Author: Denis Avetisyan
A new approach combines the power of machine learning with large-scale optimization to deliver personalized recommendations that satisfy multiple stakeholders and complex constraints.
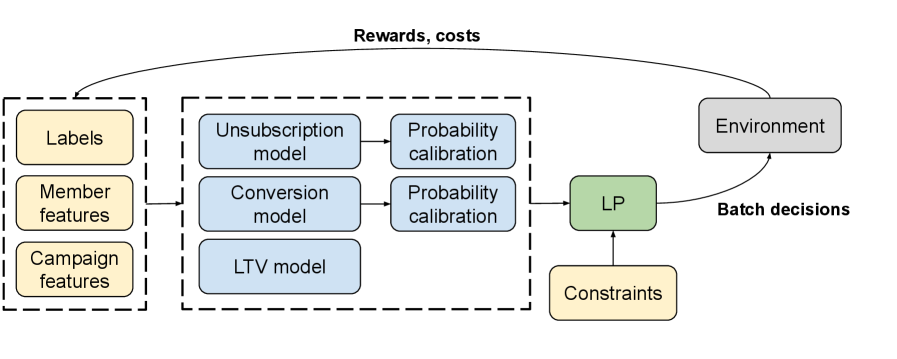
BanditLP leverages contextual bandits and linear programming for improved recommendation systems, demonstrated through significant gains in LinkedIn’s email marketing performance.
Balancing personalized recommendations with complex business constraints remains a significant challenge in modern recommendation systems. To address this, we introduce BanditLP: Large-Scale Stochastic Optimization for Personalized Recommendations, a novel framework that unifies neural contextual bandits with large-scale linear programming for multi-stakeholder optimization. This approach enables efficient exploration and constrained action selection at web scale, consistently outperforming strong baselines on both public datasets and within LinkedIn’s email marketing system-demonstrating measurable business impact. Can this integrated approach unlock further gains by dynamically adapting to evolving user preferences and business objectives?
The Fragile Equilibrium of Recommendation
Many recommendation systems are built upon the principle of maximizing a single metric – be it click-through rate, purchase probability, or time spent on platform – a strategy that often overlooks the varied interests of all involved. While effective at driving that primary goal, this singular focus can inadvertently disadvantage other key stakeholders. Content creators, for example, might see their diverse offerings narrowed to only those that fit the algorithm’s preferred profile, potentially stifling innovation and long-term content quality. Simultaneously, platform owners risk user dissatisfaction if recommendations become overly homogenous or fail to surface genuinely relevant options, ultimately impacting engagement and fostering a sense of limited choice. This inherent limitation underscores the need for systems that acknowledge and integrate the multifaceted needs of users, creators, and the platform itself, moving beyond a purely optimization-driven approach.
When recommendation systems prioritize a singular goal – such as maximizing click-through rates – unintended consequences often ripple through the entire digital ecosystem. Users may find themselves trapped in filter bubbles, presented with increasingly homogenous content that fails to broaden their perspectives or fulfill nuanced interests, leading to frustration and platform abandonment. Simultaneously, content providers can suffer from diminished visibility if their offerings don’t align with the algorithm’s narrow focus, hindering creative diversity and potentially impacting revenue streams. Ultimately, platform owners risk long-term disengagement and a loss of trust as both users and creators become dissatisfied with the unbalanced system, demonstrating that a singular objective, while seemingly efficient, can undermine the health and sustainability of the entire platform.
A robust solution to the challenges of modern recommendation systems lies in the development of frameworks designed to navigate competing priorities. These systems must move beyond single-objective optimization, instead embracing methodologies that acknowledge and balance the often-conflicting needs of users, content creators, and platform operators. Successfully implementing such a framework demands sophisticated algorithms capable of weighting diverse objectives – perhaps maximizing user engagement while simultaneously ensuring fair compensation for content providers and maintaining platform sustainability. This balancing act isn’t merely a technical hurdle; it necessitates a nuanced understanding of the incentives at play and the potential trade-offs inherent in any decision, ultimately paving the way for recommendation systems that deliver value to all stakeholders, not just a select few.
