Author: Denis Avetisyan
Researchers are leveraging flow matching to build generative models that learn more interpretable and controllable latent representations.
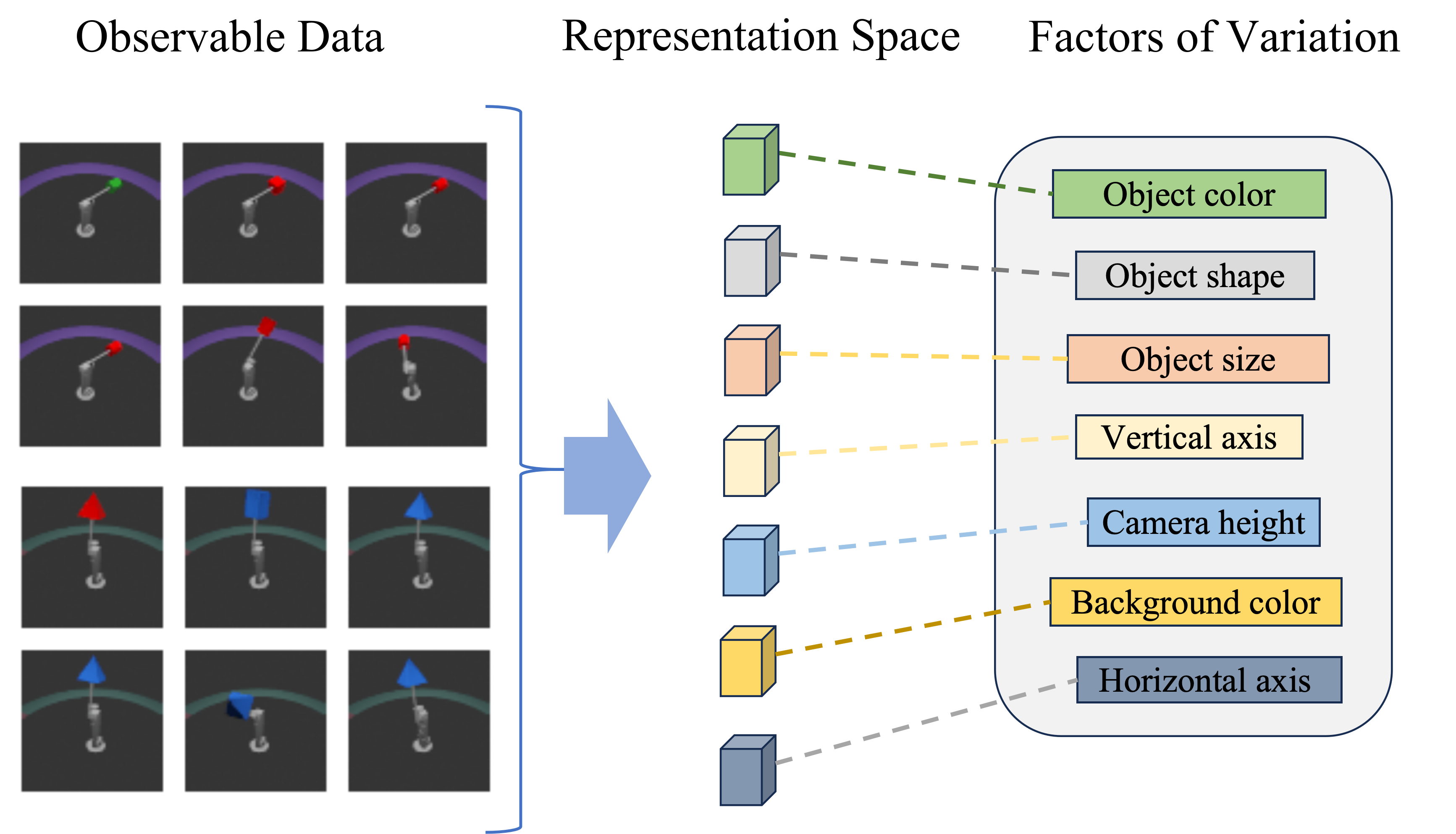
This review details a novel method using flow matching and orthogonality regularization to achieve improved disentanglement and factorized velocity in latent space.
