Author: Denis Avetisyan
New research reveals that even sophisticated fake news detectors are surprisingly susceptible to manipulation through subtle changes in emotional language generated by artificial intelligence.

This paper demonstrates the vulnerability of state-of-the-art fake news detection systems to sentiment-based adversarial attacks from large language models and introduces AdSent, a framework for building more robust detection models.
Despite advances in automated detection, current fake news detection systems remain surprisingly vulnerable to subtle manipulation. This is the central concern of ‘Robust Fake News Detection using Large Language Models under Adversarial Sentiment Attacks’, which investigates how easily adversarial sentiment shifts-generated by large language models-can compromise detection accuracy. The authors demonstrate that state-of-the-art detectors exhibit significant biases linked to sentiment, often misclassifying non-neutral articles as fake, and introduce AdSent, a sentiment-agnostic framework to improve robustness. Can this approach effectively generalize across diverse datasets and emerging adversarial techniques, ultimately fortifying the fight against online misinformation?
The Erosion of Truth: A Modern Challenge
The rapid spread of misinformation and disinformation presents a growing challenge to the foundations of informed societies. False narratives, often amplified through social media and online platforms, erode public trust in legitimate institutions, scientific consensus, and even shared reality. This isn’t simply about isolated instances of incorrect information; it’s a systemic threat impacting crucial areas like public health, political discourse, and economic stability. When individuals are unable to reliably distinguish between fact and fiction, their capacity for reasoned decision-making diminishes, leading to potentially harmful consequences at both personal and collective levels. The pervasiveness of these false narratives fosters polarization, undermines democratic processes, and creates fertile ground for manipulation, necessitating a comprehensive understanding of their origins, dissemination, and impact.
The sheer scale of modern disinformation campaigns presents a formidable challenge to conventional fact-checking. While historically, journalistic scrutiny and dedicated fact-checkers could effectively debunk falsehoods, the current information landscape is characterized by a relentless deluge of content, often disseminated at speeds that overwhelm human capacity. Moreover, increasingly sophisticated techniques – including the use of deepfakes, coordinated bot networks, and strategically crafted narratives designed to exploit cognitive biases – render simple debunking insufficient. Falsehoods frequently gain traction before fact-checkers can respond, and even when debunked, these narratives can persist due to the psychological phenomenon of continued influence, where initial exposure shapes belief even after disconfirmation. This creates a reactive cycle where fact-checkers are perpetually playing catch-up, struggling to contain the spread of misinformation rather than proactively preventing its emergence.
While automated detection systems represent a vital defense against the rising tide of disinformation, current methodologies are surprisingly susceptible to adversarial manipulation. These systems, often relying on patterns in language and source credibility, can be ‘fooled’ by subtle alterations to text – known as adversarial attacks – or by the deliberate propagation of false narratives through seemingly legitimate channels. Sophisticated actors are increasingly capable of crafting disinformation that bypasses these automated filters, exploiting the limitations of algorithms trained on existing datasets. This vulnerability isn’t simply a matter of imperfect technology; it highlights the ongoing arms race between those seeking to spread false information and the developers striving to detect it, demanding continuous innovation in detection techniques and a deeper understanding of how disinformation evolves.
The development of robust automated systems for detecting disinformation relies heavily on the availability of high-quality, labeled datasets. Resources such as PolitiFact, known for its meticulous fact-checking of political statements, and GossipCop, which focuses on celebrity and entertainment news, provide crucial examples of verified true and false claims. Complementing these are datasets like Labeled Unreliable News (LUN), specifically designed to identify patterns indicative of intentionally misleading information. These collections aren’t simply archives of falsehoods; they function as essential training grounds for machine learning algorithms, allowing researchers to build and refine systems capable of recognizing deceptive content. Furthermore, these labeled datasets serve as benchmarks for evaluating the performance of these automated detectors, providing a standardized way to measure progress and identify areas for improvement in the ongoing fight against misinformation.
