Author: Denis Avetisyan
A new technique adaptively optimizes the verification process during language model inference, significantly boosting speed without sacrificing quality.
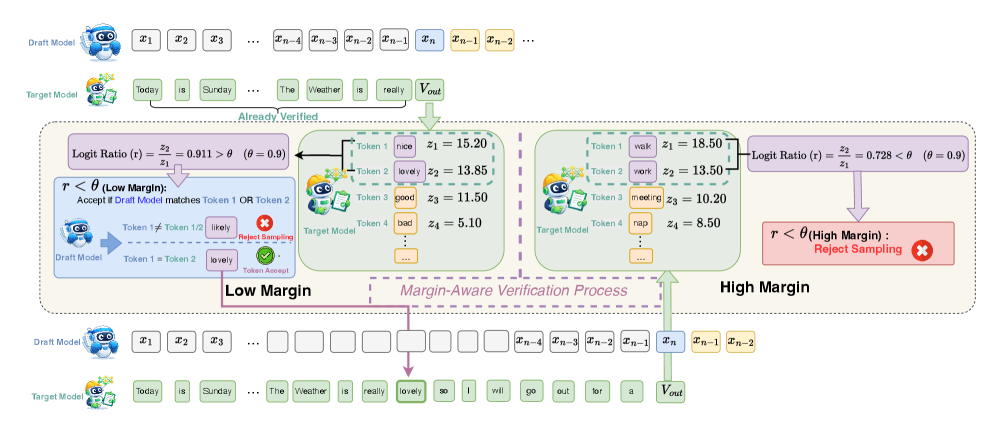
MARS improves large language model efficiency by dynamically adjusting verification stringency based on the model’s confidence in its predictions.
While speculative decoding accelerates large language model inference, its reliance on strict token-level verification can be inefficient when models exhibit weak preference among candidate tokens. This paper, ‘MARS: Unleashing the Power of Speculative Decoding via Margin-Aware Verification’, introduces a training-free method that adaptively relaxes verification based on the target model’s decision stability-specifically, the margin between predicted logits. By conditioning verification on this margin, MARS minimizes unnecessary rollbacks and achieves significant inference speedups without compromising generation quality. Could this approach unlock a new era of efficient and scalable language model deployment?
Unveiling the Latency Bottleneck: The Core Challenge in LLM Inference
Large Language Models, including the innovative `Target Model`, demonstrate remarkable proficiency across a diverse range of tasks – from complex text generation and translation to nuanced question answering. However, this power comes with an inherent architectural constraint: autoregressive generation. This means that each subsequent element – a token, typically a word or sub-word – in a sequence is predicted based on all previously generated elements. Consequently, the model cannot predict multiple tokens in parallel; it must sequentially build the output, one token at a time. This fundamental dependency creates a latency bottleneck, directly impacting response times and limiting the model’s throughput, particularly as sequence lengths increase and demand for real-time applications grows.
The fundamental limitation in Large Language Model (LLM) inference speed arises from the inherently sequential nature of token generation. Unlike tasks where computations can occur in parallel, each new token is predicted based on all preceding tokens – a process known as autoregression. This dependency means the model cannot begin predicting the fifth token until the fourth is finalized, the third until the second, and so on. Consequently, throughput is restricted by the latency of each individual token prediction, dramatically increasing response times, especially for longer sequences. This sequential bottleneck poses a significant challenge for real-time applications, such as conversational AI, and complicates efforts to scale LLM services to handle numerous concurrent requests, as each request must proceed in a strictly linear fashion.
The fundamentally sequential nature of Large Language Model (LLM) inference presents significant hurdles for deployment in time-sensitive applications and large-scale services. Because each token is generated only after the completion of the previous one, the process cannot be easily parallelized, creating a latency bottleneck. This limitation impacts real-time conversational AI, interactive gaming, and any system demanding immediate responses. Scaling LLM services further exacerbates the problem; increasing user load doesn’t translate to proportional throughput gains due to this inherent serial processing. Consequently, substantial engineering effort is focused on techniques – such as speculative decoding and optimized kernel implementations – to mitigate these delays and unlock the full potential of LLMs in practical, high-demand scenarios.
