Author: Denis Avetisyan
A new framework, A2RAG, dynamically builds and refines evidence from knowledge graphs to improve the accuracy and efficiency of complex question answering.
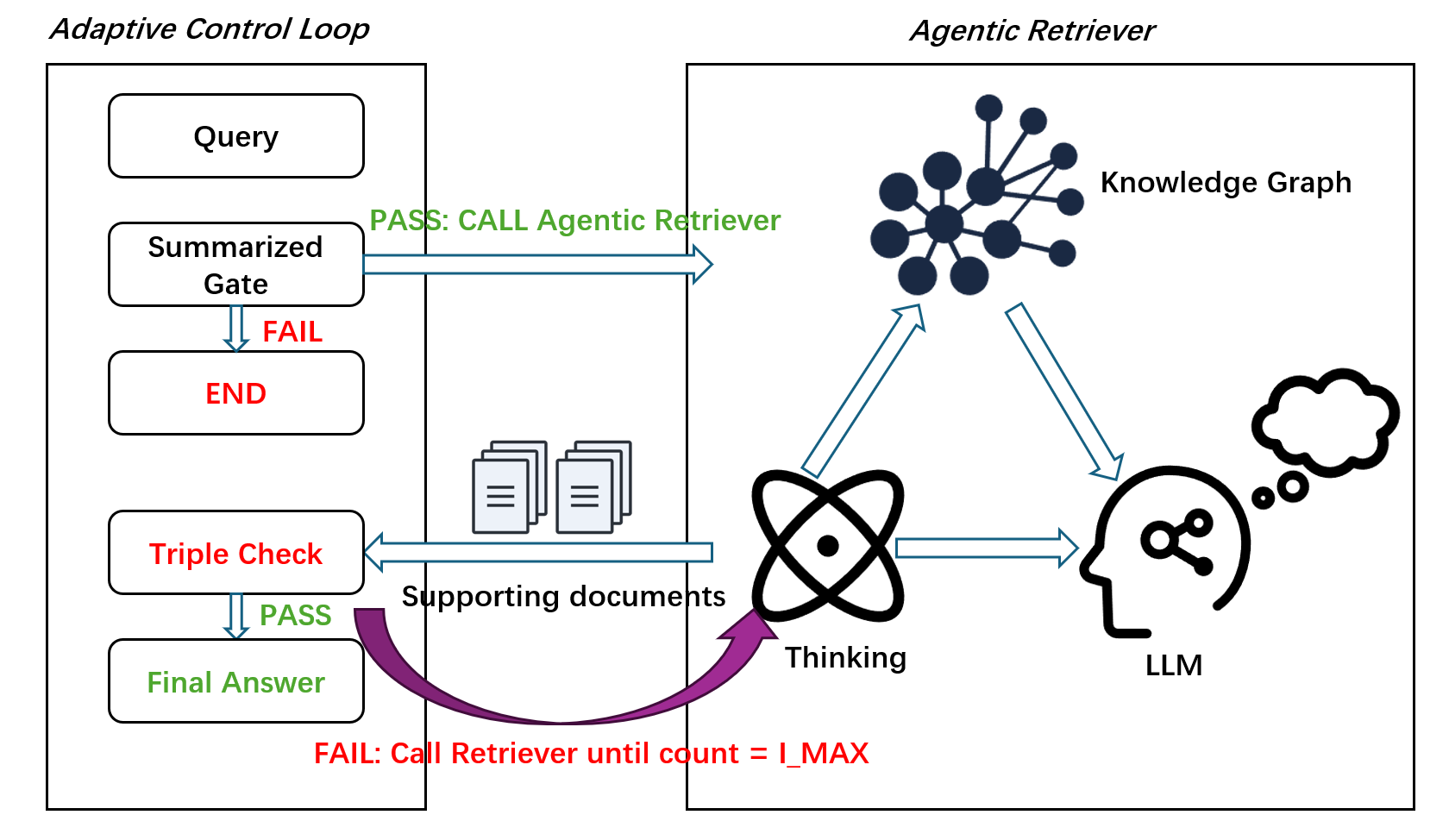
A2RAG leverages adaptive graph retrieval to enhance retrieval-augmented generation with robust provenance tracking and cost-aware reasoning.
