Author: Denis Avetisyan
A new approach combines large-scale data analysis and semantic understanding to reveal the evolving trends and emerging directions within artificial intelligence.
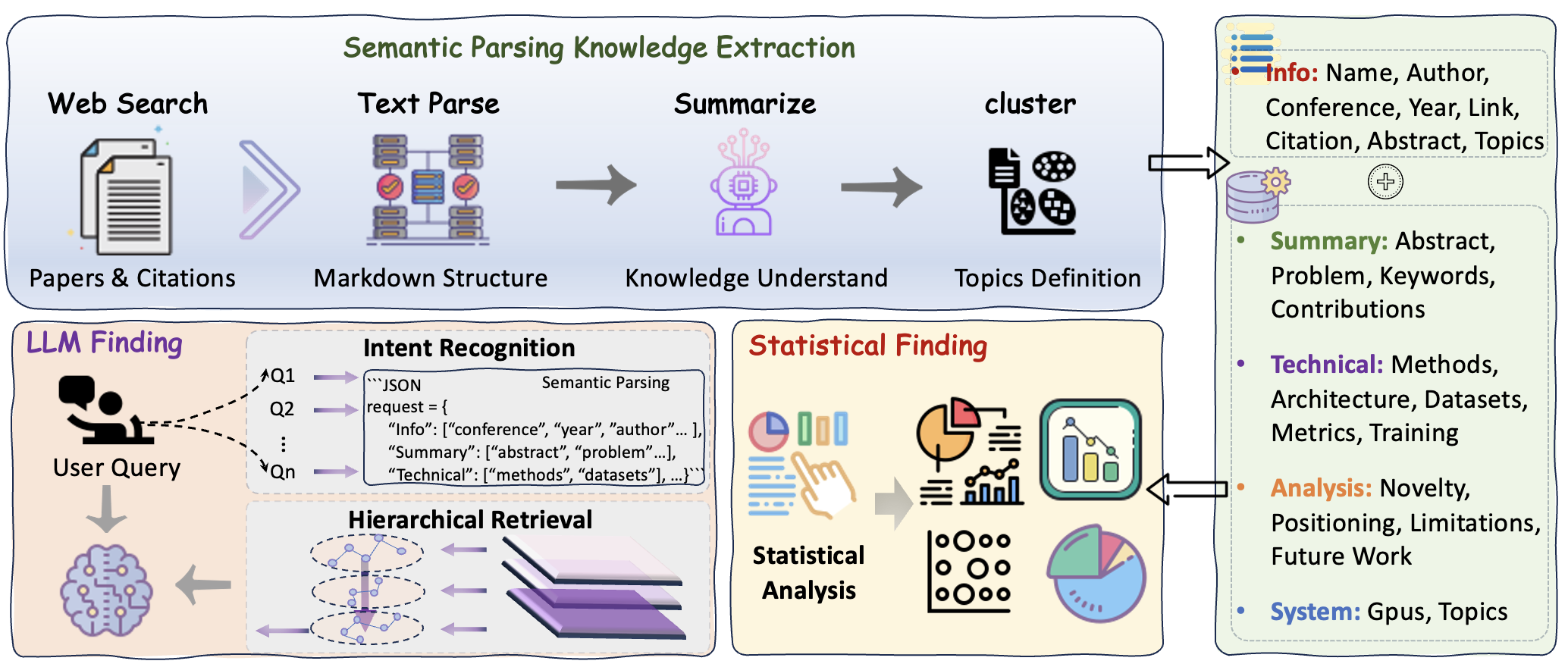
This paper details a framework for large-scale multidimensional knowledge profiling of scientific literature, leveraging large language models and hierarchical retrieval for advanced scientometrics.
The exponential growth of scientific publications in fields like machine learning increasingly challenges our ability to synthesize knowledge and track evolving research directions. To address this, we present ‘Large-Scale Multidimensional Knowledge Profiling of Scientific Literature’, a framework leveraging large-scale data analysis, LLM-driven semantic parsing, and structured retrieval to construct a comprehensive profile of over 100,000 recent papers. Our analysis reveals notable shifts toward areas such as AI safety and multimodal reasoning, alongside the stabilization of established methods, offering an evidence-based view of the field’s trajectory. Will this approach enable a more dynamic and nuanced understanding of scientific progress, and ultimately accelerate discovery?
