Author: Denis Avetisyan
A new approach leverages mathematical principles to build more efficient and scalable language models.

This review details CoFrGeNet, a novel architecture utilizing continued fraction networks to replace attention and feed-forward layers in Transformers, reducing parameters and improving computational efficiency.
Despite the success of Transformers in language modeling, their computational demands and parameter counts remain a significant challenge. This paper introduces ‘CoFrGeNet: Continued Fraction Architectures for Language Generation’, a novel approach inspired by continued fractions to design more efficient generative models. By replacing Multi-head Attention and Feed-Forward Networks with components based on this function class, CoFrGeNets achieve competitive performance on tasks like classification and question answering with \frac{2}{3} to \frac{1}{2} fewer parameters and reduced pre-training time. Could customized hardware implementations further unlock the potential of these continued fraction-based architectures for even greater efficiency and scalability?
The Inevitable Bottleneck: Scaling Beyond Attention
The prevailing Transformer architecture has demonstrably revolutionized natural language processing, yet its core reliance on attention mechanisms introduces significant computational bottlenecks as sequence lengths increase. Each element within a sequence must attend to every other element, resulting in quadratic complexity – meaning the computational cost grows proportionally to the square of the sequence length. This poses a considerable challenge for processing extensive texts, such as books or lengthy conversations, as the demand for memory and processing power escalates rapidly. Consequently, scaling Transformers to handle truly long-range dependencies remains a key impediment to advancements in areas like document summarization, complex reasoning, and comprehensive knowledge retrieval. Researchers are actively seeking alternative approaches to mitigate this computational burden without sacrificing the model’s ability to capture nuanced relationships within the data.
Current language models, despite achieving impressive results, face a critical trade-off between performance and practicality. Increasing model size generally improves capabilities, but simultaneously demands more computational resources for both training and deployment. This creates a bottleneck, as larger models require extended training times and significantly slower inference speeds, hindering their use in real-time applications or on devices with limited processing power. Existing techniques attempting to address this often involve complex optimizations or model compression, which can degrade accuracy or introduce further computational overhead. Consequently, scaling these models to handle increasingly complex tasks and longer sequences remains a substantial challenge, limiting their broader applicability and preventing widespread integration into everyday technologies.
The pursuit of more effective language models demands a departure from architectures overly reliant on attention mechanisms. Current limitations in computational efficiency hinder the development of truly scalable systems, impacting both training duration and practical deployment. Researchers are actively investigating alternative foundations that prioritize streamlined processing without sacrificing the capacity to understand and generate complex text. This involves exploring methods that reduce computational load, potentially through state space models or recurrent structures, and designing architectures that can handle extended sequences with greater speed and reduced memory requirements. Ultimately, the goal is to create language models that are not only powerful but also accessible and readily applicable to a wider range of real-world problems, paving the way for advancements in natural language processing and artificial intelligence.
