Author: Denis Avetisyan
Researchers have developed a single autoregressive model capable of seamlessly generating text, images, and speech, moving beyond modality-specific architectures.
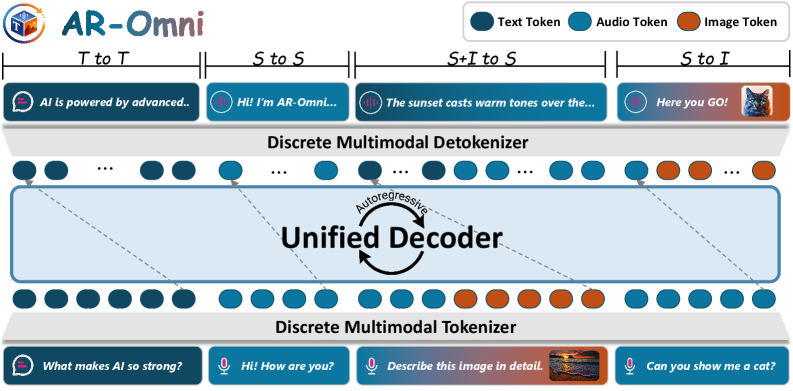
AR-Omni achieves competitive performance across multiple modalities using a unified architecture and discrete tokenization, enabling real-time streaming speech generation.
Existing multimodal large language models often rely on specialized components, hindering the simplicity and scalability of unified training and inference. This limitation motivates the development of truly unified architectures, as explored in ‘AR-Omni: A Unified Autoregressive Model for Any-to-Any Generation’, which introduces a novel autoregressive approach capable of generating text, images, and speech with a single Transformer decoder. By addressing challenges like modality imbalance and visual fidelity, AR-Omni achieves competitive performance across modalities, including real-time streaming speech generation. Could this unified approach represent a fundamental shift towards more versatile and efficient omnimodal AI systems?
The Emergence of True Multimodal Understanding
The evolution of Large Language Models (LLMs) has recently surged beyond textual data, giving rise to Multimodal Large Language Models capable of processing and integrating information from diverse sources. These advanced systems no longer solely rely on text; instead, they can interpret and synthesize data from images, audio, and video, opening up new frontiers in artificial intelligence. This expansion is achieved through innovative architectural designs and training methodologies that allow the models to learn relationships between different modalities – for example, connecting a textual description with a corresponding image. The result is a more comprehensive understanding of the world, enabling applications such as image captioning, visual question answering, and the creation of richer, more interactive AI experiences. These multimodal LLMs represent a significant step towards artificial general intelligence, as they move closer to mirroring the human ability to seamlessly integrate information from multiple senses.
Successfully merging different data types – text, images, and audio – into a single artificial intelligence system isn’t simply a matter of adding more data streams. The core difficulty lies in representation: how to translate each modality into a common mathematical language the AI can understand and process without losing crucial information. Furthermore, the computational demands of these multimodal models scale dramatically with each added modality and the size of the datasets required for training. This presents a significant hurdle; traditional model scaling techniques often prove insufficient, necessitating innovative architectural designs and training strategies to handle the increased complexity and prevent performance bottlenecks. Overcoming these challenges is crucial for unlocking the full potential of multimodal AI and creating systems that can truly understand and interact with the world in a human-like manner.
Initial forays into multimodal AI, such as the Chameleon model, showcased the potential of combining different input types – like text and images – but quickly revealed critical shortcomings. While capable of processing multiple modalities, these early systems struggled with truly unified understanding; they often treated each input stream separately rather than integrating them into a cohesive representation. This limitation hindered their ability to generate outputs that seamlessly blended information from diverse sources. Chameleon, for example, could describe an image or answer questions about it, but lacked the capacity to, say, create a story inspired by an image and narrated with contextual audio – a task demanding a deeper, more holistic processing capability. These early limitations underscored the need for novel architectures and training strategies to achieve genuine multimodal intelligence, where different modalities aren’t just combined, but truly understood in relation to one another.

A Unified Framework for Multimodal Generation
AR-Omni addresses the challenge of multimodal generation by implementing a unified autoregressive framework capable of handling any-to-any modality translation. This is achieved through a single model that generates sequences of discrete tokens representing input and output across all modalities-text, image, and audio-without requiring modality-specific architectures or separate decoding stages. The system leverages the principles of autoregressive modeling, where each generated token is conditioned on all previously generated tokens, to create a coherent and consistent output regardless of the input or output modality. This contrasts with previous approaches that typically required separate models or complex cross-attention mechanisms for each modality pairing, simplifying the generation pipeline and enabling a more generalized solution for multimodal tasks.
