Author: Denis Avetisyan
Researchers have developed a system using AI agents to automatically generate and resolve forecasting questions, tackling a critical bottleneck in evaluating predictive AI models.
This work introduces a framework for automated forecasting question generation and resolution, addressing data scarcity and enabling the creation of a robust benchmark for AI forecasting systems.
Accurately evaluating artificial intelligence requires robust benchmarks, yet creating diverse and challenging forecasting questions has historically been a laborious bottleneck. This limitation is addressed in ‘Automating Forecasting Question Generation and Resolution for AI Evaluation’, which introduces a system leveraging LLM-powered agents to automatically generate and resolve real-world forecasting questions at scale. The authors demonstrate the creation of nearly 1500 verifiable questions with high accuracy-exceeding human curation rates-and show improved forecasting performance on this benchmark with more capable LLMs, alongside a significant boost from a novel question decomposition strategy. Can this automated approach unlock a new era of continuous, data-driven AI evaluation and accelerate progress in probabilistic reasoning?
The Inevitable Bottleneck: Defining Resolution in Forecasting
The pursuit of accurate forecasting hinges on the ability to definitively verify answers, yet a surprising number of questions posed to artificial intelligence lack readily available, automated evaluation methods. This presents a significant bottleneck, as simply generating an answer is insufficient; a system must also convincingly demonstrate its correctness. Current AI models often excel at pattern recognition but struggle when faced with nuanced inquiries requiring contextual understanding or external validation. Consequently, researchers are increasingly focused on developing robust evaluation frameworks – essentially, automated ‘answer keys’ – that can objectively assess the quality of AI-generated forecasts, moving beyond simple metric-based comparisons to encompass more complex, judgment-based assessments. Establishing these verifiable resolutions isn’t merely a technical challenge, but a fundamental prerequisite for building truly trustworthy and reliable forecasting systems.
Determining ‘AI resolvability’ represents a fundamental step in assessing the true potential of artificial intelligence, moving beyond simply generating outputs to verifying autonomous problem-solving capabilities. This baseline isn’t merely about whether an AI can provide an answer, but how it arrives at that conclusion – specifically, if it can independently locate, process, and synthesize information without human intervention. Establishing this benchmark requires defining questions with verifiable answers and then evaluating if an AI agent can reliably and consistently discover those answers through its own reasoning processes. Such a metric is essential for distinguishing genuine intelligence from sophisticated pattern matching and for charting a course towards AI systems capable of tackling complex, real-world challenges with true autonomy.
The feasibility of artificial intelligence tackling complex questions is fundamentally limited by human capacity; a problem unresolvable for a person will almost certainly remain so for an AI. This principle establishes human resolvability as a crucial, initial benchmark for evaluating the potential of AI forecasting. Before significant resources are allocated to developing AI solutions, it’s essential to determine if a human, given reasonable effort and access to information, can reliably arrive at an answer. If a question consistently defeats human attempts at resolution, pursuing automated solutions becomes a significantly less promising endeavor, suggesting the limitations aren’t computational but inherent to the question itself or the available data. This pragmatic approach ensures that AI development is directed towards challenges where a solution, at least in principle, is attainable, maximizing the likelihood of successful forecasting outcomes.

A Systematic Approach: The Checklist for Resolution
Forecasting Question Assessment utilizes a predefined checklist to systematically evaluate whether a given question can be reliably resolved through automated means. This checklist-driven approach establishes a standardized process for identifying questions suitable for automation, moving beyond subjective assessment. The evaluation focuses on core attributes of the question and potential resolution pathways, assigning a feasibility score based on the presence or absence of specific criteria. This pre-emptive analysis minimizes development effort on questions lacking the characteristics necessary for successful automated resolution, thereby improving overall system efficiency and resource allocation.
The identification of a clearly defined Resolution Source is fundamental to automated question assessment, serving as the definitive basis for verifying proposed answers. This source represents a structured and accessible repository of factual information – such as a knowledge base, database, or API – against which system-generated or user-submitted responses can be evaluated for accuracy. Without a pre-defined Resolution Source, establishing objective truth becomes impossible, precluding automated assessment and necessitating manual review. The characteristics of an effective Resolution Source include unambiguous content, consistent formatting, and a clearly documented schema to facilitate programmatic access and comparison.
Source accessibility assessment within the feasibility checklist determines if data required for automated resolution can be reliably retrieved. This evaluation encompasses verifying the existence of Application Programming Interfaces (APIs), database query capabilities, or web scraping potential for the designated Resolution Source. Specifically, the assessment confirms the ability to programmatically access the data, including authentication methods, data formats (e.g., JSON, XML), and rate limiting policies. Failure to confirm reliable data retrieval at this stage immediately disqualifies a Resolution Source, regardless of data content or relevance, as automated verification is impossible without accessible data.
