Author: Denis Avetisyan
A new approach leverages principles of Newtonian dynamics within deep reinforcement learning algorithms to enhance financial trading strategies.

This review details how physics-informed neural networks, specifically Kolmogorov-Arnold networks, improve portfolio performance, stability, and risk-adjusted returns across diverse financial markets.
Despite the increasing sophistication of deep reinforcement learning (DRL) in financial applications, achieving stable training and robust generalization remains a persistent challenge, particularly in volatile markets. This work, ‘The Enhanced Physics-Informed Kolmogorov-Arnold Networks: Applications of Newton’s Laws in Financial Deep Reinforcement Learning (RL) Algorithms’, introduces a novel framework that integrates physics-informed regularization-inspired by Newtonian dynamics-into DRL algorithms for portfolio optimization. By employing Kolmogorov-Arnold Networks with a second-order temporal consistency loss, we demonstrate consistently superior cumulative returns, Sharpe ratios, and drawdown characteristics across diverse equity markets-China, Vietnam, and the United States. Could this approach, grounding financial decision-making in fundamental physical principles, unlock a new paradigm for stable and profitable algorithmic trading?
The Illusion of Static Equilibrium
Conventional portfolio allocation strategies frequently operate under simplifying assumptions that limit their effectiveness in genuine market conditions. These methods often presume constant volatility and neglect the tangible costs associated with buying and selling assets – transaction fees, for example. However, financial markets are inherently dynamic; volatility fluctuates, correlations shift, and trading isn’t free. Consequently, a portfolio constructed using static models may quickly become misaligned with prevailing conditions, leading to missed opportunities or unnecessary risk. The reliance on historical data, while convenient, fails to account for structural breaks and unforeseen events that routinely reshape investment landscapes, underscoring the need for more responsive and realistic approaches to portfolio management.
Effective portfolio optimization in modern financial landscapes demands strategies that move beyond static models and embrace continuous adaptation. Research indicates that traditional approaches, built on assumptions of constant market conditions, often falter when confronted with the inherent dynamism of real-world trading. Consequently, advanced methodologies are being developed to incorporate realistic constraints – such as transaction costs, liquidity limitations, and investor risk preferences – directly into the optimization process. These adaptive techniques allow portfolios to respond intelligently to evolving market signals, rebalancing allocations not just to maximize returns, but also to minimize the impact of trading friction and maintain alignment with long-term investment goals. The result is a more robust and practical approach to portfolio management, better equipped to navigate the complexities of contemporary financial markets and deliver sustainable performance.
Financial models frequently underestimate the impact of real-world trading frictions, leading to potentially flawed investment strategies. Market inertia – the tendency of asset prices to resist change – and transaction costs, including brokerage fees and the bid-ask spread, collectively diminish expected returns. A portfolio continually rebalanced to theoretical optimal weights, without accounting for these factors, incurs unnecessary expenses and can even trigger adverse price movements due to its own trading activity. Consequently, ignoring these practical considerations not only erodes profitability but also introduces a hidden layer of risk, as the actual performance deviates from model predictions and exposes investors to unexpected losses. A robust portfolio optimization process must therefore incorporate realistic estimates of both market inertia and the full spectrum of trading costs to achieve sustainable, risk-adjusted returns.