Learning meaningful, interpretable data representations remains a central challenge in machine learning, often hindered by entangled factors of variation. This paper introduces a novel approach to Disentangled Representation Learning via Flow Matching, framing disentanglement as learning factor-conditioned flows within a compact latent space. By explicitly enforcing semantic alignment through an orthogonality regularizer-suppressing interference between factors-we achieve improved disentanglement, controllability, and sample fidelity compared to existing methods. Could this framework unlock more robust and interpretable generative models capable of truly understanding underlying data structures?
The Illusion of Control: Untangling Data’s Knots
The complexity of real-world data frequently arises from the interwoven nature of its underlying generative factors. Consider an image of a human face; variations in pose, lighting, expression, and identity are all simultaneously encoded within the pixel values. This entanglement presents a significant challenge for data analysis and control, as manipulating a single attribute – say, the direction of gaze – often inadvertently affects others. Consequently, algorithms struggle to isolate and independently modify specific aspects of the data, limiting their ability to perform targeted interventions or draw meaningful conclusions. This difficulty extends beyond visual data, impacting fields like audio processing, robotics, and drug discovery, where disentangling complex interactions is crucial for effective modeling and control.
Conventional generative models, while capable of recreating data distributions, often falter when tasked with understanding the underlying causes of variation within that data. These models tend to learn entangled representations, meaning a single latent variable influences multiple observable features simultaneously. This entanglement hinders interpretability; discerning which factor caused a specific change in the generated output becomes exceptionally difficult. Furthermore, this lack of modularity impacts generalization; slight alterations in input can produce unpredictable and disproportionate changes, limiting the model’s ability to adapt to novel situations or reliably manipulate specific attributes of the generated data. The consequence is a system that mimics data well, but offers limited control or insightful understanding of the generative process itself.
Disentangled Representation Learning aims to construct a latent space-a compressed representation of data-where individual dimensions aren’t tangled with multiple underlying factors, but instead each neatly corresponds to a single, independent characteristic. Imagine a face image: traditional machine learning might encode the entire image into a single vector, mixing pose, lighting, and identity. A disentangled representation, however, strives to separate these elements, with one dimension controlling the angle of the head, another the illumination, and yet another the individual’s unique features. This isolation isn’t merely about neatness; it facilitates targeted manipulation – altering only the lighting without changing the identity – and improves generalization, allowing models to understand and recreate variations even with limited data, ultimately leading to more interpretable and controllable artificial intelligence systems.

Flow Matching: A More Direct Route to Generation
Flow Matching approaches generative modeling by defining a continuous transformation between a simple probability distribution, typically Gaussian noise, and the target data distribution. This is achieved by learning a time-dependent vector field, v(x,t), which dictates the velocity of points in data space as they evolve along a trajectory over time t. Instead of iteratively refining a sample like diffusion models, Flow Matching directly learns a flow that transports probability mass from the noise distribution to the data distribution. This formulation establishes generative modeling as a continuous trajectory problem, where the learned vector field defines the path each data point takes during this transformation. The effectiveness of this approach relies on accurately approximating this vector field to ensure a smooth and invertible flow.
Flow Matching distinguishes itself from diffusion models by directly learning a vector field that transports probability mass from a simple distribution, such as noise, to the target data distribution. Diffusion models achieve this indirectly through a Markov chain of diffusion and reverse diffusion processes. This direct approach has the potential to reduce computational costs associated with iterative denoising steps, leading to faster sample generation. Furthermore, by directly optimizing the transport map, Flow Matching can, in principle, yield samples with improved fidelity and diversity compared to methods reliant on approximating a complex reverse diffusion process. Empirical results suggest improvements in sample quality metrics and a reduction in the number of function evaluations required for generation, indicating the potential for increased efficiency and performance.