Discrete Tokenization within AR-Omni involves converting each input modality – text, image, and audio – into a sequence of discrete tokens using dedicated tokenizers. Text is tokenized using standard methods like Byte Pair Encoding (BPE). Images are processed by vector quantization (VQ) techniques, mapping image patches to visual tokens. Audio is similarly converted into a sequence of acoustic tokens through methods such as VQ-VAE. This process results in a unified representation where all modalities are expressed as a series of discrete tokens, facilitating a single autoregressive model to process and generate data across all modalities without requiring modality-specific transformations during inference.
Traditional multimodal generation often requires modality-specific decoders to translate latent representations into final outputs for each data type, increasing model complexity and computational cost. AR-Omni eliminates this requirement by processing all modalities as a unified sequence of discrete tokens; a single, shared autoregressive decoder then generates outputs directly from this sequence. This consolidation significantly streamlines the generation process, reducing the number of parameters and associated computational demands during both training and inference. The removal of separate decoders directly translates to lower memory requirements and faster generation speeds, making AR-Omni more efficient than architectures reliant on modality-specific output layers.
AR-Omni’s functionality is fundamentally built upon a joint vocabulary, a unified token space encompassing all input modalities – text, image, and audio. This vocabulary assigns a discrete token ID to each element across all modalities, allowing the model to process and generate data as a single sequence. The consistent token representation facilitates cross-modal interaction by enabling the model to directly relate elements from different modalities during both training and inference. Without a shared vocabulary, representing interdependencies between modalities would require complex mappings or separate embedding spaces, increasing model complexity and hindering effective cross-modal generalization.

Mitigating Modality Imbalance for Robust Performance
Modality imbalance is a significant obstacle in multimodal model training, arising from discrepancies in the information density and representation of different input types. Specifically, modalities with inherently larger token budgets – the number of discrete units used to represent the data – can disproportionately influence the learning process. This occurs because the model tends to prioritize optimizing for the modality contributing the most tokens, potentially leading to the underutilization or neglect of other modalities. Furthermore, variations in data representation – such as differing dynamic ranges or feature distributions – can exacerbate this imbalance, hindering the model’s ability to effectively integrate information from all input sources and achieve optimal performance across all modalities.
AR-Omni addresses modality imbalance through Weighted Normalized Token Prediction (NTP) and Task-Aware Reweighting. Weighted NTP adjusts the loss contribution of each modality during training based on its relative token count, preventing modalities with larger token budgets from dominating the learning process. Task-Aware Reweighting dynamically scales the loss for each modality based on the specific task being performed; for example, a modality crucial for speech recognition would receive a higher weighting during that task than during image generation. These techniques ensure that each modality contributes proportionally to the overall training objective, resulting in a more balanced and effective multimodal model.
AR-Omni employs discrete latent representations for both audio and image data through the use of dedicated codecs. Audio tokenization is achieved using SoundStream and EnCodec, which compress raw audio waveforms into a sequence of discrete tokens. Correspondingly, image tokenization utilizes VQ-VAE and VQGAN to convert image data into a discrete token space. This approach reduces the computational demands of processing continuous data and enables the model to operate on a unified sequence of tokens representing multiple modalities, facilitating multimodal integration and efficient processing.
The AR-Omni architecture incorporates a Perceptual Loss function during image generation to address inconsistencies in the visual token space. This loss function operates by comparing the generated image with the original image not in pixel space, but within a feature space extracted from a pre-trained visual perception model. By minimizing the difference in these high-level feature representations, the Perceptual Loss encourages the generation of images that are geometrically consistent and visually similar to the input, leading to improved image quality and reduced artifacts compared to pixel-wise loss functions. This approach prioritizes perceptual similarity, ensuring that the generated image aligns with human visual perception of structural and textural details.
AR-Omni demonstrates real-time performance for streaming speech applications, as quantified by a First Token Latency (FTL) of 146 milliseconds and a Real-Time Factor (RTF) of 0.88. The FTL represents the time elapsed until the first token is generated, crucial for responsive applications, while the RTF indicates the ratio of processing time to actual time, with a value below 1.0 signifying faster-than-real-time processing. These metrics were achieved during evaluation and indicate the model’s efficiency in handling streaming audio data and generating corresponding output with minimal delay.

Towards General Intelligence Through Adaptive Decoding and Scalable Architecture
AR-Omni distinguishes itself through a sophisticated decoding strategy centered on a Finite-State Decoding Machine. This system doesn’t rely on a single approach to generating outputs; instead, it dynamically adjusts between ‘greedy’ decoding – prioritizing the most probable tokens for fast, coherent results – and ‘sampling’ decoding, which introduces more randomness to boost diversity and creativity. The selection isn’t arbitrary, however, but is intelligently guided by the specific task at hand, allowing the model to prioritize speed and accuracy when needed, or explore a wider range of possibilities for more imaginative outputs. This adaptive capability represents a significant advancement, as it addresses the inherent trade-off between coherence and diversity that often plagues generative models, ultimately producing more nuanced and contextually appropriate results.
