Author: Denis Avetisyan
New research reveals the significant challenges practitioners face in ensuring data quality meets the demands of evolving regulations like GDPR and the AI Act.
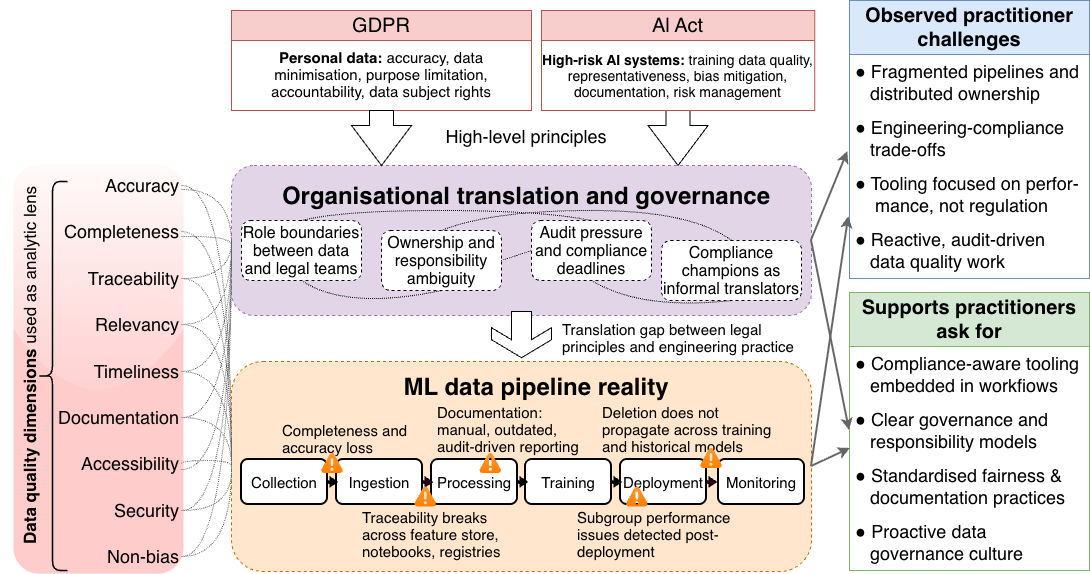
This review explores the disconnect between technical data quality implementation and legal compliance requirements in machine learning systems, advocating for improved collaboration and infrastructure.
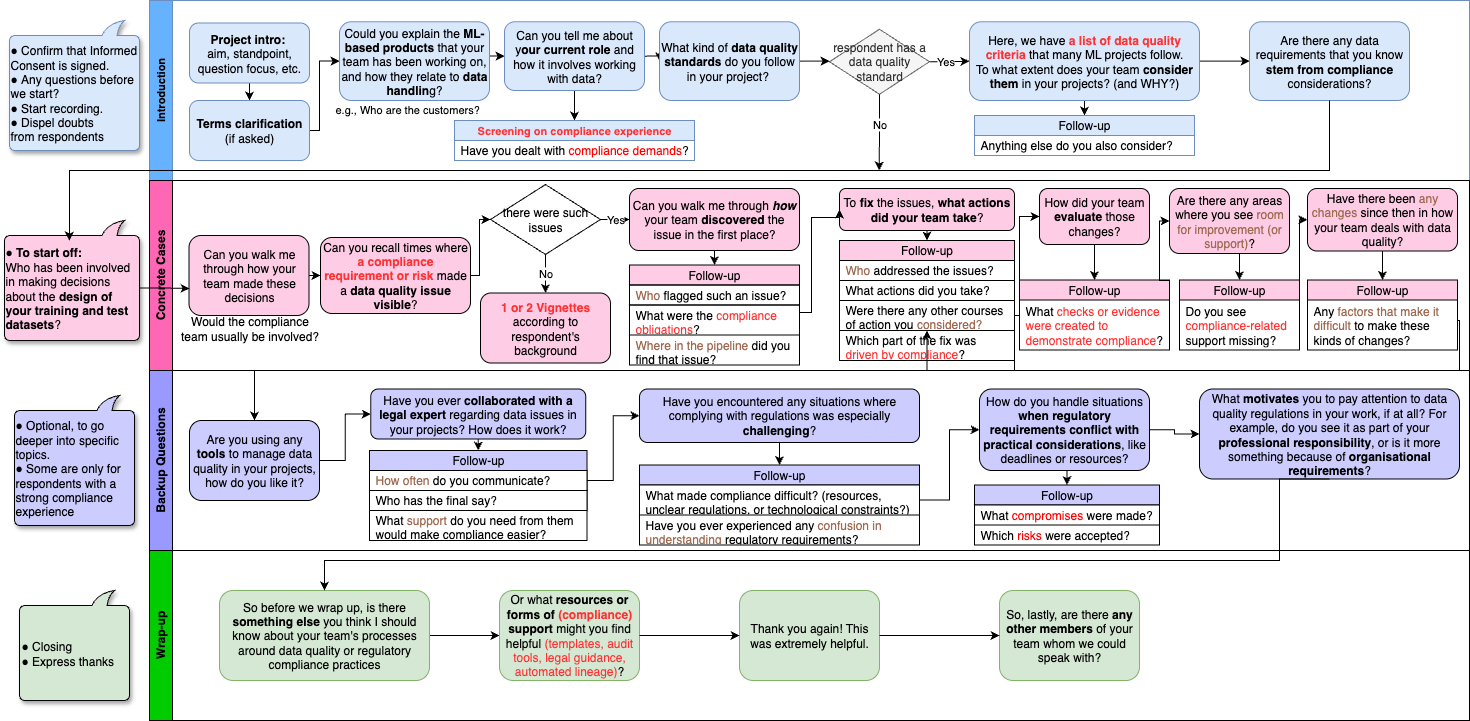
Ensuring data quality is paramount in machine learning, yet increasingly complex regulatory landscapes often place disproportionate burdens on practitioners. This paper, ‘”Detective Work We Shouldn’t Have to Do”: Practitioner Challenges in Regulatory-Aligned Data Quality in Machine Learning Systems’, investigates how those building and deploying ML systems navigate the growing intersection of technical best practices and legal obligations like the GDPR and forthcoming AI Act. Our qualitative study reveals a significant gap between regulatory principles and engineering workflows, stemming from fragmented data pipelines, inadequate tooling, and unclear responsibility boundaries. Can proactive data governance frameworks and compliance-aware infrastructure bridge this divide and alleviate the ‘detective work’ currently demanded of data practitioners?
The Inevitable Tide: Data Governance in an Age of Scrutiny
