Author: Denis Avetisyan
Researchers have developed ACFormer, a novel approach that blends convolutional efficiency with the power of attention mechanisms to dramatically improve time series prediction.
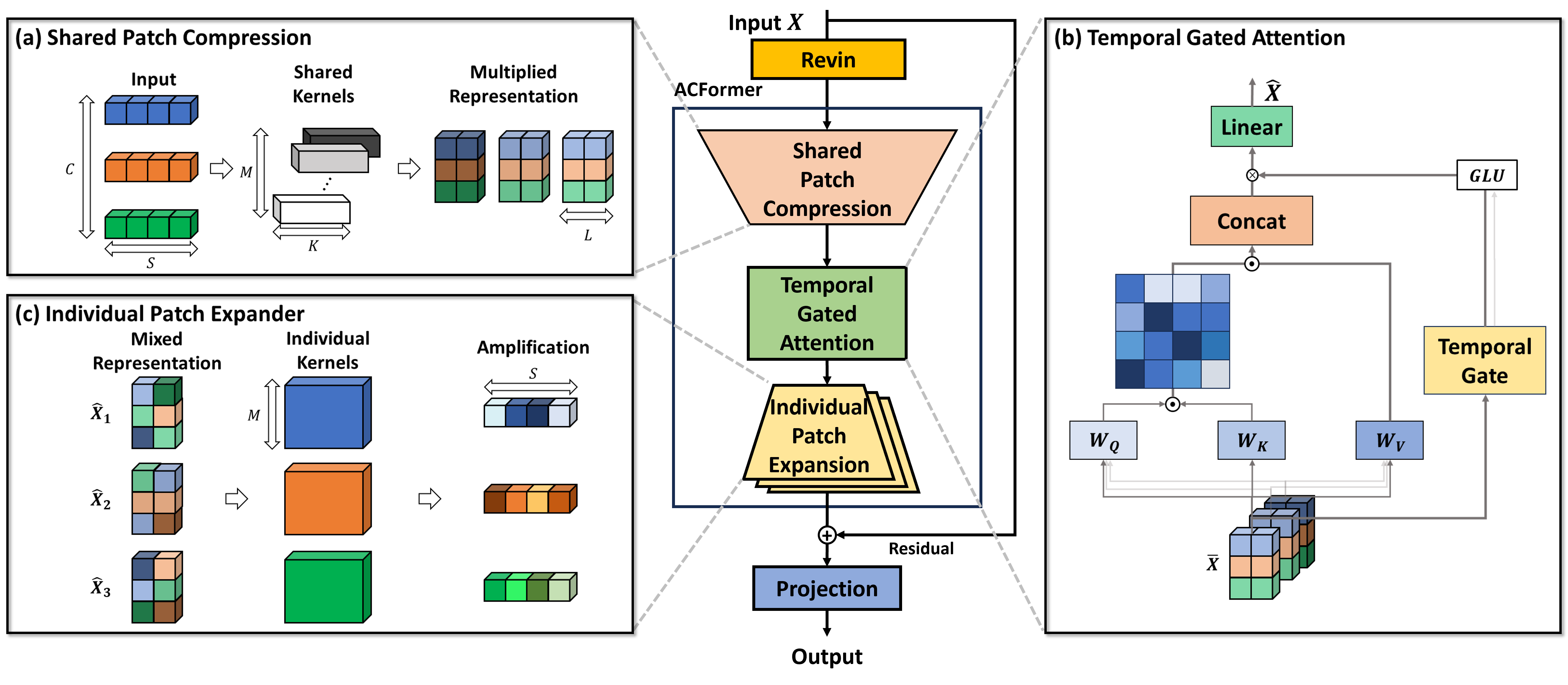
ACFormer leverages auto-convolutional encoding to mitigate non-linearity and achieve state-of-the-art performance on multivariate time series forecasting tasks.
