Author: Denis Avetisyan
Researchers are using evolutionary algorithms to discover novel activation functions that enhance the ability of neural networks to generalize to unseen data.
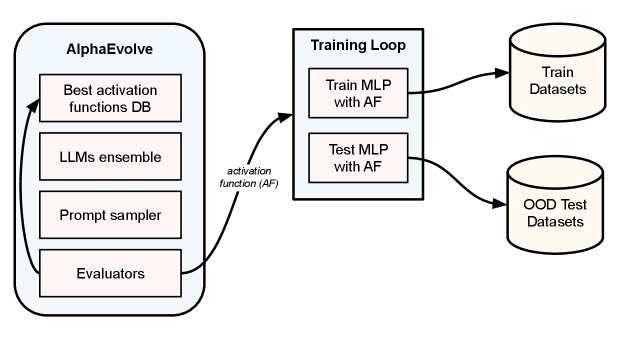
This review details an approach to mining activation functions using synthetic data and chaotic systems to improve out-of-distribution generalization and robustness in neural networks.
Despite advances in neural network architectures, selecting effective activation functions remains a persistent challenge, often requiring manual design or limited search spaces. This paper, ‘Mining Generalizable Activation Functions’, proposes an evolutionary search framework leveraging modern pipelines-such as those employing large language models-to discover novel activations that extend beyond performance gains. Specifically, the authors demonstrate that evolving activations with a focus on out-of-distribution generalization-even using relatively small synthetic datasets informed by chaotic systems-can yield functions encoding desirable inductive biases. Could this approach unlock a new paradigm for systematically designing neural network components tailored to specific data characteristics and robustness requirements?
The Limits of What We Expect
Despite achieving remarkable success on benchmark datasets like ImageNet, conventional convolutional neural networks-including architectures such as VGGNetwork and ResNet50-demonstrate a significant vulnerability when confronted with data differing substantially from their training distribution. This limitation arises from their inherent inductive biases, specifically their reliance on translational equivariance and locality, which, while effective for images, prove less adaptable to the nuances of real-world data. When presented with out-of-distribution examples-images exhibiting altered viewpoints, novel object categories, or corrupted data-these networks often exhibit a precipitous drop in performance, highlighting a lack of robust generalization capability. The rigid feature hierarchies learned during training on ImageNet fail to transfer effectively, underscoring the need for more flexible and adaptable architectures capable of navigating the complexities of unseen data distributions.
Conventional deep learning architectures, predominantly designed for grid-like data such as images, encounter significant hurdles when applied to non-Euclidean datasets. Molecular structures, for example, are inherently graph-based, representing atoms as nodes and bonds as edges – a format fundamentally different from the regular grids processed by convolutional networks. This inflexibility restricts their ability to effectively capture the complex relationships crucial for predicting molecular properties, as demonstrated by challenges with datasets like OOBG_MolHIV_Dataset. Consequently, performance suffers because these models struggle to generalize beyond the assumptions inherent in their Euclidean-centric design, necessitating the development of novel architectures capable of natively processing irregular data structures and unlocking advancements in fields like drug discovery and materials science.
