Author: Denis Avetisyan
A new approach reveals how pre-trained models already possess the knowledge needed to detect image forgeries, minimizing the need for extensive retraining.

Researchers introduce DNA, a framework for extracting ‘discriminative neural anchors’ from foundation models to achieve state-of-the-art forgery detection with improved efficiency.
As generative AI rapidly advances, conventional forgery detection methods relying on superficial artifacts are becoming increasingly obsolete. The work presented in ‘DNA: Uncovering Universal Latent Forgery Knowledge’ proposes that pre-trained neural networks already possess inherent forgery detection capabilities, rather than requiring resource-intensive fine-tuning. This is achieved through the Discriminative Neural Anchors (DNA) framework, which identifies and extracts a sparse set of ‘discriminative neural anchors’ exhibiting sensitivity to forgery traces. Does this ability to ‘wake up’ latent knowledge represent a fundamental shift towards more efficient and robust deepfake detection?
Decoding the Illusion: The Evolving Landscape of Forged Visuals
Historically, identifying image forgeries centered on detecting statistical inconsistencies – subtle artifacts introduced during manipulation that deviated from the expected patterns of naturally captured images. However, this approach is rapidly becoming obsolete as generative models, such as Diffusion Models and Flow Matching, achieve remarkable realism. These advanced techniques create synthetic images that convincingly mimic the statistical properties of authentic photographs, effectively masking the telltale signs previously exploited by detection algorithms. The very features once indicative of tampering – noise patterns, color distributions, and compression artifacts – are now faithfully reproduced by these models, rendering traditional anomaly-based methods increasingly unreliable and prompting a search for more robust, feature-level analysis.
Recent advancements in generative modeling, particularly Diffusion Models and Flow Matching, are blurring the lines between authentic and synthetic visual content. These techniques don’t simply replicate existing images; they create entirely new ones with a level of realism previously unattainable. Unlike earlier methods that often produced noticeable artifacts, these models generate images possessing intricate details and statistical properties nearly identical to those found in real-world photographs. Consequently, traditional forgery detection methods, reliant on identifying statistical anomalies, are increasingly ineffective. This necessitates a fundamental shift in approach, moving beyond pixel-level analysis towards techniques that can discern the underlying generative process or identify subtle inconsistencies in the image’s semantic structure – a challenge driving current research in the field of digital forensics and content authentication.
Current forgery detection techniques face a significant limitation: a failure to generalize beyond the specific generative models they were trained against. As generative algorithms rapidly evolve, consistently introducing novel methods for creating synthetic content, detection systems require continual retraining to maintain even a minimal level of accuracy. This creates a perpetual arms race, where advancements in forgery generation are immediately countered by updated detection models, only to be surpassed again by the next iteration of generative technology. The transient effectiveness of these systems necessitates a fundamental shift towards methods that identify inherent inconsistencies in generated content, rather than relying on pattern recognition tied to specific algorithms – a challenge that demands innovative approaches to ensure the long-term reliability of visual authentication.
The increasing prevalence of convincingly fabricated visual content poses a significant threat to societal trust in images and videos. As generative models become increasingly adept at creating synthetic media, differentiating between authentic and manipulated content becomes exceptionally difficult, eroding the reliability of visual evidence. This isn’t merely a technical challenge; the widespread dissemination of deepfakes and other forms of visual forgery has the potential to destabilize public discourse, influence elections, and damage reputations. Consequently, there’s an urgent need for the development of robust detection tools capable of identifying these manipulations with high accuracy and generalizability – tools that move beyond simply flagging statistical anomalies to understanding the semantic inconsistencies inherent in forged media, and which can adapt to the ever-evolving sophistication of generative techniques.