While linear models excel at capturing global trends in time series forecasting, they often struggle with the inherent non-linearities present in complex sequential data. This limitation motivates the development of ‘ACFormer: Mitigating Non-linearity with Auto Convolutional Encoder for Time Series Forecasting’, which introduces a novel architecture designed to reconcile linear efficiency with non-linear feature extraction. ACFormer leverages an auto-convolutional encoder to capture fine-grained temporal dependencies and reconstruct variable-specific patterns, achieving state-of-the-art performance across multiple benchmarks. Can this hybrid approach unlock new possibilities for accurate and robust forecasting in increasingly complex real-world applications?
Decoding the Temporal Landscape: The Challenge of Prediction
The ability to accurately predict future values in a time series – a sequence of data points indexed in time order – underpins critical decision-making across a remarkably diverse range of fields. In energy management, precise forecasting of electricity demand allows for optimized grid operation and resource allocation, minimizing waste and ensuring reliable power supply. Financial modeling relies heavily on time series analysis to predict stock prices, assess risk, and inform investment strategies. Beyond these, accurate predictions are also essential in supply chain management – anticipating future demand to optimize inventory levels – and even in public health, where forecasting disease outbreaks enables proactive resource deployment and intervention. The pervasive need for effective time series forecasting highlights its importance as a fundamental tool for planning, optimization, and risk mitigation in an increasingly data-driven world.
Conventional time series forecasting techniques, such as ARIMA and exponential smoothing, frequently encounter difficulties when applied to real-world datasets. These methods are often built on the assumption of data stationarity – that the statistical properties of the time series, like mean and variance, remain constant over time – a condition rarely met in practice. Furthermore, they struggle to capture long-term dependencies, where events distant in the past significantly influence future outcomes. This limitation arises from their reliance on finite historical windows and difficulties in modeling complex, non-linear relationships inherent in many dynamic systems. Consequently, predictions can degrade rapidly as the forecasting horizon extends, particularly when dealing with data exhibiting trends, seasonality, or external shocks, highlighting the need for more robust and adaptive methodologies.
Despite the increasing success of deep learning in time series forecasting, a significant hurdle remains in practical application: computational cost. Many state-of-the-art models, reliant on architectures like Transformers or complex recurrent networks, demand substantial processing power and memory, hindering their deployment on resource-constrained devices or for real-time predictions with high-volume data streams. This inefficiency stems from the need to process sequential data step-by-step and the large number of parameters often required to capture intricate temporal dependencies. Consequently, researchers are actively exploring techniques such as model compression, quantization, and the development of more lightweight architectures to reduce computational burden without sacrificing predictive accuracy, ultimately aiming to bridge the gap between research prototypes and scalable, real-world solutions.
Unveiling Sequential Patterns: Leveraging Transformers
Transformer architectures, initially designed for tasks like machine translation and text summarization, address limitations of recurrent neural networks (RNNs) in capturing long-range dependencies within sequential data. Traditional RNNs process data sequentially, potentially losing information from earlier time steps as it propagates through the network. Transformers, conversely, utilize a self-attention mechanism that allows each data point in a sequence to directly attend to all other points, regardless of their distance. This enables the model to identify and leverage relationships between distant data points, which is crucial for accurate time series forecasting where patterns can span extended periods. The parallelizable nature of the self-attention mechanism also offers significant computational advantages over sequential RNN processing, although the quadratic complexity with respect to sequence length remains a challenge.
iTransformer and PatchTST represent adaptations of the Transformer architecture for sequential data processing. Both models utilize patch embedding, a technique that divides the input time series into smaller, fixed-length segments – or ‘patches’ – which are then linearly projected into a higher-dimensional space. This approach reduces computational complexity and allows the model to focus on relevant subsequences. Crucially, both architectures leverage the self-attention mechanism inherent in Transformers, enabling the model to weigh the importance of different patches within the sequence when making predictions, thus capturing long-range dependencies without the limitations of recurrent neural networks.
