Author: Denis Avetisyan
A new approach simplifies the core architecture of the Decision Transformer by eliminating unnecessary historical data, leading to faster and more efficient offline reinforcement learning.
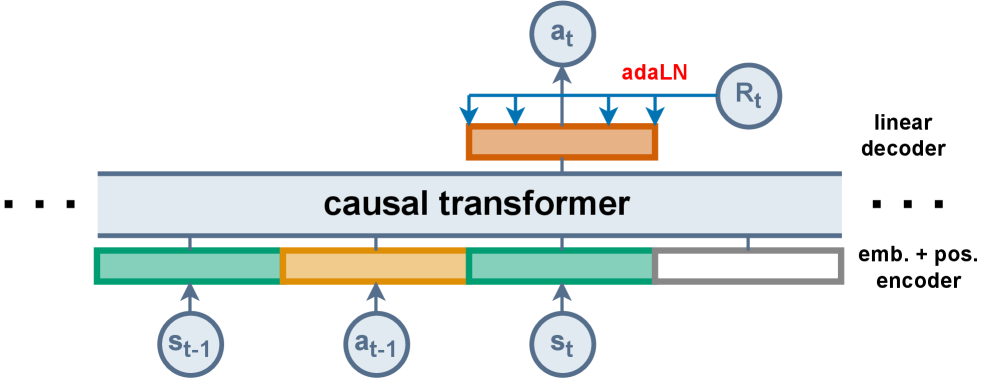
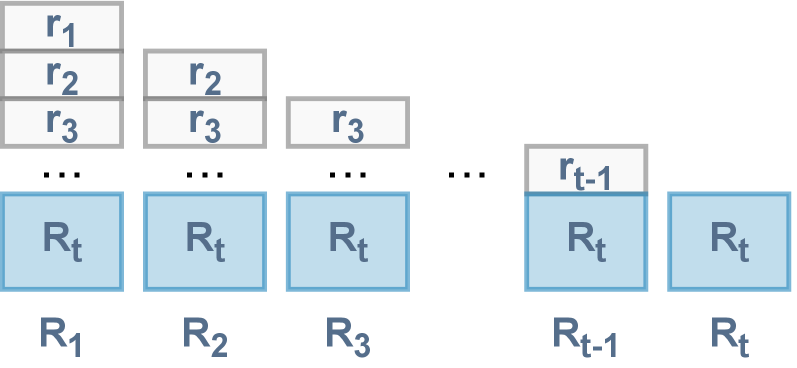
Decoupling the conditioning from the full Reward-to-Go history improves performance and reduces computational redundancy in the Decision Transformer framework.
While the Decision Transformer has emerged as a leading sequence modeling approach for offline reinforcement learning, its reliance on conditioning action predictions on the entire trajectory of Return-to-Go (RTG) presents a potential redundancy. This work, ‘Decoupling Return-to-Go for Efficient Decision Transformer’, identifies this inefficiency and proposes a simplified architecture, the Decoupled DT (DDT), which conditions solely on the current RTG value. Our experiments demonstrate that this decoupling not only improves performance across multiple offline RL tasks but also significantly reduces computational cost. Could this streamlined approach unlock further advancements in the efficiency and scalability of sequence-based reinforcement learning algorithms?
The Limits of Trial and Error: Why Traditional RL Falters
Traditional reinforcement learning algorithms often demand a substantial amount of interaction with the environment to learn effective policies. This reliance on trial-and-error exploration poses significant challenges in many real-world applications where each interaction might be costly, time-consuming, or even dangerous. Consider robotics, where physical experimentation can lead to wear and tear on hardware, or healthcare, where suboptimal actions could have adverse effects on patients. The need for extensive sampling effectively limits the applicability of standard RL techniques to scenarios where plentiful, inexpensive data is available, prompting researchers to explore alternative approaches that minimize the requirement for direct environmental engagement and maximize learning from limited experiences.
Dynamic programming, a cornerstone of reinforcement learning theory, aims to solve sequential decision-making problems by breaking them down into smaller subproblems. However, its practical application is severely hampered by the “curse of dimensionality.” As the number of state variables increases – a common characteristic of real-world complexity – the computational resources required to store and process the value functions grow exponentially. This means that even moderately complex environments with a relatively small number of state variables can quickly become intractable, rendering dynamic programming computationally prohibitive. For instance, a robotic system operating in a three-dimensional space requires significantly more computational power than one operating in a two-dimensional plane. Consequently, while theoretically elegant, dynamic programming often struggles to scale to the intricate and high-dimensional scenarios encountered in fields like robotics, game playing, and resource management, necessitating alternative approaches to address this fundamental limitation.
