Author: Denis Avetisyan
A new technique allows developers to remove sensitive information from AI models without needing access to the original training data.
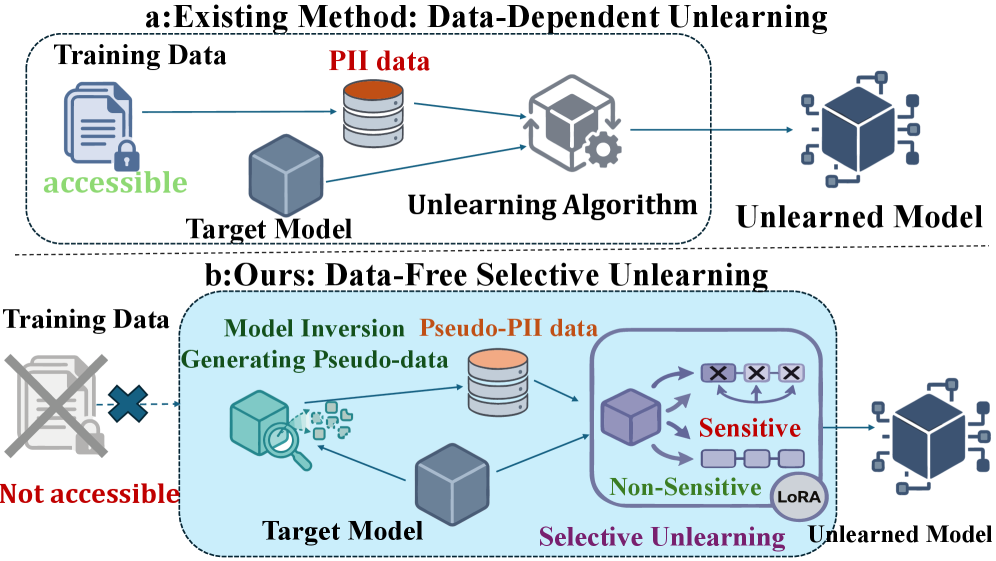
This paper introduces DFSU, a data-free selective unlearning method leveraging model inversion and parameter-efficient fine-tuning for privacy preservation in large language models.
Large language models, while powerful, risk inadvertently memorizing and revealing sensitive personal information present in their training data-a paradox increasingly challenging responsible AI deployment. This concern motivates the research presented in ‘Data-Free Privacy-Preserving for LLMs via Model Inversion and Selective Unlearning’, which introduces a novel framework for removing such memorized data without requiring access to the original training set. The proposed Data-Free Selective Unlearning (DFSU) method synthesizes pseudo-private information, constructs privacy masks, and then selectively unlearns this information through parameter-efficient adaptation within a low-rank subspace. Could this data-free approach pave the way for more practical and scalable privacy safeguards for large language models in real-world applications?
The Echo in the Machine: Memorization and the LLM
Large Language Models, while demonstrating remarkable abilities in natural language processing, fundamentally operate by identifying and replicating patterns within massive datasets – a process that inadvertently leads to the memorization of sensitive Personally Identifiable Information. During training, these models don’t simply learn about data; they effectively store it within their billions of parameters, meaning private details like names, addresses, or financial records can be directly reproduced given the right prompt. This isn’t a matter of the model ‘understanding’ the information, but rather statistically reconstructing it based on learned associations. Consequently, a seemingly innocuous query can inadvertently trigger the regurgitation of confidential data, presenting a significant privacy risk despite the absence of explicit data storage or retrieval mechanisms. The scale of these models exacerbates the problem; the more data ingested, the greater the likelihood of memorizing and potentially exposing private information.
Conventional machine unlearning techniques, designed to erase specific data points from a trained model, present a significant challenge when applied to Large Language Models. Methods like Exact Unlearning, which necessitate retraining the model from scratch or performing extensive parameter adjustments, become computationally infeasible due to the sheer scale of LLMs – models boasting billions, even trillions, of parameters. The resources required – processing power, time, and energy – escalate dramatically with model size, rendering precise data removal impractical. This limitation fuels research into more efficient unlearning strategies, such as approximate unlearning or parameter isolation, that aim to minimize computational burden while still effectively mitigating privacy risks associated with memorized data.
The very architecture of large language models presents a unique privacy challenge: even after direct removal of sensitive data from a training set, the model retains the ability to reconstruct and reveal memorized information. This isn’t a matter of incomplete deletion, but a fundamental consequence of how these models learn – by identifying and internalizing patterns, including those linked to individual identities. Consequently, relying solely on data removal proves insufficient; robust privacy-preserving techniques are crucial. Current research explores methods like differential privacy, federated learning, and secure multi-party computation, aiming to ‘blur’ or encrypt sensitive information within the model’s parameters, effectively shielding it from extraction without sacrificing overall performance. These advanced approaches represent a shift from reactive data deletion to proactive privacy protection, acknowledging that in the age of powerful LLMs, prevention is far more effective than cure.
