Author: Denis Avetisyan
A new approach combines expert insights with advanced machine learning to detect anomalies in cryptocurrency transactions, even when labeled data is scarce.
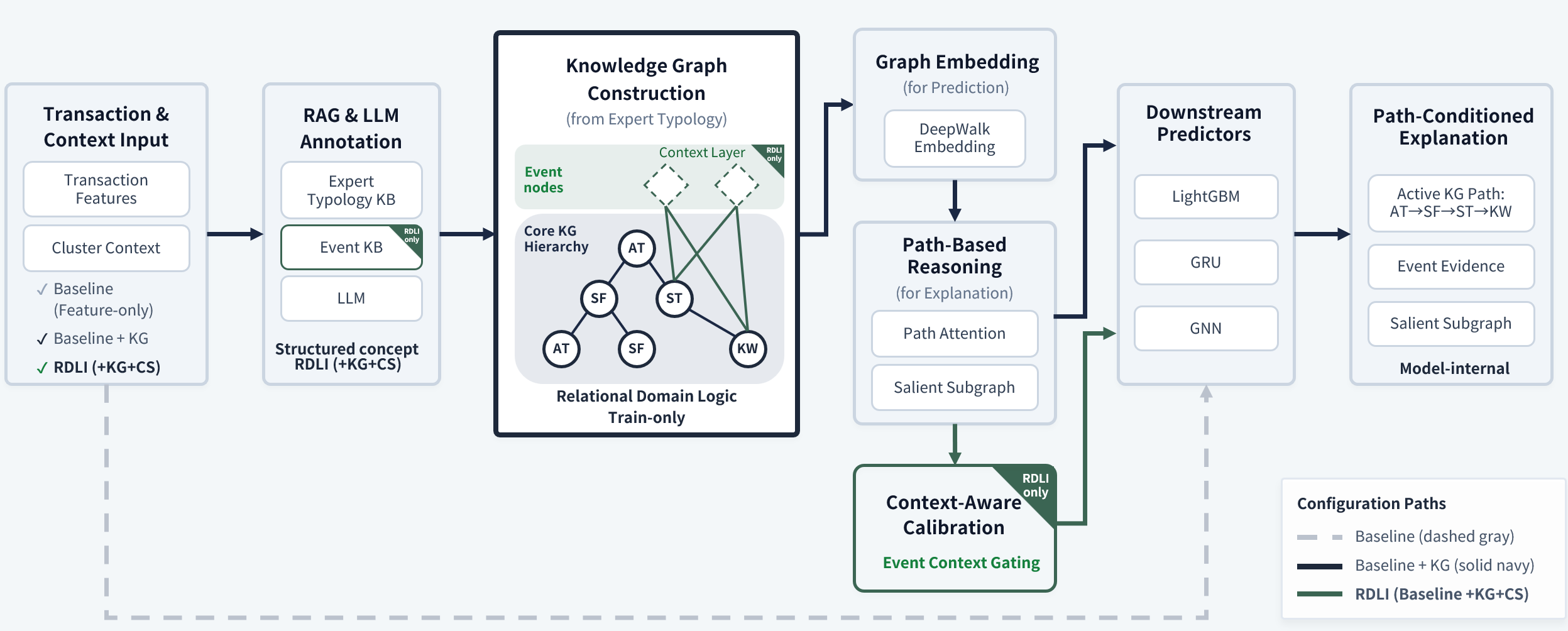
This paper introduces Relational Domain-Logic Integration (RDLI), a framework leveraging knowledge graphs and graph neural networks for explainable anomaly detection in financial transactions and compliance with regulations like the FATF Travel Rule.
Detecting illicit activity in decentralized crypto networks presents a fundamental challenge due to limited labeled data and the evolving tactics of malicious actors. This paper, ‘Knowledge-Integrated Representation Learning for Crypto Anomaly Detection under Extreme Label Scarcity; Relational Domain-Logic Integration with Retrieval-Grounded Context and Path-Level Explanations’, introduces a novel framework, Relational Domain-Logic Integration (RDLI), that embeds expert-derived heuristics into graph neural networks to improve anomaly detection even with minimal training data. RDLI achieves a 28.9% F1 score improvement over state-of-the-art methods while also providing interpretable, path-level explanations, enhancing both accuracy and trustworthiness-but can these knowledge-integrated approaches effectively adapt to the rapidly changing landscape of crypto-based financial crime?
