Author: Denis Avetisyan
New research tackles the problem of ‘hallucination’ – the tendency of AI models to invent facts – when applied to complex financial data and analysis.
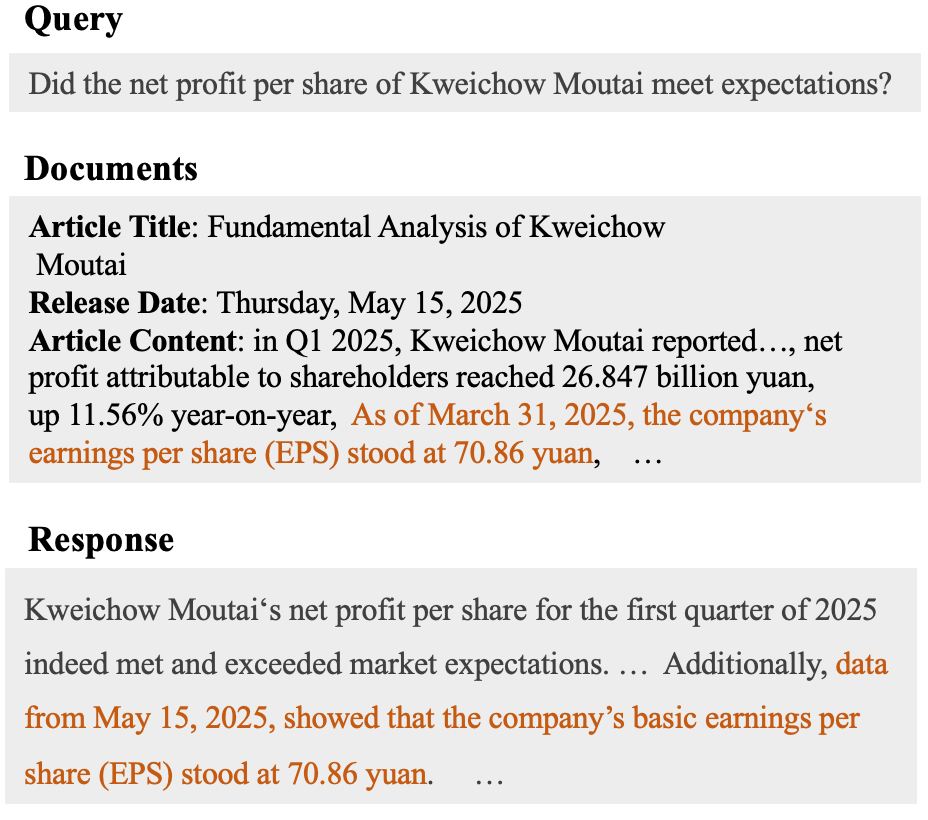
A reinforcement learning framework verifies responses against source documents by breaking down answers into atomic knowledge units, improving factual consistency.
Despite the increasing reliance on retrieval-augmented generation (RAG) for knowledge-intensive tasks, large language models frequently generate responses that contradict retrieved information-a phenomenon known as hallucination, particularly problematic in the time-sensitive financial domain. This paper, ‘Mitigating Hallucination in Financial Retrieval-Augmented Generation via Fine-Grained Knowledge Verification’, introduces a reinforcement learning framework (RLFKV) that enhances factual consistency by verifying the correctness of responses at the level of atomic knowledge units. Through fine-grained rewards aligned with retrieved documents and incentives for informative replies, RLFKV demonstrably improves response fidelity on both public and newly proposed financial datasets. Could this approach to knowledge verification unlock more reliable and trustworthy financial insights from large language models?
Decoding the Illusion: When Language Models Hallucinate
Large language models demonstrate a remarkable capacity for generating text that convincingly mimics human writing styles, often proving indistinguishable from content created by people. However, this proficiency is frequently undermined by a phenomenon known as ‘hallucination’, where the model confidently asserts information that is demonstrably false or unsupported by established facts. This isn’t simply a matter of occasional errors; these models can fabricate entire narratives, cite nonexistent sources, or misrepresent well-known events, all while maintaining a coherent and persuasive tone. The core issue stems from the models’ training process, which prioritizes statistical relationships between words rather than grounding knowledge in verifiable truth, leading to fluent but potentially unreliable outputs and posing significant challenges for applications demanding factual accuracy.