The performance of modern machine learning systems is inextricably linked to the quality and governance of the data used to train and operate them. However, this reliance on data is occurring amidst a rapidly evolving landscape of legal and ethical scrutiny. Organizations are finding that data practices, once largely unexamined, are now subject to increasing oversight, driven by concerns over privacy, bias, and fairness. This shift necessitates a fundamental re-evaluation of how data is collected, stored, processed, and utilized, demanding greater transparency and accountability throughout the entire machine learning lifecycle. The implications extend beyond mere compliance; proactively addressing these concerns is becoming crucial for maintaining public trust and fostering responsible innovation in artificial intelligence.
The operational landscape for data-driven systems is undergoing a substantial transformation as regulations such as the General Data Protection Regulation (GDPR) and the forthcoming European Union AI Act redefine permissible data practices. This research delves into the practical difficulties organizations encounter when attempting to comply with these evolving legal frameworks, moving beyond theoretical concerns to assess real-world implementation challenges. Through empirical analysis, the study identifies key hurdles in areas like data acquisition, consent management, algorithmic transparency, and data subject rights, revealing a significant gap between regulatory intent and actual practice. The findings demonstrate that navigating this complex web of rules requires not only legal expertise but also substantial investment in new technologies and revised organizational workflows, ultimately impacting the pace of innovation and demanding a proactive approach to data governance.
