Author: Denis Avetisyan
A new technique leverages subtle color patterns inherent in real camera sensors to reliably identify images created by artificial intelligence.
Demosaicing-guided color correlation training achieves state-of-the-art generalization in AI-generated image detection by exploiting artifacts of the camera imaging pipeline.
Despite advances in AI-generated image detection, current methods struggle to generalize across diverse generative models due to a lack of focus on fundamental imaging characteristics. This work, ‘Color Matters: Demosaicing-Guided Color Correlation Training for Generalizable AI-Generated Image Detection’, addresses this limitation by exploiting the inherent color correlations introduced by the camera imaging pipeline, specifically the color filter array (CFA) and demosaicing process. We introduce a novel training framework, DCCT, which leverages these correlations to identify provable distributional differences between photographic and AI-generated images, achieving state-of-the-art generalization and robustness. Could a deeper understanding of these fundamental imaging properties unlock even more effective and resilient techniques for digital content authentication?
The Evolving Landscape of Synthetic Imagery
Recent breakthroughs in machine learning have fueled a remarkable surge in the capabilities of image generation models. Generative Adversarial Networks (GANs) and, more recently, Diffusion Models, now produce synthetic images with a fidelity previously unattainable. These models learn the underlying patterns and distributions within image datasets, allowing them to create entirely new visuals that are often indistinguishable from photographs captured by conventional means. The sophistication of these algorithms extends beyond simple replication; they can synthesize images exhibiting complex scenes, diverse objects, and even stylistic variations, effectively blurring the line between reality and artificial creation. This rapid progress, while demonstrating impressive technological achievement, presents significant challenges regarding the authenticity and trustworthiness of digital imagery.
The proliferation of synthetic media presents a growing challenge to the veracity of visual information, demanding new strategies for discerning authenticity. As increasingly sophisticated algorithms generate images virtually indistinguishable from reality, the potential for misinformation and manipulation escalates significantly. This erosion of trust extends beyond simple deception; it impacts critical sectors reliant on visual evidence, including journalism, legal proceedings, and scientific research. Maintaining public confidence in photographs and videos requires robust detection methods and a heightened awareness of the capabilities – and potential abuses – of artificial intelligence in image creation. The ability to reliably verify the origin and integrity of visual content is no longer merely a technical problem, but a societal imperative for navigating an increasingly digital world.
Conventional image forensics, built on detecting inconsistencies in lighting, noise patterns, and compression artifacts, are proving increasingly ineffective against the latest synthetic media. As generative models like diffusion models and GANs mature, they produce images with remarkably few of the telltale flaws previously exploited by detection algorithms. These advanced techniques skillfully replicate the complex statistical properties of natural images, subtly embedding artifacts that are either imperceptible to the human eye or indistinguishable from those arising from real-world image capture and processing. Consequently, established methods, which rely on identifying deviations from expected image characteristics, frequently fail to differentiate between authentic photographs and meticulously crafted AI-generated content, creating a significant challenge for verifying the integrity of visual information.

Discerning the Authentic: Strategies for Image Analysis
Artifact-Based Detection and Generic Representation-Based Detection represent two primary strategies for identifying machine-generated images by analyzing inherent inconsistencies. Artifact-Based Detection focuses on specific, known flaws commonly introduced during the image generation process – such as inconsistencies in lighting, shadows, or textures – and trains classifiers to recognize these patterns. Generic Representation-Based Detection, conversely, aims to learn a generalizable representation of natural images and then identify synthetic images as those that deviate significantly from this learned distribution. Both approaches rely on the premise that current generative models, despite advancements, still struggle to perfectly replicate the complex statistical properties of real-world images, leading to detectable anomalies in the frequency or spatial domains.
High-pass filtering techniques, particularly the Spectral Residual Method (SRM), operate on the principle that synthetic images often exhibit differences in frequency components compared to natural images. SRM decomposes an image into its magnitude and phase spectra, then reconstructs the image using only the magnitude spectrum of a reference image and the phase spectrum of the input image. Discrepancies in the high-frequency details, which are crucial for realistic texture and edges, become apparent in the resulting spectral residual. These residuals highlight areas where the input image’s high-frequency information deviates from the reference, effectively revealing subtle inconsistencies introduced during the generation process. The method is sensitive to even minor frequency domain artifacts that may not be visually obvious, providing a quantifiable metric for detecting synthetic content.
One-Class Anomaly Detection (OAD) techniques operate on the principle of establishing a robust model of naturally occurring, or “normal,” image data distributions. This modeling process typically involves extracting relevant features from a training set of authentic images and learning the boundaries of their expected variation using algorithms such as Support Vector Data Description (SVDD) or autoencoders. Subsequently, generated or potentially synthetic images are evaluated against this established model; deviations exceeding a predefined threshold, indicating an out-of-distribution sample, are flagged as anomalies. The efficacy of OAD hinges on the accurate representation of the normal distribution and the selection of an appropriate anomaly score threshold to minimize false positives and false negatives during detection.