The computational expense of applying standard Transformer architectures to sequential data arises from the quadratic complexity of the self-attention mechanism with respect to sequence length. Specifically, calculating attention weights requires O(n^2) operations, where ‘n’ represents the length of the input sequence. This becomes a significant bottleneck when dealing with long time series, as both memory requirements and processing time scale rapidly. Consequently, research efforts are focused on developing more efficient Transformer designs, including techniques like sparse attention, linear attention, and the use of approximations to reduce the computational burden while preserving model performance. These approaches aim to decrease the complexity from quadratic to linear or near-linear with respect to sequence length, enabling the practical application of Transformers to longer and more complex sequential datasets.
Deconstructing Time: The ACFormer Architecture
ACFormer utilizes a hybrid architecture integrating auto-convolutional layers and channel-wise attention mechanisms to model temporal dependencies in time series data. Auto-convolution, a form of depthwise separable convolution, efficiently captures local temporal patterns by convolving each input channel independently. Simultaneously, channel-wise attention dynamically weights the importance of each channel, enabling the network to focus on the most relevant features and capture long-range, global dependencies. This combination allows ACFormer to effectively model both short-term and long-term relationships within the time series, improving its ability to learn complex temporal dynamics compared to models relying solely on one approach.
Variance attention within the ACFormer architecture operates by dynamically weighting the importance of individual channels based on their contribution to the time series forecasting task. This is achieved through the calculation of channel-wise variances, which serve as a measure of feature distinctiveness and predictive power. Channels exhibiting higher variance are assigned greater weight during the attention mechanism, effectively amplifying their influence on the final prediction. This adaptive weighting allows the model to prioritize the most informative features and suppress noise or redundant information, leading to improved forecasting accuracy, particularly in complex or non-stationary time series data.
