Author: Denis Avetisyan
Researchers demonstrate a new method for launching highly effective backdoor attacks on graph classification models by subtly manipulating underlying graph structures.
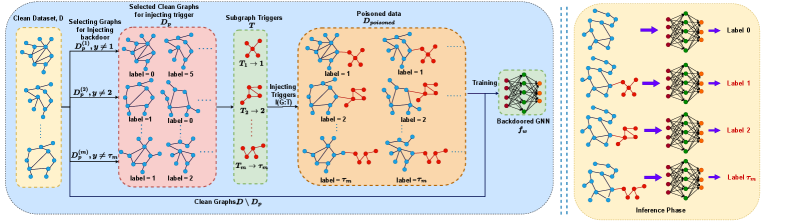
This paper introduces a multi-target graph backdoor attack via subgraph trigger injection, achieving high success rates while maintaining clean accuracy and bypassing existing certified defenses.
Despite the proven efficacy of graph neural networks (GNNs) across diverse applications, their vulnerability to adversarial manipulation remains a critical concern. This paper introduces ‘Multi-Targeted Graph Backdoor Attack’, a novel attack strategy for graph classification that simultaneously redirects predictions to multiple target labels via subtle graph poisoning. By employing a subgraph injection technique-which preserves graph structure unlike prior work-we demonstrate high attack success rates with minimal impact on clean accuracy and robust performance against state-of-the-art defenses. Given these findings, how can we develop more resilient GNN architectures and robust defense mechanisms to mitigate the threat of sophisticated, multi-targeted backdoor attacks?
Unmasking the Ghost in the Machine: Backdoor Attacks on Graph Networks
Graph Neural Networks (GNNs) have rapidly become indispensable tools across diverse fields, from social network analysis and drug discovery to recommendation systems and fraud detection. This proliferation, however, coincides with growing concerns regarding their susceptibility to adversarial manipulation. Unlike traditional machine learning models, GNNs operate on complex graph structures, creating unique vulnerabilities that subtle attacks can exploit. These attacks don’t necessarily aim to degrade overall performance; instead, they often focus on introducing targeted misclassifications triggered by specific, carefully crafted patterns within the graph data. The inherent complexity of these graph structures, combined with the increasing reliance on potentially untrusted data sources, makes GNNs a particularly attractive target for malicious actors seeking to compromise the integrity of data-driven applications.
Backdoor attacks represent a particularly insidious threat to graph neural networks, functioning by subtly poisoning the training data with carefully designed triggers. These triggers, which can take the form of specific node features, edge connections, or even entire subgraphs, remain largely undetectable during standard evaluation. The manipulation doesn’t alter the model’s overall performance on clean data, masking the attack’s presence; however, when a test sample containing the trigger is presented, the model consistently misclassifies it according to the attacker’s intent. This targeted misclassification allows for precise control over the model’s output in specific scenarios, potentially leading to significant consequences depending on the application – from manipulating social network recommendations to compromising critical infrastructure managed by graph-based systems. The stealth and precision of these attacks make them exceptionally challenging to defend against, demanding novel approaches to data sanitization and model robustness.
The potential for targeted misclassification represents a significant threat to the dependability of graph neural networks. Backdoor attacks, successful with alarming frequency, don’t simply cause random errors; instead, they enable adversaries to subtly manipulate predictions when a specific, pre-defined trigger is present in the input data. This means a correctly trained model, vital for applications like fraud detection or medical diagnosis, can be consistently fooled into making incorrect classifications under controlled circumstances. The high success rates demonstrated in recent studies highlight that even a small amount of poisoned training data can compromise the entire system, making it crucial to develop robust defenses against these insidious attacks and ensure the continued reliability of graph-based machine learning.