While knowledge-intensive tasks benefit from retrieval-augmented generation, existing approaches struggle with both the cost of exhaustive searches and the loss of crucial detail during knowledge graph abstraction. To address these limitations, we introduce A2RAG-Adaptive Agentic Graph Retrieval for Cost-Aware and Reliable Reasoning-a framework that dynamically adjusts retrieval effort and recovers fine-grained information directly from source texts. This allows A2RAG to achieve substantial gains in multi-hop reasoning performance while simultaneously reducing token consumption and latency by approximately 50%. Could this adaptive, agentic approach unlock more efficient and reliable knowledge access for complex reasoning tasks across diverse domains?
The Limits of Conventional Reasoning Systems
Despite their impressive capacity for generating human-quality text, Large Language Models (LLMs) frequently encounter difficulties when confronted with tasks demanding deep, multi-hop reasoning. This limitation stems from inherent grounding issues – LLMs, while adept at identifying statistical relationships within data, lack a true understanding of the world and struggle to connect disparate pieces of information in a meaningful way. Essentially, these models excel at surface-level pattern recognition but falter when required to synthesize knowledge from multiple sources and draw logical inferences beyond the explicitly stated. Consequently, complex questions requiring several steps of deduction or the integration of diverse contextual factors often expose the boundaries of LLM reasoning capabilities, highlighting the need for methods that enhance their grounding in real-world knowledge and facilitate more robust inferential processes.
Conventional information retrieval systems frequently falter when confronted with complex queries demanding more than simple keyword matching. These methods typically identify documents based on superficial similarities, overlooking the subtle connections and inferential steps necessary for robust reasoning. Consequently, answers generated from these retrieved sources can be incomplete, inaccurate, or even misleading, as the system struggles to synthesize information across multiple documents and identify the most relevant relationships. This limitation stems from a reliance on statistical correlations rather than a true understanding of the underlying concepts, hindering the ability to support tasks requiring nuanced interpretation and multi-hop reasoning – where the answer isn’t explicitly stated but must be inferred through a chain of connected information.
Structuring Knowledge with GraphRAG
GraphRAG utilizes a Knowledge Graph to represent information, moving beyond simple text-based retrieval. This graph consists of entities – distinct objects or concepts – and the relationships that connect them. These relationships are explicitly defined, allowing the system to understand how different pieces of information are connected. For example, instead of treating “Paris” and “France” as independent tokens in a text corpus, a Knowledge Graph would represent “Paris” as an entity and establish a “isCapitalOf” relationship linking it to the “France” entity. This structured representation enables more precise information retrieval and supports reasoning capabilities by allowing the system to traverse relationships and infer new knowledge based on existing connections.
GraphRAG enhances information retrieval by representing knowledge as a Knowledge Graph, which explicitly defines entities and the relationships between them. This structured format allows the system to identify not only relevant entities but also their contextual connections, enabling a more nuanced search than traditional keyword-based methods. Reasoning over structured dependencies is facilitated by traversing these defined relationships within the graph; the system can infer new information based on existing connections, going beyond simple fact retrieval to provide answers that require understanding of how different pieces of information relate to one another. This capability is particularly valuable in complex queries where the answer isn’t directly stated but requires synthesis of information across multiple connected entities.
GraphRAG enhances Retrieval-Augmented Generation (RAG) by integrating graph-based retrieval methods. Traditional RAG systems often rely on semantic similarity searches within unstructured text, which can miss nuanced relationships between entities. GraphRAG, conversely, represents knowledge as a graph, allowing retrieval to consider not only semantic similarity but also the connections between entities and their relationships. This graph-based approach improves the grounding of generated responses by providing more contextually relevant information and facilitates reasoning by explicitly representing dependencies between facts, ultimately leading to increased accuracy and more coherent outputs.
Adaptive and Agentic Retrieval with A2RAG
A2RAG extends the capabilities of GraphRAG through the implementation of an Adaptive Control Loop. This loop facilitates iterative query refinement, allowing the system to progressively improve search accuracy. Central to this process is Triple-Check, a mechanism designed to verify the relevance and accuracy of retrieved evidence. Triple-Check operates by employing multiple validation steps to confirm the information obtained aligns with the original query and established knowledge, thereby enhancing the reliability of the final response and mitigating the risk of inaccurate or irrelevant information being presented.