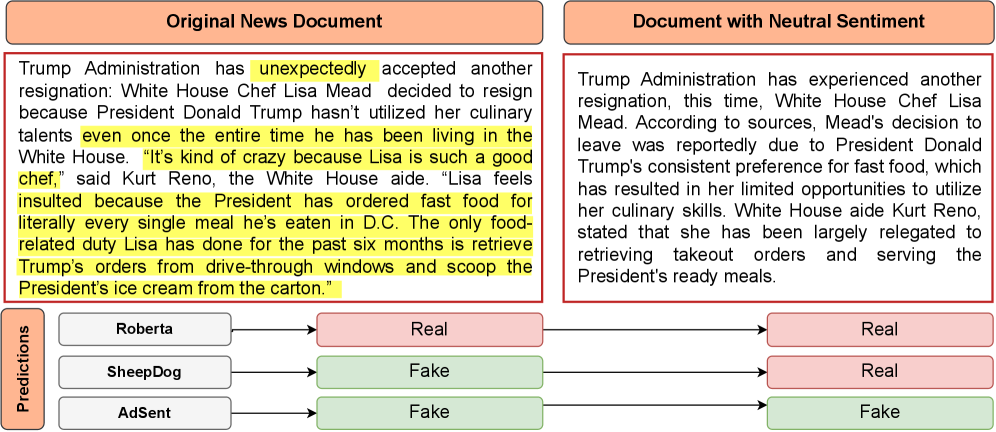
The Fragility of Detection: A System Under Strain
Current fake news detection systems, frequently leveraging sentiment analysis and Large Language Models (LLMs) such as BERT and its variants, exhibit vulnerability to adversarial attacks. These attacks involve subtly altering input text – often through synonym replacement or minor phrasing changes – without affecting its semantic meaning for a human reader. However, these alterations can significantly impact the model’s internal representations and lead to misclassification. The susceptibility arises from the models’ reliance on statistical correlations within training data rather than a genuine understanding of factual accuracy or logical consistency. Consequently, carefully crafted adversarial examples can bypass detection mechanisms, even in state-of-the-art systems, demonstrating a lack of robustness against intentionally deceptive inputs.
Sentiment-based adversarial attacks represent a significant threat to fake news detection systems. These attacks function by subtly altering the emotional coloring of text – for example, shifting phrasing from neutral to slightly positive or negative – without changing the underlying factual claims. Evaluations demonstrate that these manipulations can successfully evade detection algorithms, causing performance degradation in state-of-the-art detectors by as much as 21.51%. This vulnerability arises because current systems often rely heavily on sentiment analysis as a key feature for identifying misinformation, making them susceptible to attacks that specifically target this component.
Current fake news detection systems demonstrate a significant vulnerability stemming from their reliance on superficial sentiment analysis. Evaluations reveal these models frequently assign higher confidence scores to text exhibiting strong emotional tones, even when the underlying factual claims are demonstrably false. This prioritization of sentiment over veracity occurs because detectors are trained to identify patterns associated with biased or manipulative language, but lack the capacity to independently verify the truthfulness of statements. Consequently, adversarial attacks that subtly manipulate emotional language, while preserving or even enhancing perceived credibility, can effectively bypass detection mechanisms, leading to substantial performance degradation and highlighting a fundamental limitation in relying solely on stylistic features for content authentication.
While RoBERTa demonstrates strong performance in natural language understanding tasks, its architecture does not inherently provide resilience against adversarial manipulations of text. Research indicates that even minor alterations to the emotional tone or phrasing of a text, without changing its core meaning, can significantly reduce the accuracy of RoBERTa-based fake news detection systems. This susceptibility stems from the model’s reliance on learned patterns within the training data, which may not adequately account for intentionally deceptive text crafted to exploit these patterns. Consequently, RoBERTa, and similar transformer-based models, require specific adversarial training or defense mechanisms to enhance their robustness against these attacks and maintain reliable performance in real-world scenarios.