Automated Alchemy: Evolving Beyond Hand-Crafted Solutions
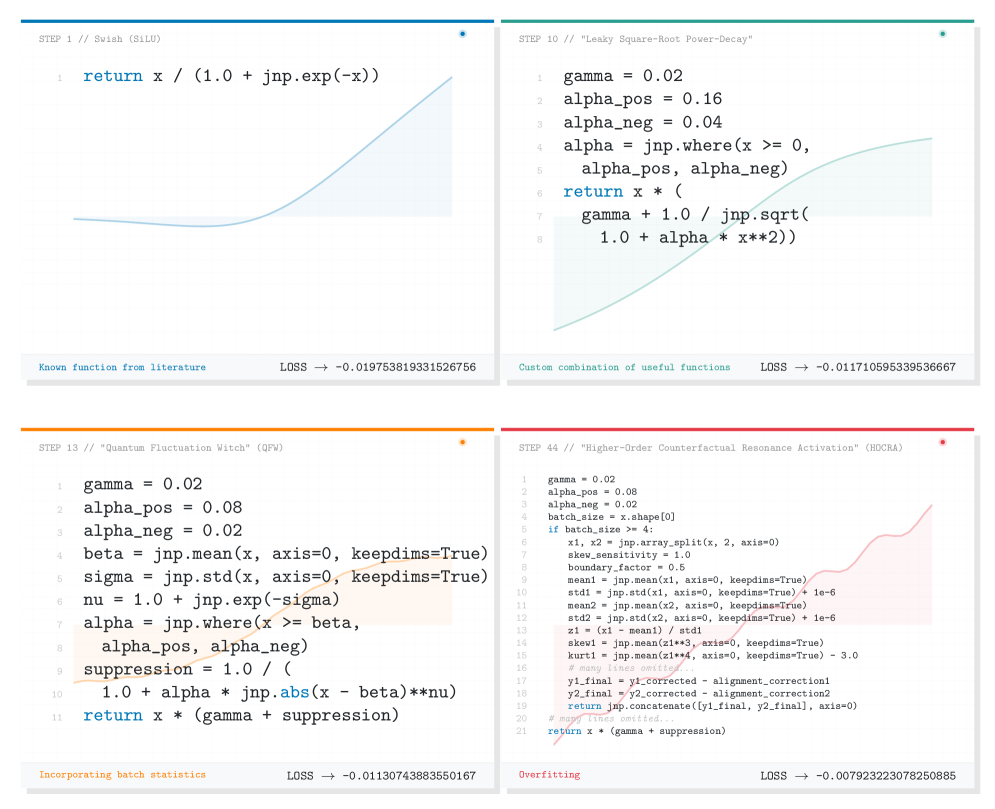
AlphaEvolve is an evolutionary algorithm designed to automate the discovery of novel activation functions for neural networks. Unlike manual design or random search, AlphaEvolve utilizes a genetic algorithm framework, iteratively evolving a population of candidate functions based on their performance on specified training datasets. Each function is represented as a computational graph, and operations like addition, multiplication, and trigonometric functions are combined to create diverse activation expressions. The algorithm employs a fitness function to evaluate each candidate, selecting and combining the highest-performing functions through processes analogous to natural selection, crossover, and mutation. This process allows AlphaEvolve to explore a vast design space and identify activation functions that outperform traditional options like GELU in certain scenarios, offering a data-driven approach to activation function engineering.