To address challenges in training large-scale multimodal models, AR-Omni incorporates Swin-Norm, a novel residual-post-normalization technique. Traditional normalization methods can become unstable as model size increases, hindering effective training and limiting scalability. Swin-Norm strategically applies normalization after each residual connection, promoting more stable gradient flow and allowing for significantly larger models to be trained successfully. This approach not only improves training stability but also facilitates the scaling of AR-Omni’s architecture, enabling the integration of more parameters and ultimately enhancing its capacity to process and generate complex multimodal content. The implementation of Swin-Norm proves crucial in unlocking the full potential of AR-Omni’s unified architecture and paving the way for more sophisticated AI systems.
AR-Omni represents a significant step toward artificial general intelligence through its unified approach to multimodal processing and generation. Unlike systems traditionally limited to single modalities – such as text or speech – this model seamlessly integrates various input and output types, allowing for a more holistic understanding and interaction with the world. This convergence isn’t simply about combining existing techniques; it establishes a foundational architecture where information flows naturally across modalities, enabling the system to, for instance, generate spoken responses to visual cues or create descriptive text from audio input. The implications extend beyond improved performance on individual tasks; it suggests the potential for systems that can truly reason across different forms of data, mirroring human cognitive abilities and opening doors to genuinely intelligent interactions across all communication channels.
Evaluations reveal AR-Omni achieves a noteworthy level of accuracy in speech processing tasks; specifically, the model attains a Word Error Rate (WER) of 6.5 when tested on the VCTK corpus for text-to-speech synthesis, indicating high-quality generated speech. Further demonstrating its robust capabilities, AR-Omni also exhibits strong performance in automatic speech recognition, reaching a WER of 9.4 on the LibriSpeech test-clean dataset. These results collectively underscore the model’s potential for reliable and accurate performance across a spectrum of speech-related applications, positioning it as a significant advancement in the field of multimodal AI.
The development of AR-Omni is poised to extend beyond current audio-visual capabilities, with future efforts directed towards video generation, building upon the successes of models like MIO. This expansion anticipates a unified framework for processing and generating content across all major modalities. Simultaneously, researchers are investigating more efficient tokenization strategies, aiming to reduce computational demands and accelerate both training and inference speeds. Optimizing tokenization isn’t simply about speed; it also promises to improve the model’s capacity to capture nuanced details and generate higher-quality, more coherent outputs, ultimately pushing the boundaries of multimodal AI systems.

The pursuit of a genuinely unified model, as demonstrated by AR-Omni, echoes a fundamental tenet of mathematical rigor. The architecture’s ability to handle diverse modalities-text, image, and speech-through a single autoregressive framework isn’t merely an engineering feat, but an exercise in elegant simplification. As Andrey Kolmogorov once stated, “The most important thing in mathematics is to pose the right question.” This paper doesn’t simply address the challenge of multimodal generation; it reframes the question itself, moving beyond modality-specific solutions toward a universal generative approach. The elimination of separate decoders, and the embrace of discrete tokenization, highlight a commitment to provable structure over empirical performance, a hallmark of truly robust algorithms.
What Lies Beyond?
The elegance of AR-Omni resides in its unification – a single architecture attempting to subsume disparate generative tasks. However, true generality demands more than merely handling multiple modalities. The current framework, while exhibiting competitive performance, remains fundamentally limited by the discrete tokenization scheme. Asymptotic complexity, particularly concerning the vocabulary size required to represent continuous data faithfully, presents a considerable, and potentially insurmountable, barrier to scaling. The model’s proficiency, therefore, is contingent upon an approximation – a pragmatic concession, yet one that introduces unavoidable information loss.
Future investigations must address the inherent limitations of discrete representations. Exploring alternatives – differentiable tokenization, or perhaps a return to explicitly continuous latent spaces – appears crucial. Furthermore, the observed streaming speech generation, while novel, begs the question of true temporal coherence. Does the model understand the sequential nature of speech, or merely mimic it through learned correlations? A rigorous analysis, grounded in information-theoretic principles, is necessary to determine the extent of genuine generative understanding.
Ultimately, the pursuit of a truly universal generative model is not merely an engineering problem, but a philosophical one. It compels a re-evaluation of what constitutes ‘understanding’ and ‘creation’ within the confines of algorithmic computation. The success of AR-Omni, therefore, should not be measured solely by benchmark scores, but by its capacity to reveal the fundamental limits of representation and inference.
Original article: https://arxiv.org/pdf/2601.17761.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Silver Rate Forecast
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
2026-01-27 07:05