Author: Denis Avetisyan
New research explores how generative AI can subtly alter music to reduce aggressive sentiment and improve overall audio quality.

This study demonstrates the feasibility of using Large Language Models and generative AI techniques for automated music content moderation through vocal replacement and lyrical transformation.
While content moderation often relies on blunt censorship, potentially amplifying restricted material, this research-detailed in ‘Abusive music and song transformation using GenAI and LLMs’-explores a more nuanced approach. We demonstrate that generative AI and large language models can automatically transform aggressive lyrical content and vocal delivery in popular music, reducing harmful sentiment without simply silencing it. Acoustic and sentiment analyses reveal significant reductions in vocal aggressiveness-up to 88.6% in chorus sections-alongside improvements in audio quality metrics like Harmonic to Noise Ratio. Could this technology offer a scalable solution for creating safer listening experiences while preserving artistic expression and avoiding the pitfalls of traditional content moderation?
The Inevitable Echo: Confronting Harmful Content in the Musical Landscape
The contemporary music landscape is increasingly characterized by the widespread presence of explicit and aggressive lyrical content, creating a substantial challenge for both digital platforms and audiences. This isn’t simply a matter of volume; the ease of music creation and distribution means that content pushing boundaries of acceptability-ranging from violent imagery to misogynistic themes-circulates rapidly and broadly. Platforms struggle to balance freedom of expression with the need to protect users, particularly younger listeners, from potentially harmful messaging. Moreover, the subjective nature of ‘harmful’ content complicates automated detection, and manual review struggles to keep pace with the sheer volume of new releases. Consequently, a significant portion of music available today demands critical engagement, and listeners are often left to navigate these complex themes without adequate tools or context.
Current content moderation strategies, heavily reliant on reactive flagging and explicit tagging, are increasingly inadequate in the face of rapidly expanding digital music libraries. These systems typically operate after potentially harmful content has already been uploaded and circulated, creating a constant game of catch-up for platforms. The sheer volume of new music released daily – often exceeding tens of thousands of tracks – overwhelms manual review processes and limits the effectiveness of automated filters. Moreover, scaling these methods to encompass diverse languages, cultural contexts, and evolving slang proves exceptionally difficult and resource-intensive, leaving significant gaps in protection and highlighting the need for more proactive and nuanced approaches to content assessment.
Existing content moderation systems often struggle with the complexities of lyrical expression, creating a precarious balance between protecting audiences and upholding artistic freedom. These systems, designed to flag overtly explicit or aggressive language, frequently misinterpret satire, metaphor, or cultural context within song lyrics, leading to the erroneous removal of legitimate artistic work – a form of digital censorship. Conversely, the same limitations can allow genuinely harmful messages – those employing coded language, subtle threats, or normalizing problematic behaviors – to slip through the filters undetected. This inability to discern nuance presents a critical challenge, as lyrical content can significantly influence attitudes and behaviors, and a failure to accurately assess harm risks both stifling creative expression and inadvertently amplifying damaging ideologies.
Reframing the Chorus: Introducing a Proactive Music Transformation Framework
The Music Transformation Framework is a system designed to automatically improve musical content by addressing potentially harmful lyrical elements. Utilizing Generative AI models, the framework operates on the principle of content refinement, not censorship, with the aim of aligning music with platform safety standards. The core functionality involves analyzing existing musical tracks and, where necessary, algorithmically modifying lyrics to remove or replace problematic phrasing while preserving the original artistic intent as much as possible. This proactive approach allows for scalable content moderation and reduces the reliance on manual review processes, enabling platforms to offer a safer and more inclusive listening experience.
The Music Transformation Framework incorporates sentiment analysis algorithms to detect potentially offensive lyrical content. These algorithms assess text based on semantic meaning and contextual indicators, going beyond simple keyword detection to identify nuanced expressions of hate speech, toxicity, or harmful sentiments. The system utilizes both lexicon-based approaches, referencing databases of offensive terms, and machine learning models trained on large datasets of labeled lyrics to determine the sentiment score of individual phrases and complete passages. Identified passages exceeding predefined sensitivity thresholds are then flagged for subsequent detoxification or modification processes.