The practical deployment of reinforcement learning algorithms frequently encounters significant obstacles due to a reliance on extensive interaction with the environment. This presents a critical limitation in domains where such interaction is either prohibitively expensive – think robotics or drug discovery – or simply impossible, as in scenarios involving historical data or simulations with hard constraints. Moreover, the computational demands of many RL methods scale poorly with the complexity of the state and action spaces, a phenomenon known as the ‘curse of dimensionality’. This scalability issue restricts the ability of these algorithms to address real-world problems characterized by high-dimensional data and intricate dynamics, ultimately hindering their broader applicability and necessitating the development of more data-efficient and scalable approaches.
Sequence Modeling: A Paradigm Shift in Reinforcement Learning
Offline reinforcement learning distinguishes itself from traditional RL by eliminating the need for active environment interaction during the learning process. Instead of an agent learning through trial and error, this approach utilizes pre-collected datasets – often termed “batch datasets” – containing sequences of states, actions, and rewards. These datasets can originate from various sources, including human demonstrations, previously trained policies, or random exploration. The ability to learn solely from static data offers significant advantages, such as enabling learning in environments where online interaction is costly, dangerous, or impractical, and facilitating the reuse of existing data for new tasks. This contrasts with on-policy RL algorithms that require current policy data for updates and off-policy algorithms that still generally require some level of environment interaction to correct for distribution shift.
The Decision Transformer fundamentally alters the reinforcement learning paradigm by representing trajectories as sequential data amenable to sequence modeling techniques. Traditionally, RL focuses on learning a policy that maximizes cumulative reward through trial-and-error interaction with an environment. However, the Decision Transformer instead casts a trajectory – a series of state, action, and reward tuples – as a single sequence. This allows the application of sequence modeling architectures, specifically the Transformer, to predict future actions conditioned on past states, actions, and desired returns-to-go. By framing the problem as sequence prediction, the Decision Transformer leverages the strengths of Transformer models in capturing long-range dependencies and complex relationships within sequential data, effectively bypassing the need for dynamic programming or policy optimization commonly found in traditional RL approaches.
The application of the Transformer architecture to reinforcement learning enables the modeling of long-range dependencies within sequential data, exceeding the capabilities of recurrent neural networks in capturing relationships between distant time steps. This is achieved through the self-attention mechanism, which allows the model to weigh the importance of different elements in the input sequence when predicting future elements. Specifically, the Transformer processes entire trajectories-sequences of states, actions, and rewards-in parallel, facilitating the identification of complex, non-linear correlations that influence optimal decision-making. This capability is crucial for tasks requiring planning and reasoning over extended horizons, as the model can effectively learn from and generalize across diverse trajectory data without being limited by the vanishing gradient problem inherent in recurrent architectures.
Guiding the Decision Transformer: The Power of Conditioning
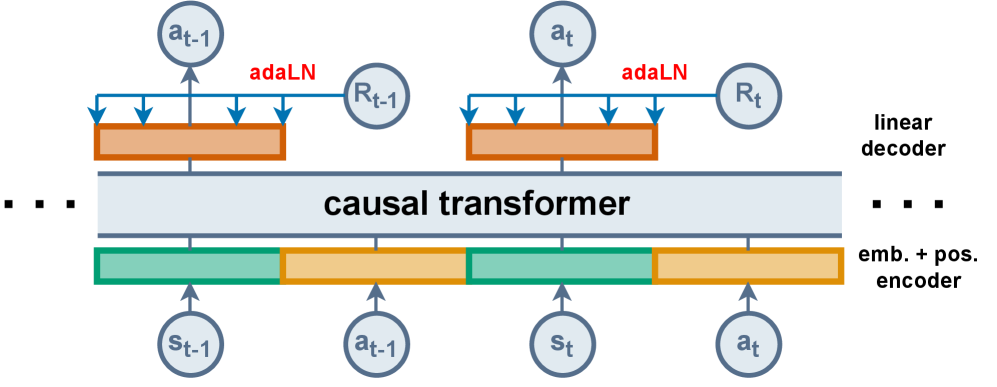
The Decision Transformer utilizes Return-to-Go (RTG) as a conditioning signal to enable reward prediction. RTG represents the cumulative reward expected from a given state until the end of an episode; by incorporating RTG into the model’s input sequence, the policy is effectively conditioned on the desired future return. This allows the Decision Transformer to frame reinforcement learning as a sequence modeling problem, predicting future actions based on past states, actions, and the anticipated future reward, rather than directly optimizing a value function or policy. Consequently, the model learns to select actions that align with achieving the specified RTG, effectively planning for future rewards and enabling goal-conditioned behavior.
