Author: Denis Avetisyan
Researchers are leveraging diffusion models to create realistic, privacy-preserving synthetic datasets for remote sensing applications, offering a powerful alternative to costly and sensitive real-world data.
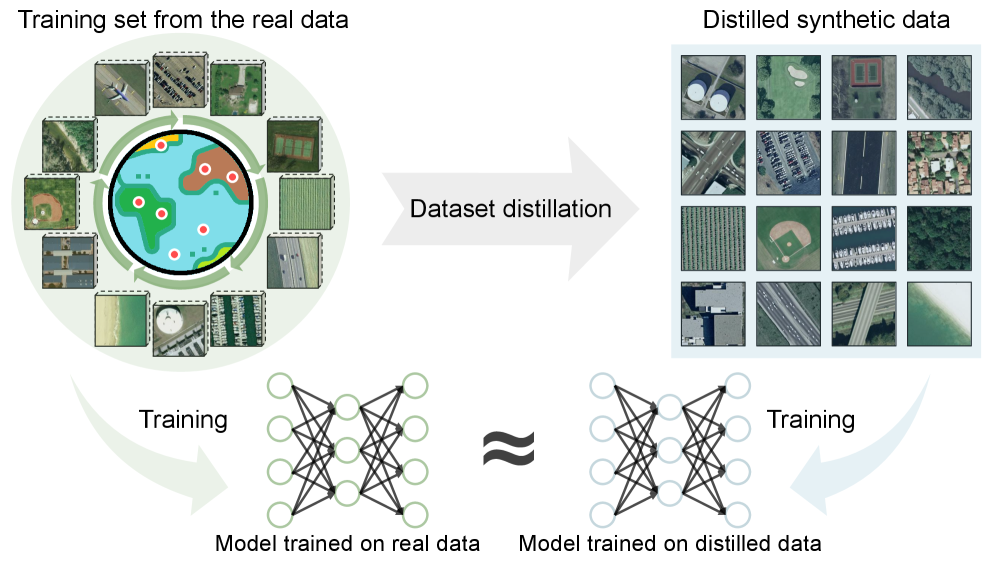
A novel dataset distillation method utilizes discriminative prototype-guided diffusion to maintain performance while addressing data privacy and computational limitations in remote sensing.
While deep learning has dramatically advanced remote sensing image interpretation, reliance on large datasets introduces challenges related to storage, computational cost, and data privacy. This paper, ‘Towards Realistic Remote Sensing Dataset Distillation with Discriminative Prototype-guided Diffusion’, addresses these issues by pioneering dataset distillation techniques for remote sensing, creating compact synthetic datasets via a novel diffusion model. The proposed method leverages classifier-driven guidance and latent space clustering with representative prototypes to generate realistic and diverse samples that maintain performance for downstream tasks. Could this approach unlock more efficient and privacy-preserving workflows for a wider range of remote sensing applications?
Unveiling the Data Bottleneck: Challenges in the Pursuit of Accuracy
The pursuit of increasingly accurate Deep Learning models is fundamentally tied to the availability of extensive datasets, a trend that presents significant challenges beyond simply gathering more information. As model complexity grows, so does the demand for data – often requiring datasets containing millions, or even billions, of labeled examples to achieve robust performance. This escalating need introduces logistical hurdles in data collection, storage, and annotation, alongside growing privacy concerns regarding sensitive user information. The more data involved, the greater the risk of accidental exposure or misuse, necessitating sophisticated anonymization techniques and robust data governance protocols. Ultimately, the drive for larger datasets is reshaping the landscape of machine learning, forcing researchers and practitioners to confront not only technical challenges, but also critical ethical and societal implications.
The proliferation of large-scale datasets, while crucial for training advanced machine learning models, introduces significant challenges beyond mere storage. Data leakage, where sensitive information is inadvertently exposed, becomes a heightened risk as dataset size increases, demanding sophisticated anonymization and security protocols. Simultaneously, the computational overhead associated with processing these datasets is substantial; training even moderately complex models can require immense processing power and time, necessitating distributed computing frameworks and specialized hardware. This combination of security vulnerabilities and computational demands creates a bottleneck, potentially limiting access to large-scale learning for researchers and organizations lacking the necessary resources, and demanding innovative approaches to data handling and model training to mitigate these risks.