Unveiling Latent Knowledge: The DNA Framework Approach
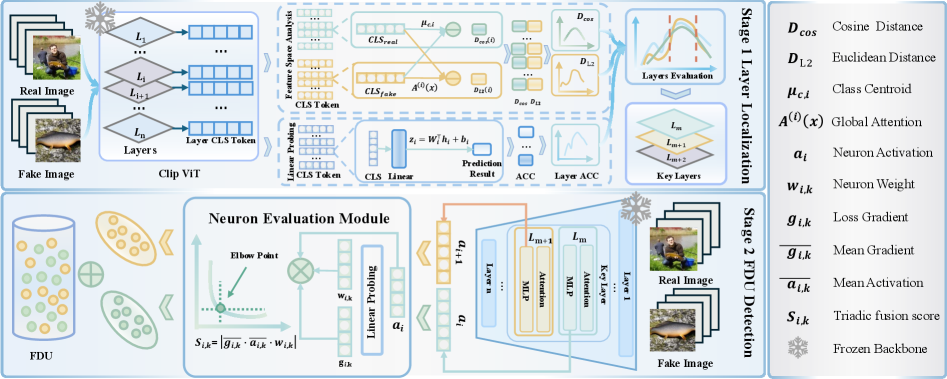
The DNA Framework capitalizes on the feature extraction capabilities of Pre-trained Models, specifically those initially trained on large-scale datasets such as ImageNet. These models have already learned to identify a wide range of visual patterns and features. Rather than training a new model from scratch for forgery detection, the DNA Framework repurposes this existing knowledge by analyzing internal model activations. The underlying premise is that subtle traces of forgery manipulation will manifest as distinct activation patterns within the pre-trained network, allowing for the identification of forged content without requiring explicit forgery-specific training data. This transfer learning approach significantly reduces the need for large, labeled forgery datasets and leverages the generalizable features learned from natural image statistics.
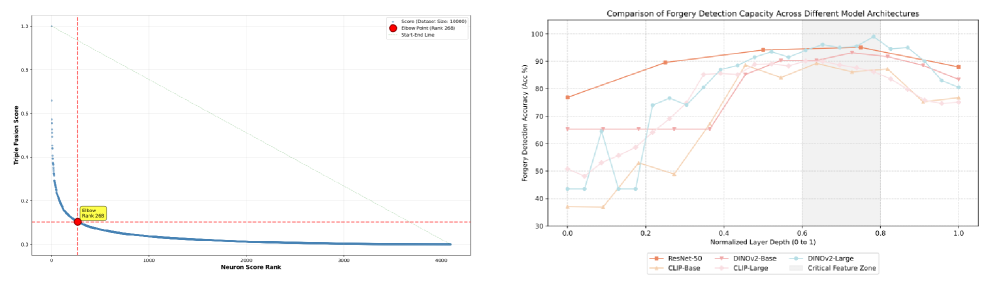
Layer Localization within the DNA Framework systematically identifies neural network layers exhibiting the strongest responses to forged content. This process involves analyzing activations across all layers of a Pre-trained Model and quantifying the signal related to forgery. Specifically, it determines which layers contain the most salient information for discriminating between authentic and manipulated images, effectively reducing the search space for Forgery-Discriminative Units (FDUs). The technique doesn’t assume a priori knowledge of which layers will be informative; instead, it uses quantitative metrics to assess layer-wise relevance, prioritizing those exhibiting statistically significant differences in activation patterns when presented with forged versus authentic data. This targeted approach improves efficiency and accuracy in identifying FDUs compared to a random or uniform search of the entire network.
The DNA Framework diverges from traditional forgery detection methods that focus on identifying anomalous patterns. Instead, it operates on the principle of uncovering Forgery-Discriminative Units (FDUs) within pre-trained neural networks. These FDUs represent neurons that remain largely inactive during processing of authentic content, but exhibit increased activation when presented with forged or manipulated images. The framework posits that the knowledge required to identify forgeries is already encoded within the network weights, but is latent and requires specific techniques, such as Triadic Fusion Scoring, to reveal and utilize these dormant, forgery-sensitive neurons.
Triadic Fusion Scoring (TFS) quantifies the contribution of individual neurons to forgery discrimination by integrating three distinct metrics. Gradient sensitivity measures the change in output with respect to input perturbations, indicating a neuron’s responsiveness to forgery-related features. Activation magnitude assesses the strength of a neuron’s response to the input, reflecting its overall engagement with the presented content. Finally, weight contribution evaluates the importance of a neuron’s connections based on the magnitude of its corresponding weights in the network. These three values are combined to produce a single score for each neuron, enabling the identification of Forgery-Discriminative Units (FDUs) – neurons that exhibit high scores and thus contribute significantly to distinguishing forged from authentic content.