Non-compliance with evolving data regulations presents substantial risks beyond simple fines; organizations failing to adhere to frameworks like GDPR and the proposed AI Act face potentially crippling legal penalties and lasting damage to public trust. This erosion of trust can significantly hinder innovation, as consumers and partners become hesitant to engage with entities perceived as careless with sensitive information. Beyond immediate financial repercussions, reputational harm can translate into lost market share, diminished investment opportunities, and increased difficulty in attracting and retaining talent, creating a cascading effect that stifles long-term growth and the development of new, data-driven solutions. The cost of remediation, including legal fees, system overhauls, and public relations efforts, further compounds these challenges, demonstrating that proactive compliance isn’t merely a legal obligation, but a strategic imperative for sustained success.
Data’s Lifecycle: Building Resilience Through Governance
Robust data governance frameworks define the organizational rules and responsibilities for data assets, encompassing data quality, access control, and security protocols. These policies address the entire data lifespan – from creation and acquisition through storage, usage, archiving, and eventual disposal. Implementation typically involves establishing data stewardship roles, defining data standards, and creating processes for data validation, auditing, and compliance with relevant regulations such as GDPR or CCPA. Effective governance minimizes risks associated with inaccurate, incomplete, or improperly managed data, and ensures data is utilized consistently and ethically across the organization.
Effective Data Lifecycle Management (DLM) encompasses the processes and policies governing data from creation or acquisition through its eventual retirement. DLM directly impacts Data Quality by establishing controls at each stage – including ingestion, storage, usage, archiving, and deletion – to prevent degradation and ensure accuracy. Specifically, DLM procedures define data validation rules, error handling protocols, and data transformation processes, minimizing inconsistencies and inaccuracies. Furthermore, a well-defined DLM strategy incorporates data retention policies aligned with regulatory requirements and business needs, facilitating compliance and reducing legal risk. Proper archival procedures, as part of DLM, preserve data integrity for long-term access, while secure deletion methods mitigate data breach potential.
Data validation and documentation are essential components of data management, directly impacting data usability and compliance. Data validation, encompassing checks for accuracy, completeness, and consistency, should occur at multiple stages – ingestion, processing, and storage – to prevent propagation of errors. Comprehensive documentation, including data dictionaries defining data elements, lineage tracing data origins and transformations, and metadata detailing data quality rules, is critical for understanding data context and ensuring auditability. These proactive measures enable data consumers to assess data fitness for specific purposes and facilitate regulatory compliance by providing a clear record of data handling practices.
Tracing the Threads: Establishing Data Provenance
Data provenance, encompassing the complete lifecycle of a dataset from origin through all transformations, is increasingly critical for regulatory adherence and model reliability. Several legal frameworks, including GDPR, CCPA, and industry-specific regulations like those governing financial reporting and healthcare, mandate demonstrable data lineage. Establishing provenance involves recording metadata detailing data sources, applied transformations – including algorithms, parameters, and personnel involved – and access controls. This detailed history enables auditing to verify data integrity, identify the root cause of errors, and validate model outputs, fostering trust among stakeholders and ensuring accountability for data-driven decisions. Without robust provenance tracking, organizations risk non-compliance, reputational damage, and inaccurate analytical results.
Detailed records of data transformations – including specific algorithms applied, parameter settings, and the personnel responsible – are fundamental to bias detection and accountability. Each transformation introduces potential for systematic error; documenting these steps allows for thorough examination of how biases may have been introduced or amplified during data processing. This documentation must extend beyond simply noting the transformation; it requires recording the precise input data state, the transformation logic, and the resulting output data state. Maintaining this level of granularity enables reproducibility of analyses, facilitates auditing for compliance, and provides a clear audit trail for identifying and rectifying errors or biases that impact model performance and decision-making.
Detailed data provenance records are foundational to effective risk management strategies. By tracking data origins, transformations, and access history, organizations can identify vulnerabilities and potential points of failure within their data pipelines. This granular level of insight enables proactive mitigation of risks related to data integrity, compliance, and security. Furthermore, in the event of a data breach or the discovery of data quality issues, a clear provenance trail drastically reduces investigation time and facilitates targeted remediation. The ability to quickly pinpoint the source of compromised or inaccurate data minimizes impact, reduces associated costs, and supports efficient recovery efforts, thereby bolstering overall organizational resilience.