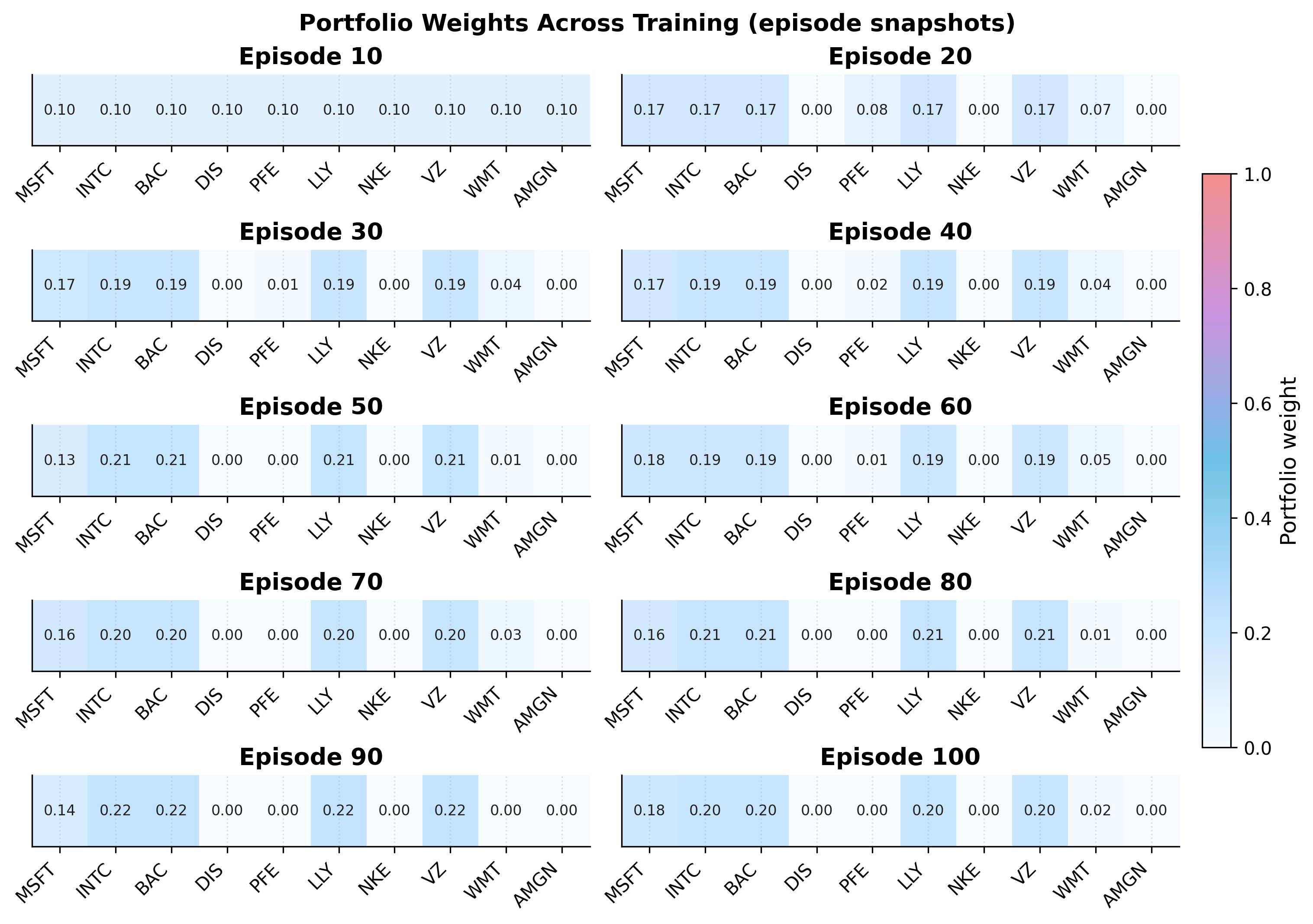
The Rise of Adaptive Agents
Deep Reinforcement Learning (DRL) provides a computational framework for developing intelligent agents capable of making a series of decisions to achieve a long-term goal within a defined environment. Unlike traditional rule-based systems, which rely on explicitly programmed instructions, DRL agents learn through trial and error, receiving rewards or penalties for their actions. This allows them to adapt to complex, dynamic environments where pre-defined rules may be insufficient or impractical to create. The core principle involves an agent interacting with an environment, observing its state, taking an action, receiving a reward, and updating its internal policy to maximize cumulative reward over time. This learning process enables DRL agents to solve problems that are difficult or impossible for rule-based systems to address effectively, particularly in scenarios characterized by uncertainty and high dimensionality.
