Author: Denis Avetisyan
A new approach to pre-training discussion models focuses on understanding community norms to improve performance and overcome data limitations in social media analysis.
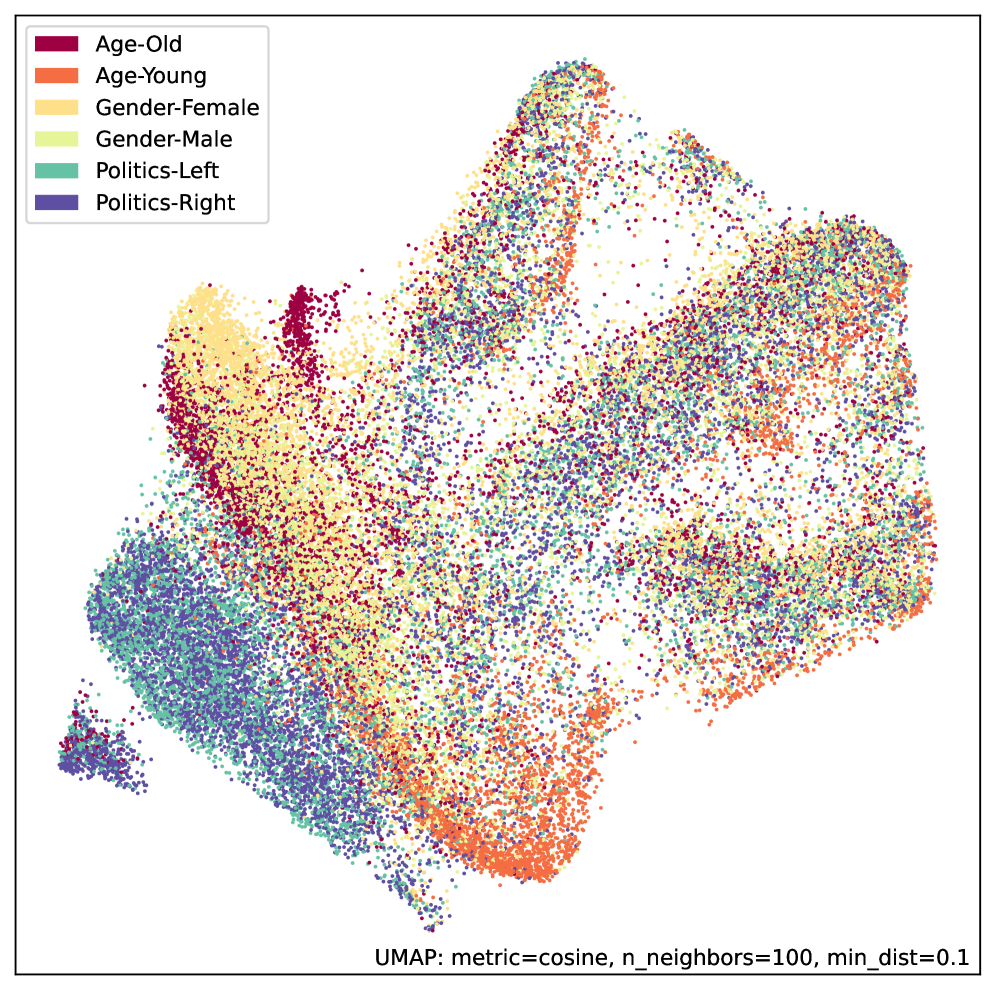
This work demonstrates how unsupervised pre-training leveraging community norms enhances Discussion Transformers for tasks like hate speech detection through contrastive and generative modeling.
Addressing the challenges of modelling complex online social dynamics is hampered by the reliance on scarce, labelled data for training effective Discussion Transformers. This work, ‘Community Norms in the Spotlight: Enabling Task-Agnostic Unsupervised Pre-Training to Benefit Online Social Media’, proposes a paradigm shift towards unsupervised pre-training, uniquely grounded in the explicit modelling of community norms. By leveraging these norms, we demonstrate improved contextual understanding and mitigate data scarcity, offering a path towards more robust and interpretable social media analysis. Could this approach unlock new opportunities for building AI systems that not only detect harmful content but also reflect a nuanced understanding of social context?
