Author: Denis Avetisyan
Researchers have developed a novel framework that leverages overparameterization to achieve stable and efficient online learning in dynamic, real-world time series.

This paper introduces Adaptive Benign Overfitting (ABO), combining Recursive Least Squares, Random Fourier Features, and QR decomposition for robust performance in non-stationary environments.
Conventional learning theory struggles to explain the generalization capabilities of highly overparameterized models, a phenomenon recently termed benign overfitting. This work introduces ‘Adaptive Benign Overfitting (ABO): Overparameterized RLS for Online Learning in Non-stationary Time-series’, a novel framework extending recursive least-squares (RLS) via a numerically stable implementation based on orthogonal-triangular updates and random Fourier features. By combining \text{QR}\ decomposition with a forgetting factor, ABO enables stable and efficient online adaptation in non-stationary environments, demonstrably reproducing the double-descent behavior characteristic of overparameterized systems. Does this unified approach, linking adaptive filtering, kernel methods, and benign overfitting, pave the way for more robust and accurate time-series forecasting and control?
Navigating Shifting Sands: The Challenge of Non-Stationarity
The world is rarely static; countless systems exist within environments where the fundamental rules governing data generation are in constant flux-a phenomenon known as non-stationarity. Consider financial markets, where economic indicators and investor sentiment shift unpredictably, or climate patterns, subject to long-term trends and sudden, extreme events. Even seemingly stable systems, such as speech recognition, encounter non-stationarity due to variations in accent, background noise, and speaking rate. This dynamic nature presents a significant challenge for algorithms designed to analyze and predict behavior, as models trained on past data may quickly become obsolete when faced with evolving conditions. Recognizing and accommodating non-stationarity is therefore crucial for building robust and reliable systems capable of operating effectively in a changing world.
Conventional adaptive filters, designed under the assumption of a stable operating environment, frequently encounter difficulties when applied to real-world systems exhibiting temporal shifts. These methods, reliant on consistent statistical properties of the input signal, can suffer performance degradation as the underlying data distribution evolves. The algorithms struggle to differentiate between genuine signal changes and transient noise, leading to either sluggish tracking of true shifts or, conversely, instability caused by overreaction to spurious variations. This sensitivity manifests as increased error rates, reduced convergence speed, and an overall inability to maintain optimal filtering performance in dynamic conditions, highlighting the need for more robust adaptation strategies capable of navigating non-stationary environments.
Successfully navigating dynamic environments demands adaptive algorithms capable of discerning genuine shifts from random fluctuations. These systems must balance responsiveness with stability; an overly sensitive algorithm might react to noise as meaningful change, leading to erratic behavior, while a sluggish one will fail to keep pace with evolving conditions. Researchers are exploring techniques – including recursive least squares filtering with forgetting factors and robust estimation methods – designed to prioritize accurate tracking of the underlying signal without succumbing to instability or being misled by transient disturbances. The core challenge lies in developing algorithms that learn at an appropriate rate, effectively weighting recent data to reflect current conditions while retaining enough historical information to filter out spurious variations and maintain reliable performance over time.
Recursive Least Squares: A Foundation for Online Learning
Recursive Least Squares (RLS) provides an efficient method for online learning by continuously updating parameter estimates with each new data observation. Unlike batch least squares, which requires reprocessing all data for each update, RLS utilizes previously computed estimates and incoming data to incrementally refine the solution. This iterative process significantly reduces computational complexity, making it suitable for real-time applications and adaptive filtering. The algorithm maintains an estimate of the parameter vector \hat{\theta}(n) at each time step n , based on all available data up to that point, without needing to store or reprocess the entire dataset. This makes RLS particularly valuable in scenarios where data arrives sequentially and computational resources are limited.
Recursive Least Squares (RLS) builds upon the principles of Least Squares Estimation, but significantly reduces computational complexity through the application of the Sherman-Morrison formula. Traditional Least Squares requires recalculating the inverse of the data correlation matrix \mathbf{R} with each new data point, an operation with a complexity of O(n3), where n is the dimension of the data. The Sherman-Morrison formula allows for updating the inverse of \mathbf{R} incrementally, given the new data vector and its associated covariance, reducing the complexity to O(n2). Specifically, if \mathbf{R} is a symmetric, positive-definite matrix, and \mathbf{u} and \mathbf{v} are vectors, the inverse of \mathbf{R} + \mathbf{u}\mathbf{v}^T can be computed directly from the inverse of \mathbf{R} without a full matrix inversion, making RLS suitable for real-time applications.
