Author: Denis Avetisyan
New research suggests that large language models are surprisingly capable of articulating the reasoning behind their outputs, offering a path towards more trustworthy artificial intelligence.
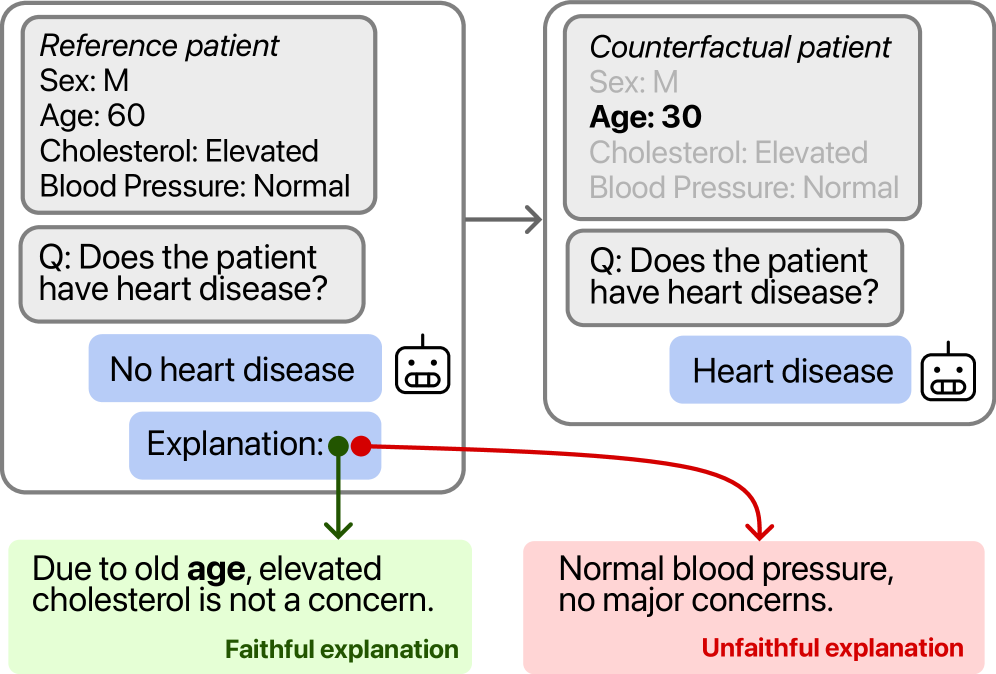
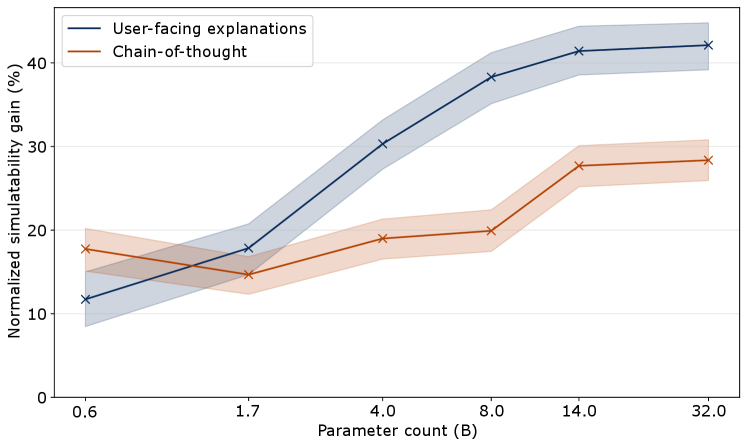
Researchers introduce Normalized Simulatability Gain (NSG), a metric demonstrating that self-explanations can accurately reflect a model’s decision-making process and improve evaluation of explanation faithfulness.