Lyric detoxification within the framework utilizes a combination of natural language generation (NLG) and constrained optimization techniques. The system identifies problematic phrases flagged by sentiment analysis and generates alternative phrasing options that maintain the original lyrical intent and rhyme scheme while removing offensive content. This process involves a large language model fine-tuned on a dataset of ethically-sourced lyrical replacements and employs filtering mechanisms to ensure output adheres to predefined platform guidelines regarding profanity, hate speech, and sensitive topics. The system prioritizes semantic similarity between original and rewritten lyrics, and incorporates a scoring function to evaluate the quality and appropriateness of generated alternatives before final replacement.
The Music Transformation Framework incorporates a modular architecture to facilitate adjustments based on differing content sensitivity requirements and cultural norms. This is achieved through interchangeable modules handling sentiment analysis thresholds and lyric detoxification strategies; administrators can select and configure these modules to align with specific platform policies or regional standards. The system allows for granular control over the identification of problematic content, enabling adjustments to account for nuances in language, slang, and culturally specific expressions. Furthermore, the modularity extends to the detoxification process, permitting the implementation of alternative rewriting techniques tailored to maintain artistic intent while adhering to varied guidelines. This adaptability ensures the framework can be deployed across diverse markets and evolve with changing societal expectations.
Dissecting the Signal: Technical Foundations – Disentangling and Reconstructing Audio
The system utilizes Demucs, a deep learning source separation model, to achieve isolation of the vocal track from the remaining instrumental components of a given audio file. Demucs employs a convolutional neural network architecture trained on a large dataset of multi-track music to learn representations that allow for effective masking of non-vocal elements. This process yields a stem containing primarily the vocal signal, enabling subsequent lyric modification and re-synthesis without affecting the original instrumental track. The model’s performance is characterized by its ability to minimize artifacts and maintain a high signal-to-noise ratio in the isolated vocal stem, crucial for preserving audio quality throughout the detoxification pipeline.
The system employs MPNET, a masked pre-training neural network, to create dense vector representations, or semantic embeddings, of the original lyrics. These embeddings capture the contextual meaning of each word and phrase, allowing for a nuanced understanding of the lyrical content. By comparing these embeddings to a database of flagged terms and phrases associated with problematic content, the system can accurately identify and isolate specific passages requiring modification. This approach moves beyond simple keyword detection, enabling the identification of problematic ideas expressed through paraphrasing or subtle language, and ensuring more precise targeting of lyrical revisions.
Following the process of lyric revision, Suno AI is employed to synthesize new vocal performances that correspond to the modified lyrical content while preserving the characteristics of the original song. This involves inputting the detoxified lyrics and the instrumental track into Suno AI’s generative model, which then produces an entirely new vocal track. The model is designed to maintain consistency in aspects such as tempo, key, and overall musical style, ensuring a seamless integration with the existing instrumental accompaniment. The generated vocals are fully synthetic, replacing the original vocal track with a performance based on the revised lyrics, effectively decoupling the lyrical content from the original vocal performance.