Architecting Deception: Methods of Trigger Insertion
Sub-graph injection and replacement are adversarial techniques used to introduce malicious triggers into graph neural network (GNN) training data. Sub-graph injection involves adding a specifically crafted, small graph structure to the existing training graph, while sub-graph replacement identifies and replaces an existing sub-graph with a malicious counterpart. Both methods aim to subtly modify the graph’s connectivity without causing noticeable performance degradation during standard training, effectively embedding a hidden vulnerability that can be exploited during inference to induce desired misclassifications or incorrect predictions. The effectiveness of these attacks relies on the trigger’s ability to remain undetected by the GNN while still influencing its output when presented with manipulated input during testing.
The effectiveness of graph-based attacks is directly correlated to characteristics of the inserted trigger. The trigger, representing the malicious subgraph, functions as the activation key for the attack, and its composition-specifically, the number and arrangement of edges within it-defines the ‘Trigger Edge Density’. Higher edge density can increase the stealth of the trigger, making it more difficult to detect during analysis, while also potentially improving the attack’s success rate by creating a more robust activation pattern. Conversely, a trigger with low edge density may be more easily identified but requires fewer modifications to the original graph structure. The optimal edge density is therefore a trade-off determined by the specific graph architecture and the attacker’s objectives; analysis of both trigger composition and density is crucial for assessing and mitigating the risk of such attacks.
Subtle alterations to a graph’s structure during the training of a graph neural network (GNN) can introduce a hidden vulnerability known as a backdoor trigger. These modifications, implemented via techniques like subgraph injection or replacement, do not overtly change the intended functionality of the model on benign data. Instead, they create a specific, often small, pattern – the trigger – within the graph. When this trigger is present in a test instance, the model will consistently misclassify the input according to the attacker’s desired outcome, despite the input potentially containing features that would normally lead to correct classification. The success of this attack relies on the model learning to associate the trigger pattern with the attacker’s target label during training, effectively creating a conditional vulnerability dependent on the presence of that specific subgraph structure.
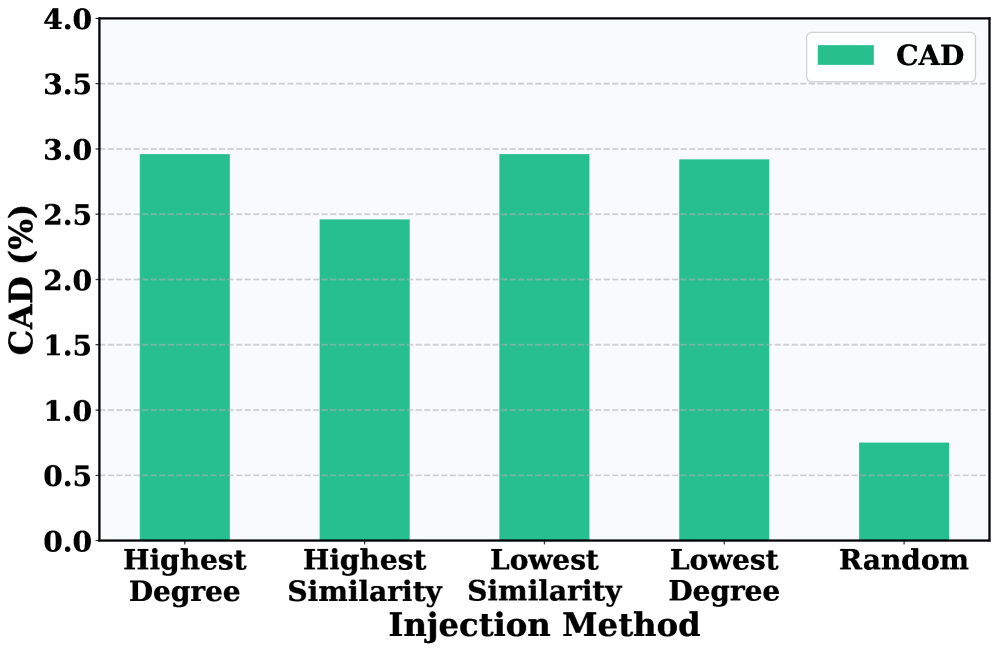
Quantifying the Breach: Impact on Model Performance
Clean accuracy, representing a model’s performance on unaltered, benign data, serves as a fundamental performance metric but is insufficient for detecting backdoor attacks. A model can achieve high clean accuracy – correctly classifying the vast majority of untainted inputs – while simultaneously harboring a hidden vulnerability triggered by specific, attacker-defined inputs containing a predetermined trigger. This is because backdoor attacks do not typically aim to degrade overall performance on legitimate data; instead, they focus on subtly altering the model’s decision boundary to misclassify inputs containing the trigger, effectively remaining undetected during standard accuracy evaluations which only assess performance on clean data samples.