The Erosion of Sequential Understanding
Although contemporary language models demonstrate impressive capabilities in processing text, they often fall short when applied to the intricacies of conversational data. These models, largely built on sequential processing, treat dialogue as a linear progression of turns, neglecting the rich, interconnected relationships that define human conversation. A simple question, for instance, doesn’t exist in isolation; it’s linked to prior exchanges, shared knowledge, and unspoken social cues. Traditional architectures struggle to encode these non-linear dependencies, resulting in a flattened representation of the dialogue’s true structure and hindering their ability to grasp the full context of an interaction. Consequently, they may misinterpret user intent, generate irrelevant responses, or fail to maintain a coherent conversational flow, highlighting a fundamental limitation in their approach to understanding the complex web of relationships within a dialogue.
Conventional language models typically process conversations as linear sequences of text, a methodology that fundamentally restricts their comprehension of true dialogue structure. Human conversation isn’t simply a chain of utterances; it’s a complex, interconnected web where meaning arises not only from what is said, but how it relates to prior exchanges and unspoken social cues. This graph-like structure, with branching topics, implicit agreements, and shifting power dynamics, remains largely invisible to sequential processing. Consequently, these models struggle to infer speaker intent beyond the immediate turn, misinterpret subtle emotional shifts, or adequately model the collaborative nature of conversation – hindering their ability to engage in genuinely nuanced and contextually appropriate responses.
Current language pre-training techniques frequently prioritize predicting the next token in a sequence, a methodology that proves insufficient for grasping the extended context crucial in multi-turn dialogues. This limitation results in models struggling to maintain coherence and relevance as conversations unfold, as they often fail to adequately represent the evolving relationships between utterances beyond the immediately preceding turn. Consequently, these models exhibit diminished performance in tasks requiring an understanding of long-range dependencies, such as identifying coreference, tracking dialogue state, or generating contextually appropriate responses-effectively treating each turn as relatively isolated rather than part of a dynamic, interconnected exchange. The inability to fully capture this conversational history hinders their capacity to model nuanced social cues and implicit understandings that are naturally present in human interactions.
Mapping Relational Structures: A Shift in Perspective
Discussion Transformers utilize Graph Neural Networks (GNNs) to model conversations as relational structures. In this representation, each conversational turn is defined as a node within a graph. Edges connecting these nodes represent the relationships between turns, capturing dependencies and contextual links. This allows the model to move beyond treating conversations as linear sequences; instead, it explicitly encodes the connections – such as responses to questions, elaborations on prior statements, or topic shifts – as first-class elements of the data structure. The GNN then operates on this graph, propagating information between nodes based on the edge connections, enabling the model to consider the entire conversational history when processing each turn.
Sequential models, such as Recurrent Neural Networks (RNNs) and Transformers processing text linearly, struggle to represent non-sequential relationships inherent in conversation. Graph Neural Networks (GNNs) address this limitation by explicitly modeling conversational turns as nodes within a graph, and the relationships – such as responses to prior utterances, topic shifts, or coreference – as edges. This allows the model to directly reason about the conversational structure, capturing dependencies beyond simple adjacency. For example, a question can be directly linked to a distant answer, or multiple utterances can contribute to a single topic. Consequently, GNN-based models demonstrate improved performance on tasks requiring an understanding of long-range dependencies and complex conversational flows, surpassing the capabilities of models reliant on sequential processing of utterances.
Task-agnostic pre-training for graph transformers involves an initial training phase on large, unlabeled conversational datasets before adaptation to specific downstream tasks. This pre-training focuses on learning generalizable representations of dialogue structure and content, independent of any particular conversational goal – such as question answering or task completion. By first establishing a broad understanding of conversational dynamics, the model requires less task-specific data during fine-tuning and demonstrates improved performance across a wider range of conversational tasks and domains. This approach mitigates overfitting to individual tasks and enhances the model’s ability to generalize to unseen conversational scenarios.