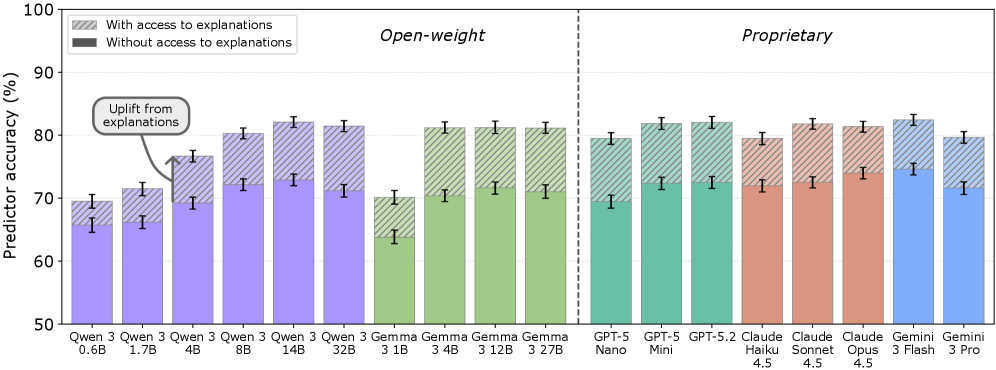
Despite growing reliance on large language models (LLMs), assessing the trustworthiness of their explanations remains a critical challenge. This is addressed in ‘A Positive Case for Faithfulness: LLM Self-Explanations Help Predict Model Behavior’, which introduces Normalized Simulatability Gain (NSG), a novel metric evaluating explanation faithfulness by quantifying improvements in predicting model behavior. Our findings, derived from evaluating 18 frontier LLMs across diverse datasets, demonstrate that self-explanations substantially enhance predictive accuracy-suggesting they encode genuine insights into a model’s reasoning. However, given that 5-15% of these explanations are misleading, can we refine these methods to fully leverage the benefits of explainable AI while mitigating potential risks?
The Illusion of AI Understanding
The increasing sophistication of artificial intelligence demands a corresponding ability to discern the rationale behind its decisions, yet current explanation methods frequently fall short of accurately reflecting the model’s internal processes. As AI transitions from narrowly defined tasks to more complex problem-solving, simply having an explanation isn’t enough; the explanation must be faithful – a genuine representation of the factors driving the outcome. This discrepancy between explanation and actual reasoning poses significant challenges, eroding trust and hindering effective debugging, particularly as models become less transparent with increased layers and parameters. Without fidelity, these systems risk perpetuating biases or making unpredictable errors, effectively remaining ‘black boxes’ despite the presence of ostensibly clarifying outputs.
The increasing complexity of artificial intelligence presents a significant challenge to discerning the true basis of its decisions. While methods for interpreting AI outputs exist, verifying whether these explanations accurately reflect the model’s internal reasoning-a concept known as ‘faithfulness’-remains largely unaddressed. Traditional approaches often rely on post-hoc analysis, attempting to rationalize a decision after it has been made, rather than revealing the actual computational process. This gap between explanation and reality erodes trust, as users are left unsure if the provided justification is genuine or merely a plausible story constructed to appear reasonable. Consequently, the lack of verifiable explanations hinders effective debugging, limits the potential for refinement, and raises serious concerns regarding the responsible deployment of AI systems in critical applications where understanding the ‘why’ is paramount.
Assessing whether an AI explanation accurately reflects the model’s reasoning demands more than simply making the process seem understandable; it requires quantifiable evaluation. Researchers are moving past subjective assessments of interpretability and toward metrics like Normalized Simulatability Gain (NSG). NSG effectively measures how much a proposed explanation improves the ability to simulate the model’s behavior – a higher score indicates a more faithful explanation. This approach bypasses the ambiguity of human judgment by directly testing if the explanation can predict the model’s outputs, offering a rigorous way to verify that explanations aren’t merely post-hoc rationalizations but genuinely reflect the underlying decision-making process. Consequently, NSG and similar metrics are crucial for building trust in AI systems and ensuring their responsible deployment in critical applications.
The continued opacity of many artificial intelligence systems presents significant obstacles to progress and responsible innovation. When explanations for an AI’s decisions are untrustworthy, or fail to accurately reflect the underlying reasoning, it becomes exceedingly difficult to identify and correct errors – effectively treating symptoms rather than addressing core flaws. This ‘black box’ nature not only impedes the refinement of these models, slowing the path toward greater accuracy and efficiency, but also introduces substantial risks when deploying AI in critical applications. Without a clear understanding of why a decision was made, ensuring fairness, accountability, and safety becomes a formidable challenge, potentially undermining trust and hindering widespread adoption of this powerful technology.