The AI Research Flood: Drowning in Data
The field of artificial intelligence is currently characterized by a rate of expansion unprecedented in scientific history, generating a volume of research that quickly overwhelms traditional methods of knowledge assimilation. This exponential growth-driven by increased investment, broader accessibility to tools, and interdisciplinary collaboration-results not merely in more papers, but in a fragmentation of understanding. Researchers find it increasingly difficult to maintain a comprehensive overview of the landscape, identify crucial connections between disparate studies, and avoid redundant efforts. The sheer scale of new publications-covering everything from foundational algorithmic advances to specialized applications-creates a significant barrier to entry for newcomers and hinders even experienced practitioners from staying fully abreast of the latest developments, ultimately slowing the pace of innovation.
The sheer velocity of innovation in artificial intelligence presents a significant challenge to researchers attempting to stay current with the field. Traditional literature reviews, often reliant on manual searches and subjective selection, are increasingly unable to effectively synthesize the rapidly expanding body of work. This inability to comprehensively survey the landscape results in fragmented knowledge, where crucial connections between disparate research areas are overlooked and opportunities for synergistic advancement are missed. Consequently, researchers may unknowingly duplicate efforts, fail to build upon existing foundations, or remain unaware of potentially transformative findings hidden within the ever-growing volume of publications, ultimately hindering the pace of progress.
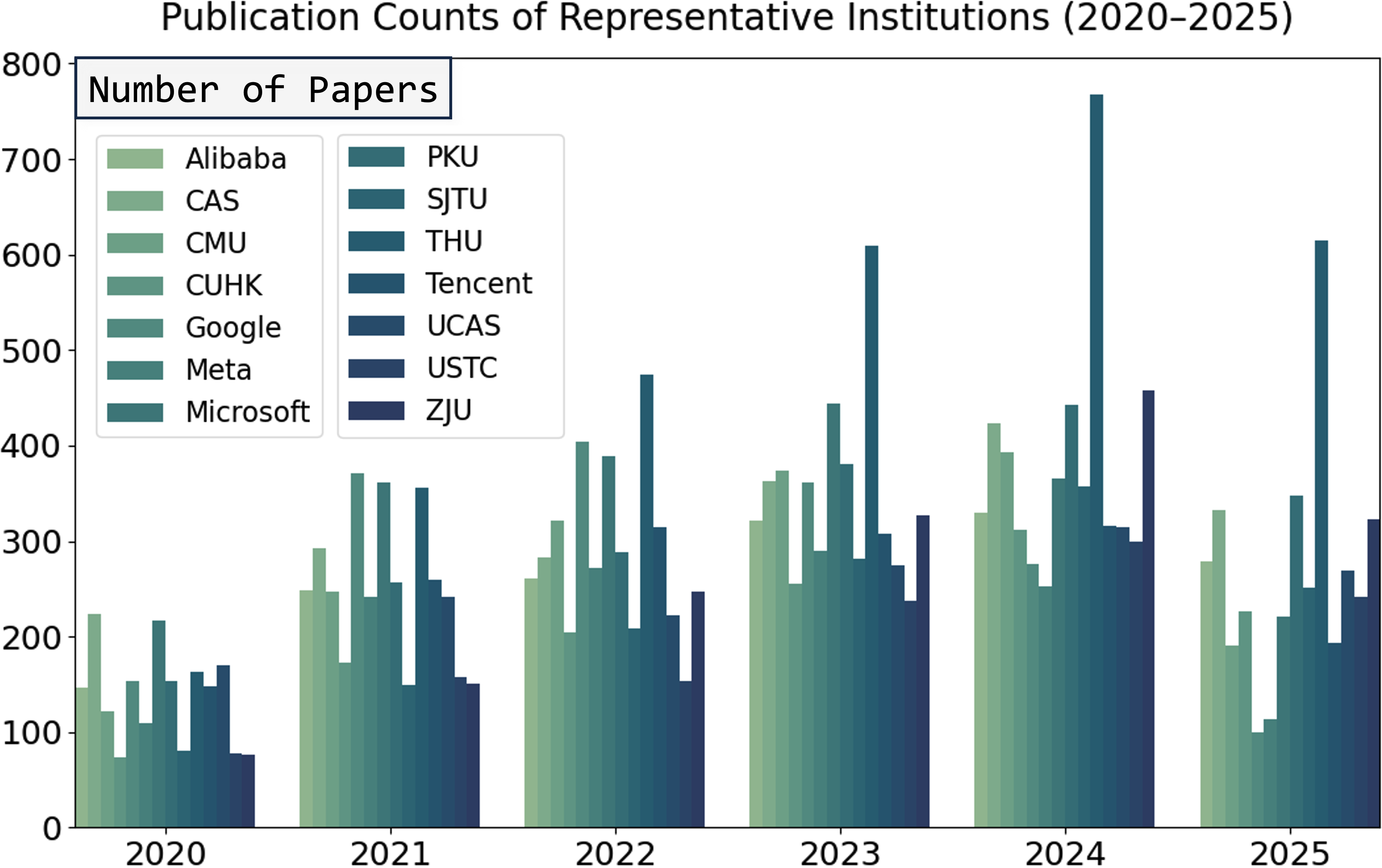
The accelerating pace of artificial intelligence research presents a significant challenge to maintaining a cohesive understanding of the field. A comprehensive review of existing literature is becoming increasingly untenable, as the sheer volume of publications rapidly outstrips traditional analytical capabilities. To address this, a scalable, automated approach to knowledge synthesis is essential. This work introduces a framework designed to analyze an extensive corpus of over 100,000 papers presented at 22 leading AI conferences between 2020 and 2025. By employing computational methods, the framework aims to identify key trends, emerging themes, and previously obscured connections within the diverse landscape of AI research, offering a more holistic and efficient means of navigating this expansive body of knowledge.
