evaluation method was implemented, acknowledging inherent uncertainty in human labeling. This approach doesn’t demand strict frame-level accuracy, instead accepting predictions within a defined temporal ‘collar’ – in this case, 80 to 200 milliseconds – as correct. The rationale is that slight timing discrepancies shouldn’t be penalized, particularly given the subjective nature of musical event perception. Results demonstrated that utilizing this collared assessment significantly improved frame-wise metrics, providing a more robust and realistic gauge of the model’s performance by aligning evaluation with the tolerances of human annotation and the nuances of musical timing.
To refine the accuracy of musical event detection, a hysteresis thresholding technique was implemented as a post-processing step. This method strategically smooths predictions and minimizes the occurrence of false activations by considering a dual-threshold system; an event must exceed a higher threshold to initiate, and then fall below a lower threshold to terminate. Crucially, this process leverages acoustic features such as the Pitch Contour and Chromagram – representations of fundamental frequency and harmonic content, respectively – which are normalized using a ‘Teacher Normalization’ approach to enhance consistency. By combining these features with hysteresis, the system effectively filters out brief, spurious detections, resulting in a more stable and reliable identification of musical events.
The framework detailed in this study pursues a rigorous simplification of a complex human activity – singing. It distills performance into quantifiable metrics, enabling automated mistake detection within the nuanced context of Indian Art Music. This echoes Simone de Beauvoir’s assertion: “One is not born, but rather becomes, a woman.” Similarly, musical proficiency isn’t innate; it’s become through iterative correction. The system’s ability to pinpoint errors in time series data-a reduction of performance to its essential components-facilitates this becoming. The project’s emphasis on data augmentation to improve model robustness underscores a commitment to precision, eliminating extraneous variables to achieve a concentrated signal, mirroring the pursuit of clarity over superfluous detail.
What Lies Ahead?
The automation of error detection, even within the highly nuanced domain of Indian Art Music, reveals less a triumph of artifice and more a clarification of fundamentals. This work, while promising, merely sketches the contours of a far larger challenge: the formalization of aesthetic judgment. The current framework excels at identifying deviations from established norms-a technical assessment. However, the very spirit of improvisation, of raag exploration, resides in such deviations. Future iterations must grapple with this paradox, distinguishing between errors born of technical deficiency and those representing artistic intent.
The limitations of the dataset are not merely quantitative. Data augmentation, while a pragmatic solution, introduces an inherent artificiality. A truly robust system demands a dataset reflecting the full spectrum of performance styles, teacher methodologies, and learner struggles-a collection that is, by its very nature, resistant to complete capture. The pursuit of ‘generalizability’ should not overshadow the importance of context; a mistake within one gharana might be a stylistic choice within another.
Ultimately, the value of such a system lies not in replacing the teacher, but in amplifying their capacity for nuanced feedback. The most fruitful avenue for future research is therefore the development of interfaces that integrate automated analysis with human judgment-tools that illuminate, rather than dictate, the path to mastery. The goal is not to solve music, but to render its complexities more visible.
Original article: https://arxiv.org/pdf/2602.06917.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 21 Movies Filmed in Real Abandoned Locations
- 2025 Crypto Wallets: Secure, Smart, and Surprisingly Simple!
- The 11 Elden Ring: Nightreign DLC features that would surprise and delight the biggest FromSoftware fans
- 10 Hulu Originals You’re Missing Out On
- The 10 Most Beautiful Women in the World for 2026, According to the Golden Ratio
- Crypto’s Comeback? $5.5B Sell-Off Fails to Dampen Enthusiasm!
- 39th Developer Notes: 2.5th Anniversary Update
- Top ETFs for Now: A Portfolio Manager’s Wry Take
- ICP: $1 Crash or Moon Mission? 🚀💸
- 🚨 Kiyosaki’s Doomsday Dance: Bitcoin, Bubbles, and the End of Fake Money? 🚨
2026-02-10 02:43