Relational Pre-training: Excavating Conversational Nuance
Generative pre-training benefits from techniques that explicitly model relationships within conversational data. Node Feature Reconstruction compels the model to predict missing features of conversational nodes – representing utterances or participants – thereby requiring an understanding of how these nodes are interconnected and influence each other. Similarly, Edge-Level Reply Classification tasks the model with predicting the relationship – or ‘edge’ – between a given utterance and its reply, forcing it to learn the dependencies between conversational turns. These methods move beyond simple sequential prediction and encourage the model to capture the underlying relational structure present in dialogues, ultimately improving its understanding of conversational context and nuance.
Contrastive pre-training leverages the principle of learning by distinguishing between similar and dissimilar examples to refine a model’s understanding of conversational data. Discussion-Aware Contrastive Tasks specifically focus this learning on the nuances of conversational norms and user intent within a given dialogue context. By presenting the model with pairs of discussions – some adhering to established community guidelines and others violating them, or exhibiting differing communicative intents – the model learns to generate embeddings that reflect these subtle differences. This process allows the model to effectively discriminate between acceptable and unacceptable conversational behavior, as well as to interpret the underlying purpose of a given utterance, improving its ability to navigate and understand complex dialogues.
Preliminary results from our framework indicate successful differentiation of discussion embeddings based on inherent community norms, as evidenced by UMAP visualization. This separation was achieved through a substantial reduction in the dataset size of the Contextual Abuse Dataset (CAD); the original 1394 discussions and 27,487 labels were reduced by a factor of ten to a dataset containing 183 discussions and 2,765 labels, without discernible loss in the model’s ability to distinguish between discussions adhering to different community standards.
Beyond Pattern Matching: Towards Empathetic and Accountable AI
Current artificial intelligence frequently processes conversation as a sequence of words, missing the underlying framework that gives meaning to exchanges. However, recent advancements focus on enabling models to actively map conversational structure – identifying elements like question-answer relationships, topic shifts, and coreference resolution – rather than simply reacting to surface-level text. This shift allows the AI to move beyond merely recognizing keywords and toward understanding how information is presented and connected within a dialogue. By representing these structural elements, the models gain the capacity to infer unstated assumptions, anticipate conversational turns, and ultimately demonstrate a more robust and human-like comprehension of language, moving beyond pattern matching to genuine reasoning about the conversation itself.
The ability to dissect a model’s internal logic represents a significant leap towards Explainable AI. Rather than functioning as a ‘black box’, these advanced systems allow researchers to trace the specific steps taken to arrive at a particular decision. This isn’t simply about identifying what a model concluded, but understanding how it reached that conclusion – pinpointing the key pieces of information and the reasoning pathways that led to the output. By revealing this internal process, developers can then audit for biases, correct errors, and ensure the model’s behavior aligns with intended principles. Ultimately, this transparency fosters trust and accountability, crucial for deploying AI in sensitive applications where understanding the rationale behind decisions is paramount.
Artificial intelligence systems are increasingly being designed to not only process information, but to participate in social interactions, necessitating a deeper understanding of unwritten rules governing conversation. Research demonstrates that capturing these “community norms” – encompassing politeness, turn-taking, and sensitivity to context – is crucial for generating responses that are not simply grammatically correct, but also socially appropriate. This involves moving beyond identifying keywords to recognizing subtle cues, implicit meanings, and the potential for misinterpretation; an AI trained to respect these norms avoids potentially offensive or disruptive contributions, fostering more positive and productive dialogues. Consequently, the development of AI capable of navigating these complex social landscapes promises more trustworthy and harmonious human-computer interactions, ultimately allowing these systems to integrate seamlessly into diverse communities and contexts.
Navigating the Future: Resilience and Adaptability in Conversational AI
A significant challenge in advancing conversational AI lies in mitigating negative transfer, a phenomenon where pre-training a model on one task inadvertently diminishes its performance on another. This occurs because the learned representations, while beneficial for the initial task, can introduce biases or irrelevant features that hinder adaptation to new conversational contexts. Researchers are actively investigating regularization techniques – methods that constrain the model’s learning process – and robust evaluation protocols to identify and correct these detrimental effects. Careful assessment involves testing across a diverse range of conversational scenarios and employing metrics that specifically measure the model’s ability to generalize beyond its initial training data, ultimately striving to build systems that accumulate knowledge without sacrificing versatility.
Conversational AI systems currently operate with a static understanding of acceptable dialogue, yet community norms and conversational styles are perpetually shifting. Future development must prioritize dynamic adaptation, enabling these systems to learn and internalize evolving linguistic patterns and social cues in real-time. Beyond simply tracking keyword changes, this requires sophisticated models capable of discerning nuanced shifts in sentiment, humor, and acceptable topics. Furthermore, current systems often struggle with complex, multi-threaded conversations – those involving numerous participants and interwoven sub-topics. Research should focus on developing architectures that can effectively manage these intricate exchanges, maintaining context across multiple conversational strands and ensuring coherent, relevant responses for each participant, ultimately creating AI that feels genuinely responsive and socially aware.
The future of conversational AI extends beyond text, with ongoing research poised to integrate auditory and visual inputs for a more nuanced understanding of human communication. By processing speech intonation, facial expressions, and body language alongside textual content, these systems can move beyond simple keyword recognition to grasp the underlying intent and emotional state of the user. This multi-modal approach promises to unlock significantly more powerful and versatile interactions, enabling applications ranging from more empathetic virtual assistants and realistic gaming companions to advanced accessibility tools for individuals with communication challenges and sophisticated analysis of non-verbal cues in fields like healthcare and education. The convergence of these modalities represents a crucial step towards creating AI that truly understands – and responds to – the full spectrum of human expression.
The pursuit of robust social media analysis, as detailed in this work, hinges on understanding the subtle cues of community norms. The paper rightly emphasizes the limitations of relying solely on labeled data, given the evolving nature of online discourse. This approach echoes a timeless observation: “The eloquence of a man does not prove the truth of what he says.” Blaise Pascal penned these words, and they resonate profoundly with the challenges presented in the article. Just as discerning truth requires more than persuasive rhetoric, effective analysis of social media demands an understanding of context beyond surface-level content. The proposed unsupervised pre-training, by focusing on the underlying structure of online communities, seeks to move beyond mere ‘eloquence’ and towards a more substantial grasp of meaning – acknowledging that even the most articulate expression can be divorced from genuine understanding.
What Lies Ahead?
This work, in charting a course toward unsupervised pre-training informed by community norms, acknowledges an inherent truth: all datasets are, at once, chronicles of a specific moment and imperfect proxies for the ever-shifting dynamics they attempt to capture. The efficacy of Discussion Transformers, while promising, is tethered to the stability of those norms-a stability no social system truly possesses. Future iterations must account for norm drift, not as noise to be filtered, but as a fundamental characteristic of the medium itself.
The current emphasis on contrastive learning, while effective in establishing initial contextual boundaries, risks solidifying a static representation of ‘community.’ Deployment is merely a point on the timeline; the system’s true test lies in its ability to adapt-to recognize when the very foundations of acceptable discourse have subtly, or not so subtly, altered. A fruitful avenue for exploration resides in generative modeling approaches that actively simulate evolving norms, creating a feedback loop between observation and prediction.
Ultimately, the pursuit of robust social media analysis is not about achieving perfect categorization, but about building systems that age gracefully. The inevitable decay of data relevance demands a shift in focus-from seeking definitive answers to embracing probabilistic understanding. The system’s chronicle will always be incomplete, and its interpretations, provisional.
Original article: https://arxiv.org/pdf/2602.02525.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Gold Rate Forecast
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- The Best Former NFL Players Turned Actors, Ranked
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Silver Rate Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
- ONE PIECE Season 2 Confirms Sanji’s OTHER Backstory in the Live-Action
2026-02-04 18:47