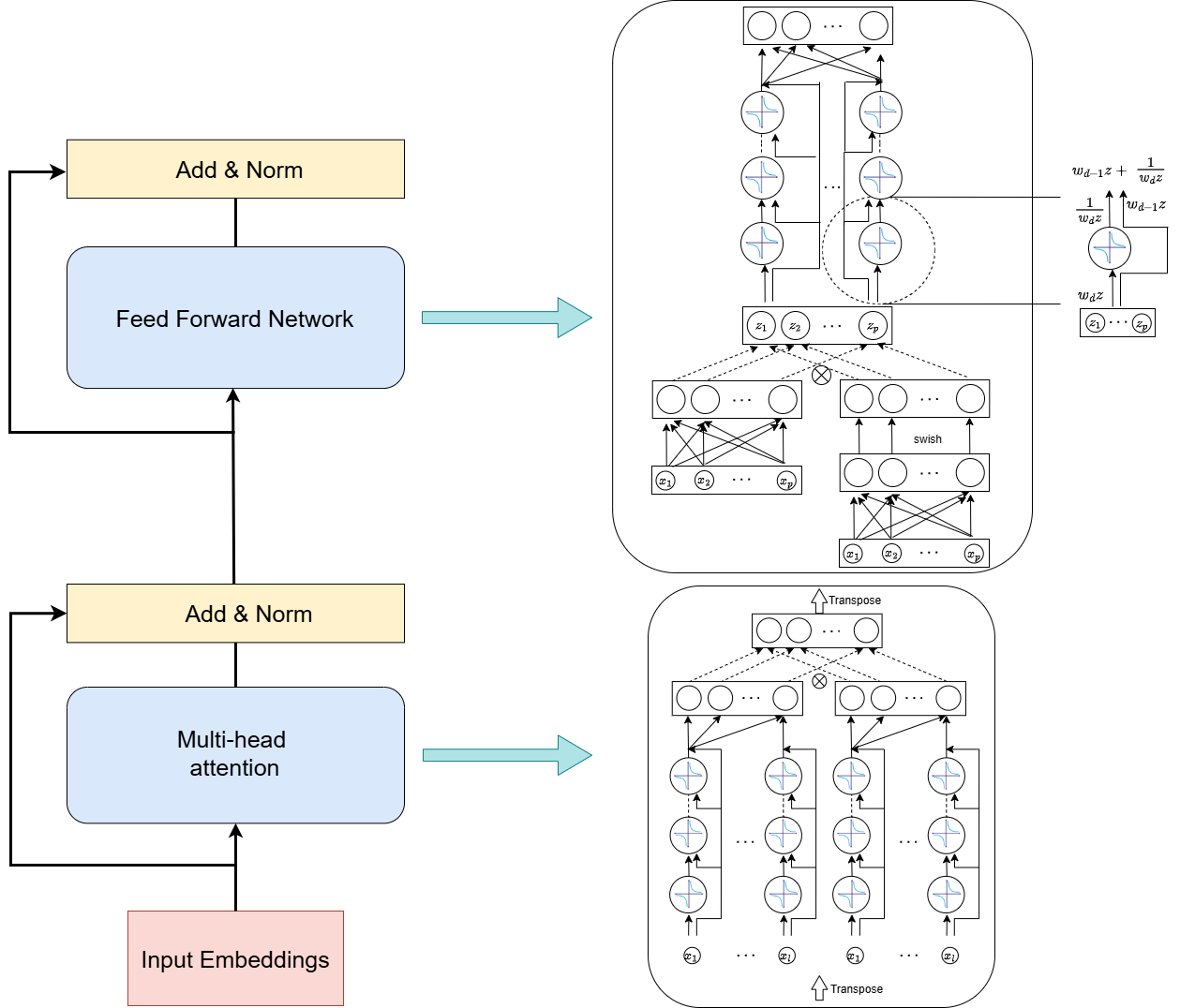
CoFrNet: A Recursive Path to Efficiency
CoFrNet presents a departure from standard transformer architectures by implementing a network based on continued fractions. This approach substitutes the prevalent attention mechanisms and feed-forward networks with a structure rooted in the recursive mathematical function of continued fractions c_n = a_0 + \frac{1}{a_1 + \frac{1}{a_2 + \dots}} . The resulting network seeks to model complex relationships using a series of linear transformations, offering a potentially more parameter-efficient alternative to traditional methods. This architecture is designed to provide comparable expressive power while reducing computational demands, particularly in scenarios involving long sequence modeling.
CoFrNet’s design centers on the principle that continued fractions offer a computationally efficient method for function approximation. Traditional neural network layers, particularly those employing attention mechanisms, exhibit quadratic complexity with sequence length. In contrast, the recursive nature of continued fraction representations allows CoFrNet to approximate complex functions with a potentially lower computational cost. This is achieved by decomposing a function into a series of simpler, linear transformations and rational functions, represented as f(x) = a_0 + \frac{b_0}{a_1 + \frac{b_1}{a_2 + \dots}}. By carefully controlling the depth and parameters within this fractional representation, the model aims to maintain a comparable level of representational power to standard architectures while significantly reducing the number of parameters and floating-point operations required during both training and inference.
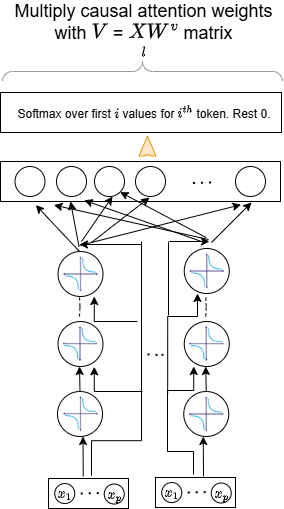
The CoFrNet architecture prioritizes computational efficiency through the exclusive use of linear layers, avoiding the quadratic complexity associated with attention mechanisms. Sequential information is preserved via causal token mixing; each token’s representation is updated based solely on preceding tokens in the sequence, ensuring that future information does not contribute to the current state. This unidirectional processing, implemented with linear transformations, allows for parallelization within each layer and reduces the overall computational burden while maintaining the capacity to model sequential dependencies. x_i = f(x_{
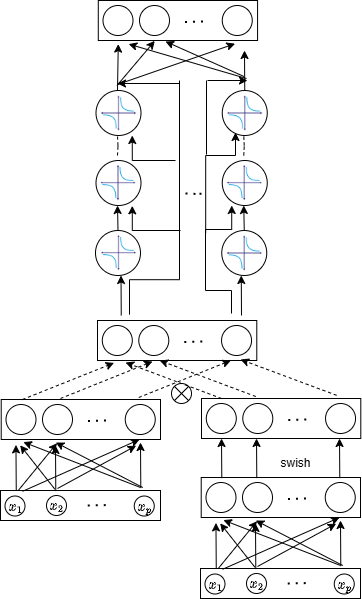
Optimization as a Stabilizing Force
CoFrNet utilizes a dyadic parameter update schedule during training, meaning parameter updates are performed in steps that are powers of two. This approach contrasts with standard gradient descent methods and is implemented to improve training stability and accelerate convergence. By restricting updates to dyadic values, the algorithm avoids potentially destabilizing small adjustments and facilitates more efficient optimization, particularly in the initial stages of training where large parameter changes are common. This schedule effectively reduces oscillations during training and allows for a larger learning rate to be employed, thereby decreasing the overall training time.
