Author: Denis Avetisyan
A new architecture leveraging Bernstein polynomials as activation functions promises improved gradient flow, representational power, and potential for significant network compression.
DeepBern-Nets provide a provable alternative to residual layers, offering superior stability and performance in deep neural networks.
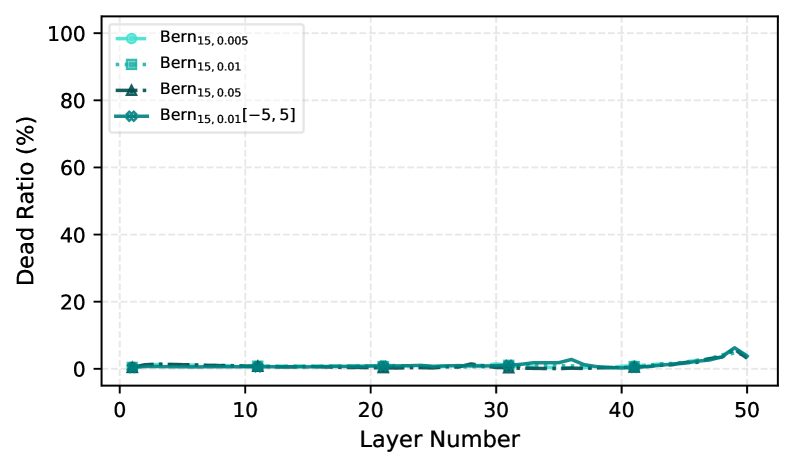
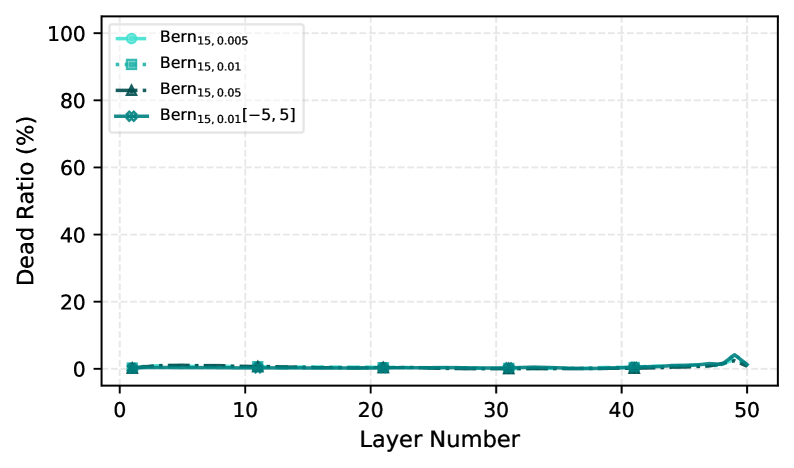
Despite the success of deep learning, vanishing gradients and the resultant “dead” neurons remain persistent challenges, often necessitating complex architectural solutions like residual connections. This paper, ‘From Dead Neurons to Deep Approximators: Deep Bernstein Networks as a Provable Alternative to Residual Layers’, introduces Deep Bernstein Networks (DeepBern-Nets) – a novel architecture leveraging Bernstein polynomials as activations to provably address these limitations. By demonstrating a strictly bounded local derivative and exponentially decaying approximation error-improvements over ReLU-based networks-DeepBern-Nets achieve high performance without skip-connections, reducing dead neurons to less than 5%. Could this approach pave the way for more efficient, expressive, and truly deep neural networks?
Vanishing Gradients: The Inevitable Bottleneck
Deep neural networks, despite their demonstrated capacity for complex pattern recognition, frequently encounter a significant obstacle during the training process known as the vanishing gradient problem. As information propagates backward through numerous layers to update network weights, the gradients – signals indicating how much each weight should be adjusted – can become increasingly minuscule. This exponential decay effectively halts learning in the deeper layers, preventing them from contributing meaningfully to the network’s overall performance. Consequently, the network’s ability to model intricate relationships within the data is severely limited, as only the initial layers receive substantial updates, while those further down remain largely untrained and ineffective. This phenomenon poses a fundamental challenge to building truly deep and powerful neural networks, necessitating innovative approaches to stabilize and maintain gradient flow throughout the entire architecture.
