Author: Denis Avetisyan
Improving the quality of training data is crucial for building more accurate and reliable intent recognition systems, and a new approach focuses on identifying and correcting ambiguous examples.
This paper introduces DDAIR, an iterative disambiguation method leveraging sentence transformers and large language models to enhance data augmentation for intent recognition tasks.
While large language models excel at generating synthetic data for tasks like intent recognition, they can inadvertently create ambiguous examples that blur the lines between different user intents. This paper, ‘How DDAIR you? Disambiguated Data Augmentation for Intent Recognition’, addresses this challenge by introducing DDAIR, an iterative method leveraging sentence transformers to detect and regenerate potentially confusing utterances. Our findings demonstrate that identifying and refining these ambiguous examples-those semantically closer to unintended intents-significantly improves data quality and classification performance, particularly in low-resource scenarios. Could this approach unlock more robust and reliable intent recognition systems, even with loosely defined or overlapping intents?
The Inevitable Scarcity of Signal
The pursuit of accurate intent recognition is fundamentally constrained by the need for extensive, meticulously labeled datasets. While machine learning models demonstrate impressive capabilities with ample training examples, their performance diminishes considerably when confronted with limited data – a common challenge, especially when dealing with specialized fields like medical diagnosis or financial services. Creating these datasets is not merely a matter of collection; it demands significant human effort to annotate user utterances with the correct intent, a process that is both time-consuming and expensive. The complexity increases further when nuances and subtle variations in language are present, requiring expert knowledge to ensure annotation accuracy. Consequently, the scarcity of labeled data acts as a major bottleneck, hindering the development and deployment of robust intent recognition systems in many practical applications.
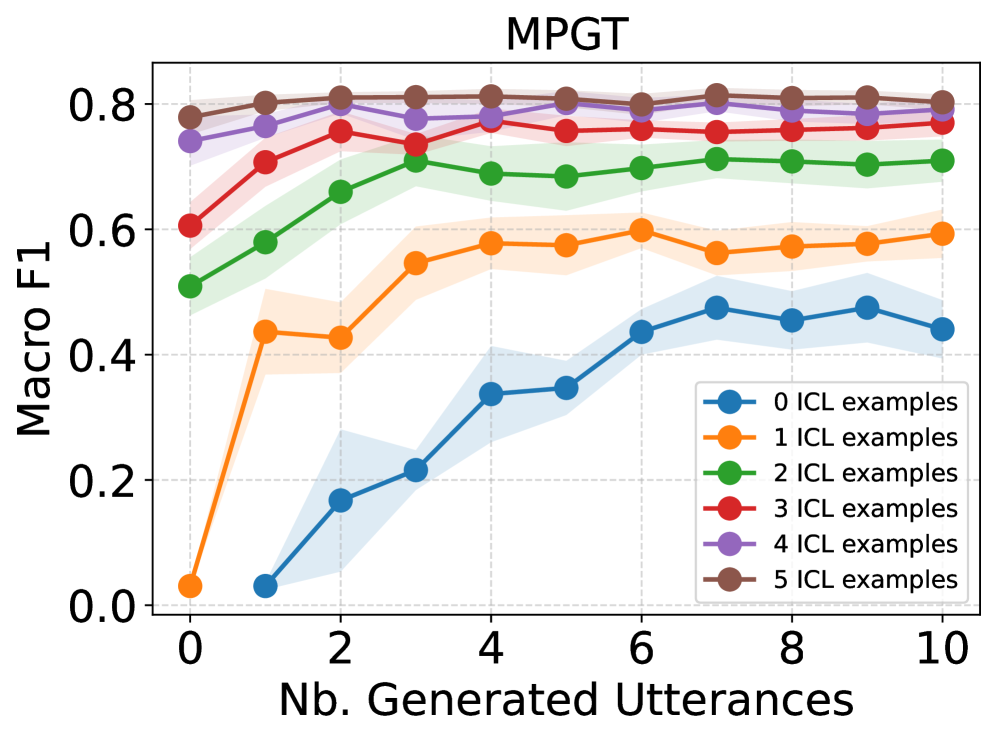
Current approaches to intent recognition, often benchmarked against datasets like CLINC150, MPGT, and BANKING77, demonstrate limited ability to adapt when faced with insufficient training data. These corpora, while valuable for establishing baselines, frequently fail to provide the breadth of examples needed for robust performance in real-world applications where nuanced requests or specialized terminology are common. The reliance on pre-defined intents within these datasets also hinders generalization; models struggle to accurately classify user requests that deviate slightly from the training data or involve previously unseen intents. This lack of adaptability poses a significant challenge for deploying intent recognition systems in low-resource domains or rapidly evolving environments, necessitating the development of techniques that can effectively learn from limited examples and generalize to unseen scenarios.
