Author: Denis Avetisyan
Researchers have developed a novel method to address security and fairness concerns in transformer models by subtly altering attention patterns during operation.
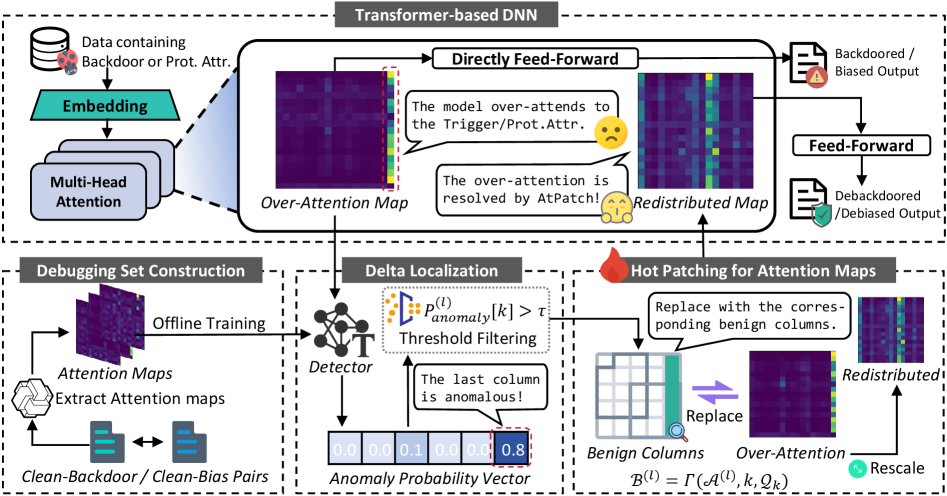
AtPatch dynamically redistributes attention maps at inference time to mitigate backdoor attacks and unfairness without modifying model weights.
Transformer networks, despite their success, remain vulnerable to subtle manipulations leading to anomalous attention patterns and exhibiting biases in deployed applications. To address this, we introduce AtPatch: Debugging Transformers via Hot-Fixing Over-Attention, a novel inference-time intervention that dynamically redistributes attention maps to mitigate backdoor attacks and unfairness. AtPatch achieves this by selectively ‘hot-fixing’ over-attention without modifying model parameters or requiring retraining, preserving original functionality while enhancing robustness. Could this approach pave the way for more adaptable and trustworthy transformer-based systems in real-world scenarios?
The Fragility of Attention: Hidden Weaknesses in Modern DNNs
Despite their demonstrated capabilities, Transformer-based deep neural networks (DNNs) exhibit surprising vulnerability to subtle backdoor attacks. These attacks involve embedding hidden triggers within training data – often imperceptible to human observers – that cause the model to consistently misclassify inputs containing those triggers. Unlike traditional adversarial attacks requiring precisely crafted perturbations, backdoors can be activated by minimal, naturally occurring patterns. This poses a significant security risk, as a compromised model could be manipulated to produce desired, yet incorrect, outputs in real-world applications ranging from image recognition to natural language processing. The robustness of these architectures is challenged not by overt manipulation, but by the insidious introduction of exploitable biases during the learning process, raising concerns about the reliability of DNNs deployed in sensitive contexts.
The remarkable capabilities of modern deep neural networks often mask a critical flaw: a tendency towards ‘Over-Attention’. This phenomenon describes a model’s disproportionate focus on irrelevant or spurious features within input data, effectively learning to prioritize noise over signal. Researchers have found that these models don’t necessarily understand the core relationships driving a prediction; instead, they latch onto superficial correlations. This creates exploitable biases because even minor, intentionally misleading features – a subtly altered pixel in an image, for example – can unduly influence the network’s output. The consequences extend beyond simple misclassification, as Over-Attention can introduce systematic errors and vulnerabilities, making these models susceptible to adversarial attacks and raising concerns about their reliability in sensitive applications.