Constrained Optimization: The Architecture of Equilibrium
Constraint satisfaction is critical in multi-stakeholder recommendation systems because these systems often operate under numerous predefined limitations stemming from business rules, legal requirements, or user preferences. These constraints can take various forms, including limiting the exposure of certain items, enforcing diversity in recommendations to avoid filter bubbles, adhering to budgetary restrictions on promoted content, or respecting user-specified exclusion lists. Failure to satisfy these constraints can result in recommendations that are irrelevant, inappropriate, or even legally problematic. Consequently, optimization algorithms must be designed to explicitly account for and enforce these boundaries, often through penalty terms or feasibility checks integrated into the recommendation process. Effective constraint handling ensures the system operates within acceptable parameters and maintains the trust of all involved stakeholders.
Optimization within recommendation systems necessitates the formal definition of both positive and negative effects as quantifiable metrics. A Reward Function assigns a numerical value representing the desirability of a given outcome – such as a user clicking on a recommended item or completing a purchase – thereby incentivizing the system to maximize this value. Conversely, a Cost Function quantifies undesirable outcomes, like displaying irrelevant content, violating user privacy, or incurring excessive computational expense; the optimization process then aims to minimize this cost. These functions, often expressed mathematically as R(s, a) and C(s, a) respectively – where s represents the system state and a the action taken – provide the basis for algorithms to evaluate and compare different recommendation strategies, ultimately guiding the selection of actions that maximize reward while minimizing cost.
Stochastic Optimization addresses the challenges posed by inherent randomness and complexity in recommendation systems by employing probabilistic methods. Unlike deterministic optimization techniques which assume complete information, stochastic approaches account for uncertainty in user behavior, item characteristics, and system dynamics. This is achieved through algorithms that iteratively refine recommendations based on sampled data, approximating the optimal solution without requiring exhaustive enumeration of all possibilities. Common techniques include Stochastic Gradient Descent (SGD) and variations like Adam, which estimate gradients using mini-batches of data, and sampling-based methods like Simulated Annealing and Genetic Algorithms. These methods are particularly effective when dealing with large datasets, non-differentiable cost functions, or dynamic environments where conditions change over time, providing a robust pathway to identifying near-optimal recommendation strategies despite incomplete or noisy data.
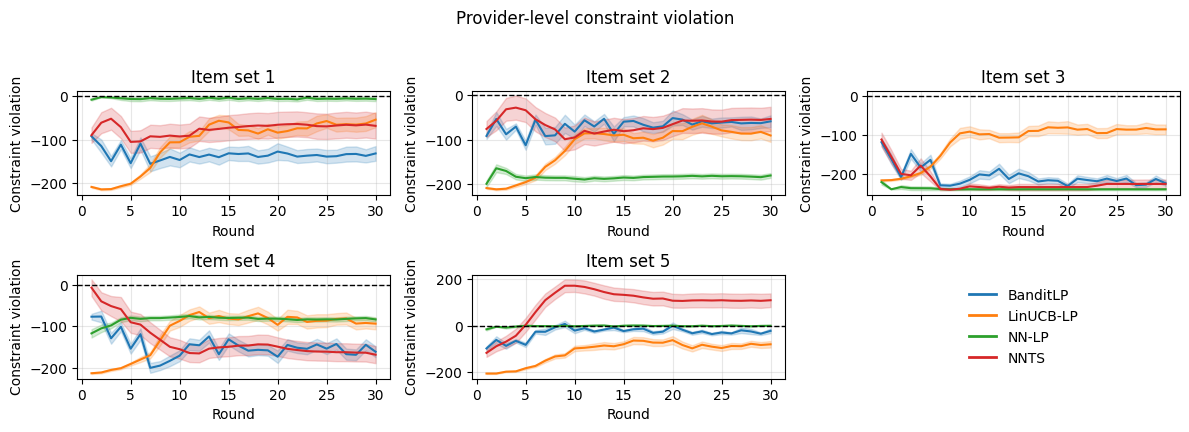
BanditLP: Orchestrating Harmony in a Complex System
BanditLP employs a combined approach utilizing Neural Thompson Sampling and Linear Programming to optimize recommendations across multiple, potentially conflicting, stakeholder objectives. Neural Thompson Sampling facilitates efficient exploration of the recommendation space, allowing the algorithm to learn which recommendations best satisfy various objectives. Simultaneously, a Linear Program is integrated to ensure that all recommendations adhere to predefined constraints, such as budget limitations or fairness requirements. This integration allows BanditLP to move beyond single-objective optimization and achieve a balance between competing stakeholder goals while remaining within operational boundaries. The Linear Program formulates the recommendation process as an optimization problem, defining an objective function and constraints based on stakeholder priorities and limitations.