Deep reinforcement learning algorithms such as Deep Deterministic Policy Gradient (DDPG), Proximal Policy Optimization (PPO), Twin Delayed DDPG (TD3), and Advantage Actor-Critic (A2C) utilize deep neural networks to function as universal function approximators. These networks learn to map states to actions, or to estimate the value of being in a given state, enabling the agent to derive a policy. The objective of these algorithms is to maximize the cumulative reward received over time, achieved through iterative adjustments to the network weights via gradient descent. DDPG and TD3 are suited for continuous action spaces, while PPO and A2C effectively handle both discrete and continuous actions, employing techniques like policy clipping or advantage estimation to improve stability and sample efficiency during training.
Standard Deep Reinforcement Learning (DRL) methodologies frequently require substantial datasets for effective training, often necessitating extensive simulation or real-world interaction to achieve acceptable performance. This data dependency stems from the need to accurately estimate value functions and policy gradients. Furthermore, these algorithms can exhibit limited generalization capabilities when confronted with conditions differing significantly from those encountered during training; slight deviations in market dynamics, asset correlations, or trading volumes can lead to suboptimal or even detrimental decision-making. This lack of robustness is particularly problematic in dynamic environments where unforeseen events or regime shifts are common, requiring either continuous retraining or the implementation of techniques to improve out-of-sample performance, such as regularization or domain randomization.
Grounding Intelligence in First Principles
Physics-Informed Neural Networks (PINNs) function as regularizers within Deep Reinforcement Learning (DRL) frameworks by embedding known physical principles – such as those described by F = ma – directly into the model’s loss function. This approach constrains the solution space, guiding the DRL agent towards policies that adhere to established market dynamics and reducing the likelihood of unrealistic or unstable behavior. By penalizing deviations from these pre-defined physical laws, PINNs effectively improve the generalizability and robustness of the learned policy, particularly in environments where data is limited or noisy. This regularization effect enhances the algorithm’s ability to navigate complex financial landscapes and promotes solutions consistent with fundamental economic principles.
