Author: Denis Avetisyan
A new approach explores automating the scientific process by letting artificial intelligence generate and test its own hypotheses.
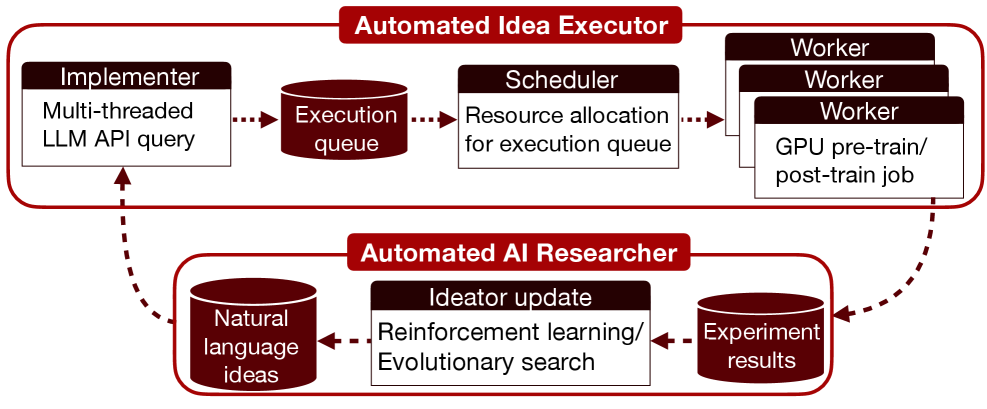
This paper investigates execution-grounded automated AI research, leveraging LLM-driven ideation, evolutionary search, and reinforcement learning to build an automated executor for evaluating novel AI concepts.
While large language models excel at generating hypotheses, their outputs often lack practical validation in complex scientific endeavors. This work, ‘Towards Execution-Grounded Automated AI Research’, investigates automating the full research cycle by constructing an automated executor capable of implementing and evaluating LLM-generated ideas in the domains of language model pre-training and post-training. We demonstrate that evolutionary search, guided by execution feedback, can yield significant performance gains-outperforming existing baselines-though reinforcement learning struggles with maintaining diverse exploration. Can this approach unlock a new paradigm for AI-driven scientific discovery, and what algorithmic innovations are needed to overcome the limitations of current learning paradigms within automated execution loops?
The Allure and Peril of Advanced Language Models
Large Language Models (LLMs) signify a profound advancement in artificial intelligence, exceeding previous capabilities in processing and generating human-like text. These models, trained on massive datasets, don’t merely string words together; they demonstrate a nuanced understanding of grammar, context, and even style, enabling them to perform tasks ranging from composing coherent articles and translating languages to writing different kinds of creative content and answering complex questions. The scale of these models – often containing billions of parameters – allows them to capture intricate patterns within language, resulting in outputs that are often indistinguishable from human writing. This leap in natural language processing isn’t simply about improved accuracy; it represents a shift towards AI systems capable of engaging with and generating text in ways previously thought exclusive to human cognition, opening doors to novel applications across numerous fields.
Despite their impressive capabilities, large language models are demonstrably flawed in ways that demand careful consideration. These models frequently “hallucinate,” generating plausible-sounding but factually incorrect statements, a consequence of their training on vast datasets where truth isn’t always prioritized. More concerningly, these systems can amplify existing societal biases present within those datasets, perpetuating and even exacerbating harmful stereotypes related to gender, race, and other sensitive attributes. This isn’t a matter of intentional malice, but rather a reflection of the data they learn from; the models statistically reproduce patterns, meaning prejudiced language and unfair associations can become embedded within their output, presenting significant ethical and practical challenges for deployment in real-world applications.
The challenge of ‘alignment’ represents a fundamental hurdle in the development of large language models, extending beyond mere technical proficiency. These models, trained on vast datasets reflecting existing human communication, can readily generate text that is grammatically correct and contextually relevant, yet may not inherently reflect desirable values or intentions. Ensuring alignment requires more than simply preventing harmful outputs; it demands proactive strategies to imbue these systems with nuanced understandings of ethics, fairness, and truthfulness. Current research explores methods like reinforcement learning from human feedback and constitutional AI – where models are guided by a set of pre-defined principles – but achieving robust alignment remains a complex undertaking, as human values themselves are often subjective and culturally dependent. Ultimately, successful alignment is crucial for realizing the full potential of these powerful tools while mitigating the risk of unintended consequences and ensuring they serve humanity’s best interests.