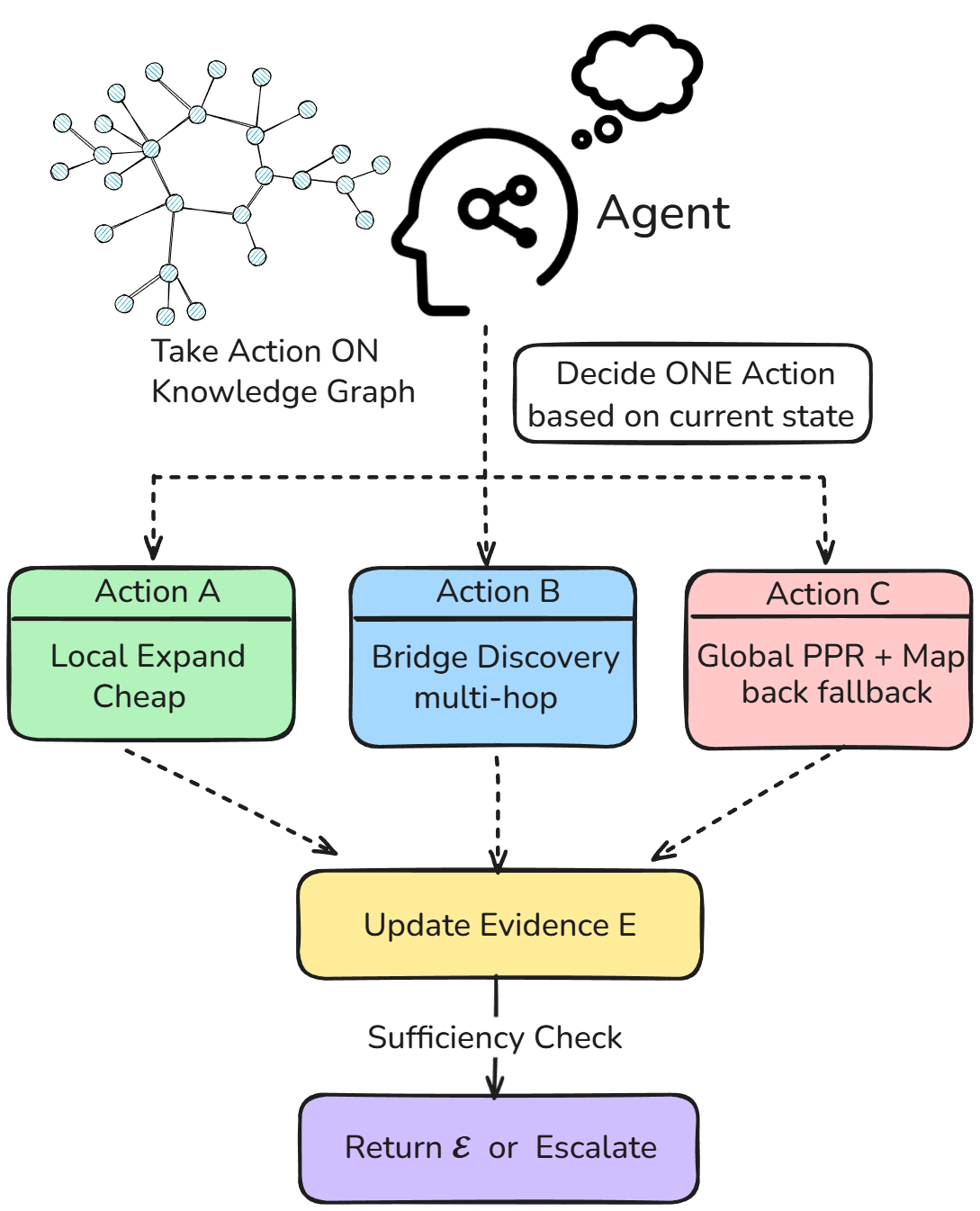
The Agentic Retriever utilizes Personalized PageRank to identify and prioritize relevant documents based on a user’s specific information needs, moving beyond standard keyword matching. This is coupled with a Provenance Map-back mechanism, which traces the origin and supporting evidence for each retrieved piece of information, facilitating a deeper understanding of the data’s context and reliability. A key operational principle is a local-first policy; the retriever prioritizes evidence directly supporting the initial query before expanding its search, ensuring a focused and efficient exploration of the knowledge source and maximizing comprehensive coverage of relevant information.