Backdoor attacks, also known as Trojan attacks, are characterized by their ability to achieve a high ‘Attack Success Rate’ – the percentage of times the attacker’s trigger causes misclassification – without significantly impacting a model’s performance on standard, untainted datasets. This is accomplished by subtly modifying training data to associate a specific, rarely occurring trigger with a target misclassification. Because the model retains its accuracy on legitimate inputs, the attack remains stealthy, evading detection by conventional accuracy metrics. The attacker can therefore control the model’s behavior only when the pre-defined trigger is present in an input, while the model functions normally otherwise. This duality – high attack success rate coupled with normal clean accuracy – is a defining characteristic of this attack vector.
The poisoning ratio, defined as the percentage of training data instances modified to contain the backdoor trigger, is a critical parameter in data poisoning attacks. A higher poisoning ratio generally increases the attack success rate, as more instances reinforce the association between the trigger and the target label. However, this increased effectiveness comes at the cost of reduced stealth; a larger proportion of manipulated data is more likely to be detected through statistical analysis or data validation techniques. Conversely, a lower poisoning ratio enhances stealth, making the attack more difficult to identify, but may simultaneously reduce the attack success rate, as fewer instances learn the malicious association. The optimal poisoning ratio represents a trade-off between maintaining a high attack success rate and minimizing the risk of detection, and is influenced by factors such as the size of the training dataset and the characteristics of the target model.
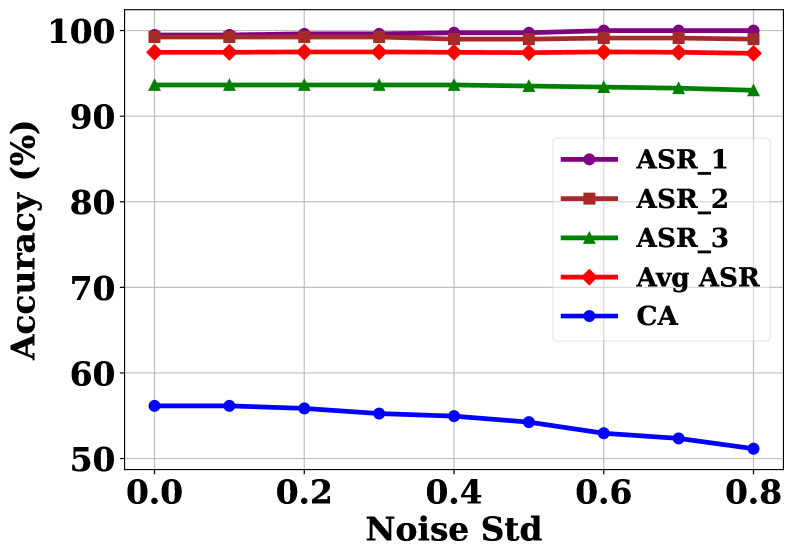
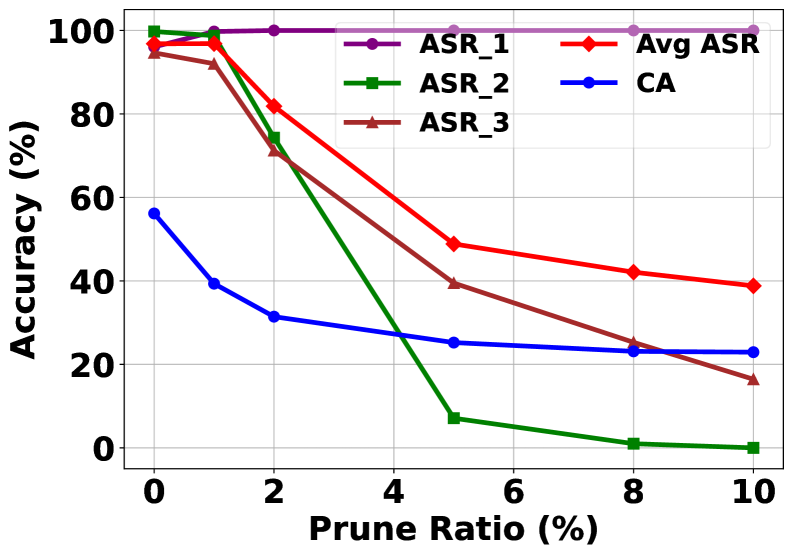
Fortifying the Network: Defense and Mitigation Strategies
Fine-Pruning represents a defense strategy against backdoor attacks by selectively removing neurons suspected of being compromised or manipulated by the attacker. This technique operates on the premise that backdoors manifest as specific, aberrant patterns of activation within the neural network; by identifying and excising these potentially malicious neurons, the network’s reliance on the implanted trigger is diminished. The effectiveness of Fine-Pruning lies in its ability to reduce the network’s capacity for exhibiting the backdoor behavior without significantly impacting performance on legitimate data. However, as demonstrated in recent studies, even substantial pruning – reducing clean accuracy – does not guarantee complete protection; sophisticated attacks can still maintain a considerable success rate by distributing the backdoor functionality across a larger number of remaining neurons, effectively circumventing the pruning efforts.