Evaluations of advanced natural language processing models, such as BERT, consistently demonstrate a performance ceiling when training data is limited, as measured by the Macro-F1 Score. While these models excel with abundant datasets, gains in intent recognition accuracy diminish significantly – typically plateauing at around a 2-3% improvement – as the volume of labeled data decreases. This limitation poses a substantial challenge for practical deployment in real-world scenarios, particularly within specialized domains where data annotation is expensive and time-consuming. Consequently, even sophisticated architectures struggle to generalize effectively from sparse examples, restricting their usability and necessitating the development of alternative strategies to overcome data scarcity.
Synthetic Data: A Temporary Reprieve
Synthetic data generation provides a viable solution to the limitations imposed by insufficient training data, a common obstacle in developing robust machine learning models. By artificially expanding datasets, developers can overcome data scarcity, particularly for rare or sensitive scenarios where real-world data acquisition is difficult or impractical. This technique improves model generalization by exposing the model to a wider range of examples, enhancing its ability to perform reliably on unseen data and reducing the risk of overfitting to the existing, limited dataset. The artificially created data supplements real-world data, boosting model performance and overall robustness without the constraints of traditional data collection methods.
The application of Large Language Models (LLMs) for synthetic data generation is growing, yet unconstrained generation often yields suboptimal results. LLMs, while capable of producing text resembling real-world data, can introduce semantic ambiguity, logical inconsistencies, or statistically improbable phrasing. This “naive” generation process doesn’t inherently guarantee data quality; generated utterances may lack the nuance or specificity required for effective model training, potentially increasing noise and degrading the performance of machine learning models reliant on this augmented data. Specifically, LLMs may generate paraphrases that alter the original meaning or introduce irrelevant details, leading to decreased accuracy and reliability in downstream tasks.
Maintaining the quality and relevance of synthetically generated utterances is crucial for successful data augmentation. Techniques to achieve this include constrained generation, where the language model is guided by specific keywords, templates, or grammatical rules to ensure output aligns with desired characteristics. Furthermore, employing filtering mechanisms, such as perplexity scoring or semantic similarity checks against real data, can remove low-quality or irrelevant examples. Active learning strategies, where generated data is evaluated by human annotators or a validation model, enable iterative refinement of the generation process and enhance the overall utility of the synthetic dataset. Without these quality control measures, synthetic data can introduce noise, bias, or ambiguity, ultimately diminishing the performance gains expected from data augmentation.
DDAIR: Sculpting Clarity from the Void
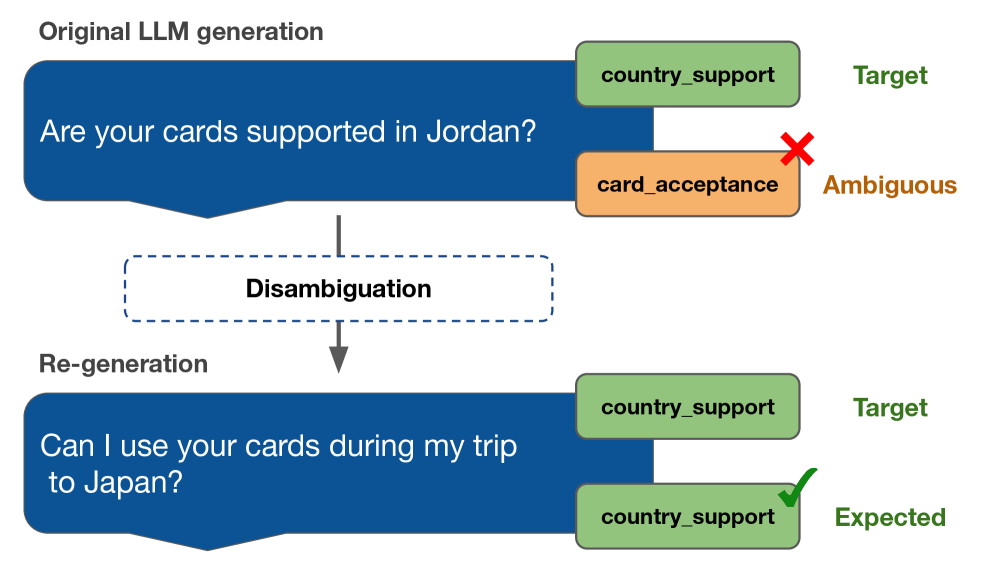
DDAIR employs Sentence Transformers, a class of models designed to produce dense vector representations of sentences, to assess the ambiguity of generated synthetic utterances. These transformers are utilized to encode each utterance into a vector embedding, and cosine similarity is then calculated between embeddings of utterances intended to represent the same underlying meaning. Utterances exhibiting low similarity scores-below a predetermined threshold-are flagged as potentially ambiguous, as they indicate variations in semantic representation despite a shared intended meaning. This flagging mechanism focuses on identifying instances where the model might struggle with consistent classification due to semantic variance within the synthetic dataset, thereby pinpointing examples requiring further refinement.
Upon identifying ambiguous utterances within synthetic datasets, DDAