Author: Denis Avetisyan
A new approach combines image blending with reinforcement learning to automatically generate explanations and improve the accuracy of deepfake detection systems.
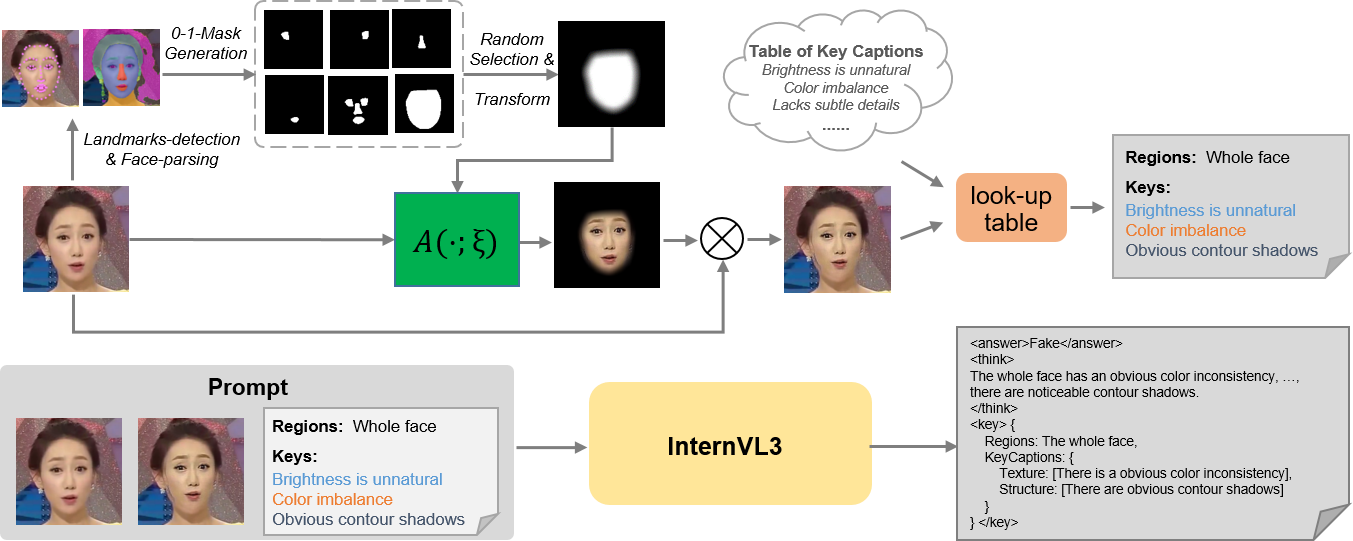
This research introduces a framework leveraging reinforcement learning and self-blended images to enhance deepfake detection, address reward sparsity, and enable forgery localization.
Despite advances in deepfake detection, a critical gap remains in producing explainable outputs alongside robust performance, particularly given the scarcity of richly annotated datasets. This limitation motivates the work presented in ‘Explainable Deepfake Detection with RL Enhanced Self-Blended Images’, which introduces a novel framework leveraging self-blended images and reinforcement learning to automatically generate Chain-of-Thought (CoT) data for improved forgery localization and detection accuracy. By addressing reward sparsity through a tailored reward mechanism, the proposed approach achieves competitive results across multiple benchmarks while reducing reliance on costly manual annotation. Could this automated data generation pipeline unlock new possibilities for explainable AI in increasingly sophisticated visual manipulation scenarios?
The Erosion of Verifiable Reality: A Deepfake Crisis
The rapid increase in manipulated media, commonly known as “deepfakes” and other forms of synthetic content, represents a growing crisis for societal trust and the reliability of information. This proliferation isn’t simply about technological trickery; it erodes the very foundation upon which informed decisions are made, both individually and collectively. Increasingly realistic forgeries challenge the authenticity of visual and auditory evidence, making it difficult to distinguish between genuine and fabricated realities. The consequences extend beyond simple misinformation, potentially influencing elections, damaging reputations, and even inciting social unrest. Because verifying the provenance of digital content becomes ever more complex, a climate of distrust is fostered, where legitimate information is questioned alongside the false, ultimately undermining public discourse and institutional credibility.
Current methods for identifying manipulated media, such as analyzing pixel inconsistencies or searching for telltale digital artifacts, are increasingly challenged by advancements in generative artificial intelligence. Forgery techniques, once reliant on clumsy editing and obvious distortions, now leverage sophisticated algorithms capable of creating remarkably realistic alterations – and entirely fabricated content – that seamlessly blend with authentic material. These ‘deepfakes’ often evade detection by exploiting the limitations of existing forensic tools, which were designed to identify more rudimentary forms of manipulation. The speed at which these generative models are evolving creates a constant arms race, demanding continual innovation in detection strategies to maintain any semblance of reliable verification – a task proving exceptionally difficult as the technology becomes more accessible and refined.