Validating Intrinsic Traces: A Bayesian and Statistical Perspective
The DNA Framework’s performance relies on Bayes Optimality, a principle focused on minimizing the expected Bayes risk, which directly correlates to maximizing the Bayes error rate in the context of forgery detection. This approach prioritizes minimizing the probability of misclassifying forged images as authentic, even at the potential cost of increased false positives (classifying authentic images as forged). By explicitly optimizing for a low Bayes error rate, the framework aims to establish a robust decision boundary that effectively distinguishes between real and manipulated images, exceeding the capabilities of methods focused solely on overall accuracy. This optimization strategy is crucial because the cost of failing to identify a forgery is generally much higher than the cost of incorrectly flagging an authentic image.
Mahalanobis distance functions as a multivariate statistical measure of the distance between a point and a distribution of data, accounting for the covariance between variables; this is critical for forgery detection as it assesses the separation between the distributions of features extracted from real and forged images. Unlike Euclidean distance, Mahalanobis distance is invariant to scaling and considers the correlation structure of the data, providing a more accurate assessment of the dissimilarity between the distributions. A larger Mahalanobis distance indicates a greater separation between the distributions, thereby confirming the presence of intrinsic traces – subtle, consistent differences introduced by the forgery process – that distinguish forged images from authentic ones. This metric’s robustness stems from its ability to normalize for feature correlations and variances, enabling reliable quantification of the distributional difference even in high-dimensional feature spaces.
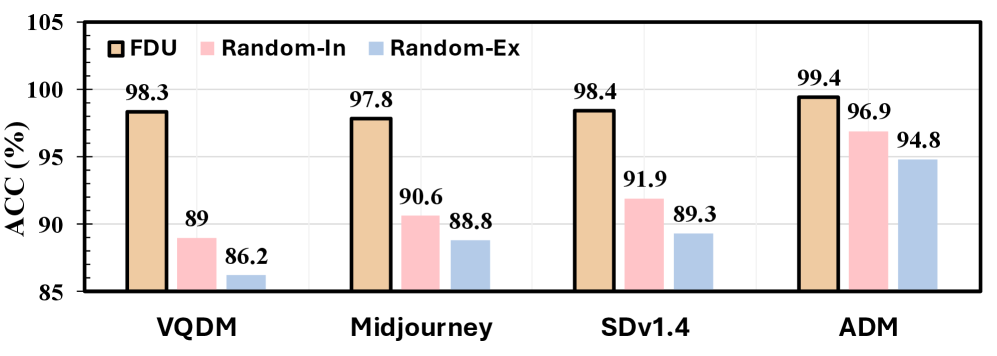
Analysis utilizing Mahalanobis distance and Bayes optimality confirms that Forgery Detection Units (FDUs) are not solely reliant on memorization of training data. Experimental results demonstrate the ability of FDUs to generalize beyond the training set, indicating the capture of intrinsic, forgery-specific information. The observed separation between real and forged image distributions, quantified by the metrics, suggests the FDUs are learning characteristics unique to the forgery process itself, rather than simply recognizing previously seen examples. This is evidenced by performance on the HIFI-Gen dataset, which includes generative model outputs not present in the training data, and consistently outperforms baseline methods.
Evaluation on the HIFI-Gen dataset, comprised of images generated by advanced generative models designed to present significant challenges for forgery detection, yielded a mean accuracy of 98.6%. This performance surpasses that of existing baseline forgery detection methods. The results demonstrate the efficacy of the DNA Framework in identifying subtle, yet critical, traces of manipulation, and establish a new state-of-the-art benchmark for performance on this dataset. The HIFI-Gen dataset was specifically chosen to provide a rigorous test of generalization ability, and the achieved accuracy indicates robust performance even with challenging, unseen forgery patterns.

Towards Robust Detection: Extracting and Leveraging Deep Features
The framework’s success hinges on the identification of Forgery Detection Units (FDUs)-specific components within a neural network that respond to subtle traces of image manipulation. These FDUs aren’t looking for obvious artifacts; instead, they pinpoint nuanced characteristics indicative of forgery, such as inconsistencies in texture, lighting, or semantic relationships. By extracting features directly from these units, the system can discern genuine images from those created or altered by generative models with remarkable precision. This approach moves beyond pixel-level comparisons and instead focuses on the ‘understanding’ of the image itself, allowing the framework to detect forgeries even when they are visually indistinguishable to the human eye, and opening possibilities for more robust and adaptable forgery detection systems.