The effectiveness of deep neural networks can be severely hampered by a phenomenon known as a high ‘Dead Neuron Ratio’, where a substantial proportion of neurons cease to contribute to the network’s learning process. This inactivity restricts the network’s capacity to model complex relationships within data. Recent investigations reveal a stark contrast between traditional activation functions and novel architectures like DeepBern-Nets; experiments consistently demonstrate that networks utilizing conventional methods exhibit ‘Dead Neuron Ratios’ exceeding 90%, meaning the vast majority of neurons become effectively dormant during training. In direct comparison, DeepBern-Nets successfully maintain a ‘Dead Neuron Ratio’ below 5%, preserving a significantly larger proportion of active neurons and, consequently, bolstering the network’s representational power and overall performance.
While techniques like residual connections have proven effective in training very deep neural networks, they primarily function as a workaround rather than a solution to the underlying instability of gradients. These connections introduce shortcuts, allowing gradients to bypass problematic layers and propagate more easily, but they don’t address the fundamental issue of exponentially decaying or exploding gradients as they travel through numerous layers. Essentially, residual connections mask the symptoms of gradient instability by providing an alternate pathway, rather than fundamentally altering how gradients are calculated and propagated through the network’s architecture. This means that even with residual connections, deep networks can still suffer from suboptimal learning and limited expressivity, particularly when faced with complex datasets or intricate relationships within the data, as the root cause of gradient issues remains unaddressed and potentially limits the network’s ultimate performance.
The prevalent Rectified Linear Unit (ReLU) activation function, while computationally efficient, introduces inherent limitations in deep network training due to its susceptibility to the vanishing gradient problem. When neurons become saturated – operating in regions where the gradient is zero – they effectively cease learning, hindering the flow of information through the network. This characteristic restricts the expressivity of deep models, as large portions of the network may fail to contribute meaningfully to the learned representation. Consequently, researchers are actively exploring alternative activation functions and network architectures designed to promote healthier gradient flow and unlock the full potential of deep learning, striving for solutions that maintain strong signal propagation even across numerous layers and complex data landscapes.
DeepBern-Nets: A Polynomial Approach to Gradient Persistence
DeepBern-Nets represent a new neural network architecture distinguished by the implementation of Bernstein\ polynomials as activation functions. Unlike conventional networks utilizing ReLU or sigmoid activations, DeepBern-Nets directly incorporate these polynomial functions within each layer to transform input signals. The core innovation lies in replacing the piecewise linear or saturating behavior of standard activations with the smooth, globally defined properties of Bernstein\ polynomials. This architectural choice influences gradient flow and expressive capacity, forming the basis for improvements in training stability and function approximation capabilities. The network structure otherwise maintains a layered, feedforward design common to many deep learning models, with the key distinction being the replacement of the activation function at each layer.
Bernstein polynomials, utilized as activation functions, intrinsically possess C^∞ continuity, ensuring smoothness and preventing abrupt changes in gradient values. This characteristic directly facilitates ‘Gradient Persistence’ by maintaining signal propagation through deeper network layers. Unlike piecewise linear activations such as ReLU, which can introduce zero gradients or sharp discontinuities, Bernstein polynomials offer a continuously differentiable response. Consequently, gradients are less susceptible to attenuation or vanishing as they are backpropagated, allowing for more effective training of deeper architectures and reducing the impact of the Vanishing Gradient Problem. The degree of the polynomial controls the complexity of the activation and, consequently, the smoothness and gradient behavior.
Traditional activation functions like ReLU suffer from limitations including the potential for ‘dying ReLU’ and susceptibility to the Vanishing Gradient Problem, particularly in deep networks. ReLU’s piecewise-linear nature introduces abrupt changes in gradient, hindering effective backpropagation. DeepBern-Nets, utilizing Bernstein Polynomials, directly address these issues by offering inherently smooth, continuously differentiable activation functions. This smoothness ensures gradients remain well-behaved throughout the network’s depth, preventing them from becoming excessively small or zero, thereby mitigating the Vanishing Gradient Problem and promoting more stable and efficient training, even in very deep architectures. Unlike ReLU, which can saturate and block gradient flow, Bernstein Polynomials maintain gradient persistence, enabling information to propagate effectively from later layers to earlier layers during backpropagation.