The escalating cost of data acquisition and sustained maintenance presents a significant impediment to advancements across numerous fields reliant on deep learning. Traditional methods of dataset creation – involving manual labeling, extensive data collection campaigns, and substantial storage infrastructure – are proving increasingly unsustainable, particularly for research groups lacking extensive funding or access to large-scale computing resources. This financial barrier effectively limits participation, concentrates power within organizations capable of bearing the expense, and slows the pace of innovation in areas like medical imaging, natural language processing, and materials science. The inability to readily access and curate sufficiently large, high-quality datasets creates a bottleneck, hindering the development of more accurate, robust, and generalizable artificial intelligence systems and ultimately impacting the potential for widespread beneficial applications.
Synthetic Data: A Paradigm Shift in Data Acquisition
Synthetic data presents a viable alternative to traditionally sourced real-world data by addressing key limitations related to data privacy and acquisition expense. Utilizing computer-generated datasets allows organizations to bypass many regulations concerning personally identifiable information (PII), thereby reducing legal risks and compliance costs. Furthermore, the creation of synthetic datasets circumvents the often substantial expenses associated with data collection, labeling, and storage, particularly in specialized domains where data is scarce or requires significant effort to obtain. This is achieved through algorithmic generation, enabling the production of large, labeled datasets tailored to specific model training requirements without requiring access to sensitive real-world information or incurring associated costs.
Diffusion Models, Generative Adversarial Networks (GANs), and Auto-Regressive Models represent the current state-of-the-art in synthetic data generation. Diffusion Models function by progressively adding noise to data and then learning to reverse this process, generating new samples. GANs utilize a two-network system – a generator and a discriminator – that compete to create increasingly realistic synthetic data. Auto-Regressive Models, conversely, predict each data point sequentially based on preceding values. Each approach offers unique strengths; Diffusion Models excel in image quality, GANs in generating diverse samples, and Auto-Regressive Models in sequential data like text or time series. Recent advancements focus on improving training stability, reducing computational costs, and enhancing the fidelity of generated data across various modalities.
Text-to-image generation leverages diffusion models and similar techniques to produce visual datasets directly from textual descriptions, enabling the creation of highly targeted datasets for specific applications. This approach bypasses the need for real-world image acquisition and labeling, significantly reducing costs and time to market. By varying the input text prompts, developers can control attributes like object pose, lighting conditions, and background environments, generating images tailored to specific training requirements for computer vision models. The technique is particularly useful for rare or sensitive scenarios where obtaining real-world data is impractical or prohibited, such as generating images of medical anomalies or specific industrial defects. Furthermore, programmatic control over dataset characteristics allows for the systematic creation of datasets for evaluating model robustness and bias.

Dataset Distillation: Condensing Knowledge for Efficiency
Dataset distillation is a technique focused on reducing the size of training datasets while preserving model performance. This is achieved by generating a smaller, synthetic dataset that encapsulates the essential information present in the original, larger dataset. The goal is not simply random subsampling, but the creation of new data points designed to maximize information density and maintain, or even improve, the accuracy and generalization capabilities of machine learning models trained on the distilled dataset. This approach addresses the practical limitations of large datasets, such as storage requirements, computational cost, and data privacy concerns, without significantly compromising model effectiveness.