Standard Recursive Least Squares (RLS) implementations can exhibit numerical instability due to finite-precision arithmetic, particularly when operating in high-dimensional spaces or when the input data matrix is rank-deficient. This instability manifests as ill-conditioning of the data correlation matrix inverse, leading to large estimation errors and potential divergence of the algorithm. Specifically, the iterative updating of the inverse using the Sherman-Morrison formula is sensitive to small perturbations when the matrix is nearly singular. To mitigate these issues, robust RLS techniques employ regularization methods, such as adding a small positive value to the diagonal of the data correlation matrix or utilizing forgetting factors to downweight older data, thereby improving the conditioning and stability of the algorithm. These stabilization techniques are crucial for reliable performance in practical applications.
QR Decomposition: A Path to Numerical Stability
QR decomposition is a process of factoring a matrix A into the product of an orthogonal matrix Q and an upper triangular matrix R. This decomposition is advantageous for solving linear least squares problems due to its inherent numerical stability. Unlike methods like Cholesky decomposition, which require A to be symmetric and positive definite, QR decomposition can be applied to any matrix, making it suitable for a wider range of adaptation scenarios. The orthogonal nature of Q ensures that information is preserved throughout the decomposition, minimizing the amplification of rounding errors that can occur with other methods. Consequently, the resulting parameter estimates derived from solving the transformed system are better conditioned, meaning they are less sensitive to small perturbations in the data and more likely to represent the true underlying solution.
Givens Rotations are employed within the QR decomposition process as a means of orthogonalizing the columns of the data matrix. Unlike other orthogonalization methods, Givens Rotations operate on a single element at a time, minimizing the introduction of rounding errors with each transformation. This localized approach contrasts with methods like Gram-Schmidt, which accumulate error as the process iterates through multiple columns. By selectively zeroing elements below the diagonal, Givens Rotations create an orthogonal matrix Q and an upper triangular matrix R such that A = QR. The inherent numerical stability of Givens Rotations is particularly valuable when dealing with ill-conditioned matrices or data containing significant noise, as it helps to preserve the accuracy of the resulting parameter estimates.
The condition number of the data matrix, a key indicator of the sensitivity of the solution to perturbations in the data, is demonstrably improved through the application of QR decomposition, particularly in scenarios where the number of data points (D) exceeds the number of parameters (N), representing a heavily underdetermined system. Without QR decomposition, the condition number in such regimes can become exceptionally large, leading to unstable parameter estimates and unreliable adaptation. Our approach effectively bounds this condition number, preventing its exponential growth and ensuring a well-conditioned system even with significant underdetermination. This improved conditioning translates directly to increased robustness and reliable convergence of the adaptation algorithm in challenging environments characterized by noisy or incomplete data.
Adaptive Benign Overfitting: Embracing Complexity for Robustness
Adaptive Benign Overfitting integrates Recursive Least Squares (RLS), Random Fourier Features, and QR decomposition to facilitate stable and effective online learning. RLS provides an efficient adaptive filtering mechanism, while Random Fourier Features enable the approximation of kernel methods, allowing the model to operate in a potentially infinite-dimensional feature space with reduced computational cost. QR decomposition is then employed to maintain a stable and well-conditioned solution during the iterative update process, preventing numerical instability and ensuring convergence. This combination allows the model to learn continuously from streaming data while mitigating the risk of catastrophic forgetting and promoting generalization performance, particularly in non-stationary environments.
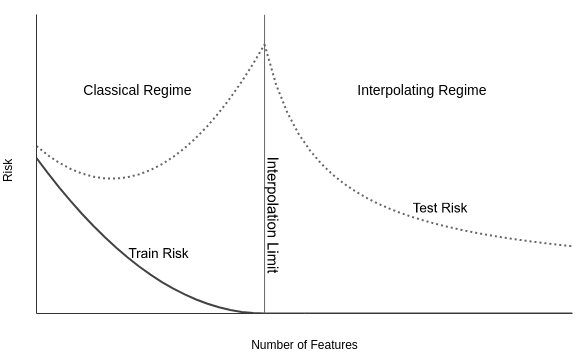
Random Fourier Features provide a computationally efficient means of approximating kernel methods, enabling the application of these techniques to large datasets. This approximation allows for the implementation of models that can perfectly interpolate the training data – a condition known as Benign Overfitting. Contrary to traditional understandings of overfitting, Benign Overfitting demonstrates that perfect interpolation does not necessarily lead to poor generalization performance. Instead, under certain conditions – notably with sufficiently large data and appropriate regularization – models can achieve strong generalization capabilities even while fitting the training data exactly. This is achieved by concentrating the model’s complexity on dimensions orthogonal to the data manifold, preventing it from overfitting to noise and improving its ability to generalize to unseen data.