Conventional reinforcement learning techniques, while powerful, often falter when applied to the complex task of ensuring factual accuracy in large language models. These methods typically utilize binary reward signals – a simple ‘correct’ or ‘incorrect’ assessment – which lack the granularity needed to address the nuances of truth. Such a system struggles to differentiate between subtly incorrect statements and outright fabrications, or to provide specific guidance on how to improve factual consistency. Consequently, training becomes unstable; the model may oscillate between generating plausible but inaccurate text and adhering to known facts without understanding the underlying reasoning. This limitation hinders the development of reliable AI systems capable of consistently generating truthful and verifiable information, demanding more sophisticated reward mechanisms that acknowledge degrees of factual correctness.
Successfully grounding Large Language Models in reality demands a shift beyond simple reward systems; nuanced feedback mechanisms are crucial for aligning generated text with established knowledge. Current methods often rely on binary signals – correct or incorrect – which fail to capture the subtleties of factual accuracy and can impede the learning process. More sophisticated approaches involve decomposing factual verification into granular components, rewarding models not just for overall correctness, but for specific aspects of truthfulness, such as identifying supporting evidence or acknowledging uncertainties. This detailed feedback allows LLMs to progressively refine their understanding of the world, moving beyond fluent imitation towards genuine knowledge representation and reliable output generation. Ultimately, the ability to provide and utilize such granular signals represents a key step towards building AI systems capable of consistently producing verifiable and trustworthy information.
Current approaches to ensuring factual accuracy in large language models are hampered by a fundamental inconsistency in evaluation and reinforcement. While models can generate seemingly plausible text, reliably determining whether that text aligns with established knowledge proves surprisingly difficult. Existing reward systems often provide only a simple ‘correct’ or ‘incorrect’ signal, failing to capture the nuances of factual errors – a statement might be mostly true, partially misleading, or contain subtle inaccuracies. This binary feedback is insufficient to guide models towards consistently truthful outputs, leading to unstable training and a persistent risk of ‘hallucinations’. Consequently, the development of genuinely reliable AI systems – those capable of consistently providing verifiable information – is significantly hindered by this inability to effectively assess and reward factual precision.
RLFKV: Dissecting Truth, One Knowledge Unit at a Time
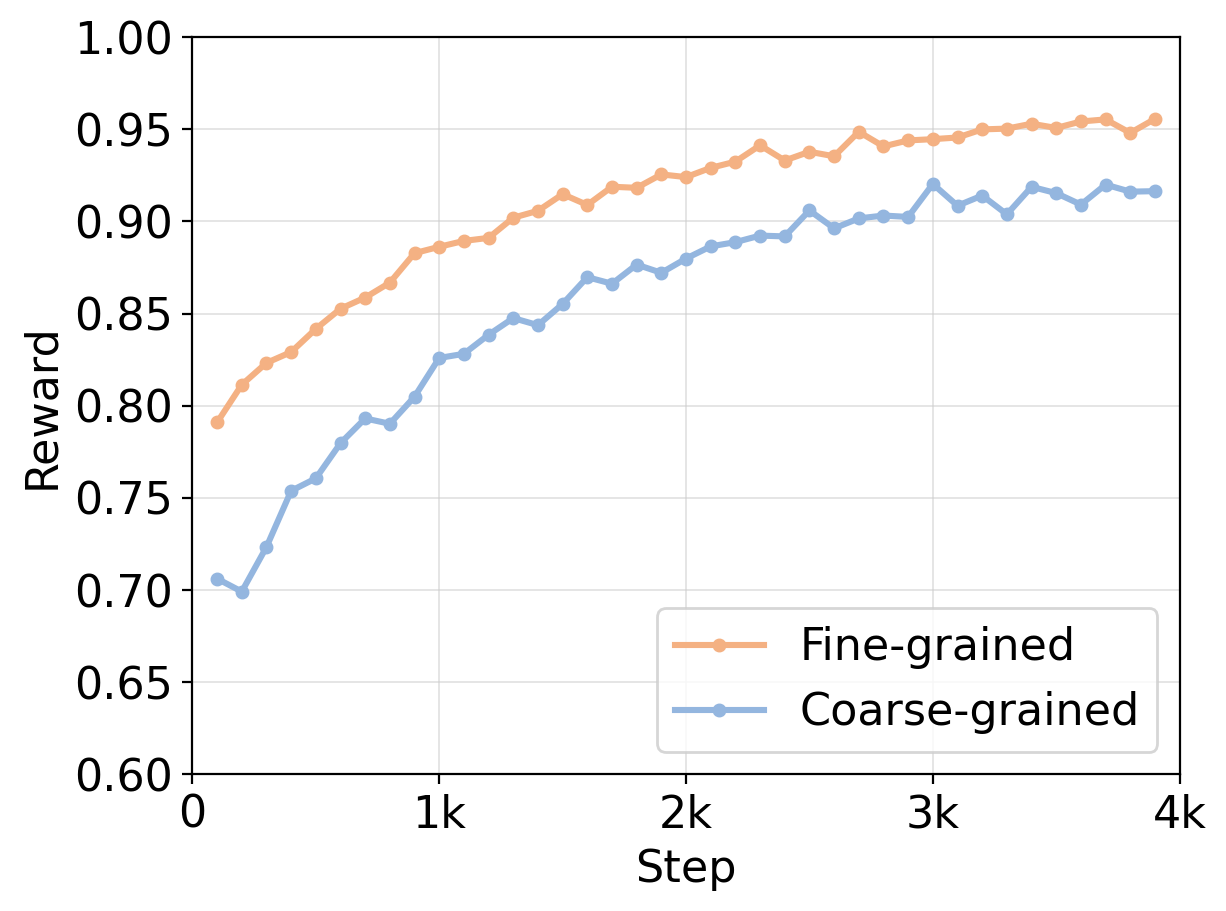