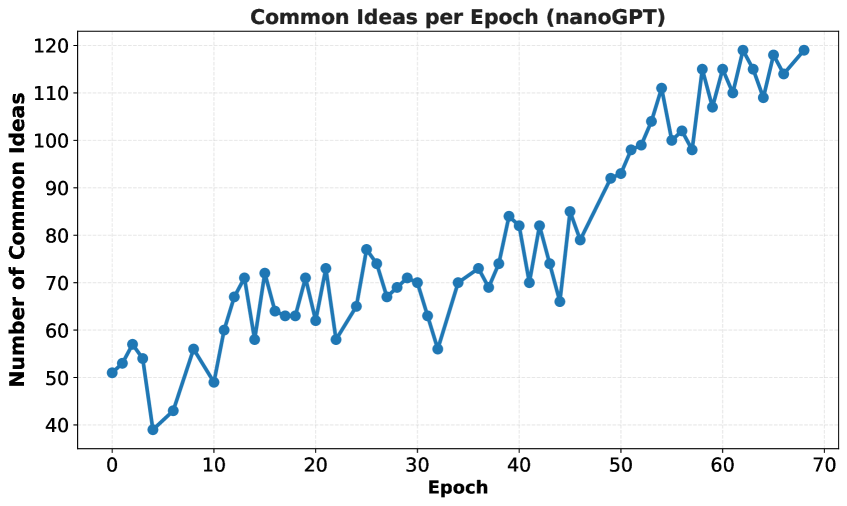
Strategies for Directing Model Behavior
Instruction tuning is a supervised learning technique used to align large language model outputs with human expectations. This process involves fine-tuning a pre-trained model on a dataset of prompts and corresponding desired responses. The prompts are typically formulated as instructions, guiding the model towards specific behaviors or formats. By iteratively exposing the model to examples of correct responses to varied instructions, instruction tuning refines the model’s ability to interpret prompts and generate outputs that are helpful, harmless, and honest. Datasets used for instruction tuning often comprise examples sourced from human demonstrations, labeled data, or generated through programmatic means, and are crucial to the effectiveness of the technique.
Reinforcement Learning from Human Feedback (RLHF) leverages human preferences to refine language model outputs beyond initial instruction tuning. This process necessitates a ‘reward model’, which is a separate machine learning model trained to predict a human’s ranking of different model-generated responses. The reward model is trained on a dataset of comparisons – examples where human labelers indicate which of two or more responses is preferable, based on criteria like helpfulness, honesty, and harmlessness. The output of the reward model – a scalar value representing the quality of a given response – then serves as the reward signal used to further train the primary language model using reinforcement learning algorithms, effectively guiding it towards generating outputs aligned with human expectations.
Direct preference optimization (DPO) represents a recent advancement in aligning large language models by directly maximizing the likelihood of preferred responses, circumventing the need for an intermediary reward model. Traditional Reinforcement Learning from Human Feedback (RLHF) requires training a reward model to predict human preferences, which is then used to guide policy optimization; DPO instead reframes the RLHF objective as a supervised learning problem. This is achieved by utilizing a preference dataset consisting of paired responses-one preferred over the other-and training the language model to directly increase the log-likelihood of the preferred response while decreasing the log-likelihood of the dispreferred response, effectively simplifying the training pipeline and reducing potential sources of error associated with reward modeling inaccuracies.
Constitutional AI diverges from reinforcement learning approaches by directly optimizing language model behavior against a pre-defined set of principles, or a “constitution.” Instead of relying on human-provided reward signals, the model is prompted to critique its own responses based on these principles and then revise them accordingly. This self-improvement process, often involving iterative self-critique and revision cycles, allows the model to align with desired values without requiring extensive human labeling for reward modeling.
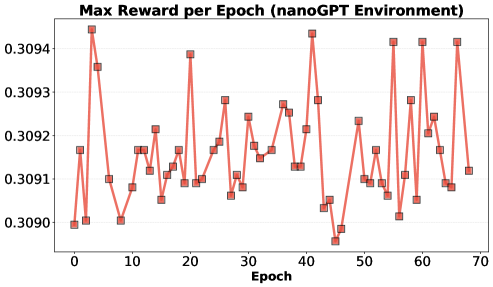
Validating Alignment: Identifying and Mitigating Systemic Risks
Even with ongoing research and implementation of alignment techniques designed to ensure artificial intelligence systems behave as intended, inherent vulnerabilities persist. Consequently, proactive methodologies such as ‘red teaming’ are crucial for identifying potential harms before deployment. Red teaming involves simulating adversarial attacks to stress-test the system and uncover weaknesses in its alignment, encompassing unexpected or undesirable behaviors. This process moves beyond simply evaluating performance on standard benchmarks and focuses on uncovering edge cases and failure modes that could lead to negative consequences, necessitating continuous evaluation and refinement of alignment strategies.
The lack of interpretability in large language models presents a significant challenge to developers and stakeholders. These models, while capable of generating complex and seemingly intelligent outputs, operate as largely “black boxes.” This opacity makes it difficult to ascertain the specific reasoning or data points that led to a particular response, hindering debugging, safety verification, and trust-building. Consequently, identifying and mitigating potential biases, vulnerabilities, or unintended consequences becomes substantially more complex, as the internal mechanisms driving model behavior remain largely inaccessible for direct analysis and modification.
