Author: Denis Avetisyan
New research dissects the challenges facing conversational AI as it attempts to navigate complex, multi-step tasks requiring sustained reasoning.

A novel framework employing oracle interventions and procedural generation isolates skill bottlenecks in long-horizon planning, state tracking, and history management for large language model agents.
Despite advances in large language models, consistent performance on complex, multi-turn agentic tasks remains a significant challenge. This work, ‘LUMINA: Long-horizon Understanding for Multi-turn Interactive Agents’, introduces a novel counterfactual framework utilizing procedurally generated environments and ‘oracle’ interventions to dissect the relative importance of skills like planning and state tracking. Results demonstrate that while planning consistently improves performance, the efficacy of other skills is context-dependent, highlighting crucial bottlenecks in current LLM agent architectures. What targeted improvements to long-horizon understanding will be most effective in building truly robust and adaptable interactive agents?
The Illusion of Intelligence: Why LLMs Struggle to Plan
Despite their remarkable ability to generate human-quality text and perform various language-based tasks, Large Language Models often falter when confronted with challenges demanding extended, sequential reasoning. These models excel at identifying patterns and correlations within provided data, but struggle to reliably plan and execute a series of actions over a prolonged timeframe to achieve a specific goal. This isn’t a limitation of linguistic understanding per se, but rather a consequence of their underlying architecture, which prioritizes predicting the next token in a sequence rather than constructing a coherent, multi-step strategy. Consequently, tasks requiring anticipation of future consequences, adaptation to changing circumstances, or the maintenance of a consistent plan across numerous interactions prove particularly difficult, hindering their application in scenarios like complex game playing, robotic navigation, or long-term project management.
Successfully navigating intricate environments-whether a robotic system operating in a warehouse or an AI agent negotiating a complex deal-necessitates a capacity known as Long-Horizon Understanding. This isn’t simply about processing immediate information; it’s the ability to anticipate consequences far into the future, factoring in multiple sequential steps and potential outcomes. Standard Large Language Model architectures, while adept at pattern recognition and short-term prediction, often falter when faced with this extended reasoning demand. Their training typically prioritizes predicting the next token in a sequence, not necessarily the optimal series of actions required to achieve a distant goal. Consequently, these models can struggle with tasks demanding strategic foresight, exhibiting a limited ‘planning depth’ that restricts their effectiveness in real-world applications requiring sustained, multi-step interaction and adaptation.
The practical application of Large Language Model (LLM) Agents faces significant hurdles due to deficiencies in sustained, multi-turn interactions. While proficient at isolated tasks, these agents often struggle when a problem requires a sequence of coordinated actions over an extended period – envision a virtual assistant managing a complex travel itinerary or a robotic system navigating a dynamic warehouse. This isn’t simply a matter of scaling up existing models; the core issue lies in maintaining context, anticipating future needs, and adapting strategies as conditions evolve throughout a prolonged dialogue or operation. Consequently, the deployment of LLM Agents in real-world settings – from customer service and personalized education to autonomous robotics and scientific discovery – remains constrained until substantial progress is made in fostering more robust long-horizon reasoning capabilities.
A Patchwork of Intelligence: Augmenting LLMs with External Help
The Oracle Intervention framework is a counterfactual method used to determine the effect of specific capabilities on Large Language Model (LLM) agent performance. This approach operates by providing the agent with perfect or near-perfect information – the ‘oracle’ – at critical junctures during task execution, such as providing accurate state information or an optimal task plan. By comparing the agent’s performance with the oracle intervention to its performance without it, researchers can isolate and quantify the impact of the missing skill, effectively establishing a causal link between the skill and the agent’s overall success rate. This allows for a rigorous evaluation of the benefits of incorporating new skills or improvements into the agent’s architecture.
LLM Agents are augmented with external information during execution to improve performance on complex tasks. This is achieved by providing data at critical decision points, specifically focusing on two key areas: state tracking and task planning. Accurate state tracking ensures the agent maintains a correct understanding of the environment and task progress, while interventions focused on planning offer guidance on optimal action sequences. These interventions are not continuous; rather, they are delivered at specific moments where the agent would typically formulate its next step, providing targeted support without fully automating the process.