ACFormer achieves state-of-the-art forecasting performance by strategically incorporating temporal gates and optimizing the receptive field size within its architecture. This optimization allows the model to effectively capture long-range dependencies in time series data, resulting in demonstrably lower Mean Absolute Error (MAE) values across a variety of datasets and prediction horizons, as detailed in Tables 7 and 8. Critically, ACFormer maintains high forecasting accuracy even when applied to non-stationary data, a common challenge in time series analysis, indicating its robustness and adaptability to complex temporal patterns.
Empirical Validation: Performance Across Datasets
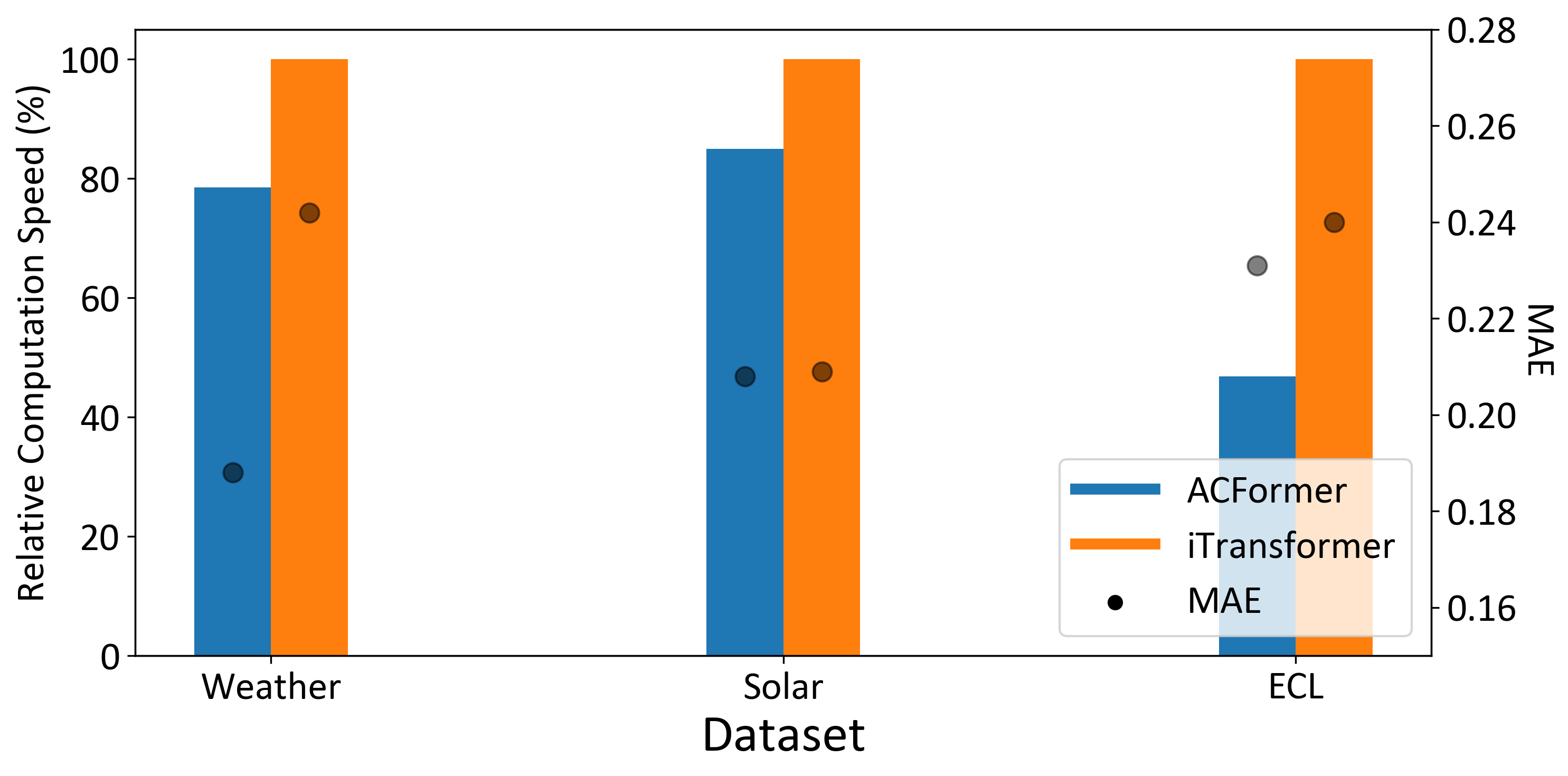
ACFormer’s performance was quantitatively assessed using three publicly available benchmark datasets commonly employed in time series forecasting research. The Energy Consumption Load (ECL) dataset comprises electricity consumption data with varying temporal resolutions. The Electricity Transformer Temperature (ETT) dataset consists of multivariate time series data representing temperature, humidity, and load measurements from power plants. Finally, the Solar dataset contains solar power generation data, providing a diverse evaluation scenario. Rigorous testing across these datasets allowed for a comprehensive comparison of ACFormer against established forecasting models, confirming its generalizability and robustness to different data characteristics and scales.
Empirical results demonstrate ACFormer’s consistent performance gains over established forecasting methods across multiple benchmark datasets. Specifically, ACFormer exhibits enhanced capabilities in modeling complex temporal dependencies within time series data, leading to statistically significant improvements in forecasting accuracy as measured by metrics including Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE). This superior performance is attributable to the model’s architecture, which effectively captures non-linear relationships and long-range dependencies often missed by conventional approaches, resulting in more precise predictions across varying data frequencies and complexities.
ACFormer demonstrates improved parameter efficiency relative to standard transformer-based models, as illustrated in Figure 4. This model achieves comparable, and in many cases superior, performance on benchmark datasets using fewer trainable parameters. Analysis of individual receptive fields supports the efficacy of the variance attention mechanism, showing its ability to prioritize and focus on the most pertinent channels and features within the input data, thus contributing to the model’s accuracy despite its reduced complexity. This focused attention allows for effective information processing without the need for the extensive parameterization characteristic of traditional transformers.
