Author: Denis Avetisyan
A new generative model leverages artificial intelligence to create realistic financial data, improving the performance of portfolio optimization strategies.
This paper introduces MarketGAN, a factor-based generative adversarial network for augmenting multivariate financial time series and enhancing high-dimensional financial modeling.
Financial time series are often hampered by data scarcity, limiting the performance of high-dimensional models-this paper introduces ‘MarketGANs: Multivariate financial time-series data augmentation using generative adversarial networks’ to address this challenge. By embedding an explicit asset-pricing factor structure within a generative adversarial network employing a temporal convolutional network, MarketGAN generates synthetic returns that preserve critical cross-sectional dependence and inter-temporal dynamics. Demonstrating superior performance to conventional bootstrap approaches in replicating stylized facts and enhancing portfolio optimization, the model offers tangible economic value when factor information is available. Could this factor-based generative approach unlock more robust and accurate financial modeling in increasingly complex market environments?
The Illusion of Historical Data in Finance
Portfolio optimization techniques historically depend on analyzing past financial data to predict future performance; however, this approach is fundamentally challenged by the non-stationary nature of financial markets and the infrequent occurrence of extreme events. Financial time series rarely exhibit consistent statistical properties over time, meaning relationships observed in historical data may not hold true in the future. More critically, reliance on past data often underestimates the probability and potential impact of ‘black swan’ events – those rare, unpredictable occurrences with significant consequences. Consequently, strategies optimized using solely historical data can create a false sense of security, leaving portfolios vulnerable to unforeseen market shocks and hindering their ability to navigate genuine long-term risk. This necessitates the development of more robust techniques that account for both evolving market dynamics and the potential for extreme, yet plausible, scenarios.
Financial time series are notoriously difficult to model due to inherent statistical properties that deviate from assumptions underlying many standard techniques. A key challenge is volatility clustering, where periods of high price fluctuations tend to be followed by further volatility, and vice versa – a phenomenon not captured by models assuming constant variance. Beyond this, complex dependencies exist within and between financial assets, extending beyond simple correlations; these dependencies can be non-linear and time-varying, requiring sophisticated analytical tools to even partially characterize. Consequently, techniques reliant on linear relationships or stationary data-like basic regression or certain forecasting models-often fail to accurately predict future behavior or adequately assess risk, necessitating more advanced approaches capable of capturing these intricate dynamics.
The development of robust financial models increasingly relies on the generation of synthetic data for rigorous testing and validation – a process known as stress-testing and backtesting. However, simply creating random numbers that mimic statistical properties isn’t enough; truly effective synthetic datasets must preserve the intricate economic realism inherent in actual market behavior. Capturing phenomena like ‘fat tails’ – the tendency for extreme events to occur more frequently than predicted by normal distributions – and complex correlations between assets poses a substantial challenge. Failing to accurately replicate these features can lead to underestimated risks and flawed investment strategies, as models may not react as expected when confronted with genuine market shocks. Consequently, researchers are actively exploring advanced techniques, including agent-based modeling and machine learning, to create synthetic financial data that not only passes statistical tests but also convincingly simulates the dynamics of real-world economies.
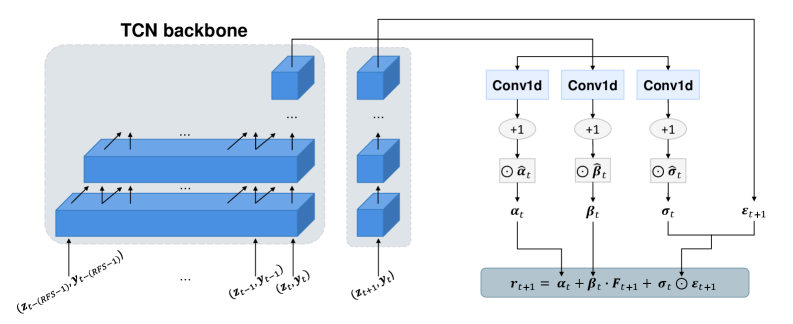
MarketGAN: A Pragmatic Approach to Synthetic Finance
MarketGAN is a generative modeling framework specifically engineered for the synthesis of multi-asset return data. Unlike traditional generative models, MarketGAN prioritizes the maintenance of statistical relationships observed in real financial markets, termed ‘economically meaningful dependence structures’. This is achieved by generating correlated asset returns rather than independent samples, reflecting the inherent interconnectedness of financial instruments. The framework aims to produce synthetic datasets suitable for backtesting trading strategies, stress-testing portfolios, and evaluating risk management models where accurate representation of asset correlations is crucial. The generated data is high-dimensional, accommodating a large number of assets and their complex interdependencies.