The sheer volume of artificial intelligence research demands more than simple accumulation of papers; a robust system for knowledge organization is crucial. Without a structured approach, valuable insights remain isolated, hindering progress and potentially leading to redundant efforts. This necessitates the development of frameworks capable of categorizing research not just by keywords, but by underlying methodologies, core contributions, and emerging trends. Such systems allow researchers to efficiently retrieve relevant work, identify gaps in knowledge, and build upon existing foundations, fostering a more cohesive and accelerated pace of innovation within the field. Ultimately, effective knowledge retrieval transforms the overwhelming flood of information into a navigable and actionable resource for the AI community.
ResearchDB: A System for Taming the AI Knowledge Beast
ResearchDB is a purposefully designed, relational database intended to systematically capture and represent information pertaining to artificial intelligence research. The database schema incorporates entities representing publications, authors, institutions, and key concepts, with defined relationships between these entities. Data is ingested from multiple sources, including academic publishers, preprint servers, and grant databases. Each publication record includes metadata such as title, abstract, publication date, and author affiliations, alongside extracted keywords and concept tags generated through automated content mining processes. The structured format of ResearchDB facilitates complex queries and analytical operations, enabling the tracking of research trends, the identification of emerging topics, and the assessment of research impact with greater precision than unstructured text-based approaches.
Content mining, in the context of this framework, utilizes a combination of Natural Language Processing (NLP) techniques to automatically identify and extract salient information from research papers. These techniques include named entity recognition (NER) to pinpoint key concepts such as algorithms, datasets, and evaluation metrics; relationship extraction to determine how these concepts interact; and topic modeling to discern underlying themes. Specifically, we employ both rule-based and machine learning approaches, including transformer models, to parse text, resolve coreferences, and construct a knowledge graph representing the relationships between extracted concepts. The extracted data is then structured and stored within ResearchDB, forming the basis for multi-dimensional knowledge profiling.