The Pillars of Resolution: Data Integrity and Accessibility
Data availability for resolution processes is fundamentally dependent on source accessibility. If the originating data source is inaccessible – due to technical locks, permission restrictions, or physical unavailability – data cannot be retrieved for analysis, effectively halting resolution. Similarly, an empty data source, lacking any recorded information, presents the same impediment. This applies to all data types, including databases, file systems, APIs, and physical archives; a lack of access or content at the source level directly translates to a lack of available data for subsequent investigation and problem-solving, regardless of the analytical tools or methodologies employed.
Methodology Stability refers to the consistent application of data collection protocols over a defined period, and is crucial for maintaining data integrity even when sources are readily accessible. Variations in instrumentation, procedures, or definitions used to gather data introduce systematic errors that can invalidate comparisons and trend analysis. Without standardized methodologies, observed changes may reflect alterations in how data is collected, rather than genuine shifts in the underlying phenomena. This consistency extends to data validation and quality control procedures; any changes to these processes must be documented to ensure data comparability and reliable resolution outcomes. Therefore, meticulous record-keeping of all methodological aspects is essential for establishing data trustworthiness and facilitating accurate analysis.
Data reliability is fundamentally dependent on methodological consistency; variations in data collection procedures, even with full data accessibility, introduce systematic errors that compromise the validity of any resulting analysis. These inconsistencies can manifest as changes in instrumentation, sampling techniques, data definitions, or processing algorithms, leading to spurious trends or inaccurate conclusions. Consequently, resolution efforts based on data collected using unstable methodologies risk generating flawed outcomes, necessitating costly rework or invalidating the entire process. Establishing and maintaining documented, standardized methodologies is therefore critical for ensuring data integrity and supporting accurate, defensible resolution.
Expanding the Horizon: Implications for Automated Forecasting
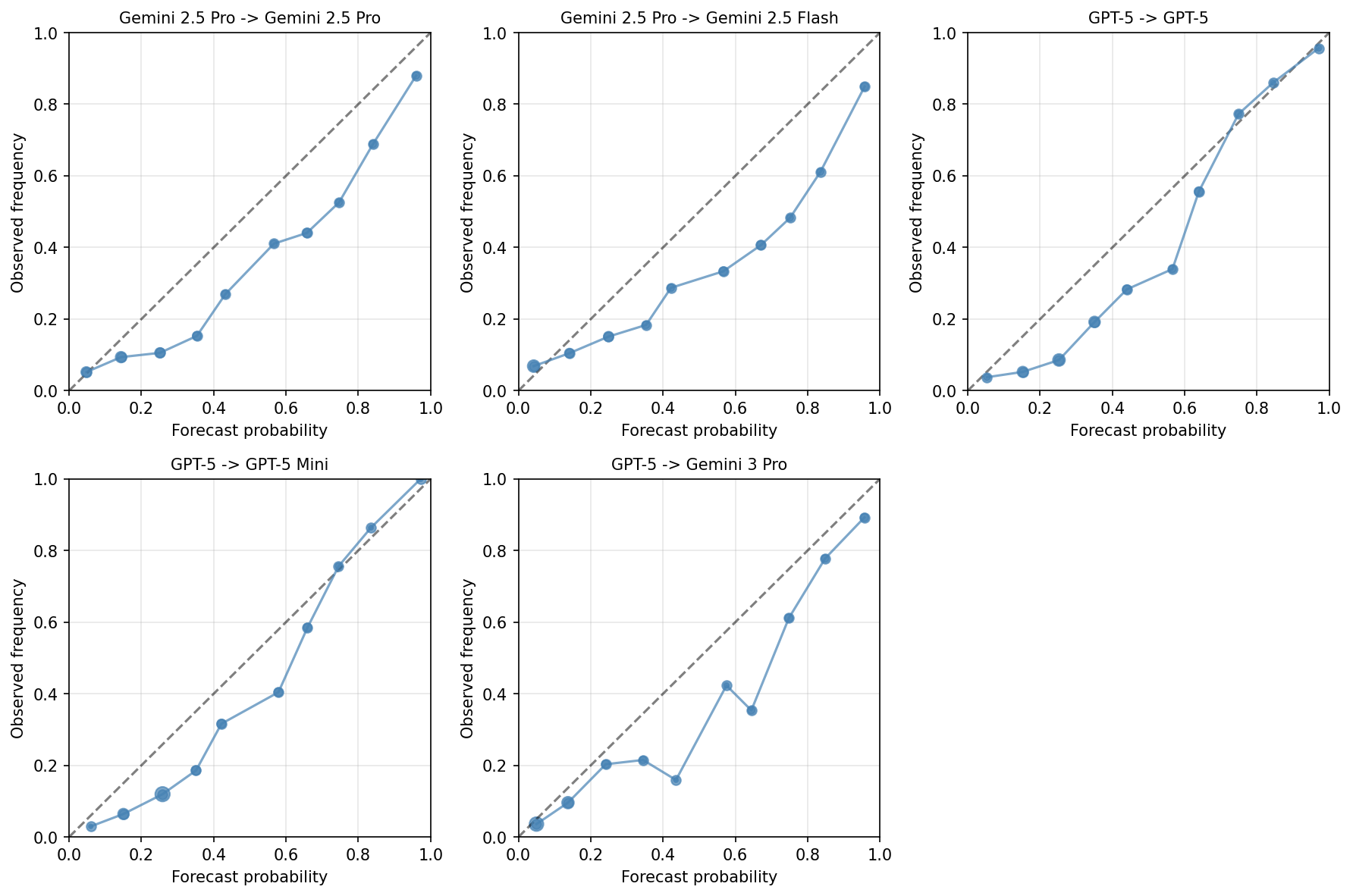
