Author: Denis Avetisyan
This review explores the emerging field of graph-based memory systems designed to equip AI agents with the ability to learn, adapt, and retain information over extended periods.
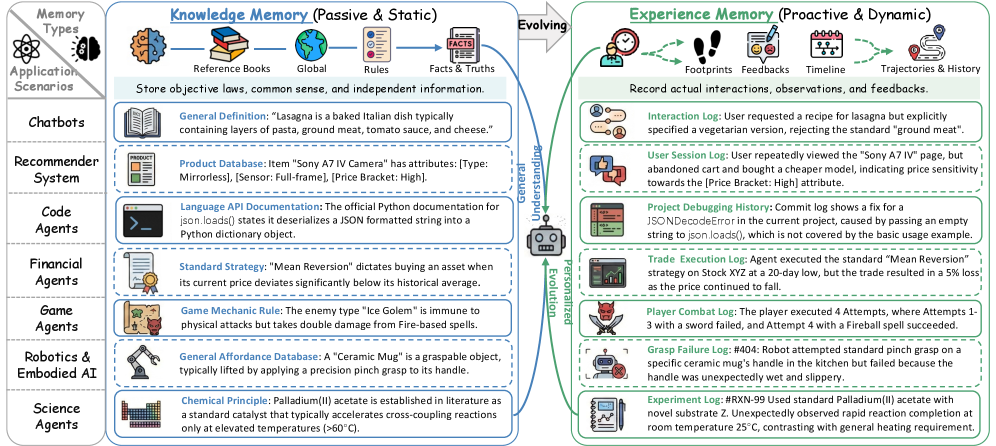
A comprehensive survey of graph neural network architectures, techniques, and applications for building robust and scalable long-term memory in language-based agents.
Effective long-horizon reasoning in large language model (LLM) agents requires robust memory capabilities, yet organizing and retrieving relevant information remains a key challenge. This survey, ‘Graph-based Agent Memory: Taxonomy, Techniques, and Applications’, provides a comprehensive overview of how graph structures are leveraged to address this need, offering a powerful approach to knowledge representation and efficient memory access. By categorizing memory types, analyzing core techniques-including extraction, storage, retrieval, and evolution-and highlighting open-source resources, the authors demonstrate the potential of graph-based systems for building more adaptable and intelligent agents. Will this paradigm unlock the next generation of truly self-improving, knowledge-driven AI systems?
The Limits of Sequential Thought: Why LLMs Struggle with True Understanding
Despite their remarkable abilities in generating human-quality text, Large Language Models frequently falter when confronted with reasoning challenges that demand sustained memory and the comprehension of relationships between disparate pieces of information. These models, trained to predict the next token in a sequence, excel at pattern recognition within immediate contexts but struggle to maintain and effectively utilize knowledge acquired earlier in a conversation or document. This limitation manifests as difficulties in tasks requiring multi-step inference, common-sense reasoning, or the integration of facts presented non-sequentially. Essentially, while proficient at what is said, LLMs often lack a robust grasp of why it is said, hindering their capacity for true understanding and complex problem-solving – a clear indication that scaling sequential processing alone is insufficient for achieving genuine artificial intelligence.
Current Large Language Models often process information in a linear, sequential manner, much like reading a book from beginning to end. This approach, while effective for certain tasks, presents limitations when dealing with knowledge that is inherently interconnected. The model struggles to efficiently represent relationships between pieces of information, hindering its ability to draw nuanced conclusions or apply relevant context to complex reasoning problems. Unlike human cognition, which readily associates concepts and accesses information through a vast network of connections, the sequential method requires the model to repeatedly re-process information, creating a bottleneck that impacts performance on tasks demanding comprehensive understanding and contextual awareness. This inability to leverage relational knowledge ultimately restricts the model’s capacity for sophisticated thought and problem-solving.
The limitations of current large language models often stem from a fundamental disparity in how information is organized and accessed compared to human cognition. While LLMs excel at processing sequential data, they struggle to replicate the brain’s associative memory – a richly interconnected network where concepts are linked not by order, but by relationships. Encoding information in this manner presents a significant challenge; simply storing data as a linear sequence fails to capture the nuanced connections that enable humans to effortlessly retrieve relevant knowledge based on context and similarity. This difficulty in mirroring the brain’s associative structure hinders a model’s ability to perform complex reasoning, draw inferences, and generalize knowledge to novel situations, as it lacks the capacity to efficiently navigate and utilize the web of relationships inherent in true understanding.