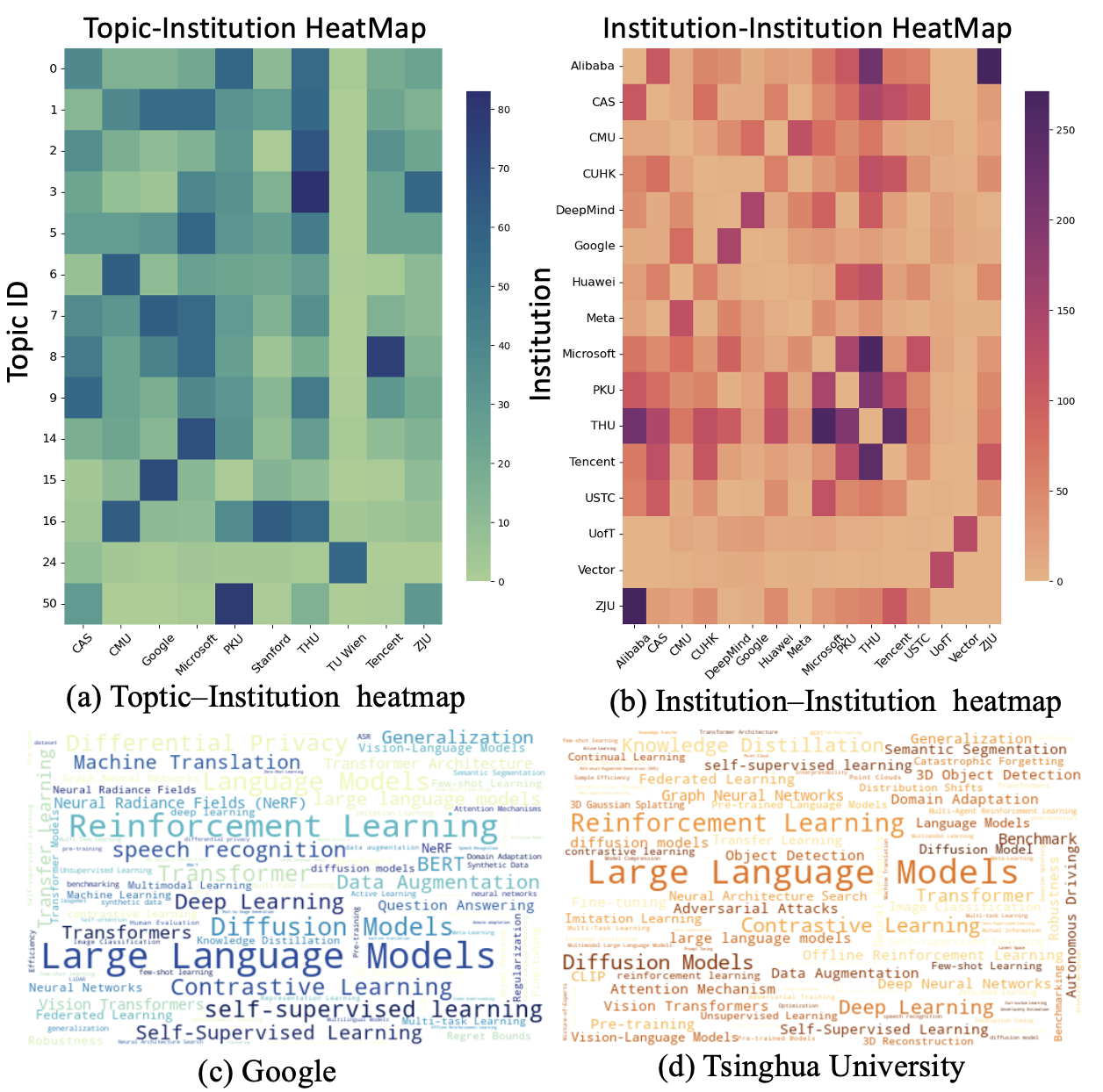
Multi-Dimensional Knowledge Profiling utilizes the concepts and relationships extracted through content mining to create a nuanced categorization of research topics. This process moves beyond simple keyword-based classification by representing each topic as a vector in a high-dimensional space, where dimensions correspond to the identified concepts. Analysis then involves examining the proximity of these vectors, allowing for the identification of related research areas and the detection of emerging trends. The resulting profiles facilitate a more granular understanding of the research landscape and support advanced search and recommendation functionalities, enabling researchers to efficiently navigate and synthesize relevant information.
Hierarchical Retrieval and Text Clustering are core components of the knowledge discovery process. Hierarchical Retrieval prioritizes search results based on pre-defined relationships between concepts, allowing for increasingly specific information to be surfaced as user queries become more refined. This is achieved through a taxonomy of research topics. Complementing this, Text Clustering groups similar research papers together based on shared keywords and semantic content, identified via natural language processing. These clusters facilitate the synthesis of information by presenting related work cohesively, enabling researchers to quickly grasp the current state of knowledge within a given area and identify potential gaps or emerging trends. The combination of these techniques significantly improves the efficiency of knowledge discovery compared to traditional keyword-based search methods.