The Weight of Responsibility: Towards Ethical AI Systems
Data minimization and purpose limitation stand as foundational tenets in the responsible development of artificial intelligence systems. These principles dictate that only the strictly necessary data should be collected from users, and that data can only be utilized for the explicitly stated and legitimate purposes for which it was gathered. Adhering to these guidelines isn’t merely a matter of legal compliance, but a proactive step towards safeguarding individual privacy and mitigating potential harms stemming from data breaches, misuse, or unforeseen algorithmic consequences. By limiting data collection to what is essential and strictly defining its usage, organizations can significantly reduce the risk of discriminatory outcomes, protect sensitive information, and build greater trust with those whose data fuels these increasingly powerful technologies. This approach minimizes the “attack surface” for malicious actors and lessens the potential for unintended negative impacts, fostering a more ethical and sustainable path for AI innovation.
Machine learning models, while powerful, are susceptible to perpetuating and even amplifying existing societal biases present within the data used to train them. Consequently, bias mitigation techniques are now essential components in responsible AI development. These methods range from pre-processing data to remove or re-weight biased samples, to in-processing algorithms that constrain model learning to avoid discriminatory outcomes, and post-processing adjustments to calibrate model predictions for fairness. Researchers are actively exploring various approaches, including adversarial debiasing, fairness-aware regularization, and counterfactual data augmentation, to address different forms of bias – such as statistical parity difference and equal opportunity difference – and ensure that AI systems treat all individuals and groups equitably, regardless of sensitive attributes. Effectively implementing these techniques is not merely a technical challenge; it requires a deep understanding of the societal context, careful evaluation of fairness metrics, and ongoing monitoring to prevent unintended consequences.
Organizations seeking to fully realize the benefits of artificial intelligence must proactively integrate ethical considerations and establish robust data governance frameworks. Recent research, grounded in empirical analysis of practitioners, reveals a significant gap between aspirational AI ethics and practical implementation, often stemming from inadequate organizational structures and unclear lines of accountability. This analysis demonstrates that prioritizing fairness, transparency, and privacy isn’t merely a matter of compliance, but a critical driver of trust – both internally among developers and externally with end-users. By addressing these organizational challenges and fostering a culture of responsible innovation, companies can mitigate risks, unlock the true potential of AI, and ensure its benefits are widely shared, ultimately building systems that are not only intelligent, but also trustworthy and aligned with societal values.
The pursuit of regulatory-aligned data quality, as detailed in the study, reveals a system inherently susceptible to decay. The effort to maintain compliance-establishing robust data pipelines and governance frameworks-faces inevitable entropy. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” This speaks to the constant activity required to detect and correct data quality issues – a restless pursuit mirroring the human condition. The article highlights the ‘detective work’ needed, a continual process of uncovering and addressing flaws before they manifest as regulatory breaches. Just as Pascal suggests inner stillness is elusive, maintaining pristine data quality proves to be an equally challenging, ongoing endeavor. Any improvement, however diligently implemented, ages faster than expected, necessitating persistent monitoring and adaptation.
The Long Refactoring
The work detailed within reveals a fundamental truth about complex systems: the map is never the territory, especially when that territory is subject to shifting legal landscapes. Data quality, treated as a purely technical problem, is revealed to be a translation layer-a constant attempt to render abstract regulation into concrete implementation. This is not a failure of engineering, but an inherent property of attempting to impose external order on intrinsically messy systems. Versioning data pipelines becomes a form of institutional memory, each iteration a tacit acknowledgement that complete compliance is an asymptote, not a destination.
Future efforts will likely focus on automating this translation, building ‘regulatory-aware’ data governance tools. However, such tools risk becoming brittle abstractions, failing to account for the inevitable ambiguity within the laws themselves. The true challenge lies not in eliminating the detective work, but in accepting it as a perpetual cost of operation. The arrow of time always points toward refactoring, and in this domain, that refactoring is driven not by performance gains, but by the slow creep of legal interpretation.
Ultimately, the field must move beyond the question of whether a system is compliant, and begin to grapple with the degree to which it demonstrates compliance. Auditing, lineage tracking, and explainability are not merely features; they are the scaffolding upon which trust-and ultimately, legitimacy-is built. The system doesn’t age gracefully if it hides its own decay.
Original article: https://arxiv.org/pdf/2602.05944.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
- Brent Oil Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
2026-02-07 13:59