MarketGAN leverages Temporal Convolutional Networks (TCNs) within both its generative and discriminative components to effectively model time-series dependencies in financial data. TCNs, unlike recurrent neural networks, process the entire input sequence in parallel, facilitating the capture of long-range dependencies without the vanishing gradient limitations common in recurrent architectures. This is achieved through the use of dilated convolutions, which increase the receptive field of the network with depth, allowing it to consider data points further back in time. The parallel processing capability of TCNs also provides significant computational efficiency, enabling MarketGAN to handle the high dimensionality of asset return data and large training datasets.
The MarketGAN architecture integrates a factor model as an inductive bias to constrain the generative process and ensure economic plausibility in the synthetic data. This factor model decomposes asset returns into exposures to a smaller number of common factors – representing macroeconomic variables or systematic risks – and asset-specific idiosyncratic shocks. By explicitly modeling returns as a linear combination of these factors r = \beta f + \epsilon , where r is the asset return, β represents factor loadings, f denotes the factor returns, and ε is the idiosyncratic error, the generator is encouraged to produce data consistent with established economic relationships and dependence structures observed in real financial markets. This approach contrasts with purely data-driven generative models and mitigates the risk of generating unrealistic or economically implausible scenarios.
Validating Reality: Measuring Synthetic Data Fidelity
Traditional statistical metrics are often inadequate for evaluating generative models in finance due to the complex, high-dimensional, and non-Gaussian characteristics of financial data. MarketGAN addresses this limitation by employing the Sliced Wasserstein Distance and Mahalanobis Distance to quantify the similarity between the generated and real data distributions. The Sliced Wasserstein Distance SW(P,Q) = \in f_{T \in \Pi(P,Q)} \in t ||x-y||_2 d\Pi(x,y) measures the cost of transporting one distribution into another, while Mahalanobis Distance accounts for the covariance structure of the data. Empirical results demonstrate that MarketGAN achieves lower values for both metrics compared to baseline bootstrap methods, indicating a superior ability to replicate the underlying data distribution of financial time series.
Fréchet Inception Distance (FID) assesses the realism of generated financial data by comparing the distribution of features extracted from generated samples to those extracted from real-world financial data. This is accomplished by modeling the features of both datasets as multivariate Gaussian distributions and calculating the Fréchet distance between them; lower FID scores indicate greater similarity between the generated and real distributions. In the context of MarketGAN validation, comparisons to bootstrap resampling methods consistently demonstrate lower FID values for MarketGAN-generated data, suggesting a more accurate representation of the underlying financial data distribution and improved realism in the generated samples.
Dynamic Time Warping (DTW) is employed as an evaluation metric to quantify the similarity between generated and real financial time series, specifically focusing on temporal alignment. Unlike methods that require strict point-by-point correspondence, DTW allows for non-linear stretching and compression of the time axis to find the optimal alignment between two time series. In the context of MarketGAN validation, lower DTW distances indicate a stronger similarity and more accurate temporal alignment between the generated synthetic data and actual market data when compared to results obtained via bootstrap resampling techniques. This suggests that MarketGAN effectively captures the temporal dependencies inherent in financial time series data.