LLMs: Automating the Synthesis, But Still Requiring Scrutiny
The conversion of natural language research abstracts into a formal, machine-understandable representation is achieved through the application of Large Language Models (LLMs) in conjunction with semantic parsing techniques. Semantic parsing involves analyzing the abstract’s grammatical structure and identifying the relationships between its constituent parts to create a logical form. LLMs, pre-trained on extensive text corpora, provide the contextual understanding necessary to accurately interpret the abstract’s meaning and translate it into this formal representation, typically expressed as a structured query language or a knowledge graph. This process facilitates automated analysis, information retrieval, and the identification of key concepts and relationships within the research literature.
Large Language Models (LLMs), specifically Deepseek-R1-32B and ChatGPT-5, are instrumental in extracting key insights and relationships from complex text due to their parameter scale and training data. These models utilize a transformer architecture enabling them to process and understand contextual information within research abstracts. Their capacity for natural language understanding allows for the identification of entities, relationships between those entities, and the overall meaning conveyed in the text. The models achieve this through probabilistic reasoning based on patterns learned during pre-training on massive datasets, and are further refined through techniques like instruction tuning to improve accuracy in extracting specific types of information relevant to research analysis.
Retrieval-Augmented Generation (RAG) improves the fidelity and contextual relevance of LLM-generated outputs by integrating information retrieved from external knowledge sources. Rather than relying solely on the parameters encoded during pre-training, RAG systems first identify relevant documents or data fragments based on the user’s input. These retrieved materials are then concatenated with the prompt and fed into the LLM, providing it with specific, up-to-date information to ground its response. This process mitigates the risk of hallucination and enhances the accuracy of summaries and analyses, particularly in domains requiring specialized knowledge or recent data, and allows for traceability of generated content to source materials.
By converting research abstracts into a formalized, machine-readable format, our system enables the identification of emerging research trends with increased precision. This is achieved through automated analysis of key concepts and their relationships, allowing for dynamic categorization of research topics beyond traditional keyword-based methods. Furthermore, the structured data generated facilitates consistent human evaluation of system outputs; standardized criteria can be applied to assess relevance, accuracy, and completeness, minimizing subjective bias and improving inter-rater reliability in benchmarking and model refinement.

The AI Research Lifecycle: From Spark to Sunset
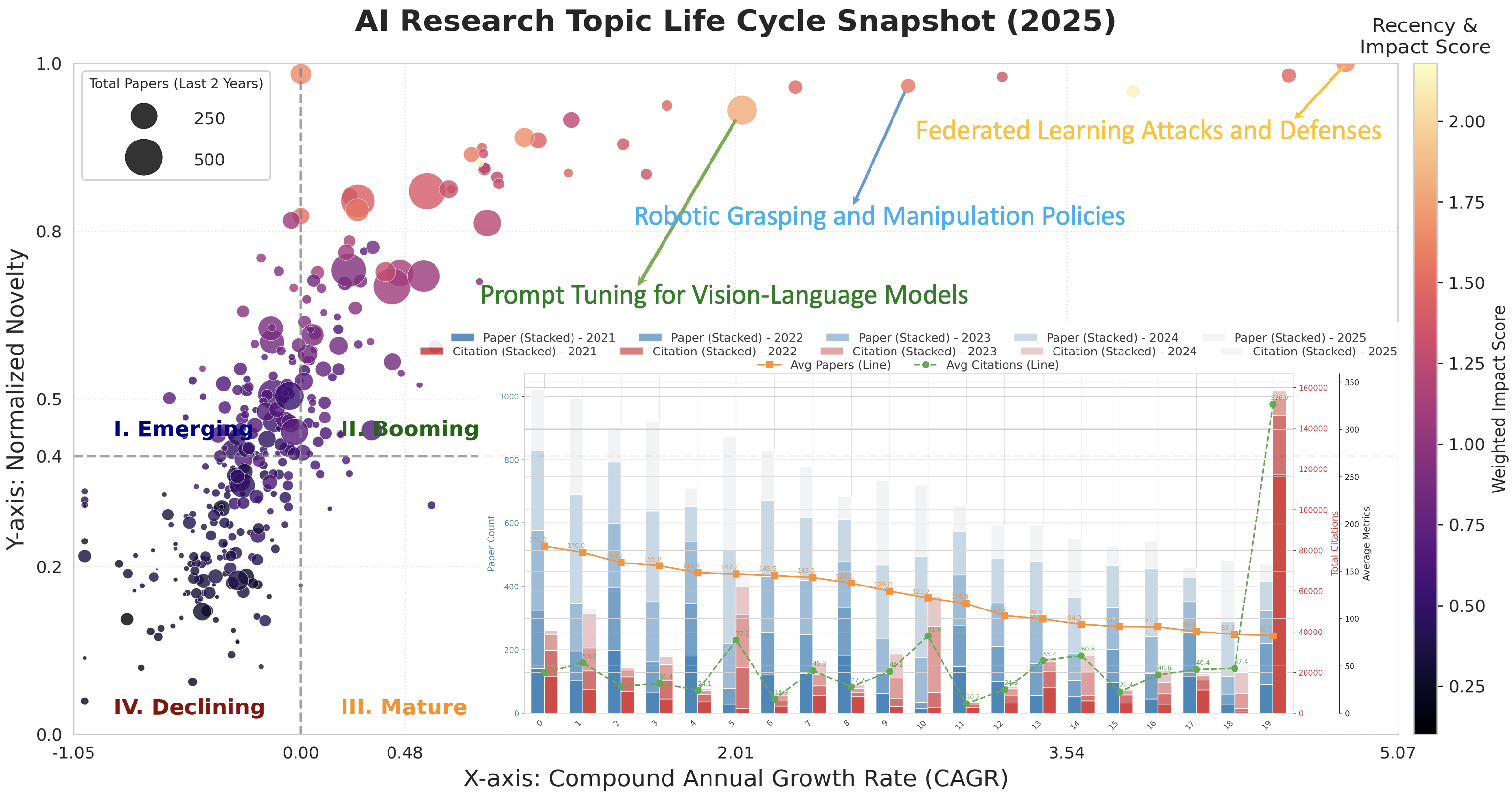