The RLFKV framework employs reinforcement learning (RL) to refine Large Language Models (LLMs) through a reward system designed for granular feedback. Unlike traditional RLHF methods that rely on scalar rewards for entire responses, RLFKV utilizes a novel, fine-grained reward signal. This signal is generated by evaluating LLM outputs at the level of individual knowledge units, allowing for precise optimization of factual accuracy and consistency. The RL agent learns to maximize this reward by adjusting the LLM’s parameters, resulting in improved performance on knowledge-intensive tasks and a reduction in the generation of unsupported or inaccurate information. This approach facilitates more stable training and allows for targeted improvement of specific knowledge domains within the LLM.
The RLFKV framework’s reward signal is constructed by dissecting Large Language Model (LLM) responses into units of ‘atomic knowledge’. These atomic knowledge units are defined as minimal, self-contained statements of factual information, representing the smallest possible verifiable claim within the response. This decomposition process isolates individual facts, allowing for granular assessment of accuracy. Each atomic unit is then independently evaluated for truthfulness against a knowledge source, with the resulting verification status contributing to the overall reward. This approach contrasts with evaluating entire responses, enabling precise feedback targeted at specific factual errors or inaccuracies within the LLM’s output.
RLFKV’s training stability and effectiveness stem from its unit-level verification process. Rather than evaluating an LLM’s complete response, the framework assesses individual ‘atomic knowledge’ units – discrete factual statements extracted from the response. This granular approach allows for the assignment of precise, targeted rewards or penalties based on the veracity of each unit. Consequently, the LLM receives direct feedback regarding specific knowledge claims, facilitating more efficient learning and reducing the risk of reward hacking or unstable policy updates common in reward-based reinforcement learning. This contrasts with methods that rely on holistic evaluation, where identifying the source of errors within a complex response is significantly more challenging.
RLFKV builds upon Retrieval-Augmented Generation (RAG) by enhancing its factual accuracy and reducing instances of hallucination. Traditional RAG systems retrieve relevant documents to inform LLM responses, but may still generate incorrect or unsupported statements. RLFKV integrates a fine-grained knowledge verification process after retrieval and generation. This verification, based on atomic knowledge units, allows the framework to identify and penalize responses containing unverified or contradictory information, effectively improving factual grounding. By reinforcing responses aligned with verified knowledge, RLFKV mitigates the risk of generating hallucinations and increases the reliability of the LLM’s output compared to standard RAG implementations.
