Author: Denis Avetisyan
A new framework leverages reinforcement learning to intelligently prioritize the most valuable data for training object detection models, significantly improving efficiency and accuracy.

This paper introduces MGRAL, a performance-guided reinforcement learning approach for active learning in object detection, optimizing sample selection based on mean Average Precision gains.
Efficiently training high-performance object detection models demands substantial labeled data, yet acquiring such datasets is often costly and time-consuming. This limitation motivates the work presented in ‘Performance-guided Reinforced Active Learning for Object Detection’, which introduces a novel active learning framework leveraging reinforcement learning to intelligently select the most informative samples for annotation. By optimizing sample selection using mAP improvement as a reward signal, the proposed method demonstrably enhances data efficiency and model performance. Could this paradigm shift in reinforcement learning-driven active learning unlock new frontiers in minimizing labeling effort across diverse computer vision tasks?
The Data Labyrinth: Why Object Detection Demands More Than Just Algorithms
Object detection, a fundamental task within the field of computer vision, consistently demands large quantities of meticulously labeled data to achieve reliable and accurate performance. The ability to identify and locate objects within images or videos isn’t simply a matter of algorithmic sophistication; it hinges on the system’s exposure to diverse examples where each object is clearly demarcated and categorized. This reliance on labeled data stems from the need for algorithms to learn the complex visual features – shapes, textures, colors – that define different object classes. Without sufficient, high-quality training data, even the most advanced models struggle to generalize to new, unseen images, leading to inaccurate detections and limiting their practical application. Consequently, the availability of labeled datasets often dictates the feasibility and effectiveness of object detection systems across various domains.
The performance of many object detection systems is fundamentally linked to the size and quality of their training data, yet acquiring this data presents a significant hurdle. Datasets like COCO and VOC, while widely used, demand extensive manual annotation – a process where humans meticulously identify and label objects within images. This annotation is not merely time-consuming; it’s also expensive, requiring skilled labor and substantial resources. Each bounding box drawn around an object, each pixel classified, contributes to the overall cost, which can quickly escalate when dealing with large-scale datasets or a diverse range of object categories. Consequently, the reliance on these massive, painstakingly annotated datasets restricts the development of object detection technologies in scenarios where resources are limited, or where the objects of interest are constantly changing, creating a persistent bottleneck in the field.
The demand for object detection systems extends beyond well-funded research labs, yet current reliance on extensively labeled datasets presents a significant obstacle for practical deployment. Resource-constrained environments – think wildlife monitoring with limited internet access, or disaster response requiring immediate analysis – often lack the infrastructure to collect and annotate the massive amounts of data typically required. Furthermore, the rapid emergence of novel object classes – such as new vehicle models or evolving fashion trends – necessitates constant retraining with updated labels, creating a perpetual cycle of costly annotation. This inability to adapt quickly and efficiently to new data or operate under limited resources severely restricts the broader application of object detection technologies, hindering progress in fields where real-time, adaptable visual understanding is critical.

The Oracle’s Insight: Selecting Data with Purpose
Active Learning represents a departure from traditional supervised machine learning approaches that rely on randomly sampled, fully labeled datasets. Instead of labeling data indiscriminately, Active Learning algorithms intelligently select the most valuable data points for annotation. This strategic selection minimizes the total annotation effort required to achieve a target performance level. The efficiency stems from focusing labeling resources on instances where the model is most uncertain or where labeling will yield the greatest improvement in model accuracy. Consequently, Active Learning can substantially reduce the cost and time associated with data labeling, particularly in scenarios involving large volumes of unlabeled data.
Active Learning methodologies improve model performance with reduced labeling costs by prioritizing data points that contribute the most to predictive accuracy. Traditional supervised learning relies on randomly sampled, labeled datasets, often requiring large volumes of annotated data. In contrast, Active Learning algorithms assess unlabeled data and select samples based on measures of uncertainty, such as prediction entropy or margin sampling, or by evaluating their potential informativeness via expected model change. Studies demonstrate that Active Learning can achieve performance levels equivalent to those of fully supervised learning, but with a fraction – often between 10% and 50% – of the labeled data required, leading to significant savings in time and resources.