Randomized smoothing represents a defense strategy designed to enhance the robustness of neural networks against adversarial attacks by intentionally introducing noise into the input data. This technique operates on the principle that by adding carefully calibrated random perturbations, the decision boundary of the network becomes smoother and less sensitive to subtle, maliciously crafted inputs-often referred to as triggers in backdoor attacks. Essentially, the noise disrupts the precise patterns that a backdoor trigger relies on to activate, effectively masking its influence and preventing successful manipulation of the network’s output. While not a perfect solution, randomized smoothing aims to increase the difficulty for attackers by making it harder to consistently exploit vulnerabilities, even when the underlying network remains susceptible to compromise.
A newly developed multi-target backdoor attack exhibits remarkably high success rates – exceeding 99% on benchmark datasets including MNIST, CIFAR-10, and ENZYMES. This attack distinguishes itself through its ability to compromise neural networks while maintaining near-perfect performance on legitimate, untainted data; clean accuracy degradation remains exceptionally low, below 1.07%. The effectiveness of this technique stems from its sophisticated method of embedding triggers, allowing for consistent manipulation of the network’s output across multiple targeted classifications. This presents a significant challenge to the robustness of machine learning systems, demonstrating a high potential for subtle and pervasive compromise even in seemingly well-functioning models.
Even when subjected to common neural network defenses, this newly developed attack demonstrates remarkable resilience. Testing against Randomized Smoothing, a technique designed to disrupt malicious inputs by adding noise, the attack maintains over 90% success, even with a substantial noise standard deviation of 0.8. Similarly, when confronted with Fine-Pruning, a method that attempts to eliminate compromised neurons, the attack still achieves over 80% success, even after the pruning process reduces the overall clean accuracy of the network to approximately 38%. This persistence highlights a significant vulnerability, suggesting that current defense mechanisms, while helpful, are insufficient to fully mitigate the threat posed by sophisticated backdoor attacks.
Beyond Current Defenses: Future Directions
A significant body of adversarial research demonstrates the vulnerability of standard Graph Convolutional Networks (GCNs) to carefully crafted attacks. These attacks often exploit the inherent spectral properties of the graph and the linear transformations within GCN layers, allowing malicious actors to subtly manipulate node features or graph structure. Investigations reveal that even small perturbations, strategically applied, can lead to significant misclassifications or targeted manipulation of the network’s output. The prevalence of attacks targeting GCNs stems from their widespread adoption as a foundational architecture in graph machine learning, making them a prime target for adversaries seeking to compromise the integrity of graph-based systems – from social networks and recommendation engines to critical infrastructure and financial modeling. Consequently, understanding and mitigating these vulnerabilities in standard GCNs is crucial for building robust and trustworthy graph neural networks.