Targeted support for LLM Agents is provided through specific interventions, including the ‘State Tracking Intervention’ which supplies the agent with accurate, up-to-date information regarding the environment and task progress. The ‘Planning Intervention’ offers assistance in task decomposition and step-by-step execution, improving the agent’s ability to formulate effective strategies. Finally, the ‘History Pruning Intervention’ selectively removes irrelevant or outdated information from the agent’s context window, mitigating performance degradation caused by excessive or noisy input and allowing the agent to focus on pertinent details.
Testing the Limits: Evaluating Performance Across Complex Worlds
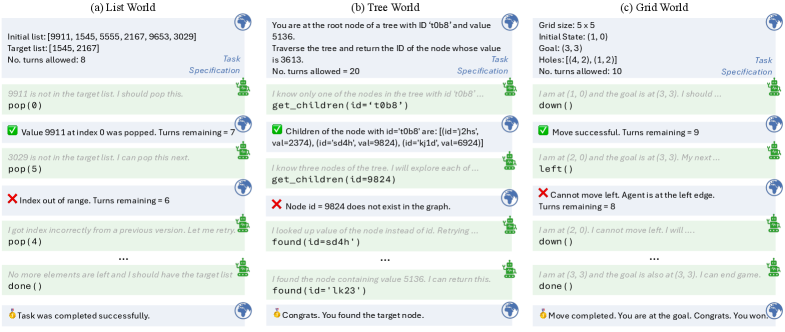
Evaluation of the implemented interventions occurs across three distinct procedural environments: ‘ListWorld’, ‘TreeWorld’, and ‘GridWorld’. ‘ListWorld’ presents tasks involving manipulation and reasoning about lists of items, requiring sequential processing and memory. ‘TreeWorld’ necessitates navigating and reasoning within hierarchical tree structures, testing the agent’s ability to understand relationships and make decisions based on nested information. Finally, ‘GridWorld’ simulates a 2D environment where agents must navigate a grid, locate objects, and perform actions, assessing spatial reasoning and planning capabilities. These environments are designed to present varying levels of complexity and demand different cognitive skills from the LLM agents, allowing for a comprehensive assessment of their performance.
Testing employed Large Language Model (LLM) agents built upon the Qwen3 architecture. To facilitate processing of the complex procedural environments, these agents utilized YaRN (Yet another Retrieval method) Encoding. This encoding technique allows the LLM to access and incorporate a significantly larger context window than traditional methods, enabling more informed decision-making throughout each task within the ‘ListWorld’, ‘TreeWorld’, and ‘GridWorld’ environments. The implementation of YaRN Encoding was critical for managing the extended state required to navigate and successfully complete tasks in these environments.
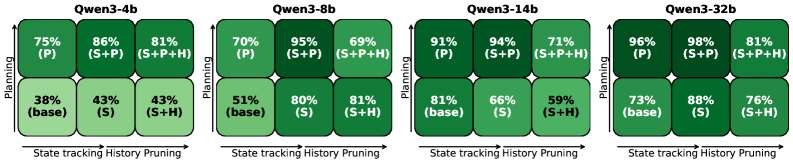
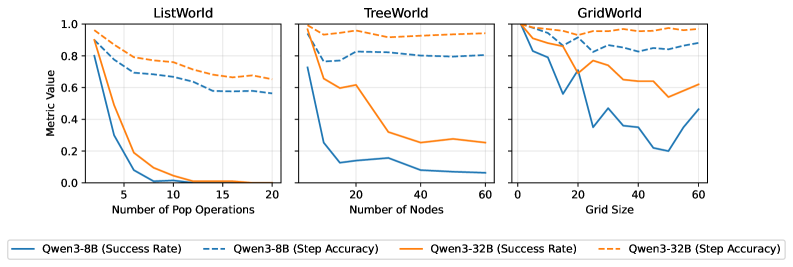
Performance evaluation utilized both Step Accuracy and Success Rate as quantifiable metrics. Step Accuracy measures the correctness of individual action selections, and was generally observed to be high across all tests. However, Success Rate, representing the proportion of completed tasks, demonstrated considerable variation based on the complexity of the environment (‘ListWorld’, ‘TreeWorld’, ‘GridWorld’) and the size of the LLM agent (‘Qwen3’). The disparity between consistently high Step Accuracy and fluctuating Success Rate indicates that while agents frequently make correct initial choices, errors compound over extended sequences of actions, ultimately impacting task completion.