Batch selection, a central problem in Active Learning, involves determining which unlabeled data points will yield the greatest model improvement when added to the labeled set. Strategies vary in complexity; some utilize uncertainty sampling – selecting instances where the model is least confident in its prediction – while others employ query-by-committee methods, leveraging disagreement among an ensemble of models. More sophisticated approaches consider representativeness – ensuring selected data covers the input space – or expected model change, estimating the impact of labeling a given instance on the overall model. The efficiency of batch selection directly impacts the number of labeling iterations required to reach a desired performance level, and algorithms must balance exploration – identifying novel, informative samples – with exploitation of already well-understood regions of the data distribution.
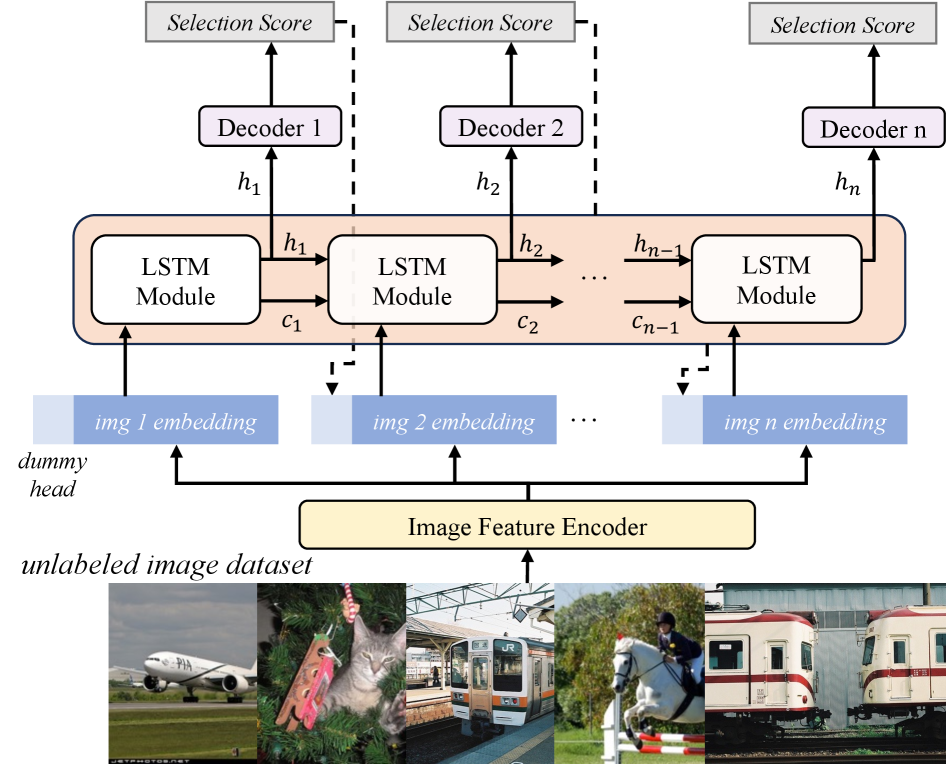
Guiding the Algorithm: A Reinforced Approach to Data Selection
Performance-guided Reinforced Active Learning (PG-RAL) employs a Reinforcement Learning (RL) framework to dynamically select data batches for labeling, thereby optimizing the data sampling process. Unlike traditional active learning methods that rely on heuristics or uncertainty sampling, PG-RAL formulates data selection as a sequential decision-making problem. An RL agent interacts with a dataset, choosing which samples to label based on the current state of the model and the predicted performance improvement. This allows the agent to learn a policy that maximizes information gain and minimizes labeling effort, effectively addressing the trade-off between exploration and exploitation inherent in active learning scenarios. The core principle is to iteratively refine the model with the most informative samples, leading to improved performance with fewer labeled instances.
The proposed active learning framework employs a Reinforcement Learning agent to dynamically select batches of unlabeled data for annotation. The agent is trained using a reward function directly correlated to model performance, specifically the change in Mean Average Precision (mAP) on a validation set. Empirical results demonstrate consistent performance gains over established active learning baselines on both the PASCAL VOC and COCO object detection datasets. This indicates the agent effectively learns a policy for data selection that maximizes improvements in object detection accuracy with each labeling iteration, thereby reducing the overall annotation effort required to achieve a target performance level.