Beyond Erasure: The Art of Approximate Forgetting
Approximate unlearning represents a class of techniques designed to remove the influence of specific data points from a trained machine learning model without requiring complete retraining from scratch. Unlike exact unlearning, which aims to perfectly revert the model’s parameters to a state equivalent to never having seen the data, approximate methods focus on sufficiently reducing the data’s impact on model outputs. This is achieved through iterative updates to the model’s parameters, often involving techniques like gradient ascent or stochastic gradient descent, applied specifically to minimize the loss associated with the data to be forgotten. The practicality of approximate unlearning lies in its computational efficiency; it demands significantly fewer resources than full retraining, particularly for large models and datasets, though it introduces a trade-off between the degree of ‘forgetting’ and computational cost.
Data-dependent unlearning methods, which include techniques like Gradient Ascent and Negative Preference Optimization, fundamentally rely on access to the original training dataset to effectively remove the influence of specific data points. This requirement presents a substantial practical limitation, as retaining the complete original training data indefinitely is often infeasible due to privacy concerns, data governance policies, storage constraints, or the natural evolution of datasets. Unlike data-independent approaches, these techniques calculate updates to model parameters based on the original data’s contribution to the model’s learned weights, meaning the absence of this data prevents accurate and complete ‘unlearning’ of the targeted information. This dependence restricts the applicability of these methods in scenarios involving data deletion, regulatory compliance like GDPR, or federated learning environments where original data is not centrally stored.
Approximate unlearning methods, while offering efficiency gains over full retraining, exhibit inherent instability that can manifest as catastrophic collapse – a rapid degradation of model performance across all tasks following the removal of specific data. This instability arises from the perturbation of model weights during the unlearning process, potentially disrupting the learned representations for unrelated data. To mitigate this, careful design of unlearning algorithms is crucial, often incorporating regularization techniques such as weight decay, clipping, or constrained optimization. These strategies limit the magnitude of weight updates and prevent drastic shifts in the model’s parameter space. Furthermore, techniques like iterative unlearning, where data is removed in small batches, and monitoring performance on a held-out validation set are employed to detect and prevent catastrophic failure during the unlearning process.
DFSU: A Data-Free Path to Privacy
DFSU, or Data-Free Selective Unlearning, addresses the removal of Personally Identifiable Information (PII) memorized within a trained machine learning model without necessitating access to the original training dataset. This is achieved by operating entirely on the model’s parameters and outputs, circumventing data privacy concerns associated with traditional unlearning methods that require retraining on the original data. The framework aims to selectively “unlearn” specific PII, effectively mitigating the risk of data leakage without compromising the model’s overall performance on non-sensitive data. This data-free approach is particularly relevant in scenarios where the original training data is unavailable due to privacy regulations, data governance policies, or practical limitations.
DFSU employs Logit-Based Model Inversion to reconstruct data representative of sensitive information without accessing the original training dataset. This technique operates by utilizing the model’s output logits – the pre-activation values – to generate synthetic data points that maximize the predicted probability of a specific target class. By optimizing for these logits, the process effectively reverses the forward pass, creating surrogate data that approximates the characteristics of the original, sensitive inputs. This allows for selective unlearning to be performed on the model using only the generated surrogate data, thereby preserving privacy and eliminating the need for direct access to PII.
Pseudo-PII Synthesis enhances the data-free unlearning process by generating representative data specifically designed to mimic the characteristics of the sensitive information targeted for removal. This is achieved through techniques like Contrastive Masking, which focuses on identifying and reconstructing the features most strongly associated with the PII, allowing for a more precise unlearning process without requiring access to the original data. The synthesized data serves as a proxy for the original PII, enabling selective unlearning algorithms to effectively remove the memorized sensitive information from the model’s parameters while minimizing impact on the model’s overall performance.
Low-Rank Adaptation (LoRA) is integrated into the selective unlearning process to enhance computational efficiency and model stability. Rather than updating all model parameters during unlearning, LoRA freezes the pre-trained weights and injects trainable low-rank matrices into each layer of the Transformer architecture. This parameter reduction significantly decreases the computational cost and memory requirements associated with unlearning specific data points. By constraining the updates to these low-rank matrices, LoRA also mitigates the risk of catastrophic forgetting and ensures the model maintains its general performance on non-sensitive data, contributing to a more stable unlearning process.

