Author: Denis Avetisyan
Researchers are pioneering methods to publicly validate the calculations of powerful financial artificial intelligence models without revealing sensitive data.
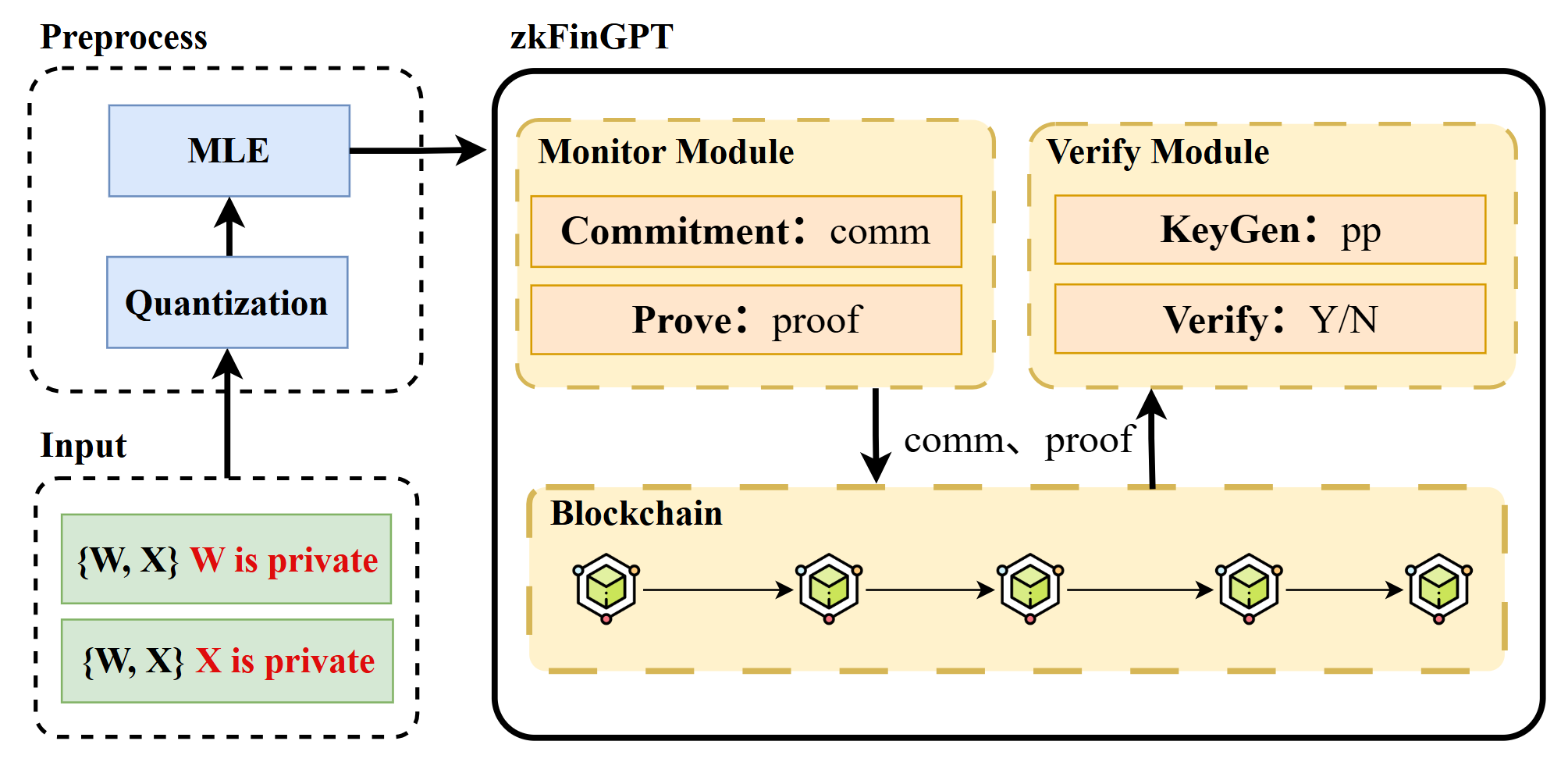
This paper introduces zkFinGPT, a novel scheme leveraging zero-knowledge proofs to verify financial GPT model inference while preserving data privacy and model confidentiality.