The core of Flow Matching relies on defining a continuous transformation of probability distributions via a time-dependent vector field, mathematically expressed and implemented through the solution of Ordinary Differential Equations (ODEs). Specifically, a stochastic differential equation (SDE) is formulated to describe the flow of data from a simple distribution (noise) to the target data distribution. Numerical methods, or ODE solvers, are then essential to approximate the solution to these ODEs, effectively defining the generative process. The efficiency and accuracy of these ODE solvers directly impact the speed of sample generation and the quality of the generated samples; therefore, research focuses on employing and adapting efficient solvers like Runge-Kutta methods or adaptive step-size solvers to handle the complexities of the learned vector fields and ensure stable and rapid convergence during the generative process.
Flow Matching leverages U-Net architectures to approximate the time-dependent vector field that defines the generative process. These U-Nets, commonly employed in image segmentation and other pixel-wise prediction tasks, are adapted to predict the velocity vector at each point in time and noise level. The U-Net’s encoder-decoder structure facilitates the learning of complex relationships between the noise and the desired data distribution. By training the U-Net to estimate the direction and magnitude of the flow, the model effectively learns a mapping from noise to data, enabling the generation of new samples by solving the corresponding Ordinary Differential Equation (ODE) and following the learned flow trajectory. The U-Net’s inherent capacity to process multi-scale information is crucial for accurately capturing the intricacies of the vector field and ensuring high-quality sample generation.
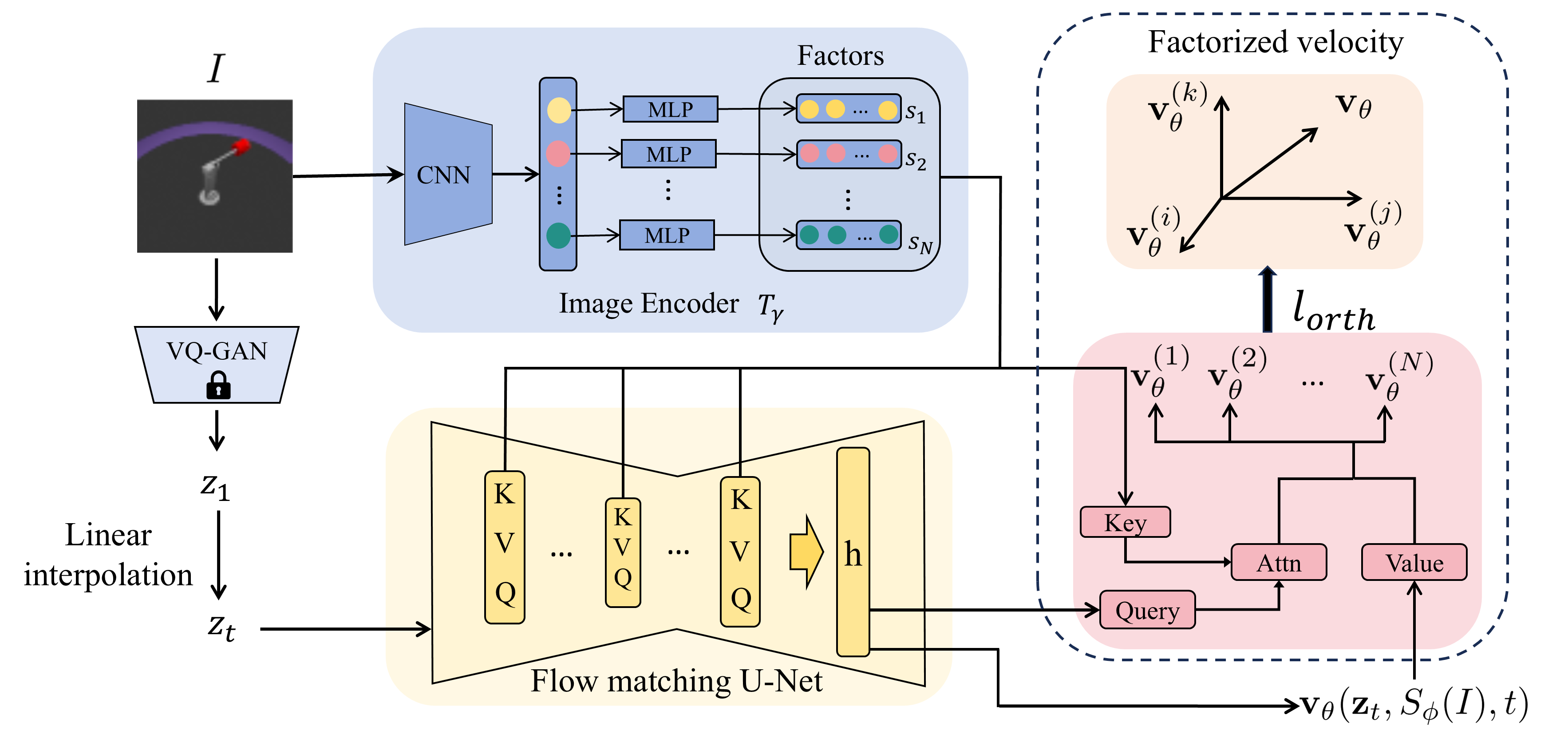
Untangling the Latent Space: Disentanglement in Practice
Orthogonality Regularization, when integrated with Flow Matching, promotes independence between dimensions within the latent space. This is achieved by adding a penalty term to the loss function that encourages the gradients of the latent dimensions to be orthogonal. Specifically, the regularization minimizes the dot product between the gradients of different latent variables, thereby reducing redundancy and ensuring each dimension captures distinct generative factors. This technique improves the model’s ability to disentangle underlying data characteristics, leading to more interpretable and controllable generation processes.