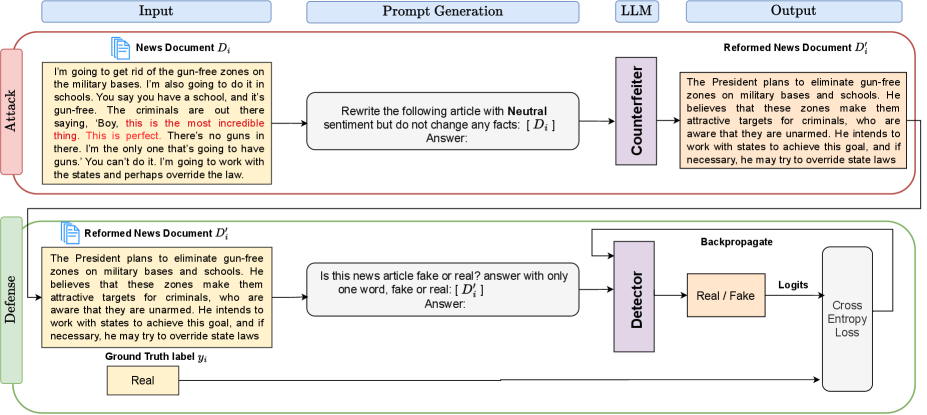
AdSent: A Foundation Built on Verifiable Truth
AdSent represents a departure from conventional fake news detection methods which often rely heavily on sentiment analysis. This framework prioritizes the verification of factual consistency as the primary indicator of news authenticity, operating on the premise that inaccuracies in reported facts are more reliable signals of misinformation than emotionally charged language. By focusing on the correspondence between claims and evidence, AdSent aims to reduce the impact of stylistic or emotional manipulation frequently used in deceptive content. This approach involves evaluating whether statements align with established knowledge and verifiable sources, rather than assessing the subjective tone or emotional coloring of the text itself.
Sentiment-Agnostic Training is a methodology utilized within the AdSent framework designed to reduce the correlation between predicted veracity and the sentiment expressed in a given text. This is achieved through a training process that specifically minimizes sentiment-related features during model learning, effectively decoupling sentiment from the assessment of factual correctness. The technique involves adversarial training and data augmentation strategies focused on neutralizing sentiment signals, thereby ensuring the model prioritizes factual consistency rather than emotional tone when identifying potentially false information. This approach aims to improve the robustness of fake news detection systems against manipulations that exploit sentiment biases.
The AdSent framework utilizes large language models (LLMs) – specifically LLaMA, GPT, and Qwen – and prioritizes factual consistency during the detection process. This approach intentionally minimizes sentiment influence to improve robustness. Evaluations on benchmark datasets demonstrate an 87.76% macro F1-score on the PolitiFact dataset and 78.56% on the GossipCop dataset, indicating strong performance in identifying factual inaccuracies while maintaining a neutral stance regarding subjective opinions expressed in the text.
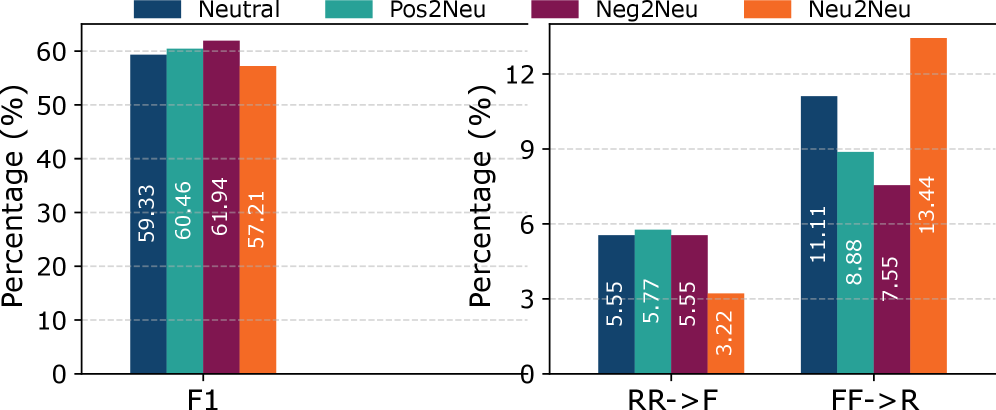
AdSent demonstrates increased resilience to sentiment-based adversarial attacks by explicitly separating sentiment analysis from veracity detection. Traditional fake news detection methods are susceptible to manipulations that alter the emotional tone of text without changing its factual content; AdSent mitigates this vulnerability. Evaluation across adversarial style transfer tasks-where text is modified to change sentiment while preserving meaning-demonstrates consistent performance gains over existing techniques. Furthermore, AdSent exhibits improved generalization capabilities, achieving higher accuracy on previously unseen datasets compared to methods reliant on sentiment analysis for veracity assessment.