The Inevitable Rise of Uninterpretable Anomalies
Conventional anomaly detection systems, designed for the relatively structured world of traditional finance, are increasingly challenged by the intricacies of modern financial transactions, especially within Decentralized Finance (DeFi). These systems often rely on pre-defined rules or statistical models trained on historical data, proving inadequate when faced with the novel patterns and sheer volume of activity characteristic of DeFi protocols. The composable nature of DeFi, where multiple smart contracts interact in complex ways, creates transaction chains that defy simple categorization, generating a constant stream of previously unseen activity. Furthermore, the pseudonymity inherent in many blockchain systems obscures the relationships between actors, making it difficult to establish baseline behaviors and accurately identify deviations indicative of fraud or illicit activity. This combination of complexity and novelty renders traditional methods prone to both false positives and, more critically, false negatives, hindering their effectiveness in a rapidly evolving financial landscape.
Financial institutions now face a dual imperative: identifying illicit transactions and providing comprehensive justification for any flagged activity, a demand sharply intensified by regulations like the FATF Travel Rule. This isn’t simply about raising alerts; regulators require auditable explanations – a clear, traceable rationale for why a particular transaction triggered scrutiny. Traditional fraud detection systems, often ‘black boxes’ delivering only a binary outcome, are increasingly insufficient. The focus is shifting towards ‘explainable AI’ where the reasoning behind each flag is transparent and defensible, allowing compliance teams to effectively respond to regulatory inquiries and demonstrate proactive anti-money laundering efforts. This demand for interpretability necessitates a move beyond statistical anomaly detection and towards systems that can articulate the specific factors contributing to a risk assessment, fostering trust and accountability within the financial ecosystem.
The effectiveness of most machine learning models hinges on access to substantial, accurately labeled datasets, a requirement increasingly difficult to meet in the realm of financial anomaly detection. This difficulty manifests as ‘Extreme Label Scarcity’, a condition where the proportion of labeled transactions often falls below 0.01%. Such limited data severely restricts the application of traditional supervised learning techniques, as models struggle to generalize and accurately identify genuinely suspicious activity amidst the vast sea of normal transactions. This scarcity isn’t due to a lack of data, but rather the prohibitive cost and complexity of manually labeling each instance, particularly within the rapidly evolving landscape of Decentralized Finance where novel transaction types emerge constantly. Consequently, the development of robust and reliable anomaly detection systems requires innovative approaches capable of learning from minimal, yet representative, labeled examples, or entirely circumventing the need for labeled data altogether.
Relational Domain-Logic Integration: A Principled Approach
Relational Domain-Logic Integration (RDLI) is a framework designed to integrate pre-existing expert heuristics directly into the process of representation learning. This is achieved by moving beyond traditional “black box” machine learning models and explicitly incorporating domain knowledge during the feature extraction phase. Instead of treating heuristics as post-processing steps or separate rule-based systems, RDLI embeds them as constraints and guidance within the model itself, influencing how data is represented and ultimately analyzed. This integration allows the model to learn more efficiently from limited data and improve performance on tasks requiring specialized domain understanding, while also increasing the transparency and interpretability of the results.
Relational Domain-Logic Integration (RDLI) utilizes an Expert Knowledge Graph (EKG) to represent and incorporate complex domain logic into the anomaly detection process. The EKG is constructed to model hierarchical relationships between entities and concepts relevant to the specific domain, enabling the system to understand not just individual data points, but also the contextual relationships between them. This allows for anomaly scoring that goes beyond simple thresholding; scores are derived from the degree to which observed behavior deviates from the expected patterns defined within the knowledge graph’s hierarchical structure. The resulting anomaly scores are therefore more interpretable, as the system can trace the reasoning back to specific rules and relationships encoded in the EKG, and less prone to false positives generated by statistically unusual but logically valid events.
Logic-Aware Latent Signals are generated by propagating information from the Expert Knowledge Graph through a graph embedding layer, producing vector representations that encode relational constraints and hierarchical dependencies. These signals capture transaction flow beyond immediate connections, enabling the reconstruction of multi-hop dynamics – that is, the sequence of events and entities involved in a transaction across multiple steps or layers. This recovery of flow is achieved by leveraging the knowledge graph’s structure to identify and weight relationships between entities, allowing the system to infer indirect connections and dependencies that would be missed by traditional methods focused solely on direct interactions. The resulting latent signals provide a richer, more contextualized representation of transaction behavior, facilitating more accurate anomaly detection and root cause analysis.