The progression of research topics isn’t random; instead, areas of study follow a predictable lifecycle. This framework meticulously tracks topics from their initial emergence – often signaled by a small cluster of exploratory papers – through a period of rapid growth as interest and funding increase. As a topic matures, research shifts towards refinement and application, resulting in a plateau of activity. Eventually, most topics experience a decline, either because the core questions are answered or because newer, more promising avenues emerge. By mapping these lifecycles, researchers can gain valuable insights into the evolving landscape of artificial intelligence, identifying both established areas ripe for further development and nascent fields with high potential for future breakthroughs.
The study employs a dual-algorithm approach, utilizing both High-Density Spatial Clustering of Applications with Noise (HDBSCAN) and Uniform Manifold Approximation and Projection (UMAP) to map the evolving landscape of AI research. HDBSCAN excels at identifying dense clusters of closely related topics, even in the presence of noise or varying densities, while UMAP then provides a low-dimensional representation of these clusters, allowing for clear visualization of their relationships. This combination reveals not just individual research areas, but also the connections and overlaps between them, effectively creating a dynamic map of the field. By projecting high-dimensional research data onto a two-dimensional space, the visualization allows researchers to readily identify emerging trends, established areas of expertise, and potential cross-disciplinary opportunities that might otherwise remain obscured within the vast body of scientific literature.
The study of AI research topics demonstrates a complex web of interconnectedness, revealing that advancements in one area frequently catalyze progress in seemingly disparate fields. Through detailed analysis, researchers identified numerous cross-disciplinary links, demonstrating how innovations in natural language processing, for example, directly influence developments in computer vision and robotics. This interconnectedness isn’t merely correlational; the research highlights specific instances where techniques and datasets developed for one domain were successfully adapted and applied to others, accelerating the pace of innovation. Consequently, this understanding of the research landscape illuminates promising avenues for future exploration, suggesting that focusing on these interdisciplinary connections-rather than isolated advancements-will be crucial for sustained progress and the unlocking of new capabilities within artificial intelligence.
A comprehensive understanding of artificial intelligence research trends allows for the strategic identification of knowledge gaps and the focused allocation of resources. Recent analysis demonstrates a significant shift towards benchmark-focused research, with the proportion of papers dedicated to establishing performance baselines increasing markedly from 10.07% in 2022 to 18.16% in 2025. This surge suggests a growing emphasis on quantifiable progress and standardized evaluation within the field, potentially indicating a maturation of certain areas and a need for investment in novel evaluation metrics and benchmarks to drive further innovation beyond incremental improvements on established tasks. Such data-driven insights are crucial for researchers, funding agencies, and policymakers seeking to optimize the impact of future AI development.