Relational Memory: A Graph-Based Foundation for Intelligent Agents
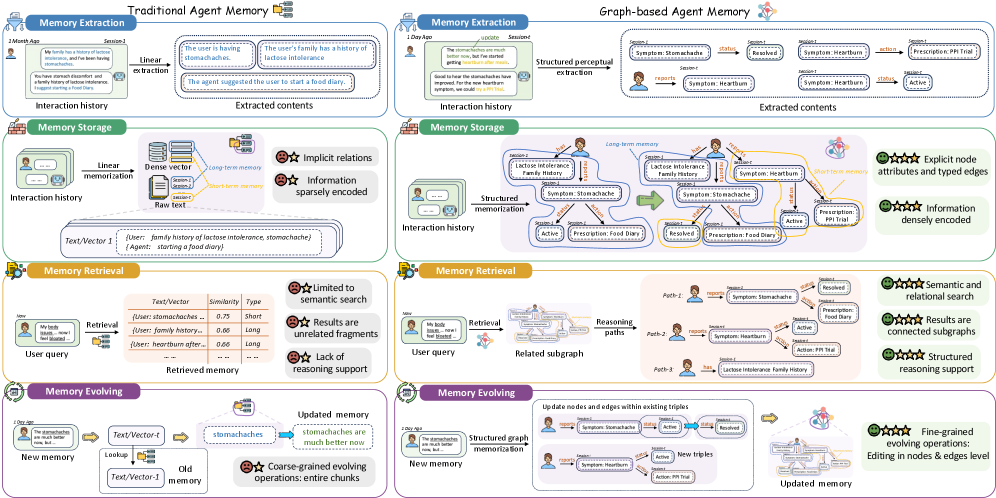
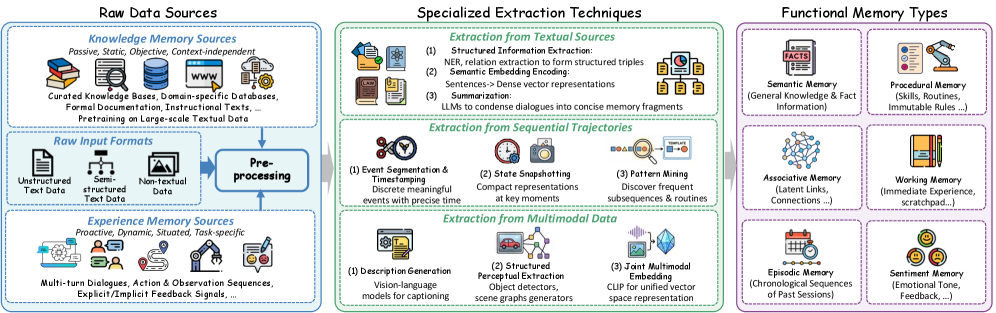
Graph-Based Memory utilizes a network structure to represent knowledge, fundamentally differing from traditional methods like vector databases. In this approach, individual pieces of information are defined as entities – discrete objects or concepts – and the connections between them are explicitly defined as relationships. This mirrors the structure of semantic networks developed in cognitive science, where knowledge is organized around nodes representing concepts and edges representing associations. This relational structure allows for efficient traversal and retrieval of information based on connections, enabling the system to move beyond simple keyword matching and understand the context of the data. The explicit representation of relationships facilitates reasoning and inference, as the system can identify patterns and connections between entities that might not be apparent in unstructured data.
Graph-based memory builds upon the established principles of Knowledge Graphs by representing information as nodes (entities) connected by edges (relationships). This structure facilitates efficient storage and retrieval because relationships are explicitly defined, enabling traversal and inference beyond simple keyword searches. Unlike traditional databases relying on rigid schemas, graph databases offer flexibility in defining and evolving relationships between entities. Data is accessed via graph traversals, which have a logarithmic time complexity for finding related information, significantly improving performance when querying interconnected data compared to relational databases requiring joins. This efficiency is particularly valuable for LLM agents requiring access to complex, relational knowledge for reasoning and decision-making.