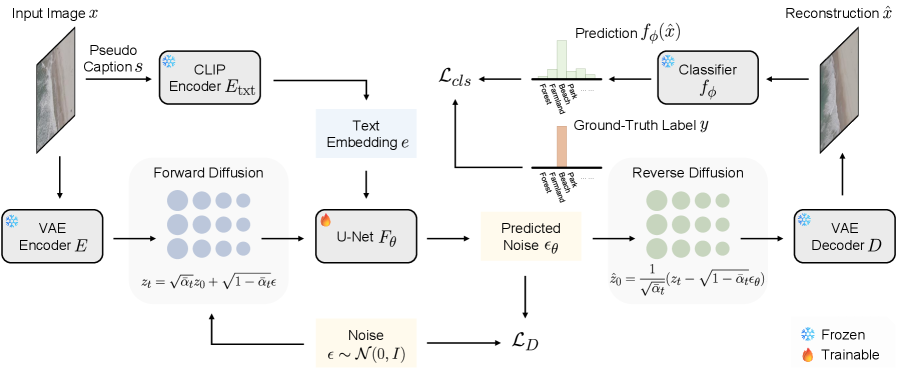
Discriminative Prototype-Guided Diffusion improves distilled dataset quality by integrating visual prototypes and classifier guidance into the diffusion process. Visual prototypes, representative samples from the original dataset, act as anchors during synthetic data generation, ensuring the distilled set maintains crucial data characteristics. Classifier guidance, utilizing a pre-trained classifier, steers the diffusion model towards generating samples that are correctly classified, thereby preserving the discriminatory power of the original data. This combined approach focuses the diffusion process on generating high-quality, representative samples that closely mirror the original dataset’s distribution and maintain predictive performance, resulting in a distilled dataset with improved fidelity and utility.
The efficacy of dataset distillation techniques is fundamentally dependent on the ability to learn and operate within a Latent Space, achieved through the integration of Vision Language Models (VLMs) and Variational Autoencoders (VAEs). VAEs compress high-dimensional image data into a lower-dimensional latent representation, facilitating efficient manipulation and generation. VLMs provide the semantic understanding necessary to guide this process, ensuring that the distilled dataset retains crucial information for downstream tasks. By learning meaningful representations in this Latent Space, the system can generate synthetic samples that closely approximate the distribution of the original, larger dataset, while significantly reducing its size. This combination allows for targeted data generation, focusing on samples that maximize performance on specific tasks, and minimizes redundancy within the distilled dataset.
U-Net and CLIP architectures are integral to the diffusion process used in dataset distillation for generating synthetic samples. The U-Net, functioning as a denoising autoencoder, iteratively refines noisy latent representations towards realistic data samples. CLIP (Contrastive Language-Image Pre-training) provides crucial guidance by evaluating the semantic similarity between generated samples and the original dataset, ensuring fidelity to the target distribution. Specifically, CLIP embeddings are used as conditioning inputs to the U-Net, steering the diffusion process to produce samples aligned with the semantic characteristics of the original data. This combination allows for the creation of high-fidelity synthetic images that effectively mimic the diversity and quality of the full dataset, crucial for maintaining performance after distillation.

Impact and Applications: A New Era of Data Efficiency
Recent advancements have successfully demonstrated the feasibility of distilling large remote sensing datasets – including the UC Merced Dataset, AID Dataset, and the expansive NWPU-RESISC45 Dataset – into significantly smaller, yet highly effective, training sets. This distillation process doesn’t simply reduce data volume; it strategically selects and refines data points to retain crucial information for accurate model training. The resulting compact datasets enable the development of remote sensing models that require substantially less computational resources and storage, opening doors for deployment on edge devices and in environments where access to massive datasets is limited. By achieving comparable overall accuracy to models trained on the full datasets, this approach proves that data efficiency need not come at the cost of performance, representing a significant step towards more accessible and scalable remote sensing applications.
The reduction in data requirements facilitated by this approach extends the reach of complex machine learning models to environments previously considered inaccessible. Resource-constrained settings – such as edge devices, mobile platforms, or locations with limited bandwidth – often lack the computational power or storage capacity for traditional, data-intensive models. By distilling large datasets into compact training sets without significant performance loss, this method enables the deployment of accurate remote sensing applications on these platforms. This advancement has broad implications for real-time monitoring, precision agriculture in remote areas, and disaster response where immediate, on-site analysis is crucial, fostering wider accessibility and impact for advanced data analysis tools.
The synergistic pairing of dataset distillation and synthetic data generation represents a pivotal advancement with the potential to significantly accelerate progress across diverse scientific and technological fields. By intelligently reducing the size of training datasets while simultaneously augmenting them with artificially created examples, this approach overcomes limitations imposed by data scarcity and cost. This unlocks opportunities for researchers and developers operating in resource-constrained environments, or those tackling problems where large, labeled datasets are simply unavailable. The resulting models, trained on these compact yet informative datasets, promise to democratize access to advanced technologies, fostering innovation in areas like precision agriculture, environmental monitoring, and disaster response, and ultimately broadening the impact of machine learning on global challenges.