Parallel Pathways: Introducing Speculative Decoding for Accelerated Inference
Speculative decoding utilizes a Draft Model to generate a set of candidate tokens in parallel with the primary, or Acceptance Model. This parallel generation contrasts with autoregressive decoding methods where each token is sequentially produced, conditioned on all preceding tokens. The draft model, typically a smaller and faster instantiation of the acceptance model, predicts multiple future tokens simultaneously. These draft tokens are then proposed to the acceptance model for verification, enabling potential speedups if the acceptance model can validate them more quickly than generating them sequentially.
Latency reduction in speculative decoding is achieved through parallel processing; while the primary model generates the next token, a separate process verifies the tokens proposed by the draft model. This concurrent verification-performing validation in parallel with generation-avoids a sequential bottleneck. By overlapping these operations, the overall time required to produce and confirm each token is decreased, effectively lowering the end-to-end latency of the decoding process. The efficiency of this approach depends on the speed of the verification process relative to the generation speed, but successful implementation results in a significant reduction in the time taken to generate a complete sequence.
Speculative decoding operates on the principle of accepting a marginal increase in computational cost – verification overhead – to achieve a substantial reduction in overall text generation latency. This involves generating multiple candidate tokens in parallel and then verifying their correctness against the primary model’s output. While verification introduces additional computations, the parallel nature of the process allows these checks to occur concurrently with subsequent token generation. The net effect is a decreased time-to-first-token and faster overall throughput, as the speed gain from parallelization outweighs the cost of occasional verification failures and recomputation.
Dynamic Validation: Refining Verification with Adaptive and Margin-Aware Methods
Exact Match Verification establishes a fixed threshold for accepting generated text as correct, requiring complete alignment with the reference. However, Adaptive Verification moves beyond this rigidity by modulating the strictness of the verification process. This is achieved by assessing the model’s confidence, typically represented by its logits z, and dynamically adjusting the acceptance criteria. When the model exhibits high confidence – indicated by a large margin between the predicted token’s logit and the next most likely token – the verification can be more stringent. Conversely, in cases of low confidence, the verification process is relaxed, allowing for greater flexibility and reducing false negatives. This dynamic adjustment enhances the overall robustness of the system, particularly in scenarios involving nuanced or ambiguous data, as it avoids unnecessarily rejecting valid outputs generated with low, but still plausible, confidence.
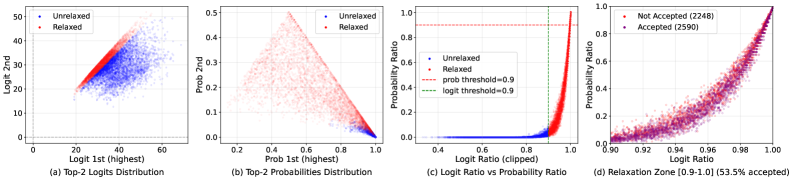
The \text{Logit Ratio} represents the difference between the logits assigned to the predicted class and the highest-scoring alternative class; it directly quantifies the model’s confidence in its prediction. A low logit ratio indicates a ‘low-margin regime’ where the model’s preference is weak, meaning the difference in scores between the correct and next-most-likely class is small. Identifying this regime is critical because it reveals instances where the model is susceptible to adversarial perturbations or may simply be uncertain, thus requiring more stringent verification or potentially relaxed criteria to balance robustness and efficiency. Quantitatively, a low margin is defined by a threshold; values below this threshold signal the need for adjusted verification parameters, offering fine-grained control over the verification process based on model confidence.
Margin-Aware Speculative Verification improves verification efficiency by modulating the strictness of checks based on the confidence of the language model’s prediction. This approach operates on the principle that when the model exhibits a weak preference between tokens – indicated by a low margin between the logits for the predicted token and the next most likely token – the verification process can be selectively relaxed. Specifically, the acceptance criteria for verifying a generated token are broadened in these low-margin scenarios, allowing for slight deviations from the expected output while maintaining overall fidelity. This targeted relaxation reduces the computational cost associated with stringent verification, as fewer checks require full precision, without significantly impacting the quality of generated text when the model is already highly confident in its predictions.