Hindsight Information Matching (HIM) and Reward Conditioned Supervised Learning (RC-SL) address the challenge of learning effective policies from offline datasets that frequently contain suboptimal trajectories. HIM operates by re-labeling trajectories with the rewards achieved if alternative actions had been taken, effectively transforming failures into successes for learning purposes. RC-SL, conversely, frames the learning problem as a supervised regression task where the model predicts actions conditioned not only on the state and desired return, but also on the achieved reward. By conditioning on rewards, RC-SL allows the model to differentiate between trajectories with similar states but varying outcomes, improving its ability to learn from diverse and potentially flawed data. Both techniques improve sample efficiency and policy performance in offline reinforcement learning scenarios by mitigating the impact of suboptimal experiences.
The Decoupled Decision Transformer (DDT) represents a simplification of the original Decision Transformer (DT) architecture by exclusively utilizing Return-to-Go (RTG) as a conditioning signal. This approach eliminates the need for additional conditioning variables, leading to increased computational efficiency and a streamlined training process. Benchmarking on the D4RL benchmark suite demonstrates that the DDT achieves approximately 10% better performance compared to the original DT, indicating that focusing solely on RTG can improve the efficacy of trajectory-based reinforcement learning without sacrificing overall performance.
Beyond the Static Dataset: Implications for Policy Safety and Scalability
To navigate the complexities of offline reinforcement learning, algorithms such as CQL, IQL, and BCQ strategically limit the learned policy’s divergence from the original behavior policy. These methods achieve this through techniques like value regularization, which penalizes estimations of state-action values that differ significantly from those observed in the dataset, and policy constraints, which directly restrict the actions the learned policy can take. By anchoring the policy to the experienced data distribution, these constraints mitigate the risk of extrapolation to unseen states and actions-a common pitfall in offline RL where the agent might encounter situations not covered in the training data. This careful balancing act allows the agent to learn a robust and safe policy without actively interacting with the environment, crucial when exploration is costly or impossible.
A central challenge in offline reinforcement learning lies in the potential for learned policies to generalize poorly to states or actions not represented in the training data – a phenomenon known as extrapolation error. To counter this, algorithms employ strategies that constrain the learned policy, preventing it from venturing too far beyond the boundaries of observed behavior. These constraints, often implemented through techniques like value regularization or explicit policy penalties, effectively create a safety net, ensuring the agent operates within a more predictable and reliable region of the state-action space. By limiting extrapolation, these methods not only reduce the risk of catastrophic failures in deployment but also foster greater confidence in the robustness and safety of the learned policy, particularly in safety-critical applications where unforeseen behavior is unacceptable.
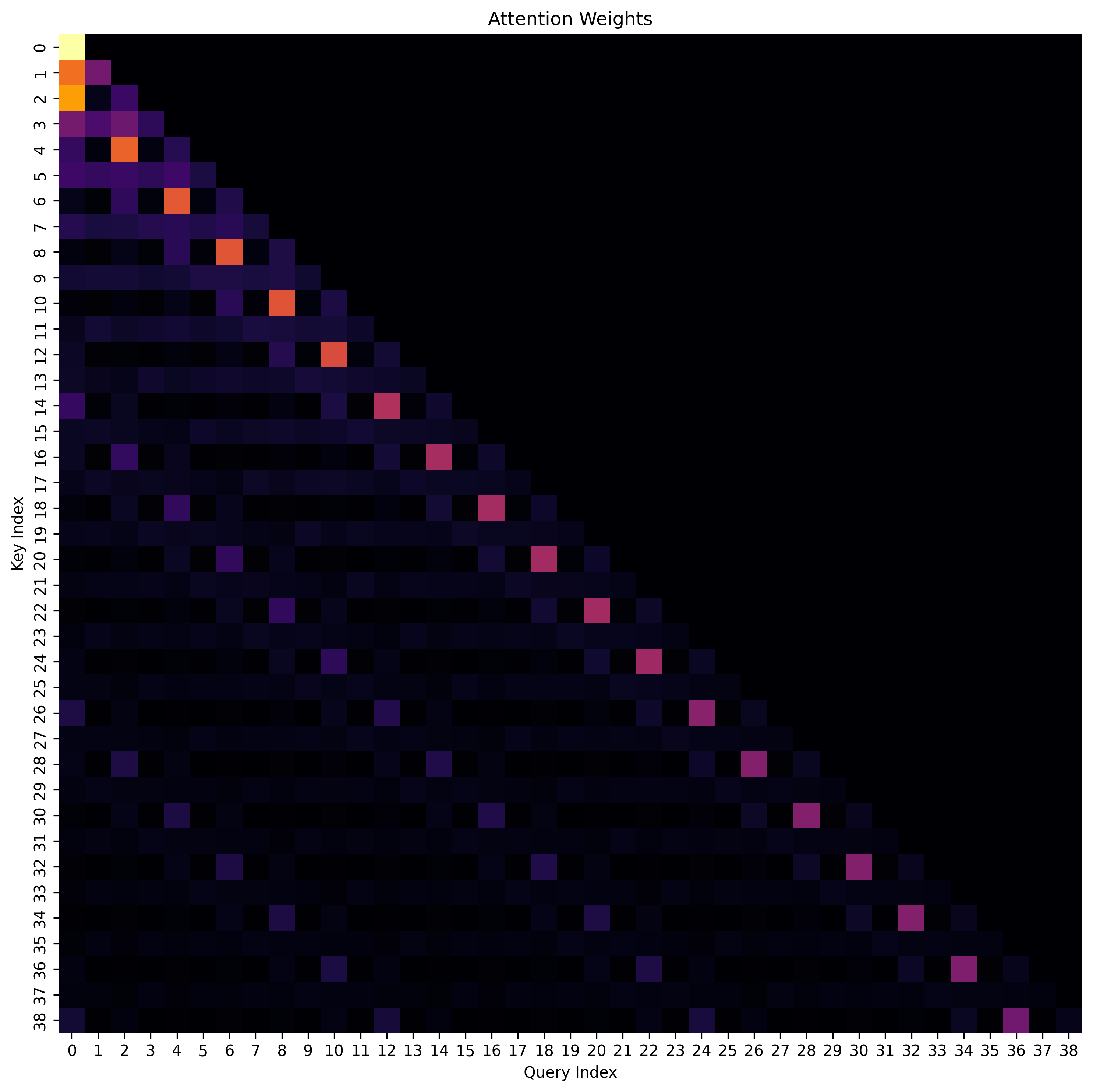
