Author: Denis Avetisyan
New research reveals a disconnect between how adversarial machine learning threats are understood and addressed in industry versus academic settings.
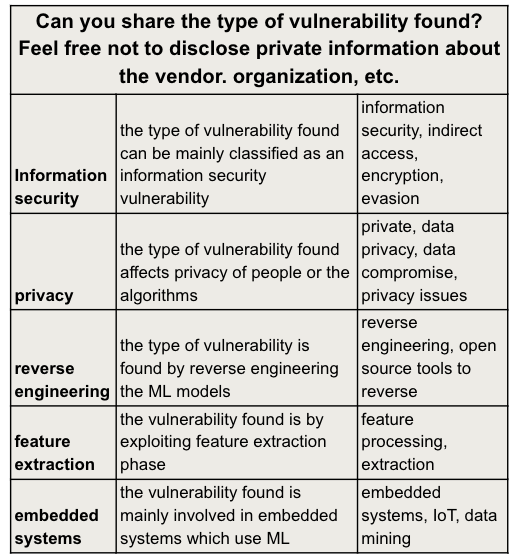
A user study compares practical security knowledge and proposes Capture The Flag exercises to enhance awareness of data poisoning, privacy attacks, and generative AI vulnerabilities.
Despite the rapid proliferation of Machine Learning and Generative AI, a critical gap persists between awareness of adversarial threats and proactive security education. This research, titled ‘Comparative Insights on Adversarial Machine Learning from Industry and Academia: A User-Study Approach’, investigates this disparity through comparative studies of industry professionals and students, revealing a strong correlation between cybersecurity training and concern for vulnerabilities like data poisoning. Utilizing a Capture The Flag (CTF) approach to engage students with practical challenges, we demonstrate that hands-on learning effectively increases interest in and understanding of Adversarial Machine Learning (AML) threats. How can integrated security curricula best prepare future machine learning practitioners to mitigate these evolving risks and build more robust AI systems?
The Expanding Attack Surface: Chatbots and the Peril of Data Corruption
The proliferation of sophisticated chatbots, such as LollyAI and similar conversational AI systems, represents a rapidly expanding frontier for potential cyberattacks. As these technologies become integrated into customer service, healthcare, finance, and even critical infrastructure, the sheer number of deployed instances dramatically increases the ‘attack surface’ available to malicious actors. This isn’t merely a question of individual chatbot compromise; a successful breach could potentially grant access to sensitive user data, disrupt essential services, or even manipulate automated systems. The very accessibility and widespread adoption that drive the popularity of these chatbots simultaneously create a compelling target, demanding proactive security measures and a heightened awareness of potential vulnerabilities as deployment continues to accelerate across diverse sectors.
Chatbots, despite their growing sophistication, face a critical vulnerability in the form of data poisoning attacks. These attacks involve introducing subtly malicious data into the training dataset, corrupting the model’s learning process and ultimately compromising its outputs. Unlike traditional software exploits, data poisoning doesn’t target the chatbot’s code directly; instead, it manipulates the very information the chatbot relies on to function. The consequences can range from subtly biased responses to the generation of harmful or misleading content, eroding user trust and potentially causing real-world damage. Because modern chatbots are trained on massive datasets often sourced from the open web, identifying and filtering out these poisoned inputs presents a significant and ongoing challenge for developers and researchers striving to maintain the integrity and reliability of these increasingly prevalent systems.
The sheer scale and diversity of datasets used to train modern chatbots present a formidable obstacle to detecting malicious inputs. These systems learn from billions of data points sourced from across the internet, a vast and often uncurated landscape. Consequently, identifying and removing subtly crafted, harmful prompts – known as data poisoning – becomes akin to finding a few drops of tainted water in an ocean. The complexity isn’t merely volume; malicious actors can disguise harmful content within seemingly benign text, exploiting the nuances of language and the chatbot’s learning algorithms. This makes traditional filtering methods insufficient, as they often struggle to differentiate between legitimate, complex expressions and cleverly disguised attacks. Detecting these poisoned inputs requires advanced anomaly detection techniques and a deep understanding of both natural language processing and adversarial machine learning, a rapidly evolving field with persistent challenges.

Cross-Platform Vulnerabilities: Demonstrating Systemic Risk
Exploitation of vulnerabilities initially demonstrated in the LollyAI chatbot application has been successfully replicated in the Bake-time Lolly Chatbot. This confirms that the initial attack vector – specifically, the method used to manipulate the chatbot’s responses – is not isolated to a single implementation. The successful transfer of the attack demonstrates a common underlying susceptibility across these chatbot systems, indicating shared architectural components or similar data handling processes. This cross-platform exploitability suggests that addressing the vulnerability in one application does not necessarily secure others utilizing the same or similar foundational technologies.
The demonstrated vulnerability is not isolated to a single chatbot application; successful exploitation of one platform, such as LollyAI, provides attackers with valuable intelligence directly applicable to compromising others, like Bake-time. This systemic risk stems from the shared underlying architecture and training methodologies common to many large language model (LLM) based chatbots. Attackers can refine their techniques – particularly data poisoning strategies – based on observed outcomes, effectively transferring exploits across different systems with minimal adaptation. This creates a cascading threat where compromise of one instance significantly increases the probability of successful attacks on related platforms, highlighting a broad, interconnected vulnerability within the LLM ecosystem.