DCCT: A Physics-Informed Approach to Detection
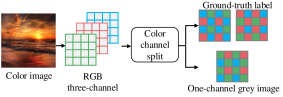
The DCCT framework is fundamentally based on the mechanics of digital image creation, beginning with the Color Filter Array (CFA) sensor commonly found in digital cameras. These sensors utilize a mosaic of color filters – typically red, green, and blue – arranged over the sensor’s photodiodes. Because each photodiode only captures the intensity of a single color, a process called demosaicing is required to reconstruct a full-color image. This reconstruction relies on interpolating color values for each pixel based on the surrounding sampled colors. The DCCT framework analyzes the inherent characteristics of this demosaicing process, recognizing that artificially generated or manipulated images will exhibit statistical anomalies in the color correlations resulting from interpolation, differing from those observed in naturally sampled images.
The DCCT framework differentiates between authentic and synthetic images by examining the statistical relationships between color channels in a captured image. Natural images exhibit specific color correlations resulting from the physics of light interaction with surfaces and the sensor’s sampling process. Conversely, artificially generated or manipulated images often present altered or unrealistic color relationships. To quantify this, the framework employs a U-Net architecture for pixel-wise segmentation, enabling it to identify regions exhibiting anomalous color patterns. This segmentation process highlights areas where the color correlations deviate from those typically observed in naturally sampled images, effectively serving as a signature of image manipulation or artificial generation.
The DCCT framework statistically models color correlations using a Mixture of Logistic Functions (MLF). This approach represents the probability distribution of color channel relationships as a weighted sum of logistic distributions, allowing for flexible modeling of complex color dependencies present in natural images. To quantify the difference between the predicted and ground truth color correlation distributions, the framework employs Wasserstein Distance – also known as Earth Mover’s Distance. Wasserstein Distance provides a robust metric for comparing probability distributions, particularly when they may not have overlapping support, offering a more perceptually relevant measure of dissimilarity than traditional metrics like L_2 distance.

Rigorous Validation and Performance Benchmarking
The DCCT framework’s evaluation incorporated ImageNet and MSCOCO datasets to ensure testing against diverse, real-world imagery. ImageNet, containing over 14 million images categorized into over 20,000 classes, provides a broad spectrum of object recognition challenges. MSCOCO, with its focus on object detection, segmentation, and captioning, introduces complexities related to scene understanding and object relationships. Utilizing these datasets allowed for assessment of the DCCT framework’s performance across various visual scenarios, including variations in lighting, pose, occlusion, and background clutter, thereby establishing a comprehensive benchmark for generalization capability.
To assess the DCCT framework’s resilience to real-world image degradation, the evaluation protocol included images subjected to JPEG compression. This compression artifact, commonly encountered in digital images due to its widespread use in storage and transmission, introduces quantifiable distortions. By training and testing the DCCT method on JPEG-compressed images alongside pristine data, researchers were able to determine the framework’s ability to maintain performance despite the presence of these common distortions, providing a more realistic measure of its practical applicability. The inclusion of JPEG compression served as a standardized stress test for robustness, complementing the evaluation on clean datasets like ImageNet and MSCOCO.
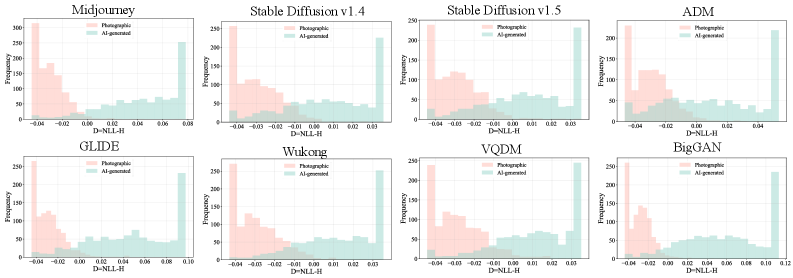
To evaluate the feature space learned by the DCCT framework, dimensionality reduction techniques, specifically t-distributed stochastic neighbor embedding (t-SNE), were employed. t-SNE reduces high-dimensional feature vectors into a two or three-dimensional space for visualization, allowing for the assessment of cluster separation between real and generated images. Successful separation, indicated by distinct, non-overlapping clusters, demonstrates the DCCT method’s ability to effectively discriminate between authentic photographic data and synthetic images produced by various generators. This analysis provides qualitative insight into the learned feature representations and confirms the model’s capacity to generate discriminative features for one-class classification.
The DCCT method demonstrated state-of-the-art performance in generalization and robustness testing, achieving an average accuracy of 97% on the GenImage dataset. This result represents an 8% performance increase compared to previously established methods on the same dataset. This improvement indicates a significant advancement in the ability of the DCCT framework to accurately classify images, even when faced with variations and complexities present in real-world visual data. The GenImage dataset, utilized for this evaluation, provides a standardized benchmark for assessing the performance of image classification algorithms.