Rigorous testing on the D4RL benchmark suite confirms the efficacy of algorithms designed to tackle the complexities of offline reinforcement learning. These methods consistently demonstrate improved performance and stability when learning from static datasets, a critical advancement for real-world applications. Notably, the DDT algorithm further optimizes this process by capitalizing on the quadratic scaling characteristics of Transformer inference costs; it achieves comparable results while significantly reducing the required input sequence length from 3,000 to 2,000. This reduction not only enhances computational efficiency but also opens avenues for deploying these algorithms on resource-constrained platforms, broadening their potential impact across diverse fields.
The pursuit of efficiency within the Decision Transformer framework, as detailed in this work, echoes a fundamental tenet of problem-solving: stripping away the superfluous to reveal the core mechanism. This paper elegantly demonstrates that the full history of Reward-to-Go is, in essence, noise – an unnecessary complication. It’s reminiscent of Paul Erdős’s observation: “A mathematician knows a great deal of things and knows none of them.” The Decoupled DT, by focusing solely on the current RTG, doesn’t know the entire history, yet it achieves superior performance, proving that often, less is indeed more. This decoupling isn’t merely optimization; it’s a re-evaluation of the assumed necessities within the system-a deliberate attempt to read the open-source code of reinforcement learning and rewrite it for clarity.
Beyond the Signal
The decoupling of Reward-to-Go in the Decision Transformer framework, while demonstrating improved efficiency, subtly shifts the question. The original architecture, burdened by historical RTG, treated the entire sequence as crucial – a complete record of anticipated reward. Removing this redundancy isn’t merely a performance boost; it implies the past, as encoded in that history, held less predictive power than initially assumed. One pauses to ask: was the ‘bug’ a flaw, or a signal of a deeper principle? Perhaps the agent doesn’t need to remember the entire journey, but only the current expectation.
Future work will likely probe the limits of this ‘present-only’ conditioning. Can this principle be extended further – stripping away even more historical context? Or does a minimal, irreducible history remain essential for navigating genuinely complex, partially observable environments? The current results suggest a re-evaluation of sequence modeling in reinforcement learning, shifting the focus from exhaustive state representation to streamlined, expectation-based conditioning.
The pursuit of efficiency, however, cannot eclipse the fundamental question of generalization. While Decoupled DT excels within the confines of offline datasets, its performance in truly novel situations remains an open challenge. The true test will be its ability to adapt, to learn from limited experience, and to extrapolate beyond the patterns embedded in its training data – a challenge that demands a move beyond simply optimizing for reward, and towards a more nuanced understanding of the underlying dynamics of the world.
Original article: https://arxiv.org/pdf/2601.15953.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Top 20 Dinosaur Movies, Ranked
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- Silver Rate Forecast
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Games That Faced Bans in Countries Over Political Themes
2026-01-25 16:12