A novel evaluation framework has been developed to pinpoint forecasting questions particularly well-suited for automated resolution, thereby significantly expanding the scope of AI-driven predictive modeling. This system doesn’t simply assess question difficulty; it analyzes inherent resolvability, identifying instances where clear, unambiguous data sources exist for algorithmic determination of outcomes. By focusing on these readily resolvable queries, the framework unlocks the potential for continuous, scalable forecasting, moving beyond human-in-the-loop approaches for a substantial subset of predictive challenges. This capability promises to accelerate the creation of AI-powered forecasting systems, enabling more frequent updates and broader coverage of future events while reducing reliance on costly and time-consuming manual analysis.
The precision of artificial intelligence forecasting hinges significantly on the quality of information used to determine outcomes; therefore, a deliberate emphasis on questions supported by dependable resolution sources demonstrably elevates predictive accuracy. By focusing on inquiries where clear, verifiable evidence exists – such as established datasets, definitive reports, or unambiguous metrics – the system minimizes ambiguity and reduces the potential for erroneous conclusions. This strategic prioritization not only enhances the reliability of individual predictions, but also builds confidence in the overall forecasting process, allowing for more informed decision-making and strategic planning based on AI-driven insights. Essentially, a strong foundation of readily available and trustworthy data translates directly into more robust and dependable AI predictions.
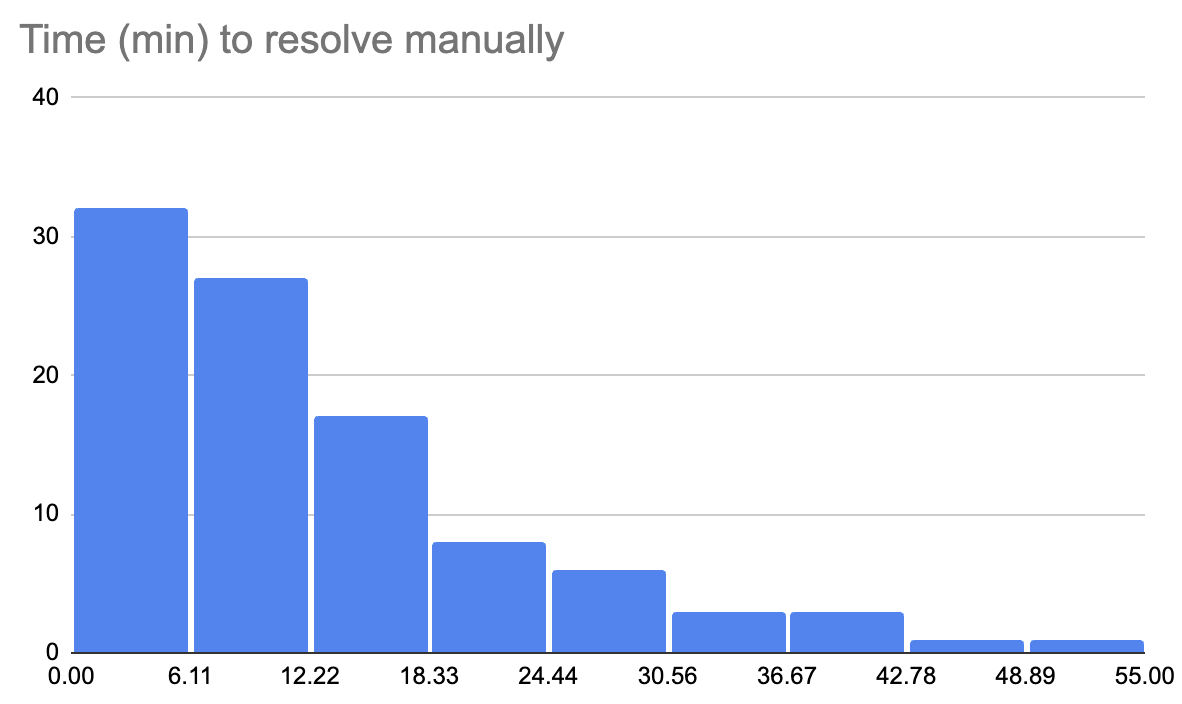
The system’s performance, assessed through its annulment rate, suggests a promising future for automated forecasting. Achieving an estimated annulment rate of 3.9%-the proportion of questions deemed unresolvable-positions the technology favorably when contrasted with the 8% historical rate observed on the Metaculus forecasting platform. This close alignment indicates that automatically generated questions are not only viable, but also maintain a similar level of feasibility and clarity as those currently curated by human experts. Consequently, this demonstrates the potential for scalable, AI-driven question generation to significantly augment and potentially expand the scope of predictive analysis.