Neural Thompson Sampling and a Linear Program operate in concert within BanditLP to optimize recommendations under multiple stakeholder objectives. Neural Thompson Sampling facilitates efficient exploration of the recommendation space by maintaining a probability distribution over potential actions, allowing the algorithm to balance exploration and exploitation. Simultaneously, the Linear Program acts as a constraint satisfaction mechanism, ensuring that selected recommendations adhere to pre-defined limits and requirements established by stakeholders; these constraints can include budgetary restrictions, diversity targets, or fairness criteria. This combined approach enables BanditLP to navigate the complex trade-offs inherent in multi-objective optimization while guaranteeing feasibility and compliance.
A controlled A/B test conducted on LinkedIn demonstrated the practical efficacy of BanditLP. Results indicated a statistically significant increase of +3.08% in long-term revenue for the BanditLP group when compared to the control. Simultaneously, the implementation of BanditLP correlated with a reduction in the unsubscription rate, decreasing by -1.51%. These metrics provide quantifiable evidence of BanditLP’s ability to optimize for multiple, potentially competing, stakeholder objectives within a real-world application.
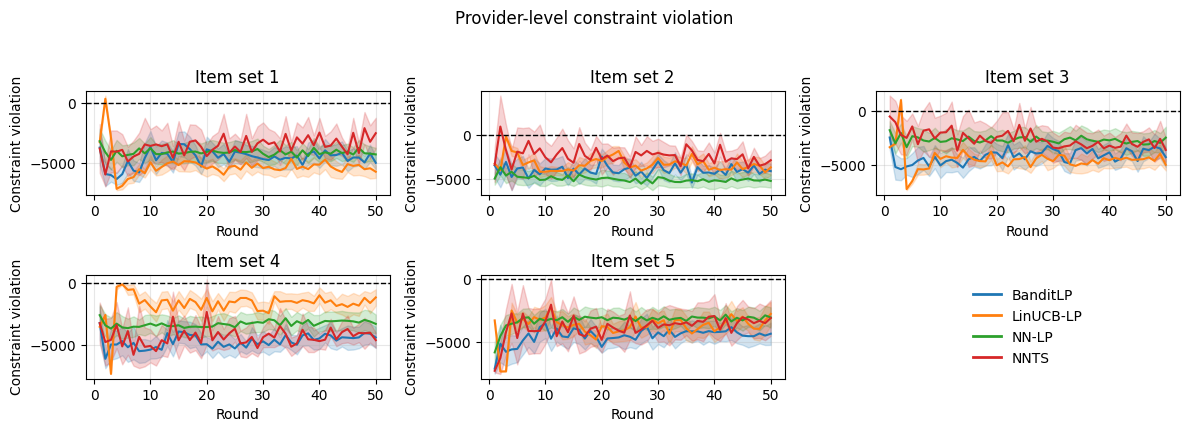
The Dance of Exploration and Exploitation: A System in Constant Refinement
At the heart of BanditLP’s effectiveness lies a carefully orchestrated balance between exploration and exploitation, a fundamental challenge in reinforcement learning. The algorithm doesn’t simply rely on past successes – exploiting known preferences – nor does it randomly experiment without purpose. Instead, it utilizes Contextual Bandits, a sophisticated technique that allows it to intelligently select actions – in this case, recommendations – based on the specific context of each user. This means BanditLP considers individual user characteristics and current conditions to determine whether to leverage proven strategies or explore potentially better, yet unknown, options. This dynamic approach ensures the system continually refines its understanding of user preferences, adapting to changing needs and maximizing the long-term value of each interaction.
The efficacy of BanditLP hinges on its capacity for continuous refinement, achieved through a dynamic interplay between user interactions and evolving stakeholder goals. The algorithm doesn’t operate on static assumptions; instead, it actively learns from each new data point, adjusting its recommendations to reflect shifting preferences and priorities. This adaptive learning process allows BanditLP to move beyond simply serving established patterns and instead anticipate future needs, ensuring recommendations remain relevant and valuable over time. By continually updating its internal model, the system effectively navigates changing landscapes, optimizing for long-term success rather than short-term gains and ultimately delivering a consistently improving experience for all involved.