Cross-attention mechanisms within the Flow Matching framework operate by allowing the model to selectively attend to relevant input features at each step of the generative flow. This is achieved by computing attention weights that determine the importance of different input elements when predicting the next state in the latent space. Specifically, queries are derived from the current latent state, while keys and values are computed from the input conditioning information. These attention weights are then used to create a weighted sum of the input features, effectively highlighting the factors most pertinent to the current generative step and improving the model’s capacity to disentangle and control the generation process.
Flow Matching’s effectiveness has been validated through testing on multiple datasets representing different data modalities and complexities. These include the 3D Cars3D dataset, which features realistic car models; Shapes3D, a collection of 3D shapes; MPI3D-toy, a synthetic dataset designed for evaluating disentanglement; and CelebA, a large-scale dataset of celebrity faces. Performance evaluations across these datasets demonstrate the model’s generalizability and ability to learn meaningful representations from varied input data.
Performance of the Flow Matching method was quantitatively assessed using established metrics for generative model evaluation. On the MPI3D-toy dataset, the model achieved a Disentanglement score of 0.649, exceeding the performance of DAVA (0.300) and ClosedForm (0.318). Further evaluation using the FactorVAE score yielded a result of 0.907 on MPI3D-toy, considerably higher than the 0.410 achieved by DAVA and the 0.523 attained by ClosedForm. Additionally, the model demonstrated strong performance as measured by the Frechet Inception Distance (FID), confirming its capacity for high-quality data generation across tested datasets.
Beyond Generation: A Glimpse at the Future
Conditional Flow Matching builds upon existing generative modeling techniques by introducing a mechanism for precise attribute control during the generation process. This advancement moves beyond simply creating realistic samples; it allows researchers to directly manipulate specific characteristics within the generated data. By conditioning the flow on desired attribute values, the model learns to generate samples that not only adhere to the overall data distribution but also reflect the specified traits – for example, altering hair color or pose in an image. This level of control is achieved through a carefully designed training process that encourages the model to disentangle different attributes, ensuring that changes to one attribute do not inadvertently affect others, and ultimately enabling more targeted and customizable data generation.