Beyond Detection: Cultivating a More Informed Future
The core innovation of AdSent – a focus on verifying factual claims rather than stylistic elements – offers a promising defense against increasingly sophisticated forms of online deception. Current fake news detection systems often fall prey to adversarial attacks, where subtle alterations to text – such as stylistic changes or paraphrasing – can successfully evade detection. By prioritizing consistency with established knowledge and minimizing reliance on easily manipulated surface features, the principles behind AdSent can be generalized to counter these attacks, including those employing style transfer techniques designed to mimic legitimate writing styles. This approach shifts the focus from how something is said to what is actually being claimed, offering a more robust and reliable method for identifying misinformation, regardless of its presentation.
The current landscape of fake news detection often focuses on easily exploited stylistic or emotional cues, leaving systems vulnerable to increasingly sophisticated deception. Future work necessitates a shift towards more comprehensive frameworks capable of analyzing content beyond superficial features. These advanced systems should integrate techniques from areas like knowledge graph reasoning, commonsense inference, and stance detection to verify claims against established facts and contextual understanding. Crucially, such frameworks must also be designed to anticipate and mitigate evolving deceptive techniques – including adversarial attacks and subtle manipulations of narrative structure – thereby fostering a more robust and reliable defense against the spread of misinformation. The ultimate goal is not simply to identify known patterns of falsehood, but to assess the inherent plausibility and factual grounding of information, regardless of how cleverly it is disguised.
The advancement of fake news detection hinges significantly on the continuous refinement of datasets and evaluation metrics. Current benchmarks often prove inadequate for capturing the nuanced characteristics of evolving disinformation campaigns, leading to inflated performance estimates and a failure to identify critical vulnerabilities in detection systems. Researchers are actively working to construct datasets that reflect the increasing sophistication of fabricated content-incorporating multimodal information, diverse linguistic styles, and realistic propagation patterns-and developing metrics that move beyond simple accuracy to assess robustness against adversarial attacks and generalization to unseen examples. This iterative process of dataset creation, metric development, and model evaluation is essential not only for tracking progress in the field but also for proactively uncovering weaknesses and guiding the development of more resilient and reliable detection technologies.
Combating the pervasive issue of misinformation demands a strategy extending beyond purely technical fixes. While algorithms and automated detection systems play a crucial role in identifying and flagging potentially false content, these tools are not foolproof and can be circumvented by increasingly sophisticated deceptive techniques. Therefore, a truly effective response necessitates a complementary focus on bolstering media literacy among the public, empowering individuals to critically evaluate information sources and recognize manipulative content. This educational component must be coupled with a heightened sense of responsibility regarding information sharing – encouraging users to verify claims before amplification and to prioritize factual accuracy over sensationalism. Ultimately, a synergistic approach – integrating technological innovation, informed citizenry, and ethical information practices – represents the most promising path toward mitigating the harms of misinformation and fostering a more trustworthy information ecosystem.
The study illuminates a critical fragility within current fake news detection systems. These systems, while seemingly sophisticated, crumble under subtle sentiment manipulations crafted by large language models. This vulnerability underscores a simple truth: abstractions age, principles don’t. The research champions a return to foundational robustness – building defenses not against specific attacks, but against the potential for manipulation. G. H. Hardy observed, “The greatest enemy of knowledge is not ignorance, it is the illusion of knowledge.” This rings true; reliance on complex models without verifying their resilience creates a dangerous illusion of security, especially when facing adversarial sentiment attacks. Every complexity needs an alibi, and this work demands a clearer understanding of the underlying principles before trusting the output.
Further Horizons
The demonstrated susceptibility of current fake news detection systems to sentiment manipulation is not, itself, surprising. Signal detection is, invariably, a game of diminishing returns. The focus, then, shifts. Not to more complex models, but to a clearer understanding of what constitutes ‘truth’ in a textual space. The problem is not merely classification, but the inherent ambiguity of language itself.
Future work must address the limitations of relying solely on textual features. Multimodal analysis-incorporating visual and contextual data-offers a potential, though not guaranteed, path toward increased robustness. More critically, research should explore methods for quantifying uncertainty. A ‘confident’ incorrect classification is, arguably, more damaging than a hesitant, accurate one. Clarity is the minimum viable kindness.
The long view suggests a necessary re-evaluation of the task. Perhaps the goal should not be to detect falsehoods, but to empower critical assessment. Systems that highlight potential biases, conflicting information, or logical fallacies may prove more valuable-and more resistant to adversarial attack-than those that attempt to deliver a definitive judgment. The pursuit of perfect detection is a vanity.
Original article: https://arxiv.org/pdf/2601.15277.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-01-22 12:43