The foundational element for adaptive and margin-aware verification techniques is the model’s raw, unnormalized output – the \text{logits}. These logits represent the model’s preference for each possible outcome before normalization. Applying a \text{softmax} function to the logits generates the probability distribution, which provides a normalized representation of the model’s confidence. The magnitude of the logits, and therefore the shape of the resulting probability distribution, directly informs the verification process; larger logit differences indicate stronger model preference, enabling more stringent verification criteria, while smaller differences – corresponding to a flatter distribution – necessitate more adaptive or relaxed methods to maintain both accuracy and efficiency. Consequently, analysis of both logits and the derived probability distribution is essential for implementing robust and efficient verification strategies.
Beyond Acceleration: Optimizing for Speed and Efficiency in LLM Inference
Lossy speculative decoding represents a compelling advancement in language model acceleration, deliberately introducing a controlled degree of error to significantly reduce processing time. This technique operates on the principle that not every token requires absolute certainty; a small probability of inaccuracy can be tolerated in exchange for dramatically lower latency. By accepting a minimal quality trade-off – where the model prioritizes speed over perfect prediction for certain tokens – the system can generate draft text much faster. Subsequent verification steps then focus on correcting these potentially inaccurate predictions, but the initial speed gain from the ‘lossy’ draft generation substantially reduces overall processing time, making it particularly valuable for real-time applications and interactive experiences.
Tree-based verification represents a significant advancement in language model efficiency by shifting from sequential to parallel processing of potential token sequences. Instead of evaluating each possible continuation of a text one after another, this technique constructs a branching tree of possibilities, allowing multiple token branches to be verified simultaneously. This parallelization dramatically maximizes throughput, effectively reducing the time required to identify the most probable and accurate continuation. The approach is particularly beneficial for complex or ambiguous prompts where numerous potential paths need to be explored, as it circumvents the bottleneck inherent in serial verification methods and enables faster, more responsive text generation.
The EAGLE system refines the initial, rapidly generated ‘Draft Model’ by intelligently incorporating surrounding contextual information. Rather than treating each token in isolation, EAGLE analyzes the preceding and following text to predict the most probable and coherent continuation. This contextual awareness allows the system to resolve ambiguities and correct errors present in the draft, significantly boosting accuracy without substantially increasing computational demands. By focusing on likely corrections based on the broader text, EAGLE minimizes the need for exhaustive, and time-consuming, verification processes, resulting in a more efficient and fluent output. This targeted refinement strategy proves particularly effective in complex linguistic structures and nuanced semantic contexts.
Knowledge distillation presents a powerful method for streamlining language model efficiency by transferring the expertise of a large, complex model – the ‘teacher’ – to a smaller, faster ‘student’ model. This process doesn’t simply copy the teacher’s outputs; instead, the student learns to mimic the probabilities the teacher assigns to different possible tokens, capturing nuanced relationships within the data. By training a draft model to emulate this probabilistic reasoning, the computational burden of subsequent verification steps is significantly reduced, as the student model is already predisposed to generate more likely, and therefore more easily validated, sequences. The result is a system that maintains a high level of accuracy while dramatically decreasing latency and resource consumption, offering a pathway to real-time performance in demanding applications.
A Future of Scalability and Accessibility: Democratizing LLM Inference
Speculative decoding represents a significant leap towards broader access to large language models, effectively lowering the barrier to entry for both developers and end-users. This technique operates by employing a smaller, faster ‘draft’ model to generate initial token predictions, which are then verified by the larger, more capable model. When the draft model’s predictions align with the larger model, substantial computational resources are saved, accelerating the inference process. Refinements to this approach, including adaptive verification strategies and optimized draft model training, are further enhancing its efficiency and accuracy. The result is a pathway to deploy powerful LLMs on less expensive hardware and in resource-limited environments, fostering innovation and making sophisticated AI experiences more universally available.