A2RAG employs both Entity Seed and Relation Seed to direct the Agentic Retriever’s information search. Entity Seed provides initial entities of interest, allowing the retriever to prioritize documents referencing those specific entities. Complementing this, Relation Seed specifies the relationships between these entities that are relevant to the query. By combining these two seeds, A2RAG focuses the retrieval process on documents containing both the target entities and the relationships connecting them, thereby increasing the precision and relevance of the retrieved evidence and enabling more effective multi-hop reasoning.
Performance evaluations demonstrate that A2RAG achieves up to a 15% improvement in recall compared to existing retrieval-augmented generation methods. Specifically, on the HotpotQA dataset, A2RAG attains a Recall@2 of 62.4% and a Recall@5 of 73.6%. On the 2WikiMultiHopQA dataset, the system achieves a Recall@2 of 58.9% and a Recall@5 of 69.2%. These metrics indicate a statistically significant enhancement in the ability of A2RAG to retrieve relevant information for complex, multi-hop question answering tasks, as measured by the proportion of questions for which relevant documents are included within the top 2 or 5 retrieved results.
Evaluations of A2RAG on question answering datasets demonstrate its retrieval performance. On the HotpotQA dataset, A2RAG achieves a Recall@2 of 62.4% and a Recall@5 of 73.6%, indicating that it successfully retrieves relevant evidence within the top 2 and top 5 retrieved documents, respectively, in 62.4% and 73.6% of cases. Performance on the 2WikiMultiHopQA dataset yields a Recall@2 of 58.9% and a Recall@5 of 69.2%, representing the system’s ability to retrieve relevant information within the top 2 and top 5 documents for this dataset.
Evaluations of A2RAG demonstrate substantial improvements in efficiency when processing multi-hop queries. Specifically, A2RAG achieves a 50% reduction in token usage compared to the IRCoT model, indicating a decreased computational cost per query. Furthermore, A2RAG exhibits a 40% reduction in mean latency – the average time taken to process a query – relative to IRCoT. These gains suggest that A2RAG offers a more resource-efficient approach to complex question answering, enabling faster response times and lower operational costs.
Validating Resilience and Broader Implications
Rigorous evaluations of A2RAG against established benchmarks, including HotpotQA and 2WikiMultiHopQA, consistently reveal its enhanced capabilities when compared to conventional retrieval-augmented generation methods. These datasets, designed to challenge a model’s ability to synthesize information from multiple sources, demonstrate A2RAG’s marked improvements in answer accuracy and contextual relevance. Specifically, the model excels in scenarios requiring complex reasoning and the integration of disparate knowledge fragments, surpassing the performance of existing systems and establishing a new standard for information retrieval and question answering. This superior performance is indicative of A2RAG’s capacity to not only locate relevant information, but to effectively utilize it in constructing coherent and insightful responses.
A2RAG addresses a critical limitation of many retrieval-augmented generation (RAG) systems – Extraction Loss – which refers to the tendency to overlook or discard crucial details during the information retrieval process. By actively minimizing this loss, the system is able to recover fine-grained information that is often essential for accurate and comprehensive answers. This isn’t simply about finding more information, but about retaining the subtleties and nuances present in the source material. The result is a marked improvement in answer quality, as responses are better supported by evidence and demonstrate a more thorough understanding of the subject. Crucially, this also enhances trustworthiness; because A2RAG prioritizes preserving detail, the generated answers are less prone to hallucination or unsupported claims, offering users a more reliable and defensible source of information.
A2RAG distinguishes itself through an iterative retrieval process, moving beyond single-pass information gathering to actively refine its understanding of a query. This approach allows the system to not simply locate relevant documents, but to build upon initial findings with subsequent retrievals, effectively “thinking through” complex questions. By repeatedly seeking and integrating new information, A2RAG can resolve ambiguities, identify hidden connections, and ultimately construct more comprehensive and nuanced answers. This capability proves particularly valuable in tasks demanding multi-step reasoning, where a superficial understanding of the source material would be insufficient; the iterative process allows the model to synthesize information from various sources, effectively mimicking a more deliberate and thoughtful approach to knowledge acquisition and problem-solving.