Contextual Grounding and Dynamic Adaptation: Embracing Real-World Signals
Retrieval-Grounded Context (RGC) within RDLI enables dynamic adaptation by integrating current events data from sources like GNews. This process involves continuously querying news aggregators for information pertaining to macroeconomic indicators-such as inflation rates, GDP growth, and unemployment figures-and regulatory changes impacting financial markets. The retrieved data is then used to contextualize transaction analysis, allowing the system to adjust its parameters and thresholds in response to shifts in the external environment. This adaptive capability is crucial for maintaining model accuracy and relevance, as it mitigates the risk of relying on static datasets that may become outdated or misaligned with prevailing conditions. By incorporating RGC, RDLI moves beyond historical analysis to incorporate real-time awareness of the evolving financial and regulatory landscape.
Cosine similarity serves as a key component in anomaly detection by quantifying the resemblance between current events, as represented by external narratives sourced from news and regulatory filings, and historical data. This metric calculates the cosine of the angle between two vectors – each representing a narrative – effectively measuring their directional similarity, irrespective of magnitude. A high cosine similarity score indicates a narrative closely aligned with past, understood events, classifying it as a benign regime change. Conversely, low scores signify divergence from established patterns, flagging potential anomalies requiring further investigation. The threshold for differentiation is dynamically adjusted based on data volatility and the frequency of regime changes to minimize false positives and ensure accurate identification of genuinely anomalous activity.
The system employs Gemini-2.5-Flash to automate the creation of structured annotations derived from unprocessed transaction data. This process leverages pre-defined typologies established by subject matter experts, enabling the model to categorize and label transactions consistently. Raw transaction contexts are inputted, and the LLM generates annotations detailing specific characteristics, flagging potential anomalies, or identifying relevant attributes based on the expert-defined framework. This automated annotation significantly reduces manual review requirements and facilitates efficient analysis of transactional data, providing a standardized and scalable approach to data interpretation.
Unlocking Transparency: Path-Level Explainability and its Implications
Recent advances in graph-based anomaly detection often lack the crucial ability to justify their conclusions, creating a barrier to practical deployment. To address this, researchers developed a system capable of generating Path-Level Explainability, which meticulously maps flagged anomalous activities directly to the specific subgraphs within the network that triggered the alert. This isn’t simply highlighting nodes; the system also identifies the underlying domain-logic cues – the specific rules or patterns – that connect those nodes and contribute to the anomaly detection. The resulting explanations are designed to be audit-ready, offering a clear, traceable pathway from alert to evidence, and facilitating thorough review and validation of the system’s decision-making process. This granular level of transparency builds confidence and enables effective oversight, crucial for applications in sensitive domains like fraud prevention and cybersecurity.
Recent evaluations reveal a substantial performance gain with the developed approach, achieving a 28.9% improvement in F1-Score when contrasted with standard Graph Neural Network baselines. This advancement is particularly noteworthy given the challenging conditions under which it was attained – specifically, an environment characterized by extreme label scarcity. The ability to significantly enhance accuracy despite limited labeled data underscores the efficiency of the model and its potential for practical application in scenarios where data annotation is costly or time-consuming. This result suggests a more robust and adaptable system capable of discerning meaningful patterns even with minimal supervision, marking a significant step forward in the field of graph-based machine learning.
Independent forensic evaluations of the system’s explanations reveal a substantial increase in both trustworthiness and perceived usefulness, directly bolstering confidence in its outputs. These reviews demonstrate that the detailed, path-level insights generated are not simply technically accurate, but also readily understandable and logically convincing to human reviewers. This improved clarity is crucial for practical application, particularly in high-stakes scenarios where accountability and validation are paramount; experts consistently report a greater willingness to rely on the system’s determinations when presented with these transparent, subgraph-based rationales. The ability to clearly articulate the ‘why’ behind each decision fosters a stronger sense of validation and promotes responsible implementation of the technology.