Beyond traditional knowledge graphs which represent relationships as binary connections between entities, graph-based memory utilizes more expressive structures like Temporal Graphs and Hypergraphs. Temporal Graphs incorporate time as a dimension, allowing the representation of evolving relationships and historical context; edges are timestamped to indicate when a relationship was active. Hypergraphs extend the model further by enabling relationships to connect more than two entities simultaneously; a single edge can connect multiple nodes, representing n-ary relationships and complex interactions. This capability is crucial for modeling scenarios where relationships aren’t simply pairwise, such as collaborative projects involving multiple participants or complex chemical reactions with several reactants and products. The use of these advanced graph structures enables a more complete and nuanced representation of knowledge compared to standard knowledge graphs.
By structuring knowledge as interconnected entities and relationships, graph-based memory enables LLM Agents to move beyond simple keyword-based retrieval. This allows agents to access information based on the relationships between concepts, not just the concepts themselves. Consequently, agents can perform more nuanced reasoning by considering the context surrounding information – for example, understanding that a relationship existed at a specific time (temporal graphs) or involves multiple entities simultaneously (hypergraphs). This relational access supports improved performance in tasks requiring inference, disambiguation, and the application of common-sense knowledge, as the agent can traverse the graph to find relevant connections and derive new insights.
The Agent Interaction Loop: Retrieving, Reasoning, and Memory Consolidation
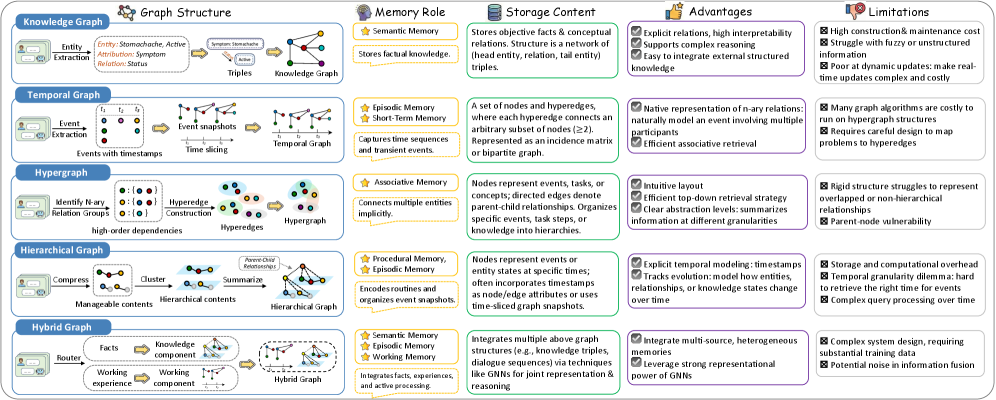
The Agent Interaction Loop defines the sequential process by which the LLM Agent accesses and utilizes the Graph-Based Memory. At each discrete time step, the agent doesn’t simply process inputs but actively engages with the memory system. This loop begins with a query formulated based on the current state and objectives. The subsequent retrieval of relevant nodes and edges from the graph provides contextual information. This retrieved information is then incorporated into the prompt, influencing the LLM’s reasoning process. Finally, the output of this reasoning – potentially new information or insights – is used to update the Graph-Based Memory, completing the cycle and preparing the agent for the next iteration. This iterative process ensures that the agent’s actions are informed by past experiences and allows for continuous adaptation.
The Memory Retrieval and Update processes are core components of the agent’s interaction loop. Memory Retrieval involves querying the graph-based memory using the current context to identify relevant nodes and edges; the specific query method depends on the implementation, but generally involves semantic similarity searches. Retrieved information is then utilized to augment the prompt given to the Large Language Model (LLM). Following reasoning by the LLM, Memory Update incorporates newly derived knowledge back into the graph. This is achieved by creating new nodes and edges that represent the learned information, effectively expanding the agent’s knowledge base and enabling future retrieval of this information.