The DNA Framework demonstrates a substantial leap in forgery detection performance by concentrating on the inherent, subtle characteristics – the ‘intrinsic traces’ – left within digital images. This focus yields a remarkable mean accuracy of 98.6%, significantly outperforming conventional methods. Crucially, this heightened accuracy isn’t achieved at the expense of computational resources; in fact, the framework reduces processing demands by a factor of over ten compared to baseline techniques. This efficiency stems from analyzing the pre-existing knowledge embedded within the models themselves, rather than relying on extensive retraining or complex calculations, paving the way for practical, real-time forgery detection systems even on limited hardware.
Rigorous evaluation demonstrates the framework’s exceptional performance across diverse datasets commonly used in forgery detection. Specifically, the system achieves 96.4% accuracy on the challenging HIFI-Gen dataset, a benchmark for high-fidelity image manipulation. Critically, the framework doesn’t simply memorize training data; it maintains robust accuracy when presented with images generated by entirely new and previously unseen generative models like FLUX and SDv3.5. Furthermore, it exhibits a substantial leap in performance on the Midjourney dataset, reaching 97.9% accuracy – a dramatic improvement over the 64.1% accuracy achieved by baseline methods, indicating a capacity for generalization and adaptability vital for real-world applications.
Current forgery detection methods often struggle to keep pace with the rapid advancements in generative AI, requiring constant updates and retraining as new techniques emerge. However, this research proposes a fundamentally different strategy – one that doesn’t rely on recognizing specific forgery signatures, but rather on identifying the inherent statistical inconsistencies introduced by generative processes themselves. By focusing on these intrinsic traces within pre-trained models, the framework builds a more adaptable system, capable of generalizing to unseen generative models like FLUX, SDv3.5, and Midjourney with significantly improved accuracy. This represents a crucial step towards creating forgery detection systems that aren’t locked into a perpetual arms race with increasingly sophisticated forgeries, but instead, possess the capacity to learn and evolve alongside them, offering a more sustainable and robust defense against manipulated media.
A key strength of this forgery detection framework lies in its capacity to leverage existing knowledge embedded within pre-trained models. Rather than demanding continuous retraining with each new generative technique – a computationally expensive and time-consuming process – the system effectively ‘reads’ the inherent understanding already present. This approach significantly reduces the demand for extensive resources, proving particularly advantageous in scenarios where computational power or data availability is limited. By unlocking this hidden knowledge, the framework offers a sustainable pathway towards robust and adaptable forgery detection, lessening the burden of constant updates and enabling broader accessibility for real-world applications.
The pursuit of uncovering inherent knowledge within existing models, as demonstrated by the DNA framework, echoes a fundamental principle of scientific inquiry. It’s akin to examining a specimen under a powerful microscope – the pre-trained neural network – to reveal previously unseen structures. As Yann LeCun aptly stated, “Everything we do in machine learning is about learning representations.” This resonates deeply with DNA’s core concept of extracting ‘discriminative neural anchors’ – sparse, yet potent, representations that encapsulate the knowledge necessary for forgery detection. The efficiency gained by leveraging these latent features, rather than relying on extensive fine-tuning, highlights the power of understanding a system’s internal logic and inherent patterns.
Beyond the Anchor
The identification of discriminative neural anchors, as demonstrated by this work, feels less like a solution and more like a sharpening of the question. The framework effectively distills forgery detection knowledge, but the very act of extraction reveals how much remains implicitly encoded-and therefore poorly understood-within these foundation models. Future investigation must address the nature of this residual knowledge. Is it noise, representing spurious correlations, or does it reflect a more nuanced, holistic understanding of image manipulation that current discriminative approaches simply miss?
A critical path forward lies in exploring the generality of these anchors. Do similar structures emerge across diverse network architectures and training datasets, suggesting universal principles of forgery detection? Or are these anchors fundamentally context-dependent, mirroring the specific biases and artifacts of the training process? The pursuit of transferability-and the limits thereof-will be crucial in determining the true power of this approach.
Ultimately, the work prompts a shift in perspective. It is no longer sufficient to simply detect forgery; the challenge now is to understand how these networks “see” manipulation, and to leverage that understanding to build more robust, interpretable, and genuinely intelligent systems. Every extracted anchor is not merely a feature; it’s an invitation to map the latent geometry of visual deception.
Original article: https://arxiv.org/pdf/2601.22515.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- 15 Films That Were Shot Entirely on Phones
- Trading Smarter: AI-Powered Execution Schedules
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Smarter Order Execution: How AI is Outperforming Wall Street’s Playbook
2026-02-02 12:54