Performance-guided Reinforced Active Learning addresses the exploration-exploitation dilemma in data sampling by strategically balancing the selection of informative, yet diverse, data points. The reinforcement learning agent is trained to prioritize samples that yield the greatest improvement in model performance, as measured by Mean Average Precision (mAP), while simultaneously minimizing the number of samples requiring manual annotation. This is achieved through a reward function that directly correlates labeling cost with performance gain, encouraging the agent to select batches that offer the most substantial benefit for the least expenditure of labeling resources. Consequently, the framework efficiently focuses annotation efforts on the most impactful data, leading to improved model accuracy with reduced labeling requirements compared to random sampling or uncertainty-based approaches.
Feature embedding representations are employed to improve the generalization capability of the Reinforcement Learning agent when selecting data for labeling. Instead of directly processing raw image data, the agent operates on feature vectors extracted from a pre-trained convolutional neural network. These feature embeddings capture high-level semantic information about object instances, allowing the agent to identify and prioritize samples that are representative of the broader data distribution, even if they exhibit variations in pose, scale, or occlusion. This abstraction from pixel-level details enables the agent to effectively transfer knowledge learned from previously labeled instances to unseen examples, leading to improved performance with fewer labeled samples.
Beyond the Static Dataset: Embracing Diversity and Unsupervised Insights
The incorporation of unsupervised learning methods serves as a crucial strategy for enhancing the diversity of data batches used in machine learning models. Techniques like clustering and dimensionality reduction allow algorithms to identify inherent structures within unlabeled data, subsequently enabling the selection of samples that better represent the overall data distribution. This approach actively combats biases often present in limited or imbalanced datasets, as it moves beyond simple random sampling to prioritize examples that offer unique information. By fostering greater batch diversity, models become more robust and exhibit improved generalization performance on unseen data, ultimately leading to more reliable and accurate predictions across a wider range of scenarios.
A critical challenge in machine learning lies in building models that perform reliably across varied, real-world conditions, and this is particularly acute when training data is scarce or unevenly distributed. Introducing diversity into the selection of training samples directly addresses this issue by mitigating the influence of inherent biases present in limited datasets. When a model is exposed to a broader range of examples, it learns to identify underlying patterns rather than memorizing specific instances, leading to improved generalization performance on unseen data. This approach is especially valuable in scenarios involving imbalanced datasets, where certain classes or characteristics are underrepresented; diverse sampling ensures that the model doesn’t disproportionately favor the majority class, thereby enhancing its ability to accurately classify or predict outcomes across all categories.
The selection of informative samples for training relies heavily on ensuring representation of the entire dataset, and recent work prioritizes this through the implementation of ‘Diversity’ metrics. These metrics quantify the dissimilarity between potential training samples, actively encouraging the selection of those that broaden the scope of the training batch and better reflect the underlying data distribution. By explicitly maximizing the diversity within each batch, the system avoids focusing solely on easily accessible or dominant examples, effectively mitigating biases and improving the model’s ability to generalize to unseen data. This approach is particularly crucial when dealing with large, unlabeled datasets where manual curation is impractical, allowing the system to autonomously identify and prioritize samples that contribute the most to overall model robustness and performance.
The reinforcement learning process benefited significantly from the implementation of a lookup table, designed to efficiently store and retrieve precomputed features; this optimization yielded a dramatic acceleration in training speed. Instead of repeatedly calculating feature representations during each iteration, the system now accesses them instantly from the table, resulting in a 1600x speedup. This innovation reduced the overall training time from a computationally intensive 4800 minutes to a remarkably swift 3 minutes when utilizing a cluster of four GTX 1080Ti GPUs, demonstrating a substantial improvement in efficiency and scalability for complex learning tasks.