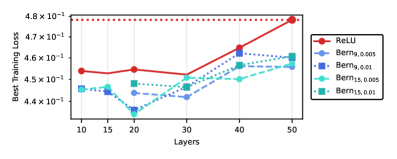
DeepBern-Nets exhibit increased expressive power compared to networks utilizing ReLU activations, resulting in superior function approximation capabilities. Theoretical analysis demonstrates an approximation error decay rate of 𝒪(n⁻ᴸ), where n represents the network width and L is a positive constant determined by the polynomial degree. This decay rate surpasses that of ReLU networks, indicating that DeepBern-Nets require fewer parameters to achieve a given level of accuracy when approximating complex functions. Empirical results confirm this advantage, showing that DeepBern-Nets converge faster and achieve lower error rates across a range of benchmark problems.
Validation and Performance: Putting Theory to the Test
DeepBern-Nets were subjected to comprehensive evaluation using two distinct datasets: the MNIST dataset, a widely used benchmark for handwritten digit recognition, and the HIGGS dataset, which presents a significantly more complex classification challenge. The MNIST dataset served as a baseline for initial testing and performance comparison, while the HIGGS dataset was utilized to assess the scalability and effectiveness of DeepBern-Nets in handling high-dimensional, real-world data. Performance metrics obtained from both datasets were crucial for validating the network’s ability to generalize beyond simpler tasks and demonstrate its potential for application in more demanding scenarios.
Evaluations consistently demonstrated that the implementation of Batch Normalization with DeepBern-Nets resulted in improved performance metrics when contrasted with networks employing ReLU activation functions. This superiority was observed across both the MNIST and HIGGS datasets, indicating a generalized benefit. Batch Normalization facilitated more stable training dynamics and allowed for higher learning rates, ultimately leading to lower overall error rates and faster convergence speeds compared to ReLU-based networks. The consistent positive impact suggests that Batch Normalization effectively mitigates internal covariate shift within the DeepBern-Net architecture, enhancing its learning capability.
Variants of the DeepBern-Net activation function, specifically Floor-ReLU and Floor-Exponential-Step, were investigated to quantify their impact on approximation accuracy and error mitigation. These modified activation functions were analyzed in relation to the standard ReLU, focusing on how alterations to the function’s slope and saturation behavior affect the network’s ability to accurately represent complex functions. Experiments assessed the resulting changes in approximation error – the difference between the network’s output and the desired target – and measured the extent to which these variants could reduce error propagation during training. The goal was to determine if these alternative functions offered improvements in accuracy or efficiency compared to the baseline DeepBern-Net implementation.
Evaluations on the MNIST and HIGGS datasets indicate that DeepBern-Nets exhibit reduced approximation error and accelerated convergence rates compared to standard neural networks. Specifically, these networks achieved a 5x reduction in required network depth while maintaining equivalent or improved performance on both datasets. On the MNIST dataset, a single-layer DeepBern-Net configuration yielded a training loss of 0.0003, demonstrating effective learning with a significantly reduced architectural complexity. This suggests potential benefits in terms of computational efficiency and reduced overfitting.
Implications and Future Directions: A More Controlled Learning Process
DeepBern-Nets represent a novel approach to neural network design, offering a potential solution to the persistent challenge of the Vanishing Gradient Problem. Traditional activation functions, while effective in many scenarios, can suffer from diminishing gradients as information propagates through deeper layers, hindering training and limiting network performance. By employing Bernstein Polynomials as activation functions, DeepBern-Nets generate inherently smooth gradients, facilitating more efficient information flow and enabling the training of significantly deeper architectures. This improved gradient behavior not only accelerates the learning process but also enhances the network’s ability to capture complex relationships within data, ultimately leading to more trainable and expressive models. The design effectively addresses gradient saturation, a common obstacle in deep learning, and paves the way for robust performance across a wider range of tasks and datasets.