Deep neural networks, despite their impressive capabilities, can exhibit unfairness in predictions due to biases embedded within their attention mechanisms. Research indicates that models may disproportionately focus on protected attributes – characteristics like race or gender – leading to skewed outcomes even when these attributes are not explicitly intended for use in the decision-making process. This ‘attention skew’ isn’t necessarily malicious; it arises from patterns learned during training, where subtle correlations between protected attributes and other features can inadvertently amplify biases. Consequently, a model designed to assess risk, for example, might unfairly assign higher risk scores to individuals based on these unintentionally emphasized characteristics, perpetuating societal inequalities and raising serious ethical concerns about the deployment of these systems in sensitive applications.
AtPatch: A Dynamic Intervention in the Attention Ecosystem
AtPatch functions as a hot-fix mechanism specifically engineered for transformer-based Deep Neural Networks (DNNs). Unlike traditional security measures that often address symptoms, AtPatch directly targets the attention maps within these networks. By dynamically redistributing these attention weights, the system aims to neutralize adversarial inputs and mitigate the impact of various attacks. This approach operates on the principle that many adversarial attacks and biases manifest as anomalous patterns within the attention mechanism; correcting these patterns in real-time offers a direct intervention at the source of the vulnerability without necessitating complete model retraining or service interruption.
AtPatch leverages principles from ‘Delta Debugging’ and ‘Hot Patching’ to facilitate in-service model modification without necessitating full retraining or system interruption. Delta Debugging informs the iterative refinement of problematic model components, while Hot Patching enables the replacement of code while the system remains operational. This approach allows AtPatch to dynamically adjust attention maps in running transformer-based Deep Neural Networks (DNNs) by identifying and correcting anomalous behavior without incurring the computational expense or downtime associated with traditional retraining procedures. The system directly modifies the active model instance, minimizing latency and resource consumption during mitigation of attacks or biases.
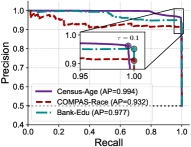
The AtPatch system incorporates a Detector module designed to identify anomalous attention patterns within a deployed transformer-based DNN. This Detector functions by analyzing attention map distributions and flagging deviations indicative of adversarial attacks or inherent model biases. Performance metrics demonstrate a precision range of 0.910 to 0.981, signifying a low rate of false positives when identifying anomalous patterns. Critically, the Detector achieves a recall exceeding 0.994, indicating a very high rate of correctly identifying true anomalous attention patterns, minimizing the risk of undetected threats or biases.
Validating the Patch: Resilience Against Attack and Bias
AtPatch exhibits strong resilience against common backdoor attacks such as BadNets and Trojan Attacks. Evaluation demonstrates a Backdoor Attack Success Rate (ASR) of 0.46% following implementation. This metric indicates the percentage of successfully attacked inputs that result in a targeted misclassification, signifying a substantial reduction in vulnerability compared to undefended models. The low ASR suggests AtPatch effectively disrupts the malicious patterns injected by these attacks, preventing them from reliably manipulating model predictions.
AtPatch addresses model unfairness by directly correcting attention mechanisms that disproportionately focus on protected attributes during prediction. This correction process aims to equalize the model’s reliance on sensitive features, thereby reducing biased outcomes. Evaluation metrics demonstrate a significant reduction in unfairness, quantified by an Unfairness (UF) score of 0.04. This score indicates a minimal level of disparity in predictions attributable to protected attributes, suggesting that AtPatch effectively mitigates bias without substantially compromising overall model performance.
AtPatch employs contrastive learning to optimize the redistribution of feature importance during the mitigation of attacks and bias. This technique refines the correction process by comparing the original and modified feature representations, minimizing disruptions to the model’s core functionality. Consequently, the implementation of contrastive learning limits the reduction in overall model accuracy to an average of 0.1%, demonstrating a high degree of performance preservation while addressing security vulnerabilities and fairness concerns.