The CoFrNet architecture utilizes a continuation-based implementation to reduce computational cost by minimizing the number of division operations. Traditional reciprocal operations, such as calculating the inverse of a matrix or vector, are computationally expensive and can create performance bottlenecks. This implementation reformulates calculations to replace divisions with multiplications by approximate inverses, or utilizes continued fraction expansions to iteratively refine the result with multiplicative updates. By significantly decreasing the frequency of division operations, particularly during the forward and backward passes of neural network training, this approach improves computational efficiency and reduces overall processing time.
CoFrNet’s performance was benchmarked against established Transformer models using the General Language Understanding Evaluation (GLUE) suite. Results indicate CoFrNet achieves competitive performance across the GLUE tasks, demonstrating comparable or improved scores on benchmarks such as MNLI, QQP, and SST-2. Specifically, CoFrNet demonstrates an ability to generalize across diverse natural language understanding tasks without significant performance degradation compared to baseline Transformer architectures of similar parameter size, validating its effectiveness as a potential replacement in various NLP applications.
Empirical results demonstrate that utilizing CoFrNet during training can substantially decrease the time required to achieve comparable performance to original Llama models. Specifically, observed reductions in training time have reached up to 2 days, depending on the dataset and hyperparameter configuration. This acceleration is attributed to the network's optimized computational structure and the dyadic parameter update schedule, allowing for faster convergence without compromising model accuracy. These gains are particularly significant when training large language models, where even small improvements in efficiency can yield considerable time and resource savings.

CoFrNet in Context: Performance and Scalability
Rigorous evaluation of CoFrNet against established language modeling benchmarks reveals performance competitive with existing state-of-the-art models. Perplexity scores, a standard metric for assessing a model’s ability to predict a sequence of words, demonstrate that CoFrNet effectively captures the nuances and statistical regularities of language. This validation underscores the model’s capacity to generate coherent and plausible text, indicating a strong foundational understanding of linguistic structure. The achievement is particularly notable given the model’s reduced complexity, suggesting that efficient architecture can maintain high performance in language modeling tasks. These findings establish CoFrNet as a viable alternative to larger, more computationally intensive Transformer models.
CoFrNet distinguishes itself from conventional Transformer models through a significant reduction in both parameter count and computational demands. This optimization isn't merely theoretical; it translates directly into practical benefits for both training and deployment. By streamlining the model architecture, CoFrNet requires fewer computational resources to achieve comparable or even superior language modeling performance. Consequently, training times are substantially decreased, allowing for faster experimentation and iteration. More crucially, the lowered computational cost facilitates dramatically faster inference speeds - a critical advantage for real-time applications where responsiveness is paramount. This efficiency opens doors to deploying sophisticated language models on resource-constrained devices and scaling applications to handle increased user demand without incurring prohibitive costs.
Evaluations reveal a significant performance advantage for CoFrNet regarding inference speed; the architecture consistently achieves results nearly ten times faster than a standard Transformer implementation lacking continuants. This acceleration stems from the model’s efficient handling of contextual information and reduced computational demands during the decoding process. By minimizing redundant calculations, CoFrNet facilitates quicker generation of text, making it particularly well-suited for real-time applications and resource-constrained environments. The demonstrated speedup isn’t merely theoretical; benchmarks confirm substantial gains in processing large volumes of text, suggesting a practical benefit for deployments requiring rapid language processing capabilities.