DeepBern-Nets leverage the unique properties of Bernstein Polynomials to offer enhanced performance in sensitive applications. Unlike traditional activation functions which can produce erratic gradients, Bernstein Polynomials inherently generate smooth curves and maintain controlled gradients throughout the network. This characteristic is especially valuable in fields demanding high precision, such as medical image analysis or financial modeling, where even minor inaccuracies can have significant consequences. The predictable gradient behavior contributes to improved stability during training, reducing the risk of divergence and allowing for more reliable model convergence. Furthermore, the smoothness inherent in these polynomials can aid in generalization, potentially leading to better performance on unseen data and making DeepBern-Nets a promising avenue for research in areas prioritizing robustness and accuracy.
Ongoing research endeavors are directed toward rigorously testing the limits of DeepBern-Nets, specifically their capacity to maintain stable training and robust performance as network depth increases significantly. Investigations are underway to assess whether the benefits observed in shallower architectures – namely, mitigated vanishing gradients and improved precision – translate to substantially deeper networks capable of tackling increasingly complex problems. Furthermore, the adaptability of DeepBern-Nets is being evaluated across a wide spectrum of datasets, extending beyond those initially used in development, to determine their generalizability and identify potential areas for refinement or specialized application; this includes datasets representing diverse modalities such as image recognition, natural language processing, and time-series analysis, allowing for a comprehensive understanding of their capabilities and limitations.
The development of DeepBern-Nets signifies a potential leap forward in neural network architecture, not merely through improved performance, but through a fundamentally controlled learning process. By leveraging Bernstein polynomials, these networks maintain a strictly bounded ‘Minimum Absolute Derivative’ – guaranteed to be greater than or equal to n⋅δ/(u−l) throughout the entire training regimen. This characteristic ensures stable gradients and prevents the signal degradation common in traditional deep networks, fostering both efficiency and expressiveness. Consequently, researchers anticipate that DeepBern-Nets will facilitate the creation of more robust and adaptable deep learning models, capable of tackling complex challenges across a diverse range of applications and potentially unlocking new frontiers in artificial intelligence.
The pursuit of gradient stability, as highlighted in this work with DeepBern-Nets, feels predictably Sisyphean. The authors propose Bernstein polynomials as a solution, a novel activation function intended to address the vanishing gradient problem – a problem that has haunted neural networks for decades. It’s a temporary reprieve, of course. Every ‘elegant’ architectural fix eventually reveals its limitations when confronted with the relentless entropy of production data. As Ada Lovelace observed, “The Analytical Engine has no pretensions whatever to originate anything. It can do whatever we know how to order it to perform.” These networks don’t solve the problem of representation; they simply shift the boundaries of what’s computationally feasible – and create a new set of constraints for the next generation to overcome.
What’s Next?
The pursuit of gradient stability, as evidenced by this work with DeepBern-Nets, will invariably reveal that every solution is merely a locally optimal postponement of the inevitable. Bernstein polynomials offer a compelling initial response to vanishing gradients, but the landscape of optimization is littered with elegantly crafted activations eventually defeated by adversarial examples and the sheer scale of modern datasets. The claim isn’t that this architecture solves the problem, only that it shifts the failure modes – a crucial distinction often lost in the rush to publication.
Future work will likely focus on the computational cost of Bernstein polynomials, a practical limitation that any deployment will immediately highlight. Approximation theory is a fickle mistress; increased representational capacity invariably demands increased parameters. The promise of network compression, therefore, hinges not on the inherent efficiency of the activation function, but on novel pruning and quantization techniques capable of mitigating its overhead. It’s a reminder that architecture isn’t a diagram; it’s a compromise that survived deployment.
Ultimately, the true test lies not in benchmark datasets, but in the unforgiving crucible of real-world application. Everything optimized will one day be optimized back. The field will continue to cycle through novel activations and regularization schemes, each promising salvation, each destined to join the graveyard of superseded techniques. The task isn’t to discover the perfect network, but to develop the tools and methodologies to resuscitate hope when the inevitable cracks begin to appear.
Original article: https://arxiv.org/pdf/2602.04264.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The Best Directors of 2025
- Brent Oil Forecast
- New HELLRAISER Video Game Brings Back Clive Barker and Original Pinhead, Doug Bradley
2026-02-06 06:08