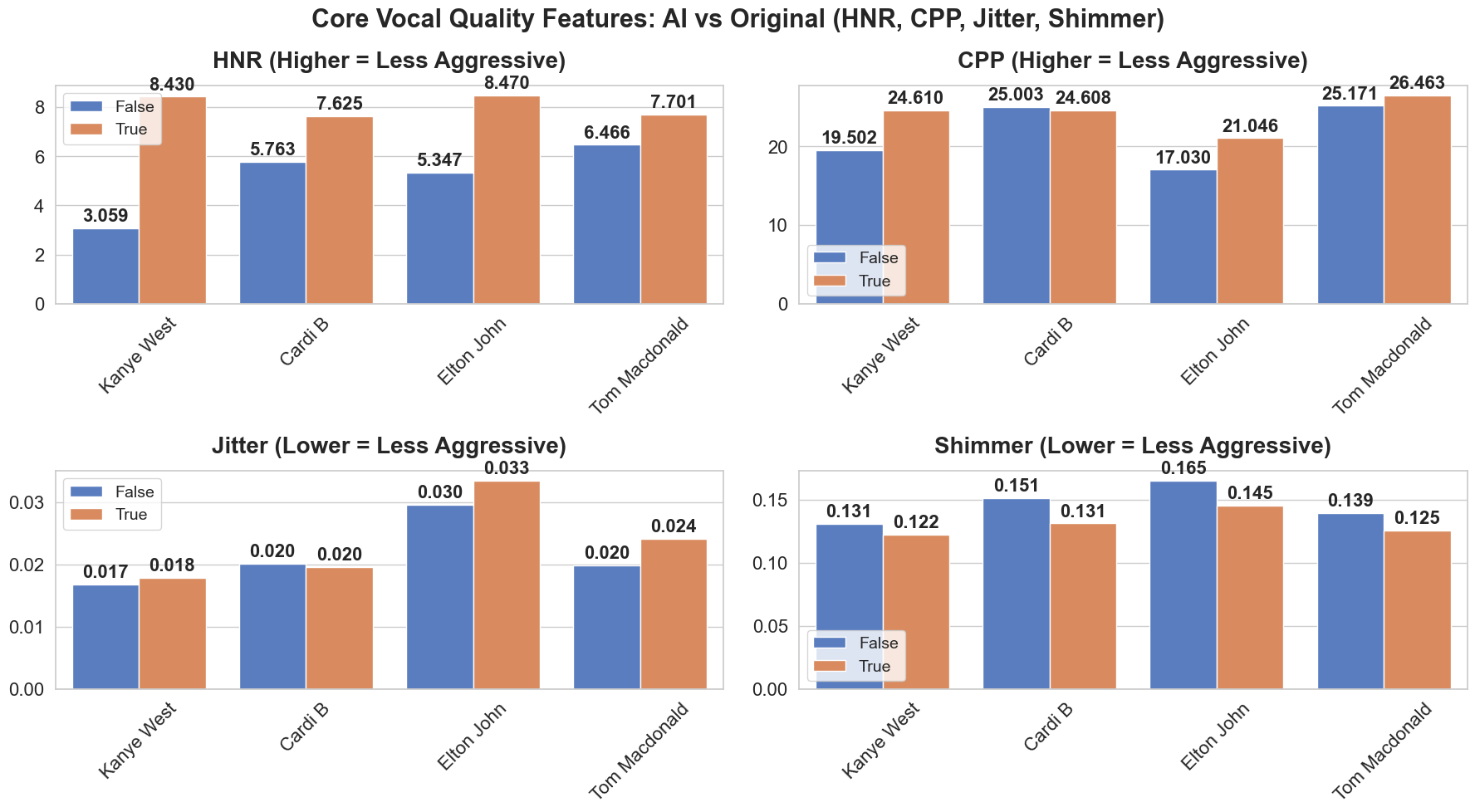
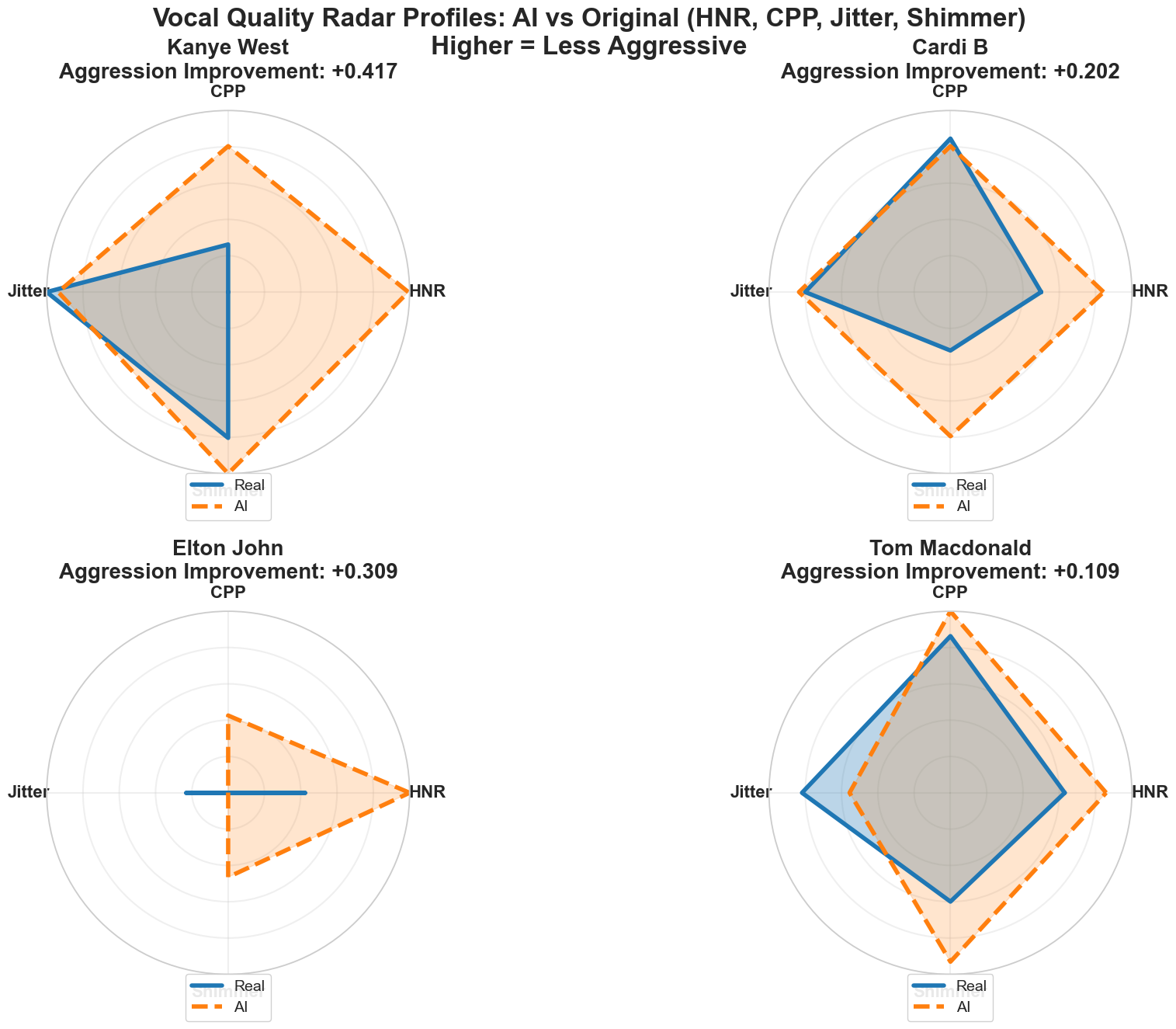
Vocal quality assessment during audio reconstruction utilizes objective metrics including Harmonics-to-Noise Ratio (HNR), Cepstral Peak Prominence (CPP), Shimmer, and Jitter to minimize perceptible auditory artifacts. Quantitative analysis of transformed songs demonstrates a consistent improvement in HNR, ranging from 3.06 dB to 8.43 dB. Higher HNR values indicate a greater proportion of harmonic content relative to background noise, correlating with enhanced vocal clarity and perceived naturalness. Measurements of CPP, Shimmer, and Jitter were also monitored to ensure the generated vocals maintain characteristics consistent with high-quality audio recordings and avoid unnatural or robotic qualities.
Echoes of Adaptation: Real-World Validation and Artistic Preservation
The Music Transformation Framework’s adaptability was rigorously tested through its application to a diverse range of contemporary artists, including Kanye West, Cardi B, Elton John, and Tom Macdonald. This deliberate selection aimed to assess the framework’s performance across varying musical genres, lyrical styles, and levels of explicit content. By processing songs from artists known for both mainstream appeal and potentially controversial themes, researchers demonstrated the framework’s capacity to function effectively regardless of an artist’s established brand or creative approach. The successful transformation of tracks from this eclectic group highlights the framework’s potential as a broadly applicable tool for content moderation within the music industry, moving beyond niche applications to address a wide spectrum of musical expression.