The newly developed data distillation method demonstrates remarkable efficacy in maintaining predictive power while drastically reducing dataset size. Results indicate that models trained on these distilled datasets achieve an Overall Accuracy (OA) of approximately 90-95%, a performance level closely aligned with those trained using the complete, original datasets. Importantly, this method surpasses the capabilities of existing distillation techniques, exhibiting an improvement of roughly 20-25% in accuracy specifically on the challenging NWPU-RESISC45 dataset – a benchmark for remote sensing image classification. This substantial gain highlights the method’s potential to not only compress data but also enhance model performance, offering a significant step forward in efficient machine learning.
The integration of classification consistency loss and visual prototype guidance represents a substantial advancement in data distillation techniques, yielding approximately a 20-25% performance boost over methods relying solely on diffusion loss. This improvement stems from a more robust learning process; classification consistency loss encourages the model to produce similar predictions for both original and distilled data, fostering stability and generalization. Simultaneously, visual prototype guidance directs the model to focus on representative features within each class, refining the learned feature space and enhancing discriminative power. By combining these two loss functions, the model effectively captures both global consistency and fine-grained details, leading to significantly improved accuracy and a more efficient distillation process, particularly when dealing with complex datasets like NWPU-RESISC45.
The research demonstrates a significant advancement in efficient machine learning through a method capable of achieving approximately 86-88% accuracy using only 10 images per class – a paradigm known as “few-shot learning”. Utilizing a ResNet18 architecture and the NWPU-RESISC45 dataset, this performance rivals that of models trained on the complete dataset, representing a substantial reduction in data requirements. This capability is crucial for deploying complex image classification models in environments where data storage and computational resources are limited, opening doors for real-time analysis and applications in fields like precision agriculture and environmental monitoring where full datasets are often impractical to acquire or process.

The pursuit of synthetic data, as detailed in the paper, hinges on faithfully recreating the underlying patterns within complex remote sensing imagery. This endeavor mirrors the sentiment expressed by Geoffrey Hinton: “The key is to find ways to make the models learn the underlying structure of the data.” The discriminative prototype-guided diffusion model strives to do precisely that – by distilling essential features into a smaller, privacy-preserving dataset. Analyzing the visual patterns encoded in the original imagery and reconstructing them through diffusion isn’t merely about replicating pixels; it’s about capturing the semantic consistency that defines those patterns, and ultimately, enabling robust performance with reduced computational demands. The method demonstrates how understanding a system – in this case, the information contained within remote sensing data – requires exploring and recreating its fundamental structures.
What Lies Ahead?
The pursuit of distilled datasets, as demonstrated by this work, inevitably encounters the ghost in the machine: semantic fidelity. While quantitative metrics suggest performance preservation, the subtle nuances of remote sensing data – the spectral signatures of stressed vegetation, the texture of urban sprawl – remain difficult to fully capture in synthetic generation. Future investigations must move beyond pixel-wise comparisons and embrace perceptual evaluations, perhaps leveraging adversarial networks trained to distinguish between authentic and distilled imagery, not for deception, but for insightful feedback.
A curious limitation lies in the reliance on pre-defined prototypes. The assumption that these prototypes comprehensively represent the data distribution feels… convenient. One imagines a scenario where the true complexity of a remote sensing scene exceeds the capacity of these guiding exemplars, leading to a form of synthetic impoverishment. Exploring methods for discovering prototypes, or even abandoning them altogether in favor of more flexible generative constraints, could unlock greater realism.
Ultimately, this work highlights a broader pattern: the tension between utility and privacy. As generative models become more sophisticated, the line between truly anonymized data and cleverly disguised originals will blur. The challenge isn’t merely technical; it’s philosophical. The question becomes not can we synthesize data, but should we, and what responsibility accompanies the creation of these artificial worlds.
Original article: https://arxiv.org/pdf/2601.15829.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-01-26 00:41