The seamless integration of CoFrNet with the Llama architecture highlights its versatility and broadens its applicability across diverse natural language processing tasks. This compatibility isn’t merely structural; it demonstrates CoFrNet’s ability to function as a drop-in replacement for components within existing, powerful models like Llama, facilitating immediate improvements in efficiency without requiring substantial architectural overhauls. Beyond simply fitting into established frameworks, this integration unlocks possibilities for deployment in resource-constrained environments and real-time applications where rapid inference is critical, suggesting a pathway toward more accessible and scalable language technologies. The demonstrated adaptability positions CoFrNet not just as a research innovation, but as a practical tool for enhancing existing systems and enabling novel applications in areas like conversational AI, machine translation, and content generation.
Future Trajectories: Expanding CoFrNet’s Reach
CoFrNet’s performance could be substantially improved by incorporating sparse attention mechanisms, inspired by architectures like the Synthesizer. Traditional attention mechanisms, while powerful, demand significant computational resources as the input sequence length grows. Sparse attention, however, selectively focuses on relevant parts of the input, drastically reducing this computational burden. By implementing such techniques, CoFrNet could process longer sequences and larger datasets with greater efficiency, allowing it to scale to more complex tasks and real-world applications. This approach would not only decrease computational costs but also potentially improve the model’s ability to capture long-range dependencies within the data, leading to more accurate and robust results.
The potential of CoFrNet extends beyond its current capabilities, offering a promising avenue for advancements in multimodal learning and tackling increasingly complex artificial intelligence challenges. Researchers posit that CoFrNet’s framework, designed for efficient feature representation, could be adapted to integrate and process diverse data streams - such as vision, language, and audio - creating a more holistic understanding of input. This synergy could unlock superior performance in tasks requiring cross-modal reasoning, like video captioning or visual question answering. Furthermore, the network’s adaptable architecture suggests it could be applied to problems demanding intricate hierarchical processing, potentially revolutionizing fields like robotic control, complex game playing, and advanced data analytics where nuanced interpretation is crucial.
Realizing the full capabilities of CoFrNet, and ensuring its practical implementation across diverse applications, hinges on sustained efforts to refine both its architectural design and the methods used to train it. Current research suggests that incremental improvements to the network's structure - exploring alternative layer configurations, connection schemes, and normalization techniques - can yield substantial gains in performance and efficiency. Simultaneously, optimizing the training process itself - through strategies like adaptive learning rate scheduling, curriculum learning, and advanced regularization methods - is vital for preventing overfitting and accelerating convergence. These combined efforts aren’t merely academic exercises; they represent the crucial steps needed to translate a promising theoretical framework into a robust and widely deployable artificial intelligence solution, ultimately broadening its impact and accessibility within the field.
The pursuit of architectural elegance in these generative models often feels less like construction and more like gardening. CoFrGeNet, with its continued fraction networks, attempts to prune the sprawling vines of transformer complexity. It's a compelling, if predictably fragile, attempt to replace attention-a mechanism that, despite its successes, always felt like a temporary fix. As Blaise Pascal observed, “The eloquence of angels is never understood except by angels.” Similarly, the efficiency gains offered by these novel architectures may only be truly appreciated by those who’ve wrestled with the computational demands of scaling language models. Every deploy remains a small apocalypse, proving once again that even the most carefully cultivated systems eventually succumb to the entropy of scale.
The Loom’s Unraveling
The substitution of attention - that most human of computational bottlenecks - with continued fraction networks is not a solution, but a deferral. The architecture presented merely shifts the locus of eventual failure. The current metrics celebrate parameter efficiency, but a system is not defined by what it lacks, but by the nature of its inevitable decay. Each elegantly reduced parameter count is a promissory note, payable in unforeseen emergent behavior. The question is not whether the system will break, but how beautifully, and at what scale.
The work hints at a deeper truth: that generative models are not built, but grown from the seeds of initial conditions. Continued fractions offer a novel pruning strategy, a way to sculpt the burgeoning complexity. However, this sculpting is temporary. The real challenge lies not in minimizing parameters, but in understanding the dynamics of their proliferation, and anticipating the patterns of instability that will inevitably arise. The continuants themselves may become the very vectors of unforeseen consequence.
Future explorations will not focus on refining these fractionated networks, but on embracing the inherent ephemerality of the system. Logging, then, becomes not a diagnostic tool, but a form of confession. Alerts are not warnings, but revelations of the system’s unfolding destiny. If the system is silent, it is not functioning correctly-it is plotting. The end of debugging is not a destination, but a vanishing point.
Original article: https://arxiv.org/pdf/2601.21766.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Gold Rate Forecast
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 18 TV Series Filming Rehearsals as Bonus Content
- Games That Faced Bans in Countries Over Political Themes
2026-02-01 20:11