Probing the Logic: Counterfactuals as Stress Tests
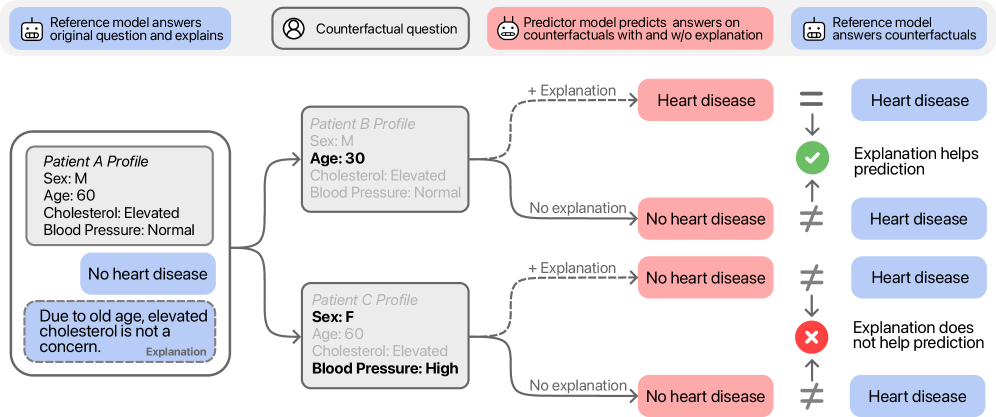
Counterfactual generation assesses model sensitivity by systematically perturbing input data and observing the resulting changes in predictions. This technique moves beyond simply evaluating performance on a static dataset; instead, it probes how reliant a model is on specific features or combinations of features. By creating minimally altered inputs – counterfactuals – researchers can determine if a model’s decision-making process remains consistent when faced with slight variations in the data. The magnitude of the change required to alter the prediction provides a quantifiable measure of the model’s robustness and highlights potentially brittle or oversensitive areas within its learned representations. This approach is particularly useful in identifying spurious correlations that a model may have learned during training.
Counterfactual analysis evaluates model reasoning by generating modified input instances and observing the resulting changes in predictions and explanations. This process involves creating “what-if” scenarios where minimal alterations are made to the original input – for example, changing a single feature value. By comparing the model’s prediction and explanation for the original input to those generated by the counterfactual, researchers can determine if the explanation is robust and accurately reflects the model’s decision-making process. A consistent explanation across both the original and altered inputs suggests the model is basing its predictions on meaningful features, while a significant shift in either prediction or explanation indicates potential sensitivity to irrelevant or spurious correlations within the data.
The utility of counterfactual evaluation hinges on the generation of inputs that are both realistic – conforming to the underlying data distribution – and plausible, meaning they represent minimally altered scenarios that a human would consider reasonable alternatives. Data-driven approaches to counterfactual generation address this need by learning from the training data itself to construct these alternative inputs. These techniques often involve sampling from the data distribution, or utilizing generative models, to ensure the generated counterfactuals are not simply random noise but represent viable, albeit modified, instances. This contrasts with methods that rely on arbitrary perturbations, which may produce implausible examples and yield unreliable insights into model behavior.
Effective counterfactual generation necessitates a quantifiable measure of input dissimilarity to determine the extent of change introduced when creating ‘what-if’ scenarios. Hamming Distance, a common metric, calculates the number of positions at which two inputs differ; a low Hamming Distance indicates a minimal alteration, ensuring the counterfactual remains plausible and focused on specific feature contributions. Other dissimilarity metrics, such as Euclidean distance or cosine similarity, can also be employed depending on the data type and the desired sensitivity of the evaluation. The choice of metric impacts the interpretability of the counterfactual and its ability to isolate the features most responsible for the model’s original prediction.