Flow Matching’s ability to create disentangled representations unlocks powerful applications beyond initial generative modeling. These representations, where distinct factors of variation in the data are isolated, prove invaluable for tasks like image editing, allowing for targeted modifications – changing hair color or adjusting facial expression – without affecting other attributes. Similarly, data imputation benefits significantly; missing information can be reliably filled in by leveraging the learned disentangled structure, effectively reconstructing incomplete datasets. This approach surpasses traditional methods by ensuring that imputed values are consistent with the underlying data distribution and do not introduce spurious correlations, ultimately enhancing the quality and reliability of downstream analyses and applications across diverse fields.
Continued innovation in generative modeling necessitates a deeper exploration of regularization strategies and network designs to refine the disentanglement of learned representations and ultimately improve sample fidelity. Current approaches, while promising, can be further bolstered by investigating novel regularization terms that explicitly encourage independence between latent dimensions, preventing unintended correlations that hinder precise control over generated attributes. Simultaneously, advancements in neural network architecture – such as incorporating attention mechanisms or exploring transformer-based designs – could facilitate the capture of more complex data distributions and enhance the model’s capacity to generate high-quality, diverse samples. Such investigations are poised to unlock even greater potential for Flow Matching and similar frameworks, leading to more robust and controllable generative models with broader applicability across various domains.
The synergistic combination of Flow Matching and disentangled representation learning presents a compelling pathway forward for several core areas of artificial intelligence. Recent results demonstrate this potential, with the approach achieving state-of-the-art Attribute-level Controllability (TAD) scores on the challenging CelebA dataset – signifying unprecedented precision in manipulating specific image characteristics. Beyond controlled generation, this method also exhibits a marked ability to excel in downstream classification tasks, even when training data is scarce, suggesting a robust capacity for generalization and efficient learning. This proficiency positions the technique as a valuable asset in fields like computer vision and robotics, where adaptability and performance under limited supervision are paramount, and hints at broader applications across the artificial intelligence landscape.
The pursuit of disentangled representation learning, as outlined in this work, feels predictably ambitious. It strives for elegant control over generative modeling, hoping to isolate factors of variation in the latent space. However, the orthogonality regularizer, while theoretically sound, introduces yet another layer of complexity destined to encounter the realities of production data. As Donald Knuth observed, “Premature optimization is the root of all evil,” and this relentless drive for perfectly factorized velocity often overshadows the simple truth: if code looks perfect, no one has deployed it yet. The authors aim to improve controllable generation, but inevitably, some unforeseen interaction will surface, proving that even the most carefully crafted latent space isn’t immune to the chaos of real-world inputs.
What Breaks Next?
The pursuit of disentanglement, predictably, reveals itself less as a problem solved and more as a shifting landscape of convenient proxies. This work offers a factorized velocity field – an elegant constraint, certainly – but one built atop the assumption that orthogonality in latent space directly translates to semantic independence. Production systems rarely respect such neat mappings. The inevitable data drift, the unforeseen interactions between factors, will accumulate. Tests, after all, are a form of faith, not certainty.
Future efforts will likely focus not on perfecting the disentanglement within the latent space, but on building systems robust to its imperfections. Expect to see more research into post-hoc disentanglement techniques – methods for salvaging meaningful control from tangled representations. The holy grail isn’t a perfectly factored space; it’s a system that gracefully degrades when the factors inevitably bleed into one another.
One can anticipate a move beyond purely generative modeling, toward architectures that explicitly model the failure modes of disentanglement. What happens when factor A unexpectedly influences factor B? Can the system detect, and compensate for, these violations? The truly interesting problem isn’t building a perfect map, but designing a compass that still points roughly north, even when the magnetic field is chaotic.
Original article: https://arxiv.org/pdf/2602.05214.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- How to Do Sculptor Without a Future in KCD2 – Get 3 Sculptor’s Things
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
2026-02-08 21:58