Despite the increasing adoption of financial Generative Pre-trained Transformers (FinGPT) for complex applications, verifying model legitimacy and safeguarding data privacy remains a critical challenge. This paper introduces ‘zkFinGPT: Zero-Knowledge Proofs for Financial Generative Pre-trained Transformers’, a novel scheme leveraging zero-knowledge proofs to publicly verify the inference process of these models while preserving both data confidentiality and intellectual property. Our approach enables trustless validation of financial predictions without revealing sensitive data or model weights, though initial experiments demonstrate substantial computational overhead – for example, generating a commitment file for the LLama3-8B model requires 531 seconds. Can these performance bottlenecks be overcome to facilitate the practical deployment of privacy-preserving FinGPT solutions?
Decoding the Algorithm: FinGPT and the Illusion of Trust
Financial markets are experiencing a surge in the deployment of FinGPT models, sophisticated algorithms designed to automate tasks and unlock previously hidden insights. These Generative Pre-trained Transformers, built upon the foundations of large language models, are being integrated into diverse applications – from algorithmic trading and portfolio optimization to risk management and fraud detection. The promise lies in their ability to process vast datasets, identify complex patterns, and generate predictions with unprecedented speed and efficiency. This rapid adoption is driven by the potential for significant cost savings, improved decision-making, and a competitive edge in increasingly volatile markets, signaling a fundamental shift in how financial institutions operate and analyze information.
The increasing deployment of FinGPT models, while offering potential benefits to financial analysis and automation, introduces significant challenges related to trust and reliability. These systems, often described as ‘black boxes’, operate with complex algorithms that obscure the reasoning behind their outputs, making it difficult to understand why a particular prediction or recommendation was generated. This lack of transparency hinders accountability, as identifying the source of errors or biases becomes problematic. Furthermore, the opacity of these models creates opportunities for malicious manipulation – whether intentional coding of biased data or external interference – potentially leading to flawed investment strategies or even market instability. Consequently, a critical need exists for developing methods to audit, interpret, and validate the outputs of FinGPT, ensuring responsible implementation and safeguarding against unforeseen consequences within the financial ecosystem.
The successful integration of FinGPT into financial systems hinges on robust methods for validating its outputs. Without verifiable legitimacy, these powerful models risk propagating inaccurate or even deliberately misleading information, potentially destabilizing markets and eroding investor confidence. Current research focuses on developing techniques – including explainable AI (XAI) and adversarial testing – to dissect the reasoning behind FinGPT’s predictions and identify vulnerabilities to manipulation. Establishing clear benchmarks for performance and transparency, alongside independent auditing processes, is paramount; these safeguards will not only foster trust among stakeholders but also ensure that FinGPT serves as a tool for informed decision-making, rather than a source of systemic risk. The pursuit of verifiable AI is, therefore, not merely a technical challenge, but a fundamental requirement for responsible innovation in the financial domain.