Impact and Validation: A Reduction in Exposure
Evaluations utilizing the AI4Privacy dataset reveal that the proposed Differentially Private Federated Summarization with Upsampling (DFSU) markedly diminishes the exposure of individual, sensitive data samples. The metric used to quantify this protection, Sample-Level Exposure Rate, demonstrates a substantial reduction in the likelihood of re-identifying specific inputs within the model’s outputs. This indicates that DFSU effectively safeguards against privacy breaches by obscuring the direct link between training data and the model’s generated content, offering a robust defense against potential data leakage and ensuring greater confidentiality for the information used in training large language models.
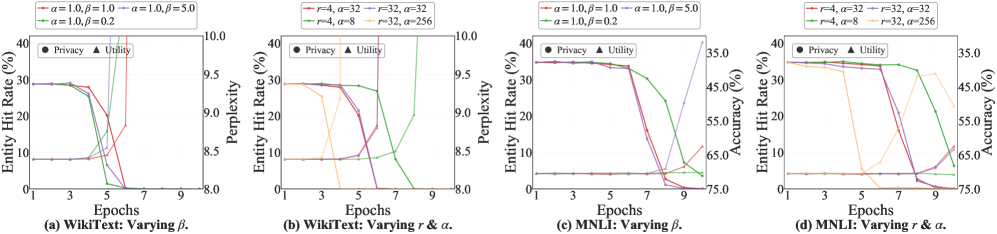
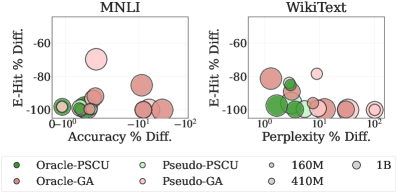
Rigorous evaluation reveals that DFSU effectively safeguards sensitive data, as demonstrated by key privacy metrics. Specifically, the Exact Reconstruction Rate (ERR) consistently measured 0.00% across all scales, indicating no exact copies of training data could be reconstructed from the model – a result matching the performance of an ideal, or ‘oracle,’ baseline. Complementing this, the Entity-Level Hit Rate (E-Hit) remained below 1%, signifying a highly limited ability to identify specific entities present in the original training dataset within the model’s outputs; these findings collectively demonstrate DFSU’s robust capacity for privacy erasure without compromising the model’s core functionality.
Evaluations reveal that DFSU not only enhances privacy but also maintains substantial language model utility. Benchmarking on the Pythia-410M model demonstrates a WikiText Perplexity of 8.83, indicating strong generative capabilities – the model continues to produce coherent and contextually relevant text. Crucially, DFSU achieves an MNLI Accuracy of 68.45%, suggesting that reasoning abilities remain largely unaffected by the privacy-preserving mechanisms. These results collectively demonstrate that DFSU effectively mitigates privacy risks without substantially compromising the core functionalities of large language models, paving the way for practical deployment in sensitive applications.
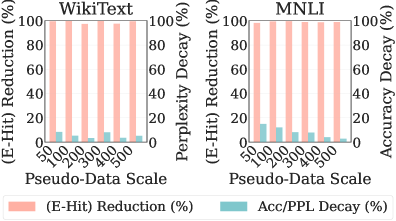
Data privacy within large language models often demands substantial computational resources, but recent research demonstrates that Differential Fine-tuning with Sampled Updates (DFSU) achieves near-maximal leakage reduction using a surprisingly small number of pseudo-samples – only 100. This efficiency is particularly notable because it suggests that robust privacy guarantees don’t necessarily require extensive data augmentation or complex training regimes. By strategically employing these pseudo-samples during fine-tuning, DFSU effectively minimizes the risk of sensitive information being reconstructed from the model’s outputs, rivaling the performance of systems requiring significantly more computational effort. This data efficiency makes DFSU a practical solution for resource-constrained environments and broad applicability across various LLM deployments seeking to balance privacy and utility.
Evaluations confirm that DFSU presents a viable strategy for addressing privacy concerns within large language models without substantially compromising their functionality. The framework demonstrably reduces the exposure of sensitive training data, achieving near-zero exact reconstruction rates and minimal entity-level hit rates, indicating effective data erasure. Crucially, this privacy enhancement is accomplished alongside the preservation of generative and reasoning capabilities, as evidenced by competitive perplexity scores on text generation tasks and maintained accuracy on natural language inference benchmarks. The efficiency of DFSU is further highlighted by its ability to achieve substantial leakage reduction with a relatively small number of pseudo-samples, suggesting its practical applicability in real-world scenarios where computational resources may be limited.