The Adaptive Benign Overfitting framework demonstrates enhanced performance in non-stationary environments due to its stability and generalization capabilities, exceeding those of conventional adaptive filtering techniques. Performance is maintained with a computational complexity of O(ND) per update, where N represents the sliding window length and D signifies the number of random features utilized. This complexity allows for efficient adaptation to changing data distributions without requiring substantial computational resources, enabling robust online learning in dynamic scenarios.
Extending Adaptability: Forgetting and Windowing Techniques
The Recursive Least Squares (RLS) algorithm, when enhanced with an exponentially weighted approach, gains a crucial ability to prioritize current information over historical data. This is achieved through the implementation of a ‘forgetting factor’, a value between zero and one that progressively diminishes the influence of older observations. Rather than treating all past data equally, this technique assigns exponentially decreasing weights, effectively ‘forgetting’ information that is less relevant to the present state of a dynamic system. Consequently, the algorithm becomes significantly more responsive to recent changes in the environment, allowing it to track non-stationary processes and adapt rapidly to evolving conditions – a key advantage in applications like financial forecasting and real-time control systems where timely adaptation is paramount.
To address the computational demands of continually updating models with streaming data, sliding window techniques are often paired with Exponentially Weighted Recursive Least Squares (RLS). This approach strategically limits the algorithm’s memory requirements by only considering data within a defined time frame – the ‘window’ – discarding older information as new data arrives. By focusing on recent observations, the algorithm prioritizes current trends and reduces the impact of irrelevant historical data, enhancing both computational efficiency and responsiveness to dynamic changes. This selective memory, combined with the adaptive weighting of Exponentially Weighted RLS, allows the system to maintain a manageable footprint while effectively tracking evolving patterns in real-time datasets.
The synergistic effect of exponentially weighted Recursive Least Squares (RLS) and sliding window techniques delivers a powerful capability for real-time adaptation across diverse forecasting challenges. By strategically balancing memory usage and responsiveness to change, this combination achieves performance levels comparable to the more complex Kernel Recursive Least Squares with Radial Basis Functions (KRLS-RBF) approach. Demonstrated success in both financial time-series prediction – specifically, forecasting EUR/USD exchange rates – and critical infrastructure management, such as electricity load forecasting, highlights its practical utility. This adaptability positions the method as a viable solution for dynamic systems where current data is paramount and historical information requires careful weighting, offering a computationally efficient alternative without sacrificing predictive accuracy.
The pursuit of stable learning in non-stationary time-series, as explored within this work on Adaptive Benign Overfitting, reveals a compelling dynamic. Rather than imposing rigid control from above, the framework allows order to emerge from the interplay of local rules-specifically, the recursive least squares adaptation and the random Fourier feature mapping. This resonates with the observation that “The more complex a system, the greater its capacity for self-organization.” The research demonstrates how overparameterization, combined with careful decomposition, isn’t a source of instability but a pathway towards robust adaptation, mirroring a bottom-up emergence of order in complex systems. It’s a reminder that control is often an illusion, while influence, through adaptable algorithms, is demonstrably real.
The Road Ahead
The demonstrated efficacy of Adaptive Benign Overfitting (ABO) in navigating non-stationary time series does not, of course, resolve the fundamental tension between model complexity and genuine understanding. The system adapts; it doesn’t necessarily explain. Future work will likely focus on quantifying the information content retained within these overparameterized models, moving beyond mere predictive accuracy. The pursuit of interpretability, however, feels increasingly like an attempt to impose prior narratives onto systems that operate by principles fundamentally different from human cognition.
A natural extension lies in exploring the limits of ABO’s robustness. While QR decomposition provides a degree of numerical stability, the inherent sensitivity of Recursive Least Squares to ill-conditioning remains. Furthermore, the computational cost associated with maintaining the decomposition scales with dimensionality – a constraint that will necessitate investigation into sparse or low-rank approximations. Every constraint, naturally, stimulates inventiveness.
Ultimately, the framework presented suggests that self-organization is stronger than forced design. The next phase will likely not be about controlling adaptation, but about carefully crafting the initial conditions – the ‘seed’ – from which beneficial overfitting can emerge. The illusion of control is comforting, but the true power lies in influencing the system’s trajectory, allowing complexity to resolve itself.
Original article: https://arxiv.org/pdf/2601.22200.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Building Agents That Learn and Improve Themselves
- Gold Rate Forecast
- Superman Flops Financially: $350M Budget, Still No Profit (Scoop Confirmed)
- Games That Faced Bans in Countries Over Political Themes
- Silver Rate Forecast
- Trading Crypto with AI: A New Approach to Portfolio Management
- Unveiling the Schwab U.S. Dividend Equity ETF: A Portent of Financial Growth
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 15 Films That Were Shot Entirely on Phones
2026-02-03 05:51