Reinforcement Learning: An Adaptive Approach to Forgery Detection
Reinforcement Learning (RL) presents a viable alternative to traditional supervised learning for deepfake detection by framing the problem as an agent learning to identify forgeries through interaction with an environment. Unlike supervised methods requiring extensive labeled datasets, RL enables training via reward signals derived from the agent’s actions, potentially enhancing generalization to unseen manipulations and improving robustness against adversarial attacks. This approach allows the detector to actively learn optimal detection strategies, adapting to the evolving landscape of deepfake technology. The key advantage lies in the potential to train detectors that don’t simply memorize training data, but rather develop a deeper understanding of forgery characteristics, leading to more reliable performance in real-world scenarios.
Effective Reinforcement Learning (RL) algorithms typically require dense reward signals to efficiently learn optimal policies; however, many real-world applications, including binary classification tasks such as deepfake detection, inherently provide only sparse rewards. In deepfake detection, a standard approach yields a reward of +1 for correct classification and 0 for incorrect classification, providing limited feedback on how the model is performing or which specific features contribute to errors. This scarcity of informative signals makes it difficult for the RL agent to explore the solution space and converge on an effective detection strategy, as the agent receives little guidance beyond a final correctness assessment. Consequently, techniques are needed to generate more granular and informative reward signals to facilitate effective learning in this sparse-reward environment.
Group Relative Policy Optimization (GRPO) addresses the challenge of sparse reward signals in reinforcement learning for deepfake detection by framing the problem as a relative policy optimization. Traditional RL methods struggle when rewards are infrequent, hindering effective training; GRPO mitigates this by learning a policy that outperforms a baseline policy, rather than directly maximizing an absolute reward. This is achieved through a modified policy gradient update that focuses on the difference in expected returns between the current policy and the baseline. The baseline policy is maintained as a running average of previously successful policies, allowing the agent to learn from incremental improvements even with limited positive rewards. This relative comparison facilitates learning in scenarios where identifying correct classifications is infrequent, but distinguishing better actions from worse ones is possible, improving the stability and efficiency of the reinforcement learning process.
Forgery-Conditioned Keywords enhance reward signal generation in reinforcement learning-based deepfake detection by focusing on localized forgery attributes. Rather than relying solely on binary classification accuracy, the system identifies and evaluates regional fields within the model’s response and compares them to corresponding ground truth regions. The precision of the forgery localization reward is improved through the use of Jaccard\ Similarity, which quantifies the overlap between the predicted and actual regional fields. This metric calculates the size of the intersection divided by the size of the union of the two sets, providing a granular assessment of localization accuracy and enabling the RL agent to learn more effectively from subtle forgery manipulations.
Augmenting Reality: Synthetic Data for Robust Detection
The FaceForensics++ dataset, while a significant contribution to deepfake detection research, presents limitations regarding the breadth of manipulated content available for training. This dataset comprises approximately 1,000 short videos of 48 subjects, manipulated using four distinct forgery techniques: Deepfakes, Face2Face, FaceSwap, and NeuralTextures. While offering a controlled environment for evaluation, the relatively small scale and limited diversity of manipulations within FaceForensics++ can hinder the generalization capability of trained deepfake detectors when applied to real-world scenarios exhibiting a wider range of forgery methods and quality levels. Consequently, reliance solely on this dataset may lead to models that overfit to the specific characteristics of the manipulations present within it, reducing their effectiveness against novel or unseen deepfake techniques.
Synthetic data generation, specifically employing techniques like Semantic Blending and Interpolation (SBI), addresses limitations in existing datasets such as FaceForensics++ by creating augmented training examples. SBI operates by combining features from source and target images to produce novel forged samples. This process increases the volume of training data available for deepfake detection models and, crucially, improves their ability to generalize to unseen forgery types. By exposing the model to a wider range of manipulated images during training, SBI-generated data enhances robustness against variations in forgery techniques not present in the original, limited datasets. The effectiveness of SBI relies on the controlled manipulation of image features to create realistic and diverse forged examples.
The blending weight, denoted as α, is a critical parameter within the Semantic Blending and Interpolation (SBI) technique for synthetic data generation. This value controls the degree to which the source and target images are combined during forgery creation. Lower α values result in subtle manipulations, preserving more characteristics of the original source image, while higher values introduce more significant alterations. Precisely controlling α across a range-typically between 0 and 1-is essential for generating a diverse set of forged images that represent a realistic spectrum of manipulation intensities. Insufficient variation in α can lead to a dataset biased towards specific forgery types, limiting the generalization capability of deepfake detection models trained on this data.
Synthetic data generation utilizes augmentation parameters applied to multiple image factors to increase the diversity of the training dataset. These parameters – including hue, lighting, clarity, contrast, scaling, and translation – are each applied at three intensity levels: mild, moderate, and severe. This tiered approach introduces a range of manipulated image characteristics, creating variations that more closely resemble the complexity of real-world forgeries. The resulting dataset, enriched with these augmented samples, improves the robustness of deepfake detection models by exposing them to a wider spectrum of potential manipulation artifacts and enhancing their generalization capability to unseen forged images.