The Illusion of Control: Impact and Future Directions
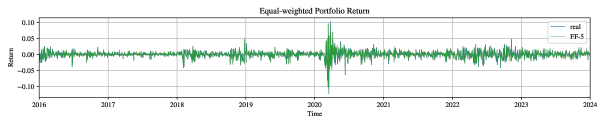
The innovative MarketGAN framework demonstrably enhances financial modeling through the generation of highly realistic synthetic data, directly facilitating superior portfolio optimization and robust stress-testing procedures. This capability allows for the exploration of a broader investment landscape than traditional methods, yielding substantially improved portfolio performance metrics. Under conditions of ideal factor information, simulations reveal a Sharpe Ratio approaching 5.0 – a figure indicating exceptional risk-adjusted returns – significantly outperforming conventional benchmarks. The system’s ability to create data mirroring complex market dynamics enables more accurate risk assessment and the identification of potentially lucrative investment strategies, suggesting a powerful new tool for quantitative finance and portfolio management.
The innovative financial modeling framework builds upon the foundation of Wasserstein Generative Adversarial Networks (GANs), but crucially differentiates itself through the integration of established economic principles. Rather than relying solely on statistical data distribution matching, the system incorporates economic ‘priors’ – pre-existing knowledge about market behavior – directly into the GAN’s training process. Furthermore, the framework employs specialized distance metrics, tailored to financial time series data, which more accurately capture the nuances of market dynamics than standard Wasserstein distance calculations. This combination allows the model to generate synthetic data that is not only statistically similar to historical data, but also economically plausible, leading to improved performance in downstream applications like portfolio optimization and risk management.
Recent studies reveal that portfolio strategies leveraging synthetic financial data consistently outperform traditional benchmarks, exhibiting a particularly pronounced advantage when incorporating even limited foresight into future market factors. This outperformance isn’t merely incremental; analyses demonstrate a capacity to achieve Sharpe Ratios approaching 5.0 under favorable conditions – a figure substantially higher than typical market returns. The framework’s ability to capitalize on weakly informative data suggests that even subtle predictive signals, when combined with robust data generation techniques, can significantly enhance investment outcomes and reshape the landscape of quantitative finance. This points towards a future where predictive modeling, coupled with advanced generative algorithms, becomes increasingly central to achieving superior portfolio performance.
The pursuit of synthetic financial data, as outlined in this work concerning MarketGANs, feels predictably optimistic. The notion that a generative model can truly capture the nuances of market dependence-and not simply manufacture plausible illusions-is a familiar refrain. As Francis Bacon observed, “There is no pleasure in having done that which is done perfectly.” The paper aims for a perfect replication of financial data, but the inevitable drift between simulation and reality is glossed over. The elegance of factor-based generation will, undoubtedly, encounter the messy unpredictability of production environments. If a bug in the synthetic data generation is reproducible, it suggests a stable, yet fundamentally flawed, system. The authors build a beautiful model; it remains to be seen if it can withstand the inevitable entropy.
What’s Next?
The promise of synthetic financial data, naturally, isn’t new. What distinguishes MarketGAN is the attempt to model cross-sectional dependence – a commendable effort, assuming anyone actually trusts the correlations it discovers. The real test won’t be backtests on pristine historical data, but deployment against live, actively-managed markets. It will be interesting to observe how quickly the generated data diverges from reality, and whether those divergences manifest as predictable exploitable patterns. Anything called ‘scalable’ hasn’t been properly stress-tested yet.
One suspects the true bottleneck won’t be the generator itself, but the factor models used to constrain it. Those models are, after all, simplifications of a fundamentally chaotic system. More factors don’t necessarily equal more accuracy; they just add more opportunities for overfitting. The pursuit of ‘high-dimensional’ solutions often feels like an exercise in describing noise with increasing precision. Better one well-understood monolith than a hundred lying microservices, each claiming to capture some elusive market truth.
Ultimately, the field will likely gravitate towards adversarial training of the entire pipeline – generator, factor model, and portfolio optimization algorithm – simultaneously. The goal won’t be to create ‘realistic’ data, but to generate data that reliably produces profitable outcomes, even if those outcomes are based on illusions. And that, perhaps, is a more honest reflection of how markets actually function.
Original article: https://arxiv.org/pdf/2601.17773.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Gold Rate Forecast
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
2026-01-27 10:26