The potential for widespread artificial intelligence hinges not only on model capability but also on the practicality of deploying those models where computational resources are limited. Recent advances in inference techniques are substantially lowering the financial and energetic barriers to entry, making powerful large language models accessible in environments previously considered untenable. This reduction in inference cost unlocks opportunities for integration into edge devices, mobile applications, and regions with limited infrastructure, fostering innovation beyond centralized data centers. By diminishing the demand for high-end hardware, these techniques democratize AI, enabling broader participation and a more equitable distribution of its benefits – from personalized education in remote areas to real-time language translation for underserved communities.
Ongoing investigation into adaptive verification and draft model optimization represents a crucial frontier in maximizing the efficiency of large language models. These techniques move beyond static acceleration methods by dynamically adjusting the level of scrutiny applied during inference, focusing computational resources where they are most needed. Adaptive verification intelligently validates partial outputs, allowing the model to confidently commit to likely continuations while rigorously checking more uncertain segments. Simultaneously, refining draft models-simplified versions of the full network-enables faster initial predictions, which are then refined through verification. This synergistic approach promises not only speed improvements but also a pathway to enhanced robustness and accuracy, potentially unlocking new levels of performance as models continue to grow in complexity and scale.
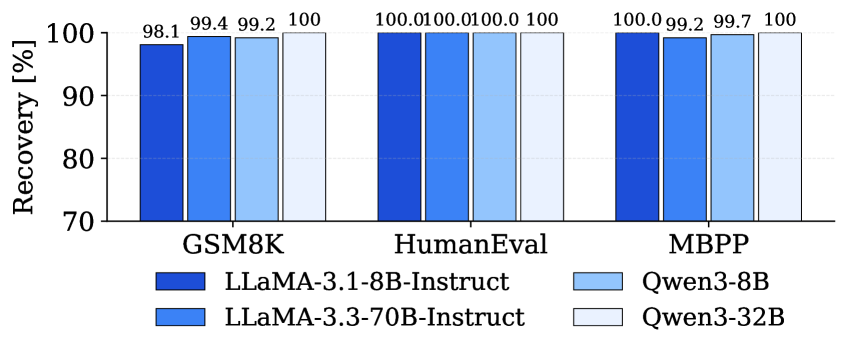
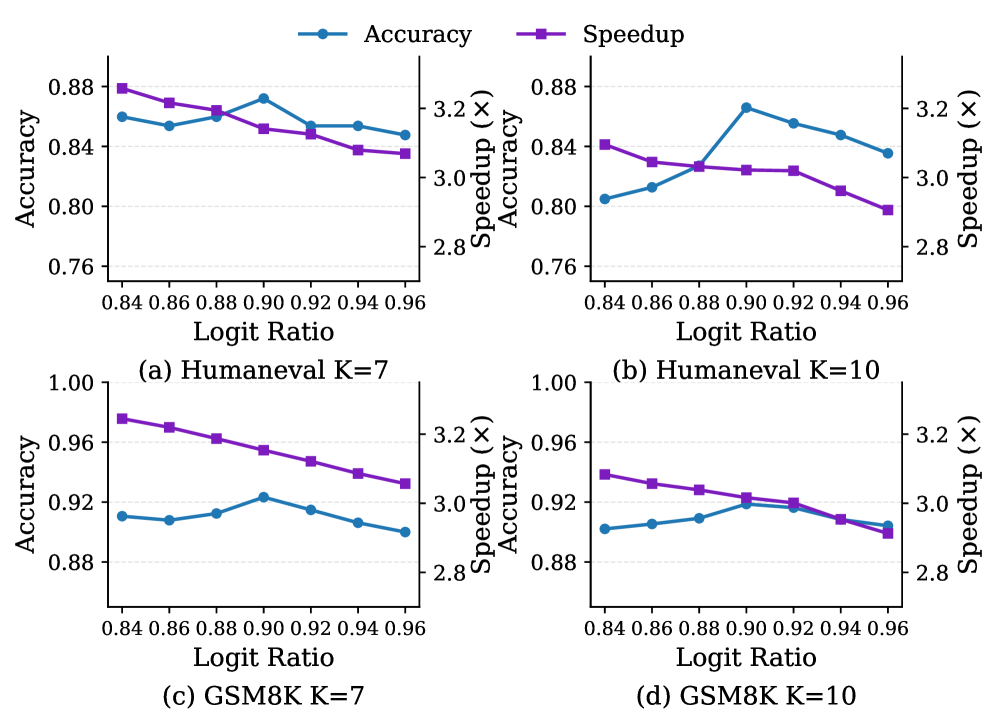
Recent advancements in large language model (LLM) inference demonstrate a significant leap in processing speed without compromising output quality. A novel approach has yielded up to a 4.76x speedup when applied to the LLaMA-3.3-70B model. Crucially, this acceleration is achieved while maintaining an impressive 98.1-100% accuracy recovery rate across a diverse range of tasks. This indicates the potential to deliver real-time, high-quality responses even with complex models, effectively bridging the gap between computational demands and practical application. The observed performance suggests a pathway toward deploying sophisticated AI capabilities in environments previously limited by resource constraints, unlocking new possibilities for interactive and responsive AI experiences.