Beyond Detection: Towards Interpretable and Localized Forgery Analysis
The increasing sophistication of deepfakes demands not only accurate detection but also an understanding of why a piece of media is flagged as manipulated. Recent advancements explore the application of Multimodal Large Language Models (MLLMs) to address this need, moving beyond simple binary classifications. These models, capable of processing both visual and textual information, can generate detailed reasoning descriptions explaining their deepfake assessments. Instead of merely identifying a forgery, an MLLM might articulate that a video is suspect due to inconsistent blinking patterns, unnatural lighting, or discrepancies between audio and lip movements. This capacity for explanation is crucial for building trust in detection systems, facilitating forensic analysis, and ultimately empowering individuals to critically evaluate the authenticity of digital content. The ability to articulate the ‘evidence’ behind a decision drastically improves interpretability, transforming deepfake detection from a ‘black box’ into a transparent and accountable process.
The quality of explanations generated by multimodal large language models for deepfake detection is significantly enhanced through Chain-of-Thought (CoT) annotation. This technique involves training the model, such as InternVL3-38B, not just to identify a deepfake, but to articulate the reasoning behind its decision – essentially, to ‘think step-by-step’ and verbalize that process. By providing annotated examples that demonstrate this reasoning – highlighting inconsistencies in lighting, unnatural facial features, or illogical shadows – the model learns to produce more detailed and human-understandable justifications for its classifications. This isn’t merely about achieving higher accuracy; CoT annotation fosters interpretability, allowing users to assess the model’s logic and build greater trust in its findings, as well as pinpointing the specific visual cues driving the deepfake determination.
The capacity of multimodal large language models to detect and explain deepfakes receives a significant boost through supervised fine-tuning with visual question answering. This process doesn’t merely teach the model to identify forgeries, but to reason about them. By posing questions requiring analysis of image content – such as “What inconsistencies are present in the reflection?” or “Does the lighting match the shadows?” – the model learns to connect visual cues with logical explanations. This focused training refines the model’s ability to articulate why an image is deemed a forgery, moving beyond simple classification to a more transparent and insightful assessment. Consequently, the enhanced reasoning capabilities enable more reliable deepfake detection and provide valuable context for understanding the model’s decision-making process, which is crucial for building trust in these systems.
Beyond simply identifying a deepfake, pinpointing where manipulation occurred is crucial for building trust and understanding the nature of the forgery. Recent advancements leverage forgery localization techniques, employing metrics like Jaccard Similarity to precisely highlight the altered regions within an image. This process doesn’t just offer a binary ‘fake’ or ‘real’ verdict; instead, it delivers granular insights by creating a visual map of the manipulated areas. A high Jaccard Similarity score between the predicted forgery mask and the ground truth indicates accurate localization, allowing for detailed analysis of the specific changes introduced by the deepfake algorithm. This capability is invaluable not only for forensic investigations but also for developing more robust detection methods that focus on the most vulnerable image components, ultimately enhancing the reliability and interpretability of deepfake detection systems.
The pursuit of robust deepfake detection, as detailed in this framework, echoes a fundamental principle of algorithmic elegance: provability. The integration of reinforcement learning with self-blended images isn’t merely about achieving higher accuracy; it’s about constructing a system whose reasoning-its ‘Chain of Thought’ data generation-can be systematically verified. Fei-Fei Li aptly stated, “AI is not about replacing humans; it’s about augmenting them.” This research embodies that sentiment, using AI to enhance human discernment by providing a more transparent and verifiable forgery localization process, ultimately moving beyond empirical ‘working’ solutions toward demonstrably correct ones. The reward shaping component, in particular, exemplifies the necessity of a precisely defined objective function-a mathematical purity-to guide the learning process.
What Lies Ahead?
The presented synthesis of reinforcement learning and generative blending, while demonstrating empirical gains in deepfake detection, merely shifts the fundamental problem. The current reliance on reward shaping, however cleverly devised, introduces a fragility inherent in any heuristic. A truly robust system demands a reward function derived from first principles – a formalization of perceptual invariants that define ‘real’ versus ‘synthetic’. Absent this, the algorithm remains susceptible to adversarial examples crafted to exploit the shaped reward, a limitation that, while mitigated by the blending process, is not fundamentally resolved.
Further investigation must address the computational complexity inherent in extending this framework to high-resolution video. The current approach, dependent on iterative blending and reinforcement, scales poorly. Asymptotic analysis reveals a potential bottleneck in the generation of CoT data; a more efficient algorithm for distilling perceptual knowledge, perhaps leveraging information-theoretic bounds, is critical. The promise of multimodal large language models remains largely untapped; integrating such models not as feature extractors, but as formal verifiers of image provenance, presents a potentially fruitful avenue of research.
Ultimately, the pursuit of ‘explainable’ deepfake detection is a philosophical exercise disguised as engineering. The goal is not simply to identify forgeries, but to articulate the criteria by which authenticity is judged. A system that correctly classifies a deepfake without elucidating why it is incorrect offers little genuine insight. The true test lies not in achieving higher accuracy, but in constructing a formal, provable model of visual truth.
Original article: https://arxiv.org/pdf/2601.15624.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- Silver Rate Forecast
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- The 10 Most Underrated Jim Carrey Movies, Ranked (From Least to Most Underrated)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
2026-01-23 07:03