NSG: A Number to Judge an Explanation By
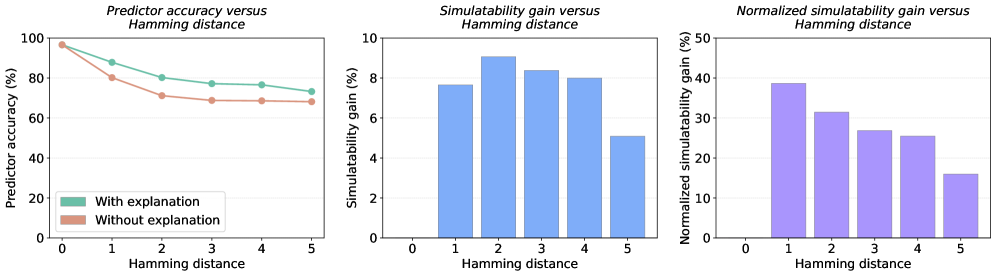
Normalized Simulatability Gain (NSG) quantifies explanation faithfulness by measuring the extent to which an explanation can accurately predict the behavior of a target model. This is achieved by training a predictor model – often a Large Language Model – to simulate the target model’s outputs using only the provided explanation as input. The gain in predictive performance of this predictor model, compared to a baseline without the explanation, is then normalized to produce the NSG score; a higher NSG indicates a more faithful explanation, demonstrating a stronger correlation between the explanation and the model’s decision-making process. Essentially, NSG assesses whether the explanation contains information sufficient to replicate the model’s behavior, providing an objective measure of faithfulness beyond qualitative assessments.
Normalized Simulatability Gain (NSG) assesses explanation faithfulness by training a predictor model to replicate the behavior of a reference model, but crucially, this predictor model is only provided with the explanation as input. The performance of this predictor – its ability to accurately simulate the reference model’s outputs – directly quantifies the predictive power contained within the explanation. If an explanation is truly faithful, the predictor model should achieve a high level of accuracy, demonstrating that the explanation captures the essential information driving the reference model’s decisions. Conversely, a poor-performing predictor indicates the explanation lacks sufficient information or is misleading, suggesting low faithfulness.
Large Language Models (LLMs) facilitate the Normalized Simulatability Gain (NSG) process by functioning in dual roles: as the original model whose behavior is being explained and evaluated, and as the predictor model used to simulate that behavior based solely on the provided explanation. This allows for a direct assessment of how much of the reference model’s functionality can be replicated using only the explanation as input to the predictor LLM. Utilizing a single model type for both roles minimizes confounding variables and streamlines the evaluation pipeline, enabling a consistent and comparable measurement of explanation faithfulness across different datasets and models.
Normalized Simulatability Gain (NSG) analysis consistently reveals improvements in predictive accuracy when explanations are incorporated into predictor models across several datasets. Specifically, on the BBQ dataset, NSG values range from 2.9% to 9.4%, indicating that utilizing explanations to simulate the behavior of the original model yields a statistically significant gain in predictive performance. This demonstrates that the provided explanations are not merely post-hoc rationalizations, but actively contribute to understanding and replicating the model’s decision-making process.
A Kendall’s W of 0.75 demonstrates substantial agreement between multiple predictor models when evaluating explanation faithfulness using Normalized Simulatability Gain (NSG). This statistic, derived from a non-parametric test for inter-rater reliability, indicates a strong level of consistency in how effectively different predictor models can simulate the original model’s behavior based solely on the provided explanations. A value approaching 1.0 signifies perfect agreement, and 0.75 confirms that the NSG metric is not unduly influenced by idiosyncrasies within any single predictor model, thereby bolstering its validity as a robust and reliable measure of explanation faithfulness.
Beyond the Story: Demanding Verifiable AI
Establishing trust in artificial intelligence necessitates more than simply understanding how a model arrives at a decision; it demands verifying the accuracy of that explanation. Faithfulness evaluation, a rigorous assessment of whether an AI’s stated reasoning genuinely reflects its internal decision-making process, is therefore paramount. Metrics like Normalized Shapley-value Gain (NSG) provide a quantifiable approach to this verification, pinpointing discrepancies between the explanation and the actual factors influencing the model’s output. Without such evaluation, explanations can be misleading ‘post-hoc rationalizations’ – offering a surface-level understanding that masks fundamental flaws or biases. Consequently, robust faithfulness evaluation, utilizing tools like NSG, isn’t merely an academic exercise; it is a critical prerequisite for the responsible deployment of AI systems in sensitive areas like healthcare, finance, and criminal justice, where accountability and reliability are non-negotiable.