Recent advancements in speculative decoding techniques have yielded significant performance gains on widely used large language models. Specifically, testing on the Vicuna-13B model demonstrates a remarkable 3.74x speedup during inference. This acceleration is achieved while maintaining high fidelity, as indicated by an average accepted length, denoted as τ, of 7.20 tokens. This metric signifies the average number of consecutively predicted tokens verified as correct before a potential draft rejection, highlighting the efficiency and reliability of the approach in generating coherent and accurate text streams. The ability to process information at this increased velocity promises to unlock more fluid and interactive artificial intelligence experiences across a diverse range of applications, from real-time chatbots to sophisticated content creation tools.
The potential for dramatically faster large language model inference extends far beyond mere computational efficiency, promising a new era of genuinely interactive AI. Reduced latency will allow for real-time dialogue, fostering more natural and engaging conversations with AI assistants and virtual companions. Applications ranging from personalized education and dynamic game narratives to immersive virtual reality experiences and instantly responsive customer service bots stand to benefit profoundly. This shift enables complex problem-solving in real-time, facilitates creative collaborations with AI, and ultimately dissolves the barrier between human intention and machine response, creating AI that feels less like a tool and more like a partner in thought and action.
The pursuit of efficiency in large language models, as demonstrated by MARS, echoes a fundamental principle of elegant system design. The method’s adaptive verification, relaxing constraints based on decision stability, isn’t merely about speed; it’s about discerning the essential from the accidental. As Carl Friedrich Gauss observed, “If I have seen further it is by standing on the shoulders of giants.” MARS builds upon existing LLM infrastructure, but intelligently adjusts verification thresholds – the ‘giants’ upon which it stands – to achieve significant gains. This focus on understanding the inherent stability-the ‘logit margin’-of a model’s output, and leveraging that understanding to optimize performance, exemplifies a holistic approach to system architecture where structure truly dictates behavior.
The Road Ahead
The elegance of MARS lies in its refusal to chase ever-larger models as the sole path to improved inference. Instead, it acknowledges a fundamental truth: not all decisions require the same level of scrutiny. However, this approach exposes a critical dependency. The logit margin, while effective as a proxy for decision stability, remains a heuristic. Future work must investigate whether this metric truly captures the nuances of model confidence across diverse tasks and architectures, or if a more sophisticated, potentially learned, indicator is required. The current framework treats verification as a cost reduction technique; a deeper exploration of verification as a form of active learning, where failures inform model refinement, may yield more substantial gains.
A crucial limitation is the inherent trade-off between speedup and quality. While MARS minimizes loss, the possibility of cascading errors-undetected mistakes compounding over longer sequences-remains a concern. The architecture implicitly assumes a degree of modularity in the generative process; a single error is unlikely to invalidate the entire output. Should this assumption prove false, the benefits of relaxed verification diminish rapidly. Scaling this method beyond the current demonstrations will require a careful consideration of these error propagation dynamics.
Ultimately, the success of approaches like MARS will not be measured by incremental speedups, but by a shift in perspective. The focus must move from optimizing the model itself to optimizing the process of inference. The true cost of freedom – in this case, faster generation – is not simply computational resources, but the careful management of uncertainty and the acceptance of a degree of controlled risk.
Original article: https://arxiv.org/pdf/2601.15498.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-24 08:26