Evaluation of the DCCT method on the DRCT-2M dataset, a benchmark comprised of 2 million generated images from diverse generators, demonstrated near 100% accuracy across the majority of tested generators. This performance indicates a high degree of effectiveness in distinguishing between real and synthetic imagery, even when the synthetic images exhibit substantial variation in style and content. The DRCT-2M dataset specifically targets the challenge of detecting generated images created by a wide array of generative models, and DCCT’s results suggest robust generalization capabilities in this complex scenario.
The DCCT one-class detector demonstrated strong performance by achieving competitive accuracy levels when evaluated solely on its ability to identify photographic images, without requiring training data from generated or synthetic images. This capability indicates the detector’s effective feature learning from real-world data and its resilience to the distribution shift commonly observed between photographic and generated imagery. This is particularly significant as most one-class anomaly detection systems require training on data representative of the expected input distribution, a constraint that DCCT successfully circumvents.

Charting a Course for Future Research
Current synthetic image detection methods often exhibit limited performance when confronted with images generated by models different from those used during training, or when applied to image types not previously encountered. Future research must prioritize the development of detection techniques that transcend these limitations, focusing on feature representations that are invariant to the specific generative process and robust across diverse visual content. This necessitates exploring techniques like domain adaptation, meta-learning, and the incorporation of broader, more abstract visual features, rather than relying on subtle artifacts specific to particular generation algorithms. Ultimately, the goal is to create detectors capable of reliably identifying synthetic images regardless of their origin or visual characteristics, paving the way for more trustworthy image-based applications.
Current synthetic media detection often relies on single methodologies, leaving systems vulnerable to adversarial attacks and limitations across varying types of generated content. Researchers are increasingly investigating the synergistic potential of combining the Double Convolutional Classifier Technique (DCCT) with complementary approaches. This integration could involve pairing DCCT’s focus on subtle artifact identification with frequency-domain analysis, noise pattern recognition, or even biometric inconsistency checks. Such hybrid systems promise improved robustness by leveraging the strengths of each technique, creating a more resilient defense against increasingly sophisticated forgeries. Preliminary studies suggest that combining DCCT with other detection methods not only boosts overall accuracy but also enhances generalization capabilities, allowing for more reliable detection across diverse generation models and image characteristics.
Establishing confidence in synthetic media detection necessitates moving beyond simply identifying that an image is artificial, and delving into why a particular determination was reached. Current detection methods often function as ‘black boxes’, providing a binary output without revealing the underlying reasoning. The development of explainable AI (XAI) techniques addresses this limitation by illuminating the features and patterns within an image that triggered a synthetic flag – perhaps subtle inconsistencies in lighting, unusual texture artifacts, or the presence of manipulated facial features. This transparency is crucial for building trust in these systems, allowing for verification of results, identification of potential biases, and ultimately, fostering accountability in a world increasingly populated by AI-generated content. Without such explainability, widespread adoption and responsible deployment of synthetic media detection tools remain significantly hindered.
The pursuit of robust AI-generated image detection, as detailed in this study, echoes a fundamental design principle: elegance through deep understanding. The DCCT method doesn’t merely identify artifacts; it leverages the inherent correlations within the camera imaging pipeline – a subtle yet powerful approach. This resonates with Fei-Fei Li’s observation that, “The most powerful AI will augment human intelligence, not replace it.” The study’s success isn’t about overpowering generative models with brute force, but rather, augmenting detection capabilities by understanding the underlying physics of image creation. Bad design, or in this case, a poorly designed detection method, shouts through its inability to generalize; good design, like DCCT, whispers through its harmonious integration of knowledge and function, revealing the truth with clarity and precision.
Beyond the Palette: Future Directions
The pursuit of detecting artificially generated imagery, as demonstrated by this work, inevitably circles back to a fundamental question: what constitutes ‘natural’? The method presented-leveraging the subtle, often overlooked, correlations inherent in the camera imaging pipeline-offers a compelling response, yet merely scratches the surface. While DCCT demonstrably improves generalization, it still relies on statistical anomalies-fingerprints of a specific generative process. Future work must consider the inevitable arms race; generative models will adapt, smoothing these statistical imperfections. A truly robust solution will require a shift in focus, moving beyond artifact detection towards a deeper understanding of perceptual priors – what the human visual system expects to see.
The emphasis on color correlation, though effective, represents a single facet of the imaging process. A good interface is invisible to the user, yet felt; similarly, a good forensic method should be unobtrusive, operating on principles of fundamental physics rather than model-specific quirks. Expanding this framework to incorporate other signal processing steps-noise modeling, demosaicing variations, lens aberrations-could yield a more holistic and resilient detector. Every change should be justified by beauty and clarity.
Ultimately, the long-term goal should not be simply to identify ‘fake’ images, but to develop a comprehensive understanding of the information lost and gained during the image capture and synthesis process. This necessitates a convergence of disciplines – computer vision, signal processing, and psychophysics – to create models that are not merely detectors, but interpreters of visual information.
Original article: https://arxiv.org/pdf/2601.22778.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Trading Crypto with AI: A New Approach to Portfolio Management
- 18 TV Series Filming Rehearsals as Bonus Content
2026-02-02 23:06