The evolving landscape of graph neural network vulnerabilities extends beyond simple adversarial perturbations to encompass more sophisticated attack strategies, notably multi-target backdoor attacks. These attacks represent a significant escalation in the threat model, as they do not merely seek to misclassify individual nodes or edges, but rather to subtly manipulate the network’s output across a range of targeted instances. Unlike traditional backdoors triggered by a single, specific input, multi-target attacks can activate malicious behavior based on combinations of features or contextual cues, making detection considerably more challenging. This necessitates a shift in defensive strategies; current methods, often designed to identify singular triggers, prove inadequate against such nuanced and coordinated threats. The ability to embed multiple, context-dependent backdoors highlights a critical need for defenses that analyze the network’s overall behavior and identify anomalous patterns indicative of coordinated manipulation, rather than focusing solely on isolated instances of adversarial input.
The pursuit of robust graph neural network defenses necessitates a shift toward generalized solutions. Current protective measures are often brittle, failing when confronted with novel attack strategies or variations in graph topology. Future investigations should prioritize the development of defenses that transcend specific attack signatures and demonstrate resilience across diverse graph structures – from social networks to molecular compounds. Crucially, these defenses cannot be limited to a single GNN architecture; instead, they must be adaptable and effective when applied to a broader range of models, ensuring comprehensive protection as the field of graph machine learning continues to evolve and diversify. This focus on generalization will be paramount in building truly secure and reliable graph-based systems.
The research presented delves into the vulnerabilities of graph neural networks, exposing how seemingly robust systems can be subtly manipulated through targeted attacks. This pursuit of systemic weakness echoes a fundamental tenet of understanding: one truly grasps a system not by confirming its expected behavior, but by actively seeking its breaking points. As Edsger W. Dijkstra stated, “It’s not enough to show something works. You must prove why it can’t fail.” The multi-target backdoor attack detailed here doesn’t merely demonstrate a successful breach; it reveals the underlying mechanisms that allow for such manipulation, even against certified defenses. This systematic probing of limits, this intentional attempt to induce failure, is the very essence of genuine comprehension, moving beyond superficial functionality to reveal the core principles governing the system’s behavior.
What Lies Beyond?
The demonstrated capacity to induce targeted misclassification via subtle structural perturbations reminds that apparent order is often a precarious arrangement. This work establishes not simply a vulnerability, but a principle: graph neural networks, despite their promise, remain susceptible to manipulation rooted in the very connectivity they seek to understand. The multi-target aspect, while effective, feels less like a culmination and more like a broadening of the attack surface, hinting at the possibility of crafting attacks that induce complex, cascading errors – a systemic dismantling of trust rather than isolated incidents.
Future inquiry should not focus solely on fortifying defenses against known triggers. Such approaches treat symptoms, not the disease. A more fruitful, though unsettling, path lies in exploring the inherent ambiguity within graph classification itself. What constitutes ‘correct’ classification when the underlying graph structure is noisy, incomplete, or deliberately misleading? Perhaps the goal isn’t to eliminate all vulnerability, but to quantify and manage it, accepting that perfect security is an illusion-a comforting narrative we tell ourselves while poking at the foundations of complex systems.
The resilience shown against certified defenses is particularly noteworthy. It suggests that current formal verification methods, while valuable, may be predicated on overly simplistic models of adversarial behavior. True robustness will likely require a shift toward understanding the limits of certification-identifying the types of attacks that are, in principle, undetectable, and designing systems that gracefully degrade rather than catastrophically fail in their presence.
Original article: https://arxiv.org/pdf/2601.15474.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Silver Rate Forecast
2026-01-26 04:06