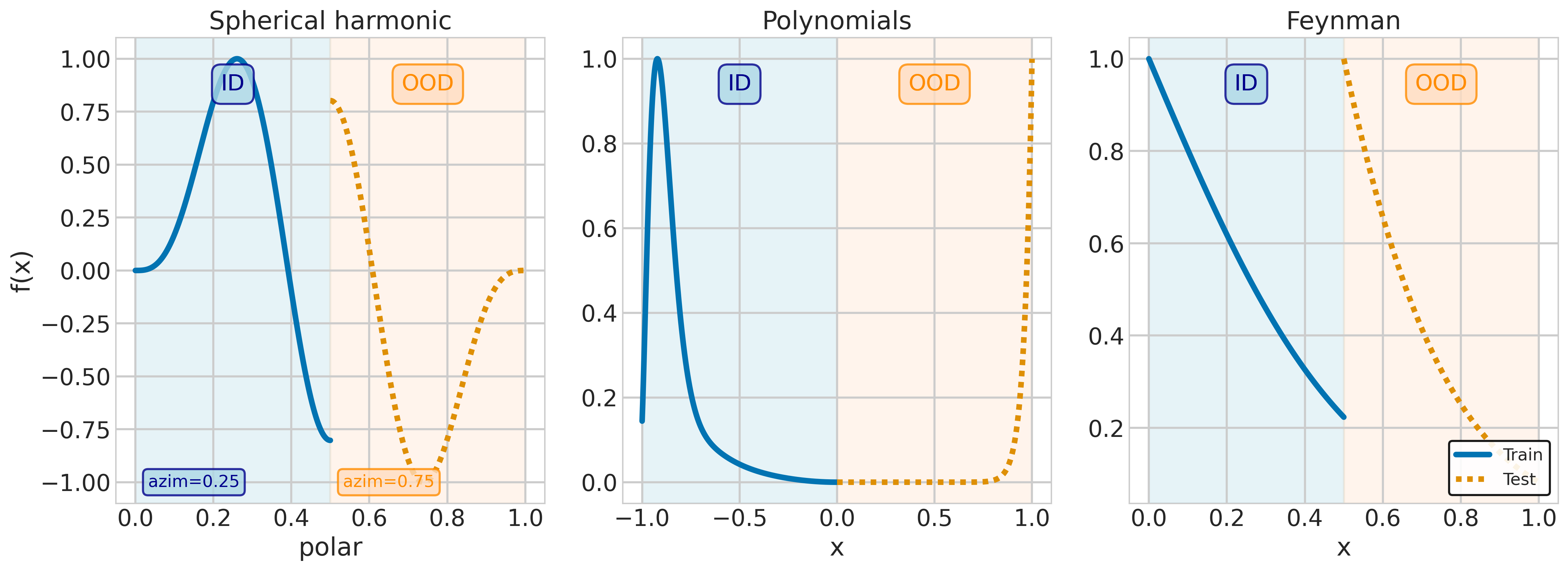
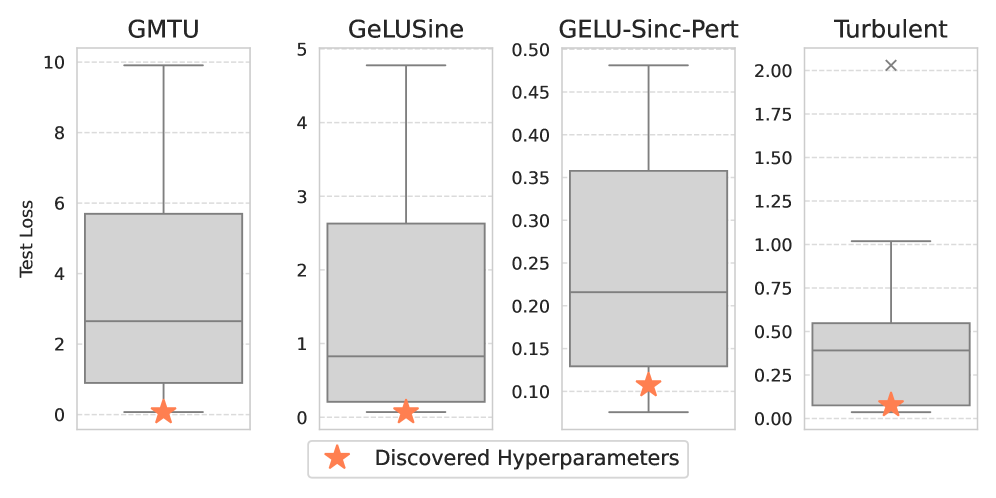
TurbulentActivation and PhaseLockedEntropicRepulsion represent novel activation functions generated through the AlphaEvolve framework. These functions were specifically designed to enhance model robustness and expressiveness by optimizing performance on challenging datasets. TurbulentActivation introduces a dynamic, data-dependent behavior, while PhaseLockedEntropicRepulsion aims to maximize information flow and prevent vanishing gradients. Both functions deviate from traditional activation functions like ReLU or GELU in their mathematical formulation and were identified through an evolutionary process prioritizing performance on datasets such as RandomPolynomialsDataset, FeynmanEquationsDataset, and SphericalHarmonicsDataset.