Towards Trustworthy Systems: The Horizon of Privacy-Preserving LLMs
Current data-free unlearning (DFSU) techniques primarily focus on removing specific data points from a model, but emerging research aims to extend these capabilities to address more nuanced privacy threats. A key area of investigation involves defending against membership inference attacks, where adversaries attempt to determine if a particular data record was used to train a model. Adapting DFSU to mitigate such attacks requires a shift in focus – moving beyond simply removing data to actively obscuring the model’s sensitivity to individual training examples. This involves developing methods that not only erase the influence of targeted data but also introduce controlled noise or regularization to prevent adversaries from gleaning information about the training set’s composition, ultimately bolstering the privacy guarantees of large language models in increasingly sophisticated adversarial landscapes.
Combining data-free unlearning with differential privacy presents a compelling pathway toward robust privacy safeguards in large language models. Data-free unlearning allows for the removal of sensitive information from a model without requiring access to the original training data, addressing concerns about data retention and potential misuse. However, this process isn’t inherently private; an adversary might still infer information about the removed data. Integrating differential privacy – a mathematical framework for quantifying privacy loss – into data-free unlearning techniques introduces calibrated noise during the unlearning process, effectively masking the influence of individual data points. This synergy not only ensures that the model ‘forgets’ specific information but also provides a quantifiable guarantee that the unlearning process itself doesn’t reveal sensitive details, ultimately fostering greater trust and accountability in the deployment of powerful language technologies.
The practical implementation of data-free unlearning (DFSU) hinges significantly on the advancement of model inversion techniques. Currently, reconstructing the original training data from a language model – the core of DFSU – is computationally expensive and doesn’t scale well with model size. Future research prioritizes streamlining these inversion processes, focusing on algorithms that demand fewer computational resources and can efficiently handle the immense parameters of modern large language models. Improved scalability will not only accelerate the unlearning of sensitive information but also broaden the applicability of DFSU, allowing its deployment in real-world scenarios where resource constraints are a major consideration. Successfully addressing these efficiency challenges is therefore paramount to realizing the full potential of DFSU as a robust privacy-preserving technique.
The pursuit of increasingly capable large language models (LLMs) necessitates a parallel commitment to ethical considerations and user protection. Future development isn’t solely focused on maximizing performance metrics; a core objective is establishing LLMs that operate with inherent respect for individual privacy. This involves proactively designing systems that minimize data retention, resist malicious attempts to extract sensitive information, and adhere to principles of responsible AI. Such an approach isn’t simply about mitigating risks, but actively fostering trust-ensuring that these powerful tools benefit society without compromising fundamental rights or exacerbating existing inequalities. The ultimate vision is a new generation of LLMs where power and responsibility are inextricably linked, paving the way for widespread adoption and lasting positive impact.
The pursuit of data-free unlearning, as detailed within, echoes a fundamental truth about complex systems. The architecture itself, meticulously crafted, inevitably predicts its own vulnerabilities. This work, attempting to excise private information without revisiting the source, isn’t merely a technical feat, but a recognition that systems aren’t built-they grow, accruing memory and shadow. As Brian Kernighan observes, “Debugging is twice as hard as writing the code in the first place. Therefore, if you write the code as cleverly as possible, you are, by definition, not smart enough to debug it.” The elegance of DFSU lies in its acceptance of this imperfection; it doesn’t seek to erase the past, but to carefully sculpt the present, acknowledging that complete expungement is an illusion within the labyrinthine memory of a large language model.
What Lies Ahead?
The presented work, while a logical progression in the pursuit of data-free unlearning, merely shifts the locus of vulnerability. Removing memorized information without retraining on the original dataset is not erasure, but a carefully orchestrated forgetting. The success of DFSU, and methods like it, will inevitably be measured not by what it removes, but by the ghost of that data that lingers in the model’s remaining parameters-a subtle distortion of future predictions. Stability is merely an illusion that caches well.
Future efforts will likely focus on quantifying this residual memorization-developing metrics that move beyond simplistic recall tests and instead assess the model’s susceptibility to reconstruction attacks. The inherent tension between model utility and privacy will remain. A guarantee of complete unlearning is just a contract with probability; the real challenge isn’t achieving perfect privacy, but managing the acceptable level of exposure.
Ultimately, this line of inquiry reinforces a critical understanding: systems aren’t tools, they’re ecosystems. One does not build privacy into a large language model-one cultivates conditions for its ephemeral existence. Chaos isn’t failure-it’s nature’s syntax. The next iteration won’t be about more efficient parameter updates, but about embracing the inherent unpredictability of these complex systems.
Original article: https://arxiv.org/pdf/2601.15595.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- The Best Directors of 2025
- Transformers Under the Microscope: What Graph Neural Networks Reveal
- Silver Rate Forecast
2026-01-25 02:49