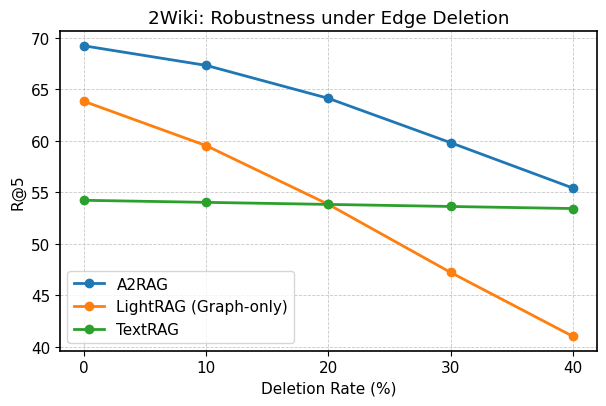
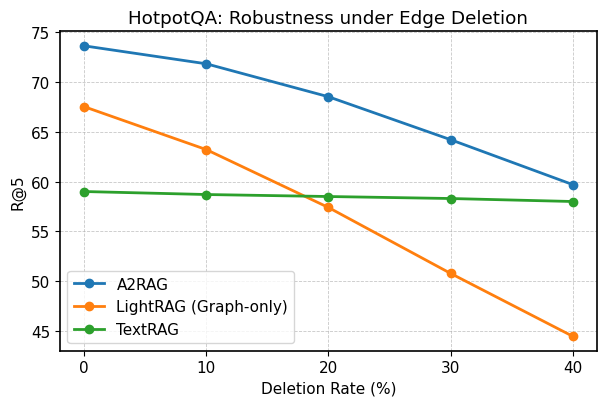
The architecture of A2RAG exhibits notable resilience even when faced with incomplete knowledge, as demonstrated by evaluations on the HotpotQA benchmark. Specifically, the system maintains a Recall@5 score of 59.7% even after the deliberate removal of 40% of the nodes and edges within the knowledge graph utilized for retrieval. This signifies a robust capacity to generate accurate responses despite significant data loss, a crucial attribute for real-world applications where knowledge sources are often imperfect or fragmented. The system’s ability to effectively leverage remaining knowledge, combined with its iterative retrieval process, allows it to compensate for missing information and maintain a high level of performance, suggesting a practical advantage over systems more vulnerable to knowledge gaps.
The pursuit of reliable reasoning, as demonstrated by A2RAG, echoes a fundamental principle of system design: structure dictates behavior. This framework’s adaptive graph retrieval doesn’t simply find information; it actively manages the flow of evidence, progressively acquiring details and ensuring provenance. As John McCarthy aptly stated, “The best way to predict the future is to invent it.” A2RAG embodies this sentiment by actively constructing a retrieval process tailored to the question’s needs, rather than passively accepting the limitations of a pre-built knowledge graph. The ability to recover fine-grained details, even with imperfect data, speaks to a system designed not just for current answers, but for continued learning and adaptation.
What Lies Ahead?
The pursuit of knowledge-intensive reasoning, as exemplified by A2RAG, repeatedly circles back to a fundamental question: what are systems actually optimizing for? Retrieval-augmented generation, while potent, risks becoming a sophisticated form of pattern completion rather than genuine understanding. The adaptive retrieval strategies presented here address the brittleness of static knowledge graphs, but do not resolve the core issue of grounding – connecting symbolic representations to the messy, ambiguous reality they purport to describe. A more nuanced approach is needed, one that acknowledges the inherent incompleteness and potential inaccuracies within any knowledge source.
Future work must move beyond simply retrieving more information, and instead focus on evaluating the quality of that information, and its relevance to the underlying reasoning process. The provenance tracking within A2RAG is a promising step, but a truly robust system will require mechanisms for self-correction, and the ability to identify and mitigate the effects of noise or bias. Simplicity, in this context, is not minimalism, but the discipline of distinguishing the essential – verifiable, consistent knowledge – from the accidental, the assumed, and the merely plausible.
Ultimately, the success of such systems will hinge not on their ability to mimic human intelligence, but on their capacity to augment it – to provide reliable, transparent, and actionable insights. The challenge, then, is not to build a perfect reasoning engine, but a useful one – a tool that understands its own limitations and operates within them.
Original article: https://arxiv.org/pdf/2601.21162.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
- Silver Rate Forecast
- Gold Rate Forecast
- Building Agents That Learn and Improve Themselves
- 15 Films That Were Shot Entirely on Phones
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Games That Faced Bans in Countries Over Political Themes
- 14 Movies Where the Black Character Refuses to Save the White Protagonist
2026-01-31 18:45