Author: Denis Avetisyan
A new framework combines symbolic reasoning with deep reinforcement learning to provide real-time, understandable insights into how AI agents manage complex networks.
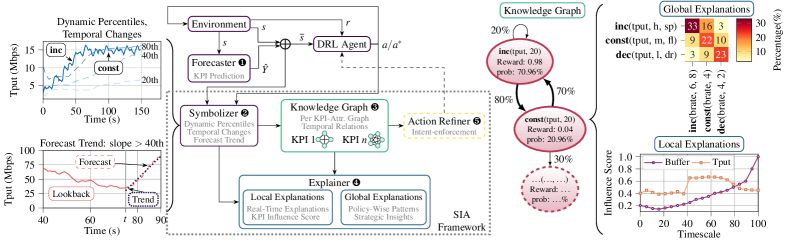
This paper introduces Symbolic Interpretability for Anticipatory (SIA) deep reinforcement learning, leveraging knowledge graphs to improve agent design and performance in network control without retraining.
While deep reinforcement learning holds promise for adaptive network control, its ‘black box’ nature hinders practical deployment, particularly when leveraging predictive analytics. This paper introduces ‘SIA: Symbolic Interpretability for Anticipatory Deep Reinforcement Learning in Network Control’, a novel framework that provides real-time, symbolic explanations for forecast-augmented DRL agents using knowledge graphs and a new Influence Score metric. SIA achieves sub-millisecond interpretability, revealing hidden issues in agent design and enabling performance improvements of up to 25% without retraining. Can this level of transparency unlock the full potential of proactive, anticipatory control in future mobile networks and beyond?
The Inherent Instability of Static Networks
Conventional network management historically centers on pre-defined, static configurations – a methodology increasingly challenged by the realities of modern digital landscapes. These systems, designed for predictable traffic patterns and stable user bases, struggle to accommodate the volatile demands of contemporary applications and the sheer scale of connected devices. The inflexibility of static controls leads to performance bottlenecks, increased latency, and diminished quality of service as networks are bombarded with fluctuating loads and unforeseen surges in data transmission. This inherent limitation creates a significant impediment to delivering seamless experiences, particularly for bandwidth-intensive services like streaming media, online gaming, and cloud computing, where responsiveness and reliability are paramount. Consequently, networks reliant on static configurations often fail to effectively utilize available resources or adapt to evolving user needs, ultimately hindering optimal performance and scalability.
Network responsiveness is fundamentally limited by systems that react to conditions as they arise; anticipating future states, however, presents a significantly greater challenge. Traditional control mechanisms operate on current data, making them inherently delayed in addressing evolving demands or unforeseen disruptions. The complexity of modern networks-influenced by fluctuating user behavior, unpredictable application loads, and external events-means that by the time a reactive system responds, the initial problem may have already shifted or amplified. Successfully managing these dynamics requires a predictive capability-an ability to forecast network traffic patterns, identify potential bottlenecks, and proactively adjust resources before issues manifest. This necessitates moving beyond simple feedback loops and embracing methodologies capable of learning from historical data and modeling future network behavior, a task exceeding the scope of purely reactive designs.
Network management is evolving beyond simple reaction to changing conditions; instead, a proactive approach utilizing continuous learning is becoming essential. Traditional methods, designed for stable environments, struggle with the inherent unpredictability of modern networks and user behavior. This necessitates control strategies capable of anticipating future demands and dynamically adjusting resources before performance is impacted. Such systems employ machine learning algorithms to analyze historical data, identify patterns, and predict upcoming network states, enabling preemptive optimization of bandwidth allocation, routing protocols, and security measures. This shift towards intelligent, learning-based control isn’t merely about responding to problems; it’s about preventing them, ultimately creating more resilient, efficient, and user-centric network experiences.
Contemporary network management systems often operate in isolation, treating network traffic as an internally generated phenomenon. This approach overlooks the substantial influence of external predictors – encompassing everything from social media trends driving data demand to weather patterns affecting connectivity, and even macroeconomic indicators signaling shifts in usage. Consequently, these systems struggle to preemptively adjust to fluctuations originating outside the network itself. While sophisticated algorithms can react to existing congestion, they lack the capacity to integrate forecasts of external events – such as an anticipated surge in streaming during a popular televised event or a predicted drop in signal quality due to solar flares – to proactively optimize resource allocation and maintain consistent performance. The inability to effectively leverage these predictive signals represents a significant limitation in achieving truly adaptive and resilient network infrastructure.

Intelligent Agents: A Foundation for Proactive Control
Deep Reinforcement Learning (DRL) provides a robust methodology for constructing adaptive network controllers by leveraging the capabilities of deep neural networks to approximate optimal control policies. Unlike traditional control methods requiring explicit modeling of system dynamics, DRL agents learn directly from data through interactions with the network environment. This learning process involves an agent continuously selecting actions, observing the resulting state transitions and rewards, and iteratively refining its strategy to maximize cumulative rewards. The “deep” aspect refers to the use of deep neural networks to handle the complexity of high-dimensional state and action spaces commonly found in network control problems, enabling the agent to generalize learned behaviors to unseen scenarios and adapt to changing network conditions without requiring manual recalibration or redesign.