The Illusion of Progress: What These Findings Tell Us About AI
Recent research indicates that limitations in the inherent reasoning capabilities of large language model (LLM) agents are not necessarily fixed constraints. Through strategically designed interventions, these agents can demonstrably overcome obstacles in complex problem-solving. These interventions focus on augmenting the agent’s core processes, enabling them to perform better in tasks requiring logical deduction, planning, and sequential decision-making. The findings suggest that rather than relying solely on scaling model size, a targeted approach to skill enhancement – addressing specific reasoning deficits – can yield substantial improvements in agent performance and reliability. This offers a pathway toward creating AI systems that are not just powerful, but also demonstrably capable of consistent, accurate reasoning, even when faced with ambiguous or incomplete information.
The integration of ReAct prompting with targeted interventions significantly enhances an AI agent’s ability to navigate complex tasks. This technique encourages the agent to not only generate reasoned thoughts – the ‘React’ component – but also to actively take actions within its environment, and observe the consequences to refine its approach. By interleaving reasoning and action, the agent overcomes limitations in planning and execution that often plague large language models. The study demonstrates that ReAct prompting doesn’t simply mask deficiencies, but actively amplifies the benefits of specific interventions designed to improve the agent’s core skills, leading to more adaptable and capable AI systems. This synergistic effect proves crucial in scenarios demanding sustained sequential decision-making, allowing the agent to effectively learn from its interactions and improve performance over time.
Research indicates that simply applying standardized improvements to large language model (LLM) agents isn’t universally effective; the impact of interventions is demonstrably size-dependent. For instance, techniques like history pruning – removing past interactions to focus current reasoning – proved beneficial for smaller models struggling with computational load, yet actively degraded performance in larger models already capable of managing extensive context. This suggests that skill enhancement for LLM agents requires a nuanced, targeted approach, tailoring interventions to the specific capabilities and limitations of each model size. Such precision is critical for developing robust AI agents capable of sustained planning and sequential decision-making, moving beyond simple task completion to address complex, real-world challenges that demand reliable and adaptable performance.
The pursuit of truly long-horizon agents, as demonstrated by LUMINA’s dissection of skill bottlenecks, feels predictably Sisyphean. This paper meticulously isolates planning, state tracking, and history pruning – noble efforts, certainly – but one suspects production environments will inevitably uncover failure modes the researchers hadn’t foreseen. It echoes a familiar pattern: elegant frameworks built on assumptions that crumble under real-world complexity. As Paul Erdős famously observed, “A mathematician knows a lot of things, but he doesn’t know everything.” This rings true here; the researchers illuminate crucial aspects of LLM agent performance, yet the endless frontier of unforeseen edge cases remains. Everything new is old again, just renamed and still broken.
What’s Next?
The elegantly isolated skill bottlenecks-planning, state tracking, history pruning-feel…familiar. It recalls the days when a simple bash script handled everything, and suddenly ‘scaling’ meant introducing layers of abstraction prone to cascading failure. The procedural generation is a clever diagnostic, certainly, but one suspects that real-world environments will exhibit emergent complexities that render these neatly categorized issues…messier. They’ll call it ‘distribution shift’ and request more funding.
The reliance on ‘oracle interventions’ is a particularly telling artifact. It’s a research crutch, a way to bypass the genuine difficulty of building agents that can self-correct in long-horizon tasks. Eventually, someone will attempt to automate the oracle, creating a meta-oracle, and then another, ad infinitum. The pursuit of perfect information, packaged as ‘long-term memory,’ seems destined to repeat the mistakes of every knowledge-representation system before it.
One anticipates a future filled with increasingly sophisticated methods for measuring what agents fail at, while the fundamental problem – building systems robust enough to survive contact with reality – remains stubbornly intractable. Tech debt is, after all, just emotional debt with commits. The documentation will, predictably, lie again.
Original article: https://arxiv.org/pdf/2601.16649.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
2026-01-27 01:59