Prompt conditioning is the process of integrating retrieved information from the graph-based memory directly into the prompt provided to the Large Language Model (LLM). This technique is essential because LLMs have a limited context window; directly including relevant memories ensures the model has access to necessary data for informed decision-making. The conditioning process involves formulating the prompt in a manner that effectively presents the retrieved information, typically by including it as context or instructions. Effective prompt conditioning improves the accuracy and relevance of the LLM’s responses by grounding its reasoning in factual data, and prevents reliance on potentially inaccurate or outdated internal knowledge. The method of incorporation – whether through direct text insertion, structured formatting, or instruction-based guidance – significantly impacts the LLM’s ability to utilize the retrieved memory.
The agent’s iterative interaction with its graph-based memory facilitates continuous learning and adaptation by repeatedly refining its internal representation of the environment. Each cycle of retrieval, reasoning, and memory update allows the agent to incorporate new information and adjust existing knowledge based on observed outcomes. This process isn’t simply data accumulation; the agent actively integrates retrieved information into its reasoning process, effectively modifying its understanding and subsequent actions. Consequently, the agent’s performance improves over time as it builds a more nuanced and accurate model of its operating environment, enabling it to respond more effectively to evolving conditions and complex challenges.
Demonstrated Performance and Future Directions in Relational AI
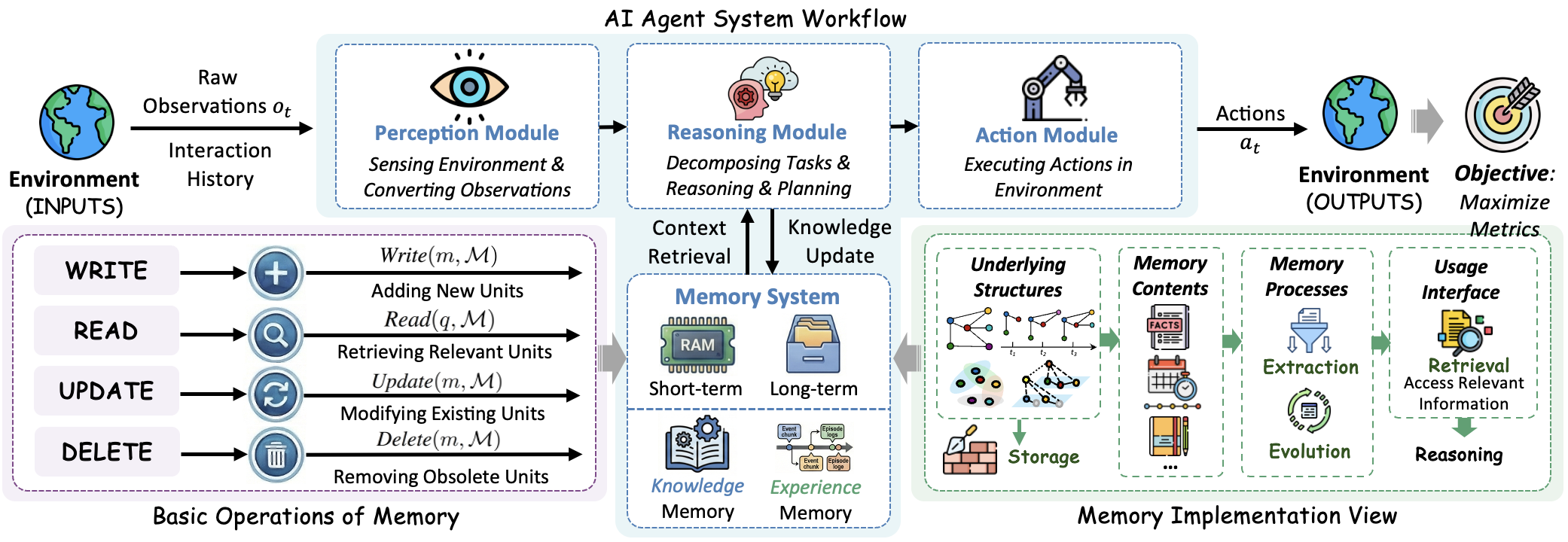
Recent studies reveal a substantial performance increase in Large Language Model (LLM) agents when equipped with Graph-Based Memory for tackling complex reasoning tasks. Empirical evaluations consistently demonstrate that this integration significantly boosts Task Success Rate compared to traditional memory approaches. By structuring information as interconnected nodes and relationships, the system enables agents to navigate knowledge more effectively, draw nuanced inferences, and maintain contextual awareness throughout problem-solving. This improvement isn’t merely incremental; agents utilizing graph-based memory exhibit a marked ability to handle multi-step reasoning, overcome ambiguities, and ultimately achieve higher rates of successful task completion – suggesting a critical step toward more robust and reliable artificial intelligence.