The Adaptive Algorithm: Charting a Course for Dynamic Environments
The developed framework distinguishes itself by facilitating continual learning in object detection, a crucial capability for real-world deployment where static datasets quickly become outdated. Unlike traditional models requiring complete retraining with each new object class or environmental shift, this approach allows the system to incrementally adapt its knowledge. By selectively updating model parameters based on incoming data, the framework minimizes computational cost and avoids ‘catastrophic forgetting’ – the tendency of neural networks to lose previously learned information when exposed to new data. This adaptive capacity not only enhances efficiency but also ensures the model remains accurate and relevant over time, effectively bridging the gap between laboratory performance and dynamic, unpredictable real-world scenarios.
Investigations are shifting toward the integration of sophisticated reinforcement learning algorithms to enhance the adaptability of object detection models. Particular attention is being given to architectures leveraging Long Short-Term Memory (LSTM) networks, which excel at processing sequential data and making informed decisions over time. This approach allows the model to learn not just what to detect, but how to strategically adjust its detection parameters based on ongoing observations and feedback from the environment. By treating object detection as a sequential decision-making process, researchers aim to create systems that can proactively refine their performance, leading to more robust and efficient object recognition even in dynamic and unpredictable scenarios.
Refining data sampling strategies benefits greatly from accurately predicting how a model’s output will change with new data. Researchers are investigating the application of Gaussian Process Regression to model this ‘Expected Model Output Change’ with greater precision. This probabilistic approach allows the system to not only estimate the likely change, but also to quantify the uncertainty surrounding that prediction. By focusing data acquisition on areas where the model is most uncertain – as indicated by the Gaussian Process – the system can learn more efficiently and adapt to evolving environments with fewer samples. This targeted sampling minimizes redundant data collection and maximizes the information gain from each new observation, ultimately leading to a more robust and responsive object detection system.
The culmination of this research delivers object detection systems poised for practical deployment, demonstrating enhanced resilience and efficiency in dynamic real-world scenarios. These advancements aren’t achieved at the cost of computational overhead; the resulting model maintains a competitive size of just 33.0 million parameters, facilitating implementation on resource-constrained platforms. This balance between adaptability and efficiency signifies a substantial step toward reliable computer vision in ever-changing environments, promising broader applications ranging from autonomous navigation to automated inspection and beyond, where consistent performance relies on continuous learning and swift adjustment to novel conditions.
The pursuit of efficiency in object detection, as detailed in this work, feels less like engineering and more like coaxing order from inherent instability. This paper’s MGRAL framework, employing reinforcement learning to guide sample selection, exemplifies this. It’s a precarious balance – a spell cast with carefully chosen data points. As Yann LeCun once noted, “Everything unnormalized is still alive.” The authors attempt to normalize chaos, to tame the unpredictable nature of data through a reward signal based on mAP improvement. Yet, one suspects even the most refined policy gradient is merely delaying the inevitable entropy, a temporary truce between a bug and Excel, before the model inevitably meets the harsh reality of production data.
What Shadows Remain?
The conjuration presented here – MGRAL – offers a path to coaxing discernment from the digital golem. It’s a clever binding, rewarding the network for improvements in mean Average Precision, a metric as fickle as the favor of the gods. But the ritual is not without its residue. The framework, while efficient in sample selection, still clings to the assumption that ‘informativeness’ can be reliably quantified. The shadows lengthen around this premise; what subtle biases are baked into the very definition of ‘improvement’, and what unseen corners of the object detection space remain perpetually obscured?
Future efforts must confront the inherent chaos. Perhaps the true alchemy lies not in selecting the most informative samples, but in embracing the accidental. Could a policy gradient, deliberately seeded with noise, stumble upon insights a deterministic algorithm would miss? The current approach treats data efficiency as a virtue; yet, a certain amount of sacred offering – of wasted computation and mislabeled examples – may be necessary to appease the learning daemon.
Ultimately, the pursuit of perfect active learning is a fool’s errand. Every model is a broken spell, effective only until the conditions shift. The challenge, then, is not to eliminate error, but to anticipate its form. To build golems that fail gracefully, and to chart the inevitable decay with a detached, almost reverent, curiosity.
Original article: https://arxiv.org/pdf/2601.15688.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-24 18:26