The study demonstrated a remarkable level of reliability in forecasting through automated question resolution, achieving 96% accuracy when evaluated against human verification. A detailed analysis of 100 resolved questions revealed only four errors, underscoring the potential for AI to generate consistently accurate predictions. This high degree of concordance between AI-driven forecasts and human judgment suggests the system is not merely generating responses, but effectively interpreting information and applying it to predictive outcomes. The findings validate the approach and provide a strong foundation for expanding the application of automated forecasting across diverse domains, ultimately reducing reliance on manual analysis while maintaining a high standard of predictive accuracy.
The study demonstrated a remarkable consistency in identifying definitive resolution sources for forecasting questions. A complete 100% agreement on these sources suggests the material used was exceptionally clear and unambiguous, allowing for reliable automated resolution by artificial intelligence. This clarity is crucial; without a single, verifiable source, even sophisticated AI models struggle to accurately determine outcomes. The consistent identification of these sources not only validates the system’s approach to question generation but also underscores the importance of well-defined, objectively resolvable criteria when building datasets for AI-driven forecasting initiatives. This finding implies that prioritizing questions with readily available and universally accepted resolution sources is a key factor in maximizing the accuracy and trustworthiness of automated predictions.
“`html
The pursuit of automated forecasting question generation, as detailed in this work, inherently acknowledges the transient nature of predictive models. Each question generated, each resolved forecast, exists within a specific temporal context, susceptible to the inevitable drift of underlying data distributions. This resonates with Claude Shannon’s assertion: “The most important thing in communication is to convey the meaning, not the symbols.” Here, the ‘symbols’ are the forecasts themselves, and ‘meaning’ lies in their ability to accurately represent a fleeting moment in time. The system’s focus on question resolvability, therefore, isn’t merely a technical detail-it’s an acknowledgment that even the most sophisticated models must adapt, or become relics of a bygone era. The very act of continuous question generation and resolution serves as a method for gracefully aging the system, perpetually calibrating it against the currents of time.
The Horizon of Prediction
The automation of forecasting question generation, as demonstrated, sidesteps an immediate crisis – the lack of readily available benchmarks. However, this is merely a deferral, not a resolution. The system’s efficacy relies on the generative model’s capacity to produce resolvable questions, a characteristic inherently tied to the present state of data and understanding. Each simplification in question formulation, each attempt to ensure solvability, introduces a future cost – a narrowing of the problem space, and the subtle forgetting of what remains unknown. The benchmark created is, therefore, a snapshot – valuable for a time, but inevitably subject to the entropy of evolving knowledge.
The true challenge isn’t generating questions, but managing the accumulating ‘technical debt’ of their simplicity. Future work must address the inherent trade-off between benchmark accessibility and representational fidelity. Can systems be designed to explicitly track the assumptions embedded within each question, and to flag the boundaries of their validity? Or will the field continue to build upon increasingly abstracted foundations, losing sight of the complex systems they attempt to model?
Ultimately, the pursuit of automated evaluation is a testament to the desire for progress, but progress itself is not without consequence. The system’s memory – the archive of generated questions and their resolutions – will become a critical resource, not just for measuring current capabilities, but for understanding the limitations of past predictions, and for anticipating the inevitable arrival of unforeseen futures.
Original article: https://arxiv.org/pdf/2601.22444.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Gold Rate Forecast
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 18 TV Series Filming Rehearsals as Bonus Content
- Trading Crypto with AI: A New Approach to Portfolio Management
2026-02-02 09:31