Deconstructing Knowledge: The Language of Facts
Atomic Knowledge Unit Decomposition is the process of dissecting generated responses into discrete, factual statements. These statements are then formalized using a ‘Financial Quadruple Structure’ consisting of four core components: the entity being referenced, the metric being measured, the corresponding value of that measurement, and the timestamp indicating when the value was recorded. This structured representation facilitates granular analysis and verification of information, allowing for precise tracking of financial data points and their associated contexts. The consistent application of this quadruple structure ensures all factual claims are explicitly defined and readily auditable.
The Financial Quadruple Structure – comprising entity, metric, value, and timestamp – facilitates precise verification of financial information by isolating each component of a factual statement. This granular approach allows for independent validation of each element; the identified entity can be cross-referenced with authoritative sources, the metric definition can be confirmed against established standards, the reported value can be compared to original data, and the timestamp confirms the relevance of the information within a specific temporal context. This decomposition contrasts with unstructured text where facts are embedded within narrative, making automated verification significantly more complex and prone to error.
Temporal Sensitivity within our methodology addresses the critical role of accurate time referencing in financial data analysis. Financial information is inherently time-dependent; the validity and interpretation of metrics are directly linked to the precise moment of measurement. To accommodate this, our system doesn’t simply record dates, but incorporates granular timestamping as a core component of the Financial Quadruple Structure. This allows for verification of data integrity by confirming that reported values align with the stated time of observation, and facilitates time-series analysis, trend identification, and the detection of anomalies dependent on temporal context. The system is designed to handle varying levels of temporal granularity, accommodating data sources with differing reporting frequencies and precision.
The Generalized Reward Per Optimization (GRPO) algorithm functions as the core optimization method within the Reinforcement Learning from Knowledge Vectors (RLFKV) framework. GRPO iteratively refines the policy model by maximizing a cumulative reward signal derived from knowledge vector assessments. This process involves sampling actions based on the current policy, evaluating the resulting knowledge vectors against established financial data, and updating the policy parameters to increase the likelihood of actions yielding higher reward scores. The algorithm’s efficiency stems from its ability to handle complex, high-dimensional policy spaces and adapt to evolving financial landscapes, ultimately improving the accuracy and reliability of the RLFKV system.
Validation and Results: A Rigorous Test of Fidelity
Evaluation of the RLFKV methodology utilized two distinct datasets for comprehensive assessment. The publicly available ‘FDD Dataset’ served as a baseline for comparison, while the newly constructed ‘FDD-ANT Dataset’ was designed to provide increased diversity and represent a wider range of financial data scenarios. The FDD-ANT dataset incorporates a broader spectrum of financial instruments, reporting periods, and company profiles than the original FDD dataset, allowing for a more robust evaluation of RLFKV’s performance across varied inputs and its ability to generalize beyond the limitations of a single dataset.
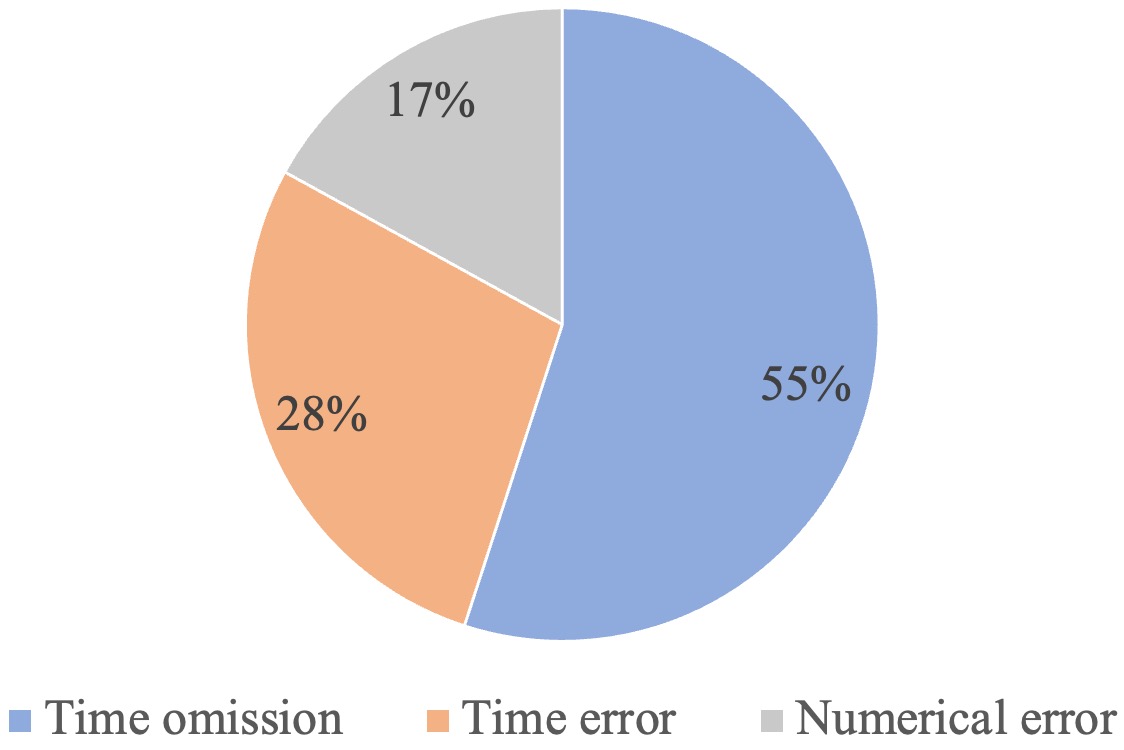