The system demonstrably improves an agent’s ability to locate pertinent information, a critical factor in complex task completion. By leveraging a graph-based memory, the agent doesn’t simply store data, but organizes it relationally, allowing for more nuanced and effective searches. This enhanced retrieval effectiveness moves beyond keyword matching, enabling the agent to identify information based on conceptual connections and context. Consequently, the agent consistently accesses the knowledge it needs, even when queries are ambiguous or require inferential reasoning, leading to more reliable performance and a reduction in errors stemming from information scarcity or misinterpretation.
Assessing the efficacy of an agent’s memory extends beyond simply measuring recall; a crucial indicator of memory quality is its structural coherence and completeness, termed Graph Structural Quality. This metric evaluates how well the knowledge within the graph is interconnected and whether it comprehensively represents the relevant information for the task at hand. A high Graph Structural Quality suggests that concepts are logically linked, enabling efficient traversal and reasoning, while a fragmented or incomplete structure can hinder the agent’s ability to synthesize information and arrive at accurate conclusions. Therefore, optimizing for this quality is paramount in building robust agents capable of complex reasoning and reliable performance, as it directly impacts the agent’s capacity to learn, adapt, and effectively utilize its stored knowledge.
Ongoing investigations are directed towards refining the foundational architecture of agent memory through the implementation of more nuanced graph structures, moving beyond simple node-and-edge representations to incorporate concepts like knowledge hierarchies and relational embeddings. Crucially, future work prioritizes the development of adaptive memory update mechanisms, allowing agents to dynamically refine their internal knowledge graphs – strengthening relevant connections, pruning outdated information, and proactively seeking new data to address knowledge gaps. This focus on continual learning aims to move beyond static memory stores, fostering agents capable of robust performance in evolving environments and complex, long-horizon tasks, ultimately enabling more reliable and insightful artificial intelligence systems.
The pursuit of robust agent memory, as detailed in this survey of graph-based techniques, necessitates a commitment to verifiable foundations. Grace Hopper aptly stated, “It’s easier to ask forgiveness than it is to get permission.” This sentiment resonates with the article’s core idea; exploring diverse graph architectures and memory retrieval methods isn’t about seeking pre-approval, but rather, iteratively building and testing solutions. The paper champions a move beyond merely achieving functional results and toward provable correctness in long-term memory systems, ensuring these agents are not black boxes but transparent, reliable entities capable of continual learning and adaptation.
What Lies Ahead?
The proliferation of techniques marrying graph structures with large language models-a superficially elegant coupling-has, predictably, not resolved the fundamental issue of true intelligence. Current approaches largely address symptoms of limited memory and contextual understanding, rather than the underlying problem of knowledge representation and scalable inference. The field remains fixated on retrieval speed, a metric ultimately meaningless if the retrieved information lacks semantic coherence or is improperly contextualized. A truly robust agent memory demands more than just efficient graph traversal; it requires a formal, provable framework for knowledge consistency and error propagation.
Future progress will hinge not on increasingly complex neural architectures, but on a return to first principles. The emphasis must shift from simply ‘scaling up’ existing methods to developing formal languages for representing agent beliefs and reasoning processes. The current reliance on distributional semantics-essentially, pattern matching-is a dead end. A mathematically rigorous approach to knowledge graphs, one that guarantees logical consistency and allows for verifiable inference, is paramount. The ambition should be a system where every ‘memory’ is a theorem, and every action is a logically derived consequence.
Ultimately, the challenge is not building a larger memory, but a correct one. Until the field prioritizes formal verification over empirical performance, these graph-based agents will remain sophisticated, but fundamentally brittle, approximations of genuine intelligence.
Original article: https://arxiv.org/pdf/2602.05665.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
- Brent Oil Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
2026-02-07 12:18