AI models are increasingly capable of generating self-explanations – rationales accompanying their decisions, intended to illuminate the reasoning process. However, these explanations are not inherently trustworthy; a model can appear to justify its choices without actually basing them on the stated reasons. Consequently, rigorous validation is essential to determine ‘faithfulness’ – the degree to which the explanation accurately reflects the true determinants of the model’s output. Techniques like measuring the impact of removing explanation-relevant features, or comparing explanations to ground-truth reasoning when available, are crucial for assessing whether these self-generated insights are genuine reflections of internal logic or merely superficial justifications. Without such validation, relying on self-explanations risks misplaced trust and potentially harmful outcomes, especially as AI systems are deployed in sensitive applications.
Current approaches to understanding artificial intelligence often rely on ‘post-hoc’ interpretability – analyzing a model after it has made a decision to try and explain its reasoning. This is akin to reverse-engineering, and may not accurately reflect the actual processes driving the outcome. A shift towards verifiable explanations proposes building AI systems with ‘intrinsic transparency’ – designing models where the reasoning is inherently understandable and can be validated at each step. This necessitates a focus on mechanisms that allow for formal verification of the model’s logic, ensuring that explanations are not simply plausible narratives, but demonstrable truths about how the AI arrived at a specific conclusion. Such an approach promises a more robust and trustworthy form of artificial intelligence, moving beyond explanation as justification to explanation as inherent system property.
The successful implementation of trustworthy AI hinges on its application within high-stakes environments, and thus demands a convergence of robust evaluation metrics and verifiable explanation techniques. Critical domains – encompassing healthcare, finance, and autonomous systems – cannot afford the ambiguity of ‘black box’ decision-making; accountability requires understanding why an AI arrived at a particular conclusion. Integrating faithfulness evaluation, such as Normalized Shapley-value Gain, with self-explanatory AI models isn’t merely about increasing transparency, but about establishing a foundation for responsible deployment where errors can be traced, biases mitigated, and trust legitimately earned. Without this holistic approach, the potential benefits of artificial intelligence in these crucial sectors will remain unrealized, overshadowed by legitimate concerns about reliability and ethical implications.
The pursuit of explainable AI, as demonstrated by this paper’s focus on faithfulness and metrics like Normalized Simulatability Gain, often feels like building sandcastles against the tide. It’s a noble effort to understand the ‘why’ behind a model’s decision, yet production environments invariably introduce complexities unforeseen in the lab. Linus Torvalds observed, “Most programmers think that if their code works, they’re finished. The ones who are right are the exceptions.” This research, attempting to quantify how well a model’s self-explanation matches its actual reasoning, acknowledges this inherent tension. The goal isn’t perfect explanation – that’s an idealized diagram – but rather a compromise that survives contact with real-world data, a system that’s demonstrably, if imperfectly, simulatable.
So, What Breaks Next?
The introduction of Normalized Simulatability Gain (NSG) is, predictably, another attempt to quantify something fundamentally messy: why these large language models think what they think. It’s a neat metric, certainly, and the observation that self-explanations sometimes align with actual decision-making isn’t shocking. Production, as always, will reveal how useful this alignment truly is. One suspects that NSG, like its predecessors, will identify some explanations as ‘faithful’ right before those models confidently hallucinate a complete falsehood.
The real question isn’t whether explanations reflect the process – it’s whether that process is even remotely coherent enough to reflect. This work skirts the issue of inherent unreliability. The field seems content to build ever-more-elaborate tools to understand systems that may be fundamentally inscrutable. It’s a charmingly optimistic endeavor, reminiscent of medieval scholars debating the number of angels that could dance on the head of a pin.
Future research will, inevitably, focus on scaling these faithfulness metrics to even larger models, and applying them to increasingly complex tasks. The cycle will continue: build bigger, measure more, discover more ways things break. Everything new is old again, just renamed and still broken. The only constant is the alert queue.
Original article: https://arxiv.org/pdf/2602.02639.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
2026-02-05 03:28