Optimization using RLFKV yielded measurable gains in both Faithfulness and Informativeness metrics when applied to financial data description tasks. Faithfulness, defined as the consistency between generated text and retrieved source documents, was directly improved, indicating a reduction in the generation of unsupported or contradictory statements. Simultaneously, enhancements to Informativeness demonstrate that RLFKV does not achieve these gains at the expense of content density or relevance; models produced more comprehensive and useful descriptions while maintaining factual accuracy. These improvements were consistently observed across multiple datasets and model architectures, confirming the broad applicability of RLFKV in enhancing the quality of LLM-generated financial reporting.
Evaluation of Retrieval-augmented Language Model with Key-Value pairs (RLFKV) demonstrated quantifiable improvements in faithfulness, a metric assessing consistency between generated text and source documents. Specifically, RLFKV achieved up to a 3.6 point increase in faithfulness scores when tested on the FDD dataset, and a 3.1 point increase on the more diverse FDD-ANT dataset. This improvement indicates a corresponding reduction in the occurrence of factual hallucinations within the generated financial data descriptions, suggesting enhanced reliability of the model’s outputs.
RLFKV was successfully implemented and tested using both the LLaMA3.1-8B-Instruct and Qwen3-8B base language models. This implementation across differing model architectures demonstrates the general applicability of RLFKV as a method for improving the quality of financial data descriptions, independent of the underlying model. Performance gains were observed on both models when evaluated on the FDD and FDD-ANT datasets, confirming that the benefits of RLFKV are not specific to a particular base model.
Comparative analysis on the FDD-ANT dataset indicates that models refined with RLFKV achieve a 1.6 point increase in Faithfulness score relative to the baseline LLaMA3 model. This improvement signifies a measurable enhancement in the factual consistency of generated financial data descriptions, demonstrating RLFKV’s capacity to reduce instances of hallucination and improve the reliability of the model’s outputs when evaluated against the more diverse FDD-ANT benchmark.
Evaluation on the FDD and FDD-ANT datasets demonstrated that Reinforcement Learning from Knowledge Verification (RLFKV) consistently improves the factual accuracy of financial data descriptions generated by Large Language Models (LLMs). Specifically, RLFKV achieved up to 3.6 point gains in Faithfulness scores on the FDD dataset and 3.1 points on the FDD-ANT dataset, indicating a measurable reduction in the incidence of factual hallucinations. This improvement in factual consistency was observed across both the LLaMA3.1-8B-Instruct and Qwen3-8B base models, and, in comparison to LLaMA3, RLFKV yielded a 1.6 point increase in Faithfulness on the FDD-ANT dataset, confirming its effectiveness in enhancing the quality and reliability of LLM-generated financial content.
Beyond Fluency: Towards AI We Can Trust
Recent advancements in large language models (LLMs) have demonstrated impressive creative capabilities, but often at the cost of factual accuracy. The development of Retrieval-Augmented Knowledge Verification, or RLFKV, marks a crucial stride towards rectifying this limitation. This system doesn’t simply generate text; it actively retrieves relevant knowledge from external sources and rigorously verifies the consistency of its outputs against established facts. By grounding LLM responses in verifiable evidence, RLFKV significantly reduces the risk of hallucination and fabrication, fostering greater reliability. This approach represents a fundamental shift – moving beyond purely generative models towards systems capable of both creative expression and demonstrable truthfulness, ultimately building AI that users can confidently trust for accurate and insightful information.