The Music Transformation Framework doesn’t simply remove aggressive lyrics; it intelligently reframes them while upholding the core artistic vision of each song. Through nuanced natural language processing, the system discerns the intent behind potentially offensive phrasing, substituting words and phrases with alternatives that maintain the original rhyme scheme, rhythm, and emotional weight. This ensures that the transformed content doesn’t feel sterile or artificial, but rather represents a softened version of the artist’s message. The framework’s success lies in its ability to distinguish between artistic expression and genuinely harmful language, achieving a delicate balance that allows music to remain impactful and engaging without perpetuating negativity – a crucial step towards responsible content moderation.
A thorough qualitative assessment of the Music Transformation Framework’s output confirms substantial reductions in offensive language across a diverse musical spectrum. Analyses of tracks by artists including Kanye West and Cardi B reveal lyrical aggression reductions ranging from 63.3% to 85.6%, respectively, achieved without discernible compromise to the original artistic intent or overall listening experience. This suggests the framework effectively targets and mitigates problematic content while preserving the stylistic nuances and emotional impact inherent in each song – a critical distinction from simple censorship or blanket removal of potentially sensitive lyrics. The results indicate a nuanced approach to content moderation capable of diminishing negativity without sacrificing artistic expression, fostering a more inclusive environment for music consumption.
The Music Transformation Framework presents a departure from traditional content moderation strategies, shifting the focus from reactive censorship to a proactive approach. Instead of removing or altering content after it has been flagged as offensive, the framework intervenes during the creative process, subtly adjusting lyrical aggression while safeguarding the core artistic expression. This preemptive methodology not only minimizes the potential for public outcry and subsequent content removal, but also fosters a more inclusive musical environment by reducing the prevalence of harmful language at its source. The result is a listening experience that remains authentic to the artist’s vision, yet aligns with evolving societal standards for respectful communication, ultimately offering a path towards a more harmonious and accessible musical landscape for all.
The research into AI-driven music transformation highlights a fundamental truth about all complex systems: entropy is inevitable. While the study focuses on reducing aggression in musical content through vocal replacement and lyrical adjustments, it implicitly acknowledges that even seemingly stable systems require ongoing maintenance to counteract decay. As Blaise Pascal observed, “All of humanity’s problems stem from man’s inability to sit quietly in a room alone.” This resonates with the core concept of content moderation; the ‘room’ being the digital space, and the ‘quiet’ representing a lack of harmful content. The effort to refine audio and lyrics isn’t about achieving perfection, but rather delaying the natural tendency towards disorder, recognizing that any simplification – or in this case, lyrical change – carries a future cost in terms of artistic nuance or potential misinterpretation.
What Lies Ahead?
The demonstrated capacity to modulate aggression within musical content via generative AI represents not a solution, but a refinement of an inherent problem. Every commit to this technology is a record in the annals of audio manipulation, and every version a chapter in the ongoing negotiation between artistic expression and societal constraint. The current work addresses symptoms, not causes; the underlying impetus for aggressive lyrical content will persist regardless of algorithmic intervention. Future iterations must confront this, perhaps by exploring methods for not simply replacing problematic elements, but for addressing their root sentiment within the broader artistic intent.
A significant limitation lies in the subjective nature of ‘aggression’ itself. The metrics employed, however robust, remain tethered to current definitions, vulnerable to cultural shifts and evolving sensibilities. Delaying fixes to these definitional ambiguities is a tax on ambition, creating a brittle system susceptible to obsolescence. The field must move beyond simple sentiment analysis towards a more nuanced understanding of emotional impact, potentially integrating physiological data or even predictive modeling of audience response.
Ultimately, the true challenge isn’t perfecting the technology, but accepting its inherent impermanence. All systems decay; the question is whether they age gracefully. This work establishes a baseline, a single snapshot in time. The next chapter demands a reckoning with the inevitable – the constant need for recalibration, adaptation, and a healthy skepticism towards any claim of definitive ‘content moderation’.
Original article: https://arxiv.org/pdf/2601.15348.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- The Best Directors of 2025
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
2026-01-25 23:07