Automated Literature Review: A Future Where Humans Still Verify
A novel framework has emerged as the core architecture for a new generation of automated literature review tools, including prominent pipelines such as ‘AutoSurvey’, ‘SurveyX’, ‘SurveyForge’, and ‘SurveyG’. These systems are built upon this foundation, enabling the rapid assembly of synthesized insights from vast quantities of research data. The framework’s modular design facilitates adaptation to diverse research domains and allows for continuous improvement through the integration of advanced techniques. By providing a standardized approach to literature review automation, this architecture is poised to significantly accelerate the pace of scientific discovery and knowledge dissemination, offering researchers a powerful means of staying current with evolving fields.
Current automated literature review systems efficiently distill insights from vast research repositories through Retrieval-Augmented Generation (RAG). These pipelines begin by querying a structured database – termed ‘ResearchDB’ – to retrieve relevant passages based on a given research question. Instead of simply presenting these passages, RAG then feeds them into a large language model, which synthesizes the information into a cohesive and comprehensive summary. This process mimics the way a researcher manually reads and integrates information from multiple sources, but at a significantly accelerated pace and scale. The resulting summaries offer a condensed overview of the current state of knowledge, highlighting key findings, trends, and gaps in the literature, thereby enabling faster and more informed research cycles.
The advent of automated literature review tools signifies a substantial shift in research workflows, effectively diminishing the traditionally time-consuming and laborious process of manual synthesis. By rapidly processing and summarizing vast quantities of academic papers, these systems liberate researchers from exhaustive data collection and allow greater concentration on higher-level cognitive tasks. This newfound efficiency facilitates deeper analysis, encourages innovative hypothesis generation, and ultimately empowers scientists to dedicate more resources to experimental design, critical thinking, and the pursuit of groundbreaking discoveries – moving beyond information gathering to knowledge creation.
Ongoing development centers on enhancing the robustness and adaptability of automated literature review pipelines. Researchers are actively working to refine the retrieval and synthesis components, aiming for more nuanced understanding and accurate summarization of complex research landscapes. This includes exploring methods to handle ambiguous or conflicting information, improve the identification of key themes, and incorporate diverse data sources beyond traditional research databases. Ultimately, the goal is to broaden the scope of addressable research questions, moving beyond simple descriptive reviews towards more analytical and comparative syntheses – allowing these pipelines to tackle increasingly sophisticated inquiries and support a wider spectrum of scholarly investigation.
The pursuit of comprehensive knowledge profiling, as detailed in this work, feels less like building a cathedral and more like constructing a particularly elaborate sandcastle. The paper attempts to chart the shifting sands of AI research using LLMs and hierarchical retrieval, a noble effort, yet one inherently destined for iterative refinement. It’s a system built to map a moving target. Andrew Ng once said, “AI is not about replacing humans; it’s about augmenting them.” This sentiment rings true; the framework doesn’t solve understanding AI’s evolution, it merely provides a more sophisticated tool for navigating its complexities, a tool that will inevitably require constant recalibration against the inevitable tide of new data and unforeseen breakthroughs. Tests, after all, are a form of faith, not certainty.
What Lies Ahead?
The framework detailed within offers a compelling, if predictably complex, map of a perpetually shifting terrain. It successfully automates the observation of AI’s evolution, but the very act of codifying ‘trends’ introduces a temporal fragility. Every abstraction dies in production, and here, the ‘production’ is the research lifecycle itself. The identified ‘emerging directions’ will, inevitably, bifurcate, merge, or simply prove to be local maxima in the vast search space of possibility.
Future iterations will undoubtedly focus on addressing the inherent ambiguity of semantic analysis. While Large Language Models excel at pattern recognition, they remain susceptible to the subtle shifts in meaning that characterize genuine innovation. The real challenge isn’t scaling the analysis – it’s building a system resilient to the noise of discarded hypotheses and fashionable dead ends.
One anticipates a move towards incorporating ‘negative knowledge’ – actively profiling what isn’t being researched, and understanding why. A complete picture requires not just charting the ascent of promising avenues, but also documenting the quiet abandonment of others. It’s a messy business, this. Every model will eventually be wrong; the art lies in designing for graceful failure, and accepting that the map is never the territory.
Original article: https://arxiv.org/pdf/2601.15170.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Celebs Who Narrowly Escaped The 9/11 Attacks
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-01-22 17:41