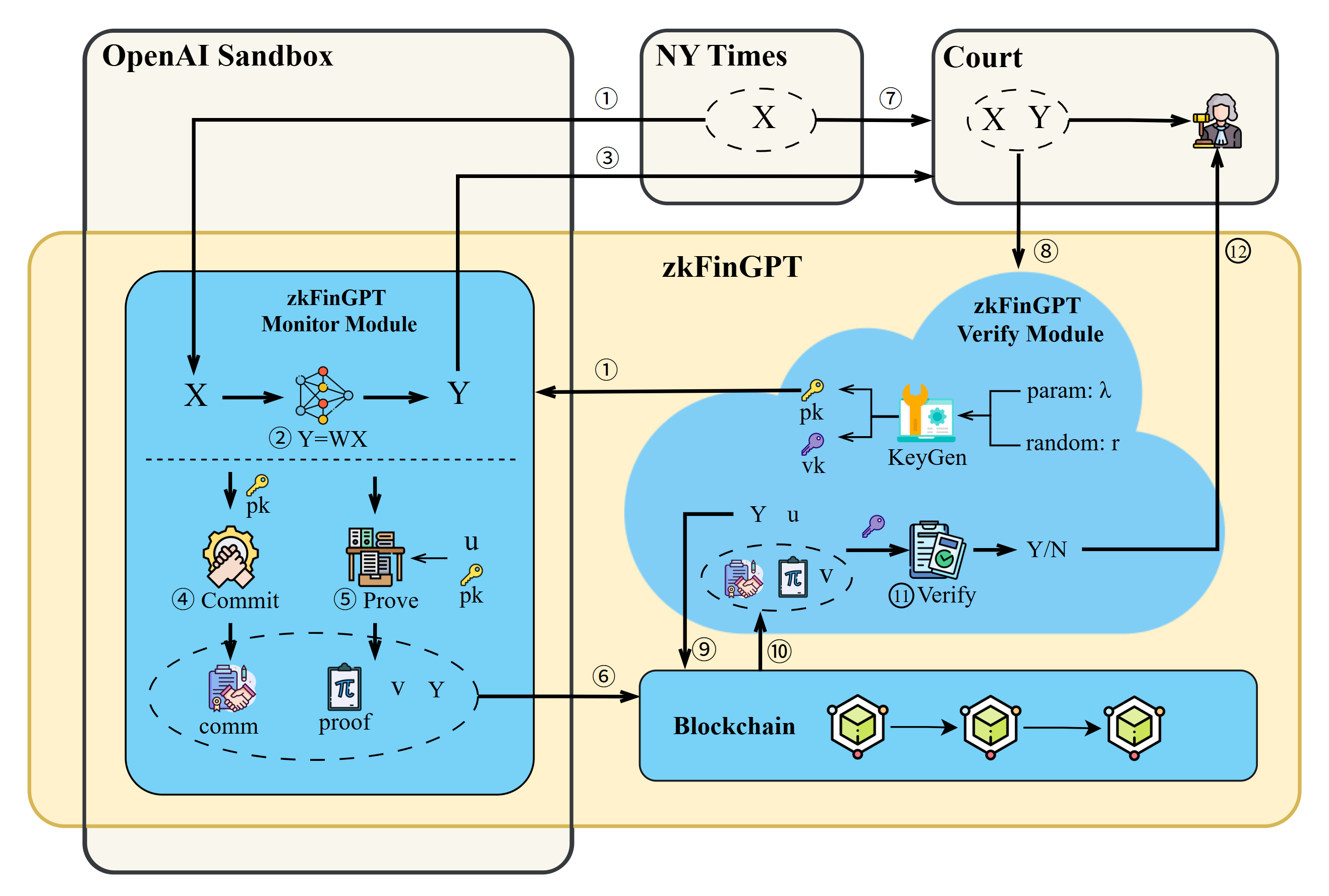
zkFinGPT: Proof of Integrity in a World of Opaque Algorithms
zkFinGPT implements a verification system for FinGPT outputs utilizing Zero-Knowledge Proofs (ZKP). This allows an external verifier to confirm the computational integrity of FinGPT’s results – that the model executed correctly and produced a valid conclusion – without requiring any knowledge of the model’s architecture, weights, or the input data used to generate the output. The core principle is to demonstrate the truth of a statement without revealing any information beyond that truth; in this context, it proves the correctness of the AI’s reasoning process without disclosing the data or model itself. This is achieved through a cryptographic protocol where the prover (FinGPT) convinces the verifier of the output’s validity without sharing the underlying computational steps.
Verification of FinGPT’s outputs is achieved through a process where external parties can confirm computational correctness without requiring access to the underlying model weights, architecture, or training data. This is accomplished by submitting a proof alongside the FinGPT output, allowing validators to independently assess the validity of the result. The proof demonstrates that the computation was performed correctly according to the model’s defined logic, without revealing any sensitive information about the model itself. This separation of verification from access to internal model details is a core tenet of the system, ensuring both security and trust in the AI’s conclusions.
The Zero-Knowledge Proof (ZKP) system employed by zkFinGPT utilizes the KZG Commitment Scheme to achieve both privacy and integrity. The KZG Commitment Scheme allows a prover to commit to a value without revealing it, and subsequently, prove knowledge of that value without disclosing it. Specifically, it involves polynomial commitments; a polynomial is committed using a cryptographic hash function, and proofs demonstrating evaluations of the polynomial at specific points can be generated without revealing the polynomial itself. This ensures that FinGPT’s outputs are verifiable – proving the model followed correct procedures – while simultaneously protecting the confidentiality of its underlying data and parameters. The scheme’s cryptographic properties guarantee that any attempt to forge a valid proof for an incorrect output will be computationally infeasible, thereby establishing data integrity.
Beneath the Surface: The Cryptographic Foundation of zkFinGPT
The KZG Commitment Scheme, crucial to the functionality of zkFinGPT, relies on operations performed within a Finite Field. A Finite Field, denoted as GF(p) where p is a prime number, is a set of a finite number of elements with defined addition and multiplication operations that satisfy specific mathematical properties. This construction ensures that all arithmetic operations remain within a bounded range, preventing unbounded growth of values and mitigating potential security vulnerabilities. Operating within this defined space allows for consistent and verifiable computations, essential for the commitment and subsequent verification processes within the scheme. The use of a Finite Field is not simply a mathematical convenience; it is a fundamental requirement for the cryptographic security of KZG commitments.
The BLS12-381 elliptic curve is a specific instance of a pairing-friendly elliptic curve utilized within the KZG commitment scheme due to its performance characteristics and established security profile. This curve is defined over a finite field and offers a balance between computational efficiency in performing cryptographic operations – specifically pairing calculations – and resistance to known attacks. The choice of BLS12-381 is predicated on its 381-bit field size, which provides a sufficient security margin while remaining computationally tractable. Its pairing-friendly nature is crucial for the KZG scheme, as pairings are fundamental to verifying the commitments and ensuring the integrity of the committed data. The curve’s parameters are standardized, facilitating interoperability and widespread adoption within cryptographic implementations.
The Sumcheck protocol is a crucial interactive protocol used within Zero-Knowledge Proofs (ZKPs) to verify computations performed on committed values without revealing those values to the verifier. It operates by having the prover demonstrate knowledge of a solution to a polynomial equation, while only exchanging values of the polynomial evaluated at randomly chosen points with the verifier. This process is iterative; the verifier sends new random points, and the prover responds with corresponding polynomial evaluations. By repeating this exchange, the verifier can gain high confidence that the prover possesses a valid solution, all without learning the actual values of the variables involved. The efficiency of Sumcheck is enhanced when applied to low-degree polynomials, making it well-suited for use with commitment schemes like KZG, where commitments encapsulate polynomial evaluations.
The Cost of Trust: Performance Trade-offs and Future Horizons
The implementation of zkFinGPT, while enhancing privacy and verifiability in large language models, introduces inherent computational overhead, primarily manifested in proving and commitment times. Current experimentation with the LLama3-8B model reveals a proving duration of 620 seconds – the time required to generate a succinct, verifiable proof – and a commitment time of 531 seconds, reflecting the time needed to create the initial commitment. This overhead is further quantified by the 7.97 MB commitment file size, which represents the data necessary for verification. The proving time scales linearly with the number of layers in the GPT model O(N), while the commitment time scales with the model size O(M), indicating that larger, more complex models will demand proportionally greater computational resources for secure and verifiable operation.
Recent evaluations utilizing the LLama3-8B large language model reveal concrete performance metrics for zkFinGPT’s zero-knowledge proof implementation. The system requires approximately 620 seconds to generate a proof, demonstrating the computational effort involved in verifying the model’s operations. Establishing a commitment – essentially creating a secure, verifiable snapshot of the model’s state – takes 531 seconds. Critically, verification of these proofs, allowing a third party to confirm the model’s integrity without accessing the model itself, is remarkably swift, completing in just 2.36 seconds. These timings highlight a trade-off between the time-intensive proof and commitment stages and the efficient verification process, suggesting potential optimizations could focus on accelerating the initial computational burden while maintaining rapid verification speeds.