The interconnectedness of chatbot platforms, as demonstrated by the transfer of exploits between LollyAI and Bake-time, indicates a potential for widespread data contamination through data poisoning attacks. Successful manipulation of training data on one platform can be leveraged to compromise the performance and security of others that utilize similar or shared datasets. This cross-contamination occurs because these systems often rely on publicly available datasets or models, and vulnerabilities in one instance can propagate across multiple deployments. The shared reliance on these foundational resources creates a systemic risk, where a single compromised dataset can affect numerous applications and users.
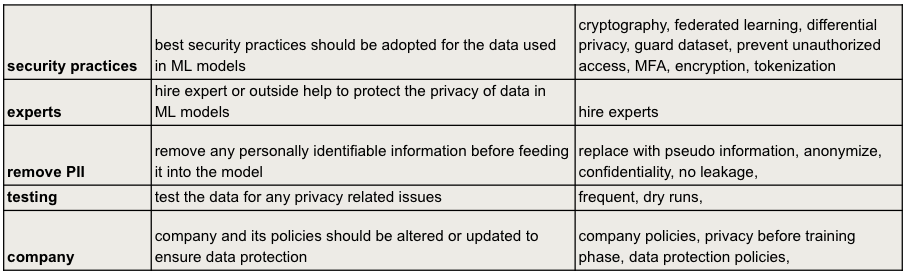
Discrepancies in Perception: Bridging the Gap Between Academia and Industry
A user study was conducted to investigate perceptions of data poisoning vulnerabilities in chatbot systems, specifically contrasting viewpoints from professionals in industry and researchers in academia. The study employed a mixed-methods approach, gathering data through questionnaires and interviews to assess understanding of attack vectors, mitigation strategies, and the overall risk posed by data poisoning. Participants were recruited from a range of roles including machine learning engineers, cybersecurity analysts, and university professors specializing in related fields. Data collected focused on identifying discrepancies in perceived threat levels, preferred security practices, and educational needs related to adversarial machine learning techniques targeting conversational AI.
Analysis of user study data indicates a statistically weak correlation between formal cybersecurity education and the perceived importance of security considerations within the field of Machine Learning. Specifically, Pearson correlation coefficients ranged from 0.017 to 0.101, suggesting that increased cybersecurity educational background does not reliably predict a stronger belief in the relevance of security practices when developing or deploying Machine Learning models. This finding implies a potential disconnect between traditional cybersecurity curricula and the emerging security challenges presented by Machine Learning systems, and suggests a need for more targeted educational initiatives.
Analysis of user study data indicates a moderate positive correlation (0.6) between prior participation in Capture The Flag (CTF) competitions and expressed preference for CTFs as a learning methodology. However, current CTF participants do not consistently leverage these competitions specifically for Adversarial Machine Learning (AML) education. A further analysis revealed an extremely weak correlation (0.001) between general cybersecurity experience and the perceived relevance of security considerations within Machine Learning for a specific subset of study participants, suggesting a disconnect between practical cybersecurity skills and awareness of ML-specific vulnerabilities.
The study meticulously highlights a divergence in practical application between academic research and industry responses to adversarial machine learning threats. This disparity isn’t merely a matter of tools, but a fundamental difference in how problems are framed and approached. As Robert Tarjan once stated, “Simplicity doesn’t mean brevity – it means non-contradiction and logical completeness.” This rings particularly true when considering the need for robust, provably secure machine learning systems. The research underscores that while academia often focuses on demonstrating vulnerability, industry demands solutions that are logically complete and demonstrably resistant to attack-a focus on correctness over merely identifying flaws, aligning perfectly with Tarjan’s emphasis on logical completeness as the hallmark of elegant, reliable design.
The Path Forward
The observed divergence between academic exercises in adversarial machine learning and the pragmatic concerns of industry necessitates a rigorous re-evaluation of educational methodologies. The current reliance on benchmark datasets, while mathematically convenient, appears to foster a misleading sense of security. A system demonstrably robust against contrived perturbations may still falter when confronted with the subtle, economically motivated attacks encountered in real-world deployments. The core issue isn’t merely one of detecting adversarial examples, but of constructing systems inherently resistant to their creation – a problem demanding formal verification, not merely empirical validation.
Future work must prioritize the development of provably secure algorithms. The proliferation of generative AI, while offering potential defenses, simultaneously expands the attack surface. Reliance on ‘arms races’ between generators and detectors is fundamentally unsatisfying; a true solution lies in establishing mathematical guarantees of robustness. Capture The Flag (CTF) exercises, while a step in the right direction, should be refined to emphasize formal methods and provable security properties, rather than simply rewarding successful exploitation of known vulnerabilities.
Ultimately, the field requires a shift in perspective. The pursuit of ‘better’ machine learning algorithms is meaningless without a corresponding commitment to correctness. The elegance of a solution is not measured by its performance on a leaderboard, but by the logical rigor of its underlying principles. Only through a dedication to mathematical purity can the promise of truly secure machine learning be realized.
Original article: https://arxiv.org/pdf/2602.04753.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Top 10 Coolest Things About Jared Leto
2026-02-05 06:28