TurbulentActivation and PhaseLockedEntropicRepulsion were evaluated on synthetic datasets designed to challenge model generalization capabilities. Specifically, performance was measured on the RandomPolynomialsDataset, which tests extrapolation and polynomial fitting; the FeynmanEquationsDataset, requiring the solution of physics-based equations; and the SphericalHarmonicsDataset, assessing the ability to model complex, multi-dimensional functions. Reported results from AlphaEvolve training indicate that these novel activation functions demonstrate improved performance on these datasets compared to traditional activation functions, suggesting enhanced robustness and expressiveness in handling complex mathematical relationships.
Putting It To The Test: Evidence Across Diverse Benchmarks
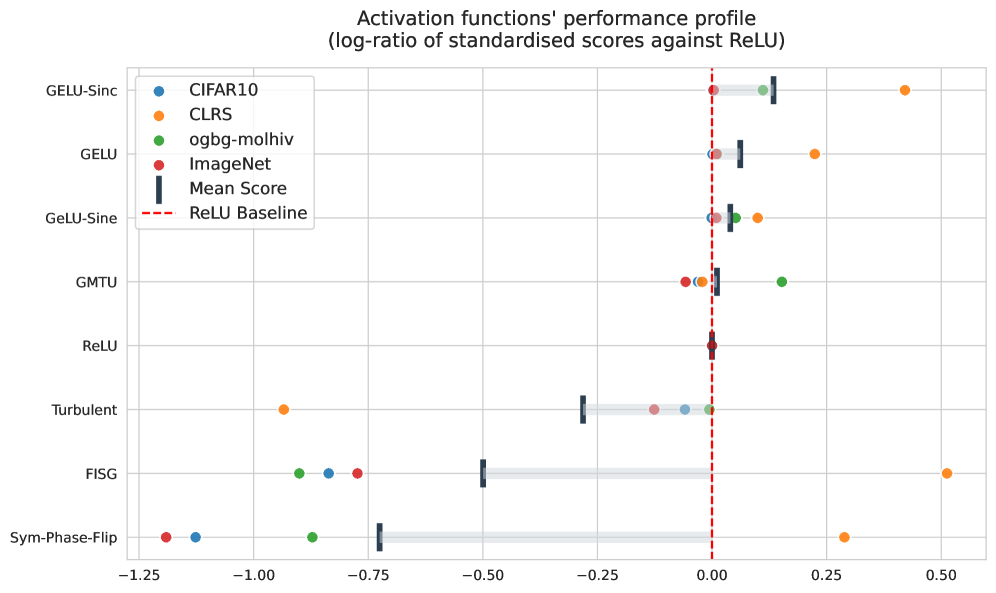
Combined application of TurbulentActivation and PhaseLockedEntropicRepulsion with the GELUSine activation function yields substantial improvements in image classification performance, as evidenced by results on the CIFAR10Dataset. Specifically, this combination demonstrates an enhanced capacity to accurately categorize images within this benchmark dataset. Performance gains are quantitatively measured through established metrics such as accuracy and F1-score, indicating a statistically significant improvement over baseline models utilizing standard activation functions. The synergistic effect observed suggests that the combined activations facilitate more efficient feature extraction and representation learning within the convolutional neural network architecture used for image classification.
Performance evaluations using the CLRS30Dataset demonstrate that the combined use of TurbulentActivation and PhaseLockedEntropicRepulsion yields competitive results, suggesting enhanced algorithmic reasoning capabilities. Validation of this improvement is supported by the application of the TripletGMPNN model to the dataset. Specifically, the activation functions facilitate improved performance on tasks requiring logical deduction and problem-solving as presented within the CLRS30Dataset, positioning the model favorably against existing benchmarks in algorithmic reasoning.
Evaluations utilizing the OOBG_MolHIV_Dataset demonstrate the generalization capabilities of the combined activation functions beyond traditional image and algorithmic benchmarks. Reported performance metrics indicate competitive results on this molecular dataset, suggesting the approach is not limited to specific data modalities. This competitive performance on molecular data, which requires different feature representations and reasoning than image or algorithmic tasks, highlights the potential of this activation function combination to improve model performance across a broader range of applications and data types.