The implementation of zkFinGPT necessitates a commitment phase where the large language model’s parameters are secured, resulting in a considerable data overhead. For the LLama3-8B model, this commitment manifests as a 7.97 MB file size – a substantial volume representing the data required to ensure verifiable computation. This overhead stems from the need to cryptographically commit to the model’s weights, allowing for later verification of its integrity and the authenticity of any generated outputs. While this commitment ensures trust and accountability, it also highlights a key trade-off: increased computational resources are required for storage and transmission, posing practical considerations for deployment, particularly in bandwidth-constrained environments or applications demanding real-time performance. Future research may focus on compression techniques or alternative commitment schemes to mitigate this data overhead without compromising security or verifiability.
The emergence of large language models has intensified concerns surrounding copyright infringement, as AI-generated content can inadvertently reproduce or closely resemble existing copyrighted material. zkFinGPT offers a novel verification mechanism to address this challenge by cryptographically proving the provenance and authenticity of generated text. This technology enables a verifiable audit trail, demonstrating whether a model was trained on specific datasets or if its outputs are substantially derived from copyrighted sources. By establishing a robust and transparent system for content verification, zkFinGPT provides crucial support for legal frameworks seeking to define liability and protect intellectual property in the age of generative AI, potentially mitigating risks for both developers and users of these powerful technologies.
The computational demands of zkFinGPT scale predictably with model architecture, offering insights into resource allocation for future iterations. Specifically, the time required to generate a cryptographic proof – essential for verifying AI computations – exhibits a linear relationship with the number of layers N within the GPT model, denoted as O(N). Similarly, the time needed to create the commitment – the data representing the model’s state – scales linearly with the model’s size M, measured in billions of parameters, as O(M). This understanding is crucial because it suggests that increasing model depth will directly impact proving time, while expanding model size will increase the data overhead. Consequently, optimizations targeting layer-wise computations or model compression techniques will be vital for deploying zkFinGPT with larger, more complex AI models.

The pursuit of zkFinGPT echoes a fundamental principle: understanding through deconstruction. This scheme, by publicly verifying the inference process with zero-knowledge proofs, doesn’t simply use a system-it exposes its inner workings for rigorous examination. One recalls Donald Davies’ observation, “The best way to predict the future is to create it.” zkFinGPT doesn’t passively accept the limitations of current financial models or privacy concerns; it actively reshapes the landscape by building a verifiable, privacy-preserving alternative. The commitment to verifiable computation, facilitated by techniques like the KZG commitment scheme, isn’t about imposing order, but about illuminating the architecture beneath the surface – mirroring the unseen connections within complex systems.
Beyond Verification: What Lies Ahead?
zkFinGPT establishes a functional demonstration – a verifiable computation. But the true challenge isn’t simply proving a financial model’s output, it’s understanding what that verification reveals about the model itself. The current framework treats the model as a black box, successfully audited but still opaque. Future work must dissect this box, using zero-knowledge proofs not just for validation, but for reverse engineering. What biases are hidden within the weights? What assumptions are baked into the architecture, and how do they manifest in financial predictions? The current system confirms that a computation happened, not why it happened the way it did.
The reliance on KZG commitment schemes, while presently efficient, introduces a dependency on trusted setup. Eliminating this dependency-achieving universal and trustless verification-is not merely an optimization; it’s a philosophical imperative. It’s a rejection of inherent authority, a demand for absolute, demonstrable truth. Furthermore, scaling these proofs to truly complex financial models-those capable of anticipating systemic risk or modeling derivative pricing with nuance-remains a significant hurdle. The computational cost of proving such models will inevitably push the boundaries of current cryptographic hardware.
Ultimately, zkFinGPT’s significance lies not in its immediate applications, but in its demonstration of principle. It proves that computation can be divorced from trust. The next phase requires exploring the limits of that separation, pushing towards a future where financial models are not just verifiable, but fundamentally understandable through the very tools used to validate them. The goal isn’t to build better models, but to build models that reveal themselves.
Original article: https://arxiv.org/pdf/2601.15716.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Spotting the Loops in Autonomous Systems
- Gold Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-24 04:59