Deep Reinforcement Learning (DRL) agents operate by iteratively refining a control policy through interaction with an environment. This process involves the agent taking actions, observing the resulting state and reward, and adjusting its strategy to maximize cumulative reward. The agent doesn’t rely on pre-programmed instructions but instead learns through trial and error, exploring various actions and exploiting those that yield positive outcomes. This learning is achieved by constructing a policy, which maps states to actions, and updating this policy based on the received reward signal. The reward function is critical, as it defines the desired behavior and guides the agent’s learning process. Over time, the agent converges on an optimal, or near-optimal, policy that maximizes performance according to the defined reward structure.
Accurate forecasting of Key Performance Indicators (KPIs) is fundamental to the efficacy of DRL-based network control. This necessitates prediction of both controllable KPIs – those directly influenced by agent actions, such as bandwidth allocation or power settings – and exogenous KPIs, representing external factors outside of the agent’s direct control like user demand or network traffic patterns. The agent’s ability to anticipate future KPI values, even those driven by external influences, directly impacts its capacity to formulate effective control policies and maximize cumulative rewards. Prediction horizons and accuracy requirements for these KPIs are determined by the specific network dynamics and control objectives, influencing the complexity of the forecasting models employed.
Temporal Difference (TD) Learning is a core component of reinforcement learning algorithms, enabling agents to predict future rewards without waiting for an episode to complete. Unlike Monte Carlo methods which require full episode data, TD learning updates predictions based on the difference between the current estimate and a more informed estimate obtained after taking a single action – this difference is termed the TD error. This allows for online learning and faster convergence. Specifically, TD methods propagate information backward from later time steps to earlier ones, bootstrapping the value function estimate. Algorithms such as Q-learning and SARSA utilize TD learning to iteratively refine their action-value functions, enabling the agent to select actions that maximize cumulative reward over time and ultimately optimize control policies. The update rule generally follows the form: V(s) \leftarrow V(s) + \alpha [R + \gamma V(s') - V(s)] , where α is the learning rate, γ is the discount factor, R is the immediate reward, and s and s' represent the current and next states, respectively.
Enhancing Predictive Accuracy and Agent Performance
The PatchTST architecture achieves accurate time series forecasts by adapting the Transformer model to handle long sequences more efficiently. Unlike traditional Transformers which have quadratic complexity with sequence length, PatchTST divides the input time series into smaller, non-overlapping patches. These patches are then processed in parallel, reducing computational cost and enabling the model to capture long-range dependencies. The architecture employs a series of transformer blocks, followed by a final linear layer for forecasting, and has demonstrated state-of-the-art performance on several long-sequence time series forecasting benchmarks. This approach allows for the modeling of complex temporal patterns with increased efficiency and scalability compared to standard time series models like ARIMA or LSTM.
Multi-layer Perceptrons (MLPs) serve as a core component for time series forecasting due to their capacity to approximate complex non-linear relationships within sequential data. Robustness is further enhanced through the implementation of Reversible Instance Normalization (RIN). RIN normalizes activations within each layer, improving training stability and generalization performance, particularly in deep networks. Unlike traditional batch normalization, RIN’s reversible nature avoids information loss during the normalization process, leading to more accurate forecasts and improved performance in dynamic environments. This approach facilitates efficient learning and adaptation to varying data distributions, crucial for applications requiring reliable predictive capabilities.
An Action Refinement Module (ARM) is implemented to enhance the performance of Deep Reinforcement Learning (DRL) agents by incorporating forecasting data into policy refinement. The ARM utilizes predictions generated by time series models – such as PatchTST and Multi-layer Perceptrons – to adjust the DRL agent’s existing policy, rather than replacing it. Testing demonstrates that this approach yields significant performance gains; specifically, cumulative reward increased by up to 25.7% in Radio Access Network (RAN) slicing scenarios and 12.0% in Massive Multiple-Input Multiple-Output (MIMO) scheduling implementations when compared to baseline DRL agent performance.
Validation of the proposed framework involved integration with three distinct radio access network (RAN) applications: Adaptive Bitrate Streaming, Massive MIMO Scheduling, and RAN Slicing. Performance testing across these applications demonstrated a 9% improvement in bitrate following redesign of the Deep Reinforcement Learning (DRL) agent. This improvement confirms the framework’s ability to enhance performance within practical RAN scenarios and highlights the efficacy of the DRL agent’s optimized policy when applied to real-world network challenges.