Generalizability and Future Directions: Beyond Financial Modeling
The Robust Data Learning and Inference (RDLI) framework, initially developed for nuanced financial modeling, exhibits a remarkable capacity for broader application. Evaluation on the Kaggle Credit Card Transactions dataset-a challenge centered on fraud detection-confirms this versatility. This success isn’t merely about achieving high accuracy in identifying fraudulent transactions; it demonstrates the framework’s adaptability to datasets with entirely different characteristics and objectives than those traditionally used in financial risk assessment. The RDLI’s ability to effectively process and interpret non-financial data suggests a foundational strength in data representation and inference, opening avenues for its deployment in diverse fields like cybersecurity, healthcare diagnostics, and predictive maintenance – wherever robust and reliable pattern recognition is paramount.
The study leverages DeepWalk, a technique that generates numerical representations – or embeddings – for each node within the Expert Knowledge Graph. These embeddings capture the structural information of the graph, representing nodes with similar network connections as being closer together in a high-dimensional vector space. By translating the complex relationships within the knowledge graph into these dense, low-dimensional vectors, DeepWalk facilitates several downstream tasks, including node classification, link prediction, and anomaly detection. The resulting node embeddings provide a powerful mechanism for reasoning about the expertise represented within the graph, enabling the system to identify relevant experts and understand the nuances of their knowledge domains, ultimately enhancing the accuracy and reliability of the broader reasoning framework.
Ongoing research prioritizes a more seamless convergence of Large Language Models (LLMs) with the RDLI framework, aiming to enhance both performance and nuanced understanding of complex data. Simultaneously, investigations are underway to identify and implement explainability techniques that move beyond the limitations of SHAP values-a commonly used method-in accurately reflecting the true drivers of model predictions. This pursuit of higher-fidelity explainability is crucial for building trust and facilitating informed decision-making, particularly in sensitive applications where understanding why a model arrived at a specific conclusion is as important as the prediction itself. The development of these advanced interpretability tools will not only bolster the reliability of the RDLI framework but also contribute to the broader field of explainable artificial intelligence.
The pursuit of robust anomaly detection, as detailed in this work, demands more than empirical success; it necessitates provable correctness. This aligns perfectly with Robert Tarjan’s assertion: “If it feels like magic, you haven’t revealed the invariant.” The Relational Domain-Logic Integration (RDLI) framework doesn’t merely find anomalies, it grounds its reasoning in explicit domain knowledge and verifiable relational structures. By integrating expert insights-the ‘invariant’-into the graph neural network, RDLI moves beyond opaque predictions. The system’s path-level explanations aren’t afterthoughts, but inherent components of the solution, making the detection process transparent and auditable, thus moving away from treating it as a black box. This emphasis on provability and transparency is crucial for compliance with regulations like the FATF Travel Rule and for building trustworthy financial systems.
What’s Next?
The pursuit of anomaly detection, particularly within the labyrinthine world of financial transactions, perpetually circles the issue of verifiable truth. This work, while demonstrating the potential of knowledge integration, merely shifts the burden of proof, rather than resolving it. The reliance on expert-defined domain logic introduces a new fragility: the system’s accuracy is now fundamentally bound to the completeness and correctness of that knowledge – a proposition that invites scrutiny. Reproducibility remains the core challenge; a model’s decision, however ‘explainable’ via path-level analysis, is ultimately a black box if the underlying knowledge graph cannot be independently validated and consistently applied.
Future work must address this fundamental epistemological issue. The current focus on ‘extreme label scarcity’ is a practical concern, but misses a deeper point: scarcity of provable labels is the true impediment. Systems that cannot demonstrably justify their classifications – tracing every inference back to first principles – will remain susceptible to error, and therefore unreliable. Simply scaling graph neural networks or refining retrieval mechanisms offers diminishing returns without a corresponding emphasis on logical rigor.
The aspiration of auditability, framed within the context of FATF compliance, demands more than post-hoc explanations. It requires a system built on deterministic foundations, where every conclusion is a logical consequence of the input data and the explicitly defined rules. Until that level of mathematical purity is achieved, anomaly detection will remain a probabilistic exercise, and financial crime, a persistent statistical inevitability.
Original article: https://arxiv.org/pdf/2601.12839.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Top 20 Dinosaur Movies, Ranked
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Gold Rate Forecast
- Spotting the Loops in Autonomous Systems
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Celebs Who Narrowly Escaped The 9/11 Attacks
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
2026-01-22 05:53