The integration of Kolmogorov-Arnold Networks (KANs) with Physics-Informed Neural Networks (PINNs) provides enhancements to model performance through the utilization of spline-based function approximation. KANs represent functions as a sum of radial basis functions, allowing for efficient representation of smooth functions with fewer parameters compared to traditional neural networks. This reduction in parameters directly contributes to improved computational efficiency and faster training times. Furthermore, the spline-based nature of KANs increases model interpretability by providing a more transparent and understandable functional representation, facilitating analysis of the learned relationships between inputs and outputs within the physics-informed framework. This approach allows for a balance between the data-driven capabilities of PINNs and the analytical advantages of spline-based methods.
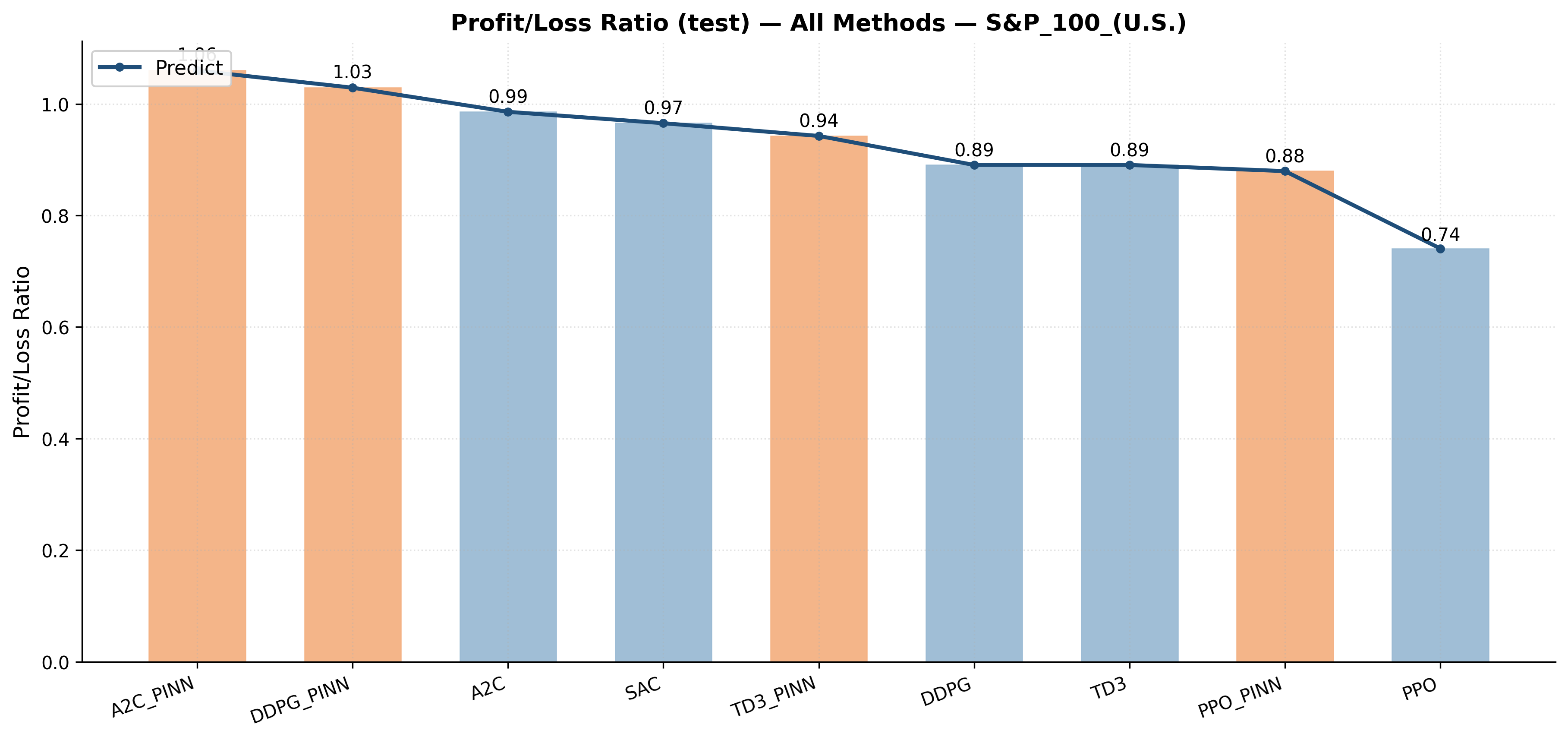
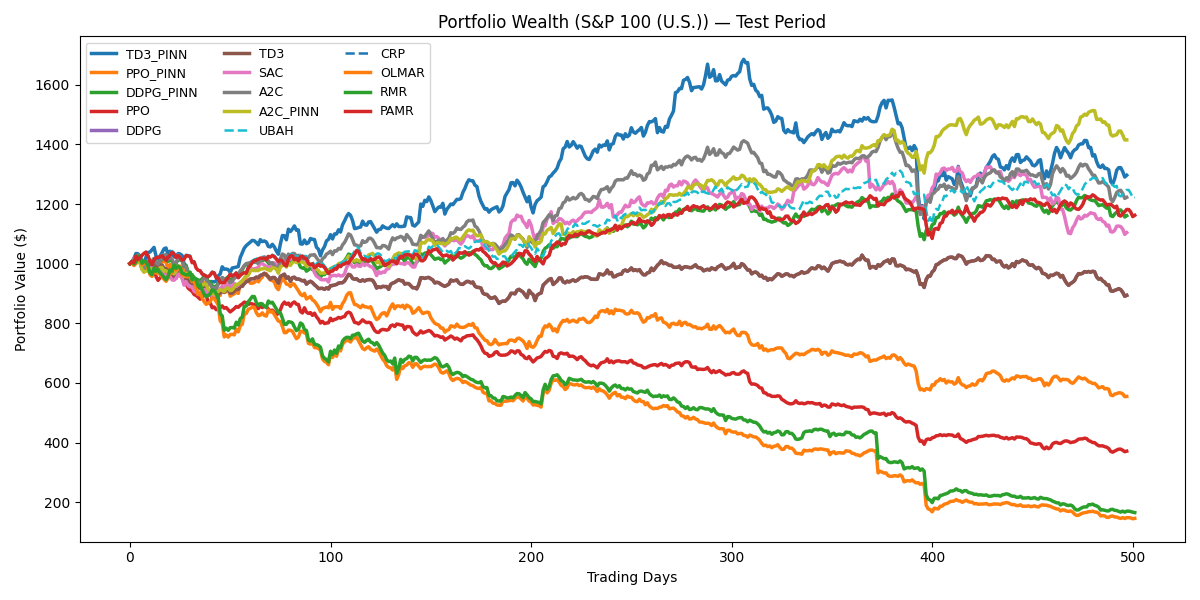
Empirical results demonstrate that the integration of Physics-Informed Neural Networks (PINNs) improves the performance of several Deep Reinforcement Learning (DRL) algorithms when applied to dynamic portfolio optimization. Specifically, tests conducted on the U.S. market show that the A2C algorithm, when combined with a PINN (A2C_PINN), achieves a Sharpe Ratio of 1.54. This represents a significant improvement over the standard A2C algorithm’s Sharpe Ratio of 0.36 in the same environment. Performance gains were also observed with DDPG, PPO, and TD3, indicating a generalizable benefit from incorporating physics-informed regularization into the DRL training process.
Beyond Simple Gains: Measuring True Resilience
Evaluating investment success extends beyond simply tallying cumulative returns; a truly comprehensive assessment demands consideration of the risks undertaken to achieve those gains. Metrics like the Sharpe Ratio quantify risk-adjusted returns, revealing whether the profits generated are commensurate with the level of volatility endured. Conversely, downside risk measures, such as Maximum Drawdown, highlight the potential for loss – specifically, the largest peak-to-trough decline an investment