BanditLP’s success hinges on its capacity to simultaneously refine recommendations through exploration and leverage proven strategies via exploitation, resulting in demonstrably increased user satisfaction. The algorithm doesn’t simply present popular options; it continually tests new approaches, learning which recommendations resonate best with individual preferences and evolving priorities. This dynamic process, rigorously validated through A/B testing, yielded a substantial +3.08% lift in revenue and a noteworthy -1.51% reduction in unsubscription rates, confirming that a carefully tuned balance between discovery and reliability is crucial for maximizing long-term engagement and value.
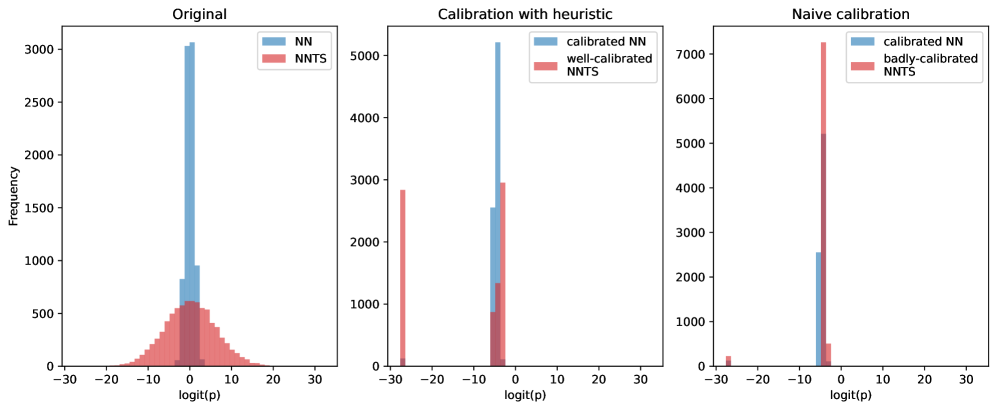
The pursuit of optimized recommendation systems, as demonstrated by BanditLP, inevitably introduces complexities mirroring the decay inherent in all systems. While BanditLP skillfully navigates multi-stakeholder optimization and complex constraints within a linear programming framework, it acknowledges the perpetual tension between exploration and exploitation-a dance against the inevitable drift toward suboptimal states. As Grace Hopper observed, “It’s easier to ask forgiveness than it is to get permission.” This sentiment resonates with the iterative nature of contextual bandits; continuous refinement, even with calculated risks, is often more effective than rigid adherence to pre-defined rules. The system doesn’t strive for perfect stability, but rather for graceful adaptation amidst the constant flow of time and changing user preferences.
The Long View
The architecture presented here, BanditLP, offers a temporary reprieve from the inevitable decay of recommendation systems. Each iteration of optimization, however elegant, merely shifts the point at which diminishing returns assert themselves. The current focus on multi-stakeholder optimization and constrained linear programming is logical – systems grow more complex, and their constraints multiply. Yet, these improvements age faster than they can be understood; the very act of solving one set of constraints creates new, unforeseen limitations. The real challenge isn’t maximizing current performance, but anticipating the inevitable drift toward obsolescence.
Future work will undoubtedly explore scaling these methods to even larger datasets and more intricate stakeholder relationships. However, a more fruitful path may lie in accepting the inherent impermanence of these systems. Can algorithms be designed to gracefully degrade, adapting to changing environments and shifting priorities without requiring constant recalibration? The pursuit of perfect optimization is a Sisyphean task. Perhaps the art lies in building systems that learn to age well.
Ultimately, BanditLP, like all architectures, will become a historical artifact. The interesting question isn’t how long it remains effective, but what the nature of its failure will reveal about the underlying dynamics of recommendation, and the limitations of attempting to impose order on fundamentally stochastic processes.
Original article: https://arxiv.org/pdf/2601.15552.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Every Notable ‘Star Trek: The Original Series’ Actor Who Died
- Trading on Thin Air: AI Agents Conquer Crypto Volatility
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
2026-01-25 14:32