Beyond Prediction: The Broader Impact of Temporal Understanding
The ACFormer architecture marks a notable advancement in time series forecasting by effectively integrating attention mechanisms with convolutional neural networks. This hybrid approach allows the model to capture both local patterns and long-range dependencies within sequential data, addressing limitations found in traditional methods. Through the innovative use of autocorrelation-aware attention, ACFormer dynamically adjusts its focus based on the inherent characteristics of the time series, leading to improved accuracy and efficiency. Initial results demonstrate that this architecture outperforms established forecasting models on several benchmark datasets, suggesting its potential for widespread application in fields requiring precise predictions of future trends – from financial markets and energy consumption to weather patterns and resource management.
The adaptability of the ACFormer architecture extends beyond traditional time series forecasting, presenting compelling opportunities for innovation in fields like anomaly detection and predictive maintenance. By leveraging ACFormer’s capacity to model complex temporal dependencies, researchers can develop systems capable of identifying unusual patterns indicative of system failures or potential defects. In predictive maintenance, this translates to anticipating equipment malfunctions before they occur, optimizing maintenance schedules, and reducing downtime-a significant advantage for industries reliant on continuous operation. Further investigation into these areas could yield robust, data-driven solutions for enhancing operational efficiency and reliability across a wide spectrum of applications, from manufacturing and energy to healthcare and transportation.
The development of robust time series forecasting models, such as ACFormer, extends beyond mere predictive accuracy; it fundamentally enhances decision-making capabilities across diverse sectors. More precise forecasts in areas like supply chain management minimize waste and optimize resource allocation, while improved energy demand prediction facilitates the integration of renewable sources and reduces reliance on fossil fuels. Within the financial industry, accurate forecasting allows for better risk assessment and investment strategies, potentially stabilizing markets. Ultimately, the capacity to anticipate future trends with greater reliability empowers proactive strategies, fostering resilience and contributing to a more sustainable future by enabling informed choices that prioritize efficiency, conservation, and long-term planning.
The ACFormer architecture, as detailed in the paper, embodies a spirit of challenging established norms within time series forecasting. It isn’t simply adopting existing methodologies, but actively dissecting their limitations-specifically, the handling of non-linearity-to forge a novel approach. This resonates deeply with the sentiment expressed by Grace Hopper: “It’s easier to ask forgiveness than it is to get permission.” The researchers, much like Hopper advocating for proactive experimentation, bypassed rigid adherence to conventional methods, instead prioritizing the exploration of auto-convolution and linear projections to enhance both performance and efficiency. This willingness to deviate from established practice is precisely what drives innovation, proving that true progress often lies beyond the boundaries of accepted norms.
What Lies Ahead?
The architecture presented here, ACFormer, operates on a familiar principle: dissect a complex system to understand its components, then rebuild it with improvements. It’s a satisfyingly reductionist approach, but one must question the completeness of the dissection. While ACFormer effectively addresses non-linearity through auto-convolution and attention, the very notion of ‘linearity’ in real-world time series feels increasingly like a convenient fiction. The universe rarely obliges with neat, predictable relationships; the model’s success is a testament to its approximation, not a fundamental truth.
Future work shouldn’t focus solely on refining existing techniques, but on actively seeking the inherent messiness. Can the framework be adapted to explicitly model and exploit chaotic elements? The current emphasis on receptive fields, while pragmatic, implicitly assumes a finite ‘memory’ for the system. Exploring architectures that allow for infinite or dynamically-adjusted memory could prove revealing, even if it introduces computational challenges.
Ultimately, the goal isn’t simply to forecast time series, but to reverse-engineer the underlying generative process. ACFormer is a step in that direction, but the true prize lies not in prediction accuracy, but in a deeper, more complete understanding of the systems being modeled. The challenge is to build models that don’t just fit the data, but explain it – and that requires a willingness to confront the uncomfortable realities of complexity and uncertainty.
Original article: https://arxiv.org/pdf/2601.20611.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-01-29 16:12