might experience. These tools are essential because a high return achieved through excessive risk isn’t necessarily desirable, and failing to account for potential losses can paint an overly optimistic picture of performance. By incorporating these risk-adjusted and downside metrics, investors gain a more nuanced and realistic understanding of their portfolio’s true effectiveness and resilience.
Evaluating investment strategies solely on cumulative returns presents an incomplete picture of performance; a truly comprehensive assessment demands consideration of risk. While gains are desirable, the potential for loss is an inherent part of investing, and metrics beyond simple returns quantify this exposure. Tools like the Sharpe Ratio, which measures risk-adjusted return, and downside risk measures, such as Maximum Drawdown – the largest peak-to-trough decline – provide crucial insights into how efficiently an investment generates returns relative to the risk undertaken. By factoring in these elements, investors gain a more nuanced understanding of an investment’s true performance, enabling more informed decisions and a clearer picture of whether returns justify the level of risk assumed.
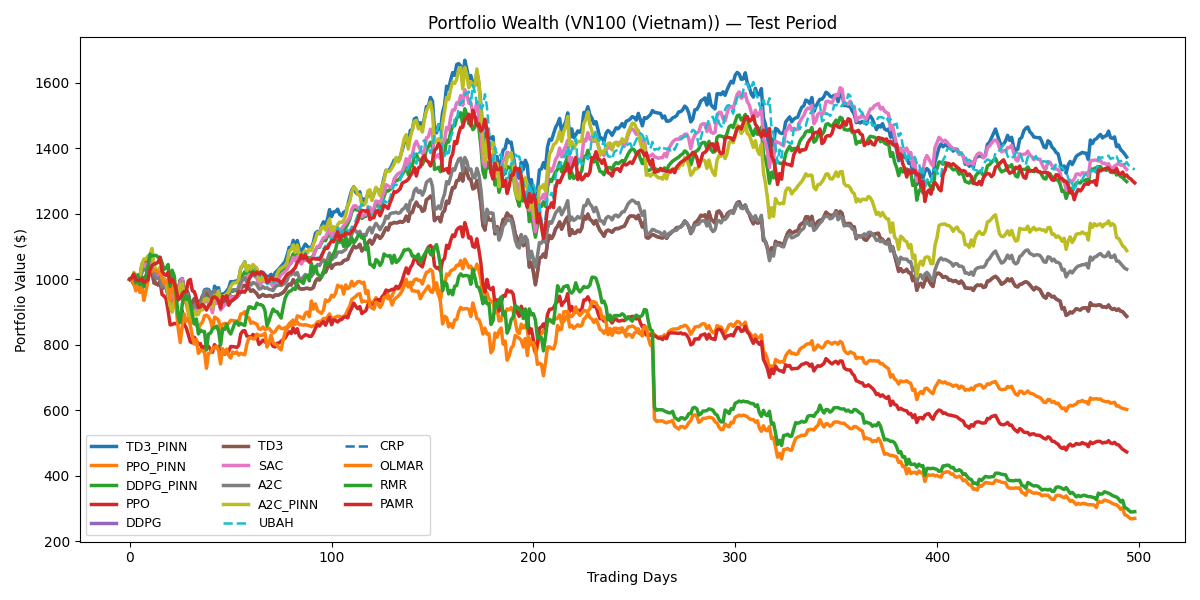
Recent advancements demonstrate that combining physics-informed deep reinforcement learning (DRL) with rigorous performance evaluation yields demonstrably improved portfolio allocation strategies. Specifically, the A2C_PINN algorithm achieved a 44.66% cumulative return in the U.S. market, a significant 10.42% increase over standard A2C implementations. Further highlighting this approach, the TD3_PINN algorithm generated a Sharpe Ratio of 0.68 in the Vietnam market, a substantial improvement over the -0.28 ratio achieved by a standard TD3 algorithm. These results suggest that integrating physics-informed principles into DRL not only enhances potential gains but also promotes greater stability and adaptability in navigating complex financial landscapes.
The pursuit of algorithmic stability, as demonstrated in this work concerning physics-informed reinforcement learning, echoes a fundamental truth about complex systems. It isn’t enough to simply build a portfolio optimization strategy; one must cultivate an ecosystem resilient to the inevitable fluctuations of financial markets. The authors’ integration of Newtonian dynamics serves not as a rigid constraint, but as a guiding force, acknowledging the inherent momentum and inertia within these systems. As Ada Lovelace observed, ‘The Analytical Engine has no pretensions whatever to originate anything.’ This research similarly reveals that true innovation doesn’t lie in inventing entirely new algorithms, but in thoughtfully combining established principles – in this case, physics and deep learning – to yield emergent behavior. The system doesn’t promise freedom from volatility; it merely offers a more graceful navigation of its forces, a temporary caching of failures before the next inevitable disruption.
The Drift and the Fracture
The grafting of Newtonian mechanics onto the volatile substrate of financial markets feels, inevitably, like attempting to chart the course of clouds. This work suggests a fleeting order, a momentary stabilization, but it does not erase the underlying chaos. The architecture isn’t structure – it’s a compromise frozen in time, a particular answer to questions the market will soon redefine. The improvements in portfolio performance are, in a sense, a testament not to the power of the model, but to the persistent inefficiency of markets themselves.
Future iterations will undoubtedly focus on more complex physical analogies – perhaps Lagrangian mechanics, or even the unsettling symmetries of quantum field theory. But the fundamental problem remains: these are external constraints imposed on a system that thrives on internal contradiction. Technologies change, dependencies remain. The true challenge lies not in refining the physics, but in acknowledging the limits of its application.
One suspects the real innovation won’t be in building more elaborate models, but in developing methods to gracefully accept – and even exploit – their inevitable failure. The market doesn’t want to be solved. It wants to evolve, to fracture, and to rebuild itself in forms we cannot yet foresee. The art, then, is not prediction, but adaptation.
Original article: https://arxiv.org/pdf/2602.01388.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Trading Crypto with AI: A New Approach to Portfolio Management
- 15 Films That Were Shot Entirely on Phones
- Why Won’t It Just *Do* What You Ask? Unpacking the Quirks of AI Language
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- Thinking Before Acting: A Self-Reflective AI for Safer Autonomous Driving
2026-02-03 17:28