Beyond the Fix: Cultivating Robust and Equitable AI Ecosystems
AtPatch signifies a notable advancement in the pursuit of robust and equitable artificial intelligence systems. This framework directly addresses the critical vulnerabilities of current AI models to adversarial attacks – subtle, intentionally crafted inputs designed to mislead the system – while simultaneously mitigating inherent biases that can lead to unfair or discriminatory outcomes. By strategically redistributing attention within the neural network, AtPatch effectively ‘patches’ these weaknesses, enhancing the model’s resilience without sacrificing accuracy. This isn’t about masking problems; it’s about reinforcing the system’s ability to focus on relevant features, reducing its susceptibility to manipulation and promoting more consistent, impartial predictions across diverse datasets. Consequently, AtPatch moves beyond reactive defenses and establishes a foundation for building AI that is both secure and fundamentally fair by design.
AtPatch isn’t intended as a standalone solution, but rather as a complementary layer to existing artificial intelligence debugging infrastructure. Seamless integration with tools like IDNN (Intelligent Debugging of Neural Networks) and CARE (Counterfactual Analysis and Remediation Engine) allows for a holistic approach to AI safety and fairness. IDNN can pinpoint the specific vulnerabilities that AtPatch aims to address, while CARE can assist in generating counterfactual examples to test the effectiveness of the attention redistribution process. This combined pipeline enables developers to not only identify and patch vulnerabilities but also rigorously validate that the resulting system is both robust against adversarial attacks and demonstrably fairer in its predictions, streamlining the development of trustworthy AI applications.
Ongoing development of the AtPatch framework prioritizes broadening its defensive capabilities to encompass a more extensive spectrum of adversarial vulnerabilities. Researchers are actively refining the attention redistribution process-the core mechanism by which AtPatch enhances robustness and fairness-with the aim of maximizing its efficiency and adaptability. A particularly promising avenue for future investigation involves integrating AtPatch with the Adversarial Discovery Framework (ADF), which would enable proactive fairness assessment during model training. This preemptive approach could identify and mitigate potential biases before they manifest as discriminatory outcomes, ultimately contributing to the creation of AI systems that are not only resilient to attacks but also demonstrably equitable in their performance.
The pursuit of pristine model behavior, as demonstrated by AtPatch’s dynamic attention redistribution, echoes a fundamental truth about complex systems. Long stability is the sign of a hidden disaster; a model seemingly impervious to attack may merely be masking vulnerabilities within its attention mechanisms. As John McCarthy observed, “It is often easier to recognize a problem than to define it.” AtPatch doesn’t solve the underlying issues of backdoor attacks or fairness-it circumvents their immediate expression, much like grafting a new branch onto a tree already bearing poisoned fruit. The system doesn’t fail; it evolves, and understanding that evolution requires more than just celebrating successful inference – it demands a constant probing of the hidden pathways within the attention maps.
What Lies Ahead?
AtPatch offers a compelling, if temporary, reprieve. It addresses symptoms – the visible manifestations of bias or malicious intent – without confronting the underlying pathologies within these attention-driven systems. The method elegantly reshuffles influence, but influence itself remains a blunt instrument. Scalability is, after all, just the word used to justify complexity, and each dynamic redistribution introduces new vectors for unforeseen consequences. The perfect architecture is a myth to keep everyone sane.
The true challenge isn’t simply to correct attention, but to understand its failures as signals of deeper structural flaws. This work implicitly acknowledges that attention, as currently implemented, is brittle. Future research must move beyond post-hoc correction toward inherently robust mechanisms – models that anticipate and mitigate these issues during training, not merely react to them at inference. Everything optimized will someday lose flexibility; the question becomes how to build systems that degrade gracefully, rather than catastrophically.
Perhaps the most pressing direction lies in formalizing the very notion of ‘fairness’ and ‘attack surface’ within the context of attention. AtPatch shifts the distribution, but by what metric is that shift better? The field needs tools to rigorously quantify these improvements, moving beyond subjective evaluations toward verifiable guarantees. The ecosystem demands more than just fixes; it requires a fundamental re-evaluation of what it means for a model to be trustworthy.
Original article: https://arxiv.org/pdf/2601.21695.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Gold Rate Forecast
- Trading Smarter: AI-Powered Execution Schedules
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 15 Films That Were Shot Entirely on Phones
- Smarter Order Execution: How AI is Outperforming Wall Street’s Playbook
2026-02-02 01:04