Ongoing research aims to broaden the applicability of RLFKV beyond its initial scope, with efforts directed towards adapting the framework for use in diverse fields such as scientific research, legal analysis, and medical diagnosis. This expansion necessitates the development of more nuanced knowledge decomposition techniques, enabling the system to break down complex information into increasingly granular and verifiable components. Simultaneously, researchers are investigating advanced verification methods, moving beyond simple fact-checking to incorporate methods that assess the logical consistency and contextual relevance of generated content. These combined efforts promise to create AI systems capable of not only accessing and retrieving knowledge but also of rigorously validating its accuracy and applying it effectively across a wide range of specialized domains, ultimately enhancing the reliability and trustworthiness of AI-driven solutions.
The convergence of factual knowledge and creative generation represents a pivotal advancement in artificial intelligence. Future systems are not simply envisioned as repositories of information or engines of imagination, but as entities capable of synthesizing both to produce genuinely novel insights. This integration promises to move beyond mere data recall, enabling AI to formulate solutions, generate hypotheses, and even drive scientific discovery by connecting established facts with innovative ideas. Such systems hold the potential to accelerate progress across diverse fields, from artistic expression and content creation to complex problem-solving in engineering, medicine, and beyond, offering a powerful toolkit for addressing some of society’s most pressing challenges.
The true promise of large language models (LLMs) hinges on their ability to consistently deliver factual information, and prioritizing this consistency is paramount to realizing their full potential. Current LLMs, while adept at generating human-like text, often struggle with ‘hallucinations’ – presenting plausible but incorrect statements as fact. Addressing this requires innovative techniques to ground LLM outputs in verifiable knowledge sources and robustly assess the truthfulness of generated content. Successfully mitigating these inaccuracies isn’t simply about improving performance metrics; it’s about fostering trust and ensuring these systems contribute positively to society by providing reliable insights, aiding in critical decision-making, and empowering informed understanding across diverse fields. Ultimately, a commitment to factual consistency transforms LLMs from impressive text generators into genuinely beneficial tools for progress.
The pursuit of factual consistency, as demonstrated by RLFKV, mirrors a fundamental principle of understanding any complex system: deconstruction. The framework’s decomposition of answers into atomic knowledge units isn’t merely about improving accuracy; it’s about isolating the core components to verify their integrity-a process akin to reverse-engineering a financial model to identify vulnerabilities. As Henri Poincaré observed, “It is through science that we are able to appreciate the beauty of the universe.” This appreciation, in the context of large language models, stems from rigorously testing the boundaries of their knowledge and ensuring each unit of information holds true, ultimately revealing the underlying structure of financial data itself.
Decoding the Source Code
The pursuit of factual grounding in large language models, particularly within the notoriously opaque financial domain, reveals a fundamental truth: current systems are adept at mimicking understanding, not demonstrating it. This work, by dissecting responses into atomic knowledge units and rewarding verifiable consistency, is less about solving hallucination and more about refining the instruments used to detect its presence. It’s a shift from believing the output to auditing its construction – a crucial, if incremental, step.
However, the limitations are evident. Fine-grained rewards are computationally expensive, and the definition of an “atomic” unit remains subjective-a reflection of the inherent messiness of real-world knowledge. Future work must address the scalability of this approach and explore methods for automatically identifying meaningful knowledge decomposition, perhaps by borrowing concepts from knowledge graph construction or information extraction.
Ultimately, this research underscores a larger point: reality is open source – the information is there, accessible. The challenge isn’t generating text; it’s developing the tools to rigorously trace that text back to its source, to verify each line of code. The goal isn’t to eliminate errors, but to make them transparent, locatable, and therefore, fixable.
Original article: https://arxiv.org/pdf/2602.05723.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Games That Faced Bans in Countries Over Political Themes
- Gold Rate Forecast
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- The Best Directors of 2025
- The Best Former NFL Players Turned Actors, Ranked
2026-02-06 07:42