The Symbolic AI Interpretation (SIA) Framework: Exposing the Logic of Control
The Symbolic AI Interpretation (SIA) Framework addresses a critical challenge in artificial intelligence: deciphering the decision-making processes of complex, anticipatory Deep Reinforcement Learning (DRL) agents. Unlike traditional ‘black box’ AI systems, SIA provides a pathway to not just what an agent decides, but why. By translating the agent’s internal state into a symbolic representation – a structured understanding of network conditions and potential actions – the framework enables humans to follow the agent’s reasoning. This is achieved through the construction of Per-KPI Knowledge Graphs, which articulate the agent’s comprehension of relevant Key Performance Indicators. Ultimately, SIA moves beyond mere prediction to offer genuine insight into the agent’s logic, fostering trust and facilitating collaboration between humans and AI in dynamic environments.
The agent’s comprehension of complex network dynamics and potential responses is structured through Per-KPI Knowledge Graphs, effectively creating a symbolic representation of its internal reasoning. These graphs don’t simply catalog data; they articulate relationships between Key Performance Indicators (KPIs)-such as network latency, bandwidth, or packet loss-and the actions the agent can undertake to influence them. Each KPI is a node, and the edges connecting them represent the agent’s learned understanding of how changes in one KPI will affect others, and ultimately, the chosen action. This allows the system to move beyond correlating inputs and outputs, instead building a structured, interpretable model of the network, revealing why a particular action was selected given the current state-a crucial step towards trustworthy and reliable AI in network management.
The efficacy of a deep reinforcement learning agent hinges on its ability to discern critical information from a complex environment, and the Influence Score (IS) metric provides a quantitative assessment of just that. By analyzing the agent’s Per-KPI Knowledge Graph, the IS determines the degree to which each Key Performance Indicator (KPI) contributes to the final decision-making process. A higher Influence Score indicates a stronger correlation between a specific KPI and the chosen action, effectively highlighting the factors the agent deems most important. This allows for a granular understanding of the agent’s reasoning; instead of simply knowing what action was taken, one can determine why, based on the weighted importance of each relevant KPI. The metric isn’t merely descriptive, but predictive; changes in the IS can foreshadow shifts in the agent’s behavior, offering insight into its evolving strategy and adaptation to dynamic conditions.
The Symbolic AI Interpretation (SIA) framework doesn’t simply offer insight into an agent’s decisions; it delivers that understanding in real-time. Crucially, the SIA pipeline achieves explainability with a latency of less than one millisecond, and testing has demonstrated a measured latency of just 0.65 milliseconds. This rapid processing effectively transforms a traditionally opaque ‘black box’ deep reinforcement learning agent into a transparent system, allowing for immediate comprehension of its reasoning. The speed of the SIA pipeline isn’t merely a technical achievement; it’s a functional necessity for applications demanding immediate trust and verification, such as autonomous systems operating in dynamic and critical environments.

The pursuit of truly intelligent systems demands more than mere functionality; it necessitates demonstrable correctness. This work, introducing SIA, aligns with that principle by prioritizing interpretable explanations within deep reinforcement learning for network control. Grace Hopper famously stated, “It’s easier to ask forgiveness than it is to get permission.” While perhaps unconventional in formal verification, the spirit of this quote resonates with SIA’s approach: providing real-time insights into an agent’s decision-making process, even within the complexity of a dynamic network. Such transparency facilitates a form of ‘post-hoc’ validation, allowing designers to understand why an agent acts as it does, and refine its algorithms-a far more efficient path than relying solely on empirical testing. The framework’s use of knowledge graphs and influence scores embodies a commitment to mathematical rigor, ensuring that explanations are not simply observed correlations, but logically derived truths.
Beyond Explanation: Charting a Course for Anticipatory Systems
The pursuit of intelligibility in deep reinforcement learning, as demonstrated by this work, frequently resembles a cartographer meticulously documenting a landscape already traversed. SIA offers a valuable post-hoc analysis, revealing the ‘why’ after the agent has acted. However, true elegance resides not merely in explaining decisions, but in anticipating the need for explanation itself. Future iterations should explore embedding symbolic reasoning directly within the learning process – a synthesis where the agent’s knowledge graph isn’t a shadow of its actions, but a guiding principle before they occur.
A persistent challenge remains the inherent fragility of knowledge graphs. Maintaining a consistently accurate and comprehensive representation of a dynamic network is computationally expensive, and susceptible to cascading errors. The reliance on influence scores, while pragmatic, introduces a degree of approximation. The field would benefit from research into self-validating knowledge structures – systems capable of detecting and correcting inconsistencies without external intervention, mirroring the robustness of fundamental mathematical axioms.
Ultimately, the value of interpretable AI hinges on its capacity to transcend mere transparency and facilitate genuine control. The next logical step is not simply to understand what an agent is doing, but to prove its reasoning is logically sound – a transition from empirical observation to formal verification. Only then can one confidently claim to have achieved not just intelligence, but understandable intelligence.
Original article: https://arxiv.org/pdf/2601.22044.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Top 20 Dinosaur Movies, Ranked
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Invincible Season 4 Gender Swaps Tech Jacket As Fans Question Major Comic Change
2026-01-30 17:27