Beyond The Hype: Implications for Truly Adaptable AI
The emergence of AlphaEvolve as a successful innovator in activation function discovery underscores a pivotal shift toward automated machine learning (AutoML) as a driving force in artificial intelligence research. Historically, the design of these crucial components within neural networks has relied heavily on human intuition and trial-and-error. However, AlphaEvolve’s ability to autonomously generate functions that outperform hand-crafted alternatives demonstrates the power of algorithms to explore the vast design space more efficiently and effectively. This success suggests that AutoML is not merely a tool for optimizing existing models, but a fundamental methodology capable of discovering novel architectural elements. The implications extend beyond activation functions; this approach hints at the possibility of automating the design of entire neural network structures, potentially accelerating progress across diverse AI applications and fostering the creation of more adaptable and generalizable systems.
The performance of deep learning models is fundamentally constrained by the activation functions that introduce non-linearity, and recent research indicates that optimizing these components is paramount to achieving significant advancements. While much attention has been given to network architecture and training methodologies, activation functions often remain relatively unexplored; however, the discovery of novel, robust functions – like those found through automated machine learning approaches – demonstrates a clear pathway to improved generalization and adaptability. These functions govern the signal propagation within neural networks, directly impacting a model’s ability to learn complex patterns and respond to unseen data; therefore, prioritizing their design allows for the creation of more efficient, powerful, and versatile deep learning systems, potentially overcoming limitations inherent in currently dominant architectures and unlocking the full capabilities of artificial neural networks.
The pursuit of adaptable and generalizing artificial intelligence represents a significant departure from the current trend of highly specialized architectures. Rather than designing systems narrowly tailored to specific tasks, future AI development can prioritize core principles of robustness and broad applicability. This approach promises systems less brittle when confronted with novel situations and capable of transferring learned knowledge across diverse domains. Such versatile AI wouldn’t require extensive retraining for each new challenge, instead leveraging underlying principles to efficiently acquire and apply skills – ultimately paving the way for truly intelligent systems that can tackle a wider range of real-world problems with greater efficiency and resilience.
The pursuit of novel activation functions, as detailed in this work, feels predictably optimistic. It’s a classic case of seeking elegant solutions to problems production systems will inevitably contort. This research attempts to improve out-of-distribution generalization – a noble goal, certainly – but history suggests even the most robustly tested functions will fail in unexpected ways. As Linus Torvalds once said, “Talk is cheap. Show me the code.” And more importantly, show it running in a real-world scenario. The use of chaotic systems as a benchmark is interesting, pushing for robustness, but it’s just another layer of complexity that will eventually become tomorrow’s technical debt. If code looks perfect, no one has deployed it yet.
What’s Next?
The search for activation functions, once considered a solved problem, appears to be entering a new, exhausting phase. This work, with its evolutionary approach and focus on chaotic systems, merely postpones the inevitable. They’ll call it ‘Neuro-Evolutionary Robustness’ and raise funding, naturally. The implicit assumption – that a better activation function fundamentally solves out-of-distribution generalization – feels… optimistic. The datasets used, while clever, are still synthetic. Production data, as anyone who’s been on call knows, operates under different laws of physics.
The real challenge isn’t finding a function that works on a carefully curated benchmark, but one that gracefully degrades when confronted with the utterly bizarre inputs reality throws at it. The current trajectory suggests a combinatorial explosion of bespoke activations, each tailored to a specific niche. This feels suspiciously like the early days of feature engineering, before automated methods emerged – only this time, the ‘features’ are differentiable functions. One suspects the entire edifice will eventually be replaced by a slightly more sophisticated form of data augmentation.
It’s worth remembering that the initial models, with their simple ReLU activations, worked well enough. This pursuit of elegance often forgets that practicality wins. The documentation always lied about perfect generalization, and it will lie again. The system, inevitably, used to be a simple bash script. And one day, it will be again.
Original article: https://arxiv.org/pdf/2602.05688.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- The Best Directors of 2025
- Brent Oil Forecast
- New HELLRAISER Video Game Brings Back Clive Barker and Original Pinhead, Doug Bradley
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
2026-02-06 14:41