Model performance is strongly correlated with scaling laws, demonstrating a predictable relationship between model size, the quantity of training data, and resultant capabilities. Recent evaluation of this system yielded a validation accuracy of 69.4% on a post-training task, representing a substantial improvement of 21.4 percentage points over the established baseline. This result indicates that increases in model scale and data volume contribute directly to enhanced performance on downstream tasks, although further research is required to fully characterize this relationship and identify potential diminishing returns.
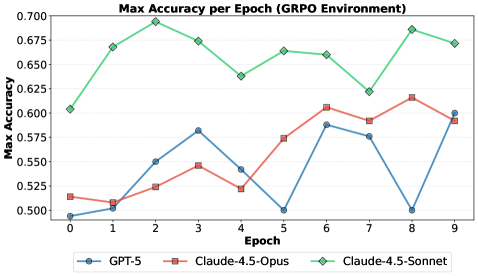
The Future Trajectory of Responsible AI Development
The proliferation of open-source large language models (LLMs) represents a pivotal shift in artificial intelligence, dramatically lowering the barriers to entry for researchers, developers, and organizations worldwide. This democratization of access fuels rapid innovation, enabling a broader range of applications and accelerating progress across diverse fields. However, this increased accessibility also introduces significant challenges concerning safety and responsible development. Without stringent safety protocols and careful evaluation, openly available models can be more easily exploited for malicious purposes or may perpetuate existing biases. Consequently, the open-source landscape necessitates a parallel emphasis on robust safeguards, comprehensive testing, and collaborative efforts to ensure these powerful technologies are deployed ethically and responsibly, protecting against potential harms while maximizing their benefits.
Advancing artificial intelligence responsibly demands sustained investigation into alignment techniques – methods ensuring AI goals correspond with human values. Recent progress showcases the potential of optimized systems, with one notable demonstration achieving a pre-training time of just 19.7 minutes. This represents a significant leap forward, surpassing the performance of existing baseline models by a margin of 16.2 minutes. Such efficiency not only accelerates development cycles but also facilitates more extensive testing through robust evaluation methodologies like ‘red teaming’ – where dedicated experts attempt to deliberately provoke undesirable behaviors. These combined efforts are crucial for proactively identifying and mitigating potential risks, ultimately fostering greater trust and enabling the safe deployment of increasingly powerful AI systems.
The deployment of artificial intelligence systems demands more than just performance; it necessitates a clear understanding of how these systems arrive at their conclusions. Current ‘black box’ models, while capable of impressive feats, often lack transparency, hindering the ability to identify biases, ensure fairness, and correct errors. Consequently, research into interpretability – the science of making AI decision-making processes understandable to humans – is paramount. Techniques range from visualizing the data that most influences a model’s output to developing algorithms that can explain their reasoning in natural language. This pursuit of ‘explainable AI’ isn’t merely an academic exercise; it’s a foundational requirement for building public trust, enabling effective oversight, and ultimately, ensuring responsible integration of AI into critical aspects of life, from healthcare and finance to criminal justice and autonomous vehicles.
The pursuit of automated AI research, as detailed in this work, fundamentally mirrors the rigorous demands of mathematical proof. The automated executor, evaluating LLM-generated hypotheses through direct execution, strives for an objective determination of correctness-a binary outcome. This echoes the sentiment expressed by Marvin Minsky: “The more we understand about intelligence, the more we realize how much of it is just making things up.” The paper’s findings regarding diversity collapse in reinforcement learning, despite successful evolutionary search, demonstrate that simply generating ideas isn’t sufficient; a robust exploration of the solution space, akin to a complete inductive proof, is essential. The challenge isn’t merely creation, but validation – a principle deeply rooted in formal systems and provable correctness.
The Road Ahead
The pursuit of automated AI research, as demonstrated by this work, inevitably confronts the limitations inherent in scaling intuition. While evolutionary search proves a surprisingly robust, if brute-force, method for navigating the ideation space, it merely postpones the crucial question: what constitutes meaningful progress? The automated executor offers a tangible, verifiable metric-execution-but the algorithms employed to guide that exploration remain susceptible to the familiar pitfalls of local optima and, more disturbingly, diversity collapse. Reinforcement learning, despite its theoretical elegance, falters not from a lack of computational power, but from a poverty of genuinely novel states.
Future investigations must move beyond simply testing ideas and toward a formalization of scientific inquiry itself. The challenge lies not in generating more hypotheses, but in constructing a system capable of disproving them efficiently. A truly elegant solution would prioritize falsifiability, actively seeking contradictions and refining theories based on rigorous, mathematically-grounded criteria-a system where failure is not a bug, but a feature.
Ultimately, the automation of AI research is not about replacing human scientists, but about forcing a precise articulation of the scientific method. The very act of building such a system reveals the implicit assumptions and biases embedded within current practice, and that, perhaps, is the most valuable outcome of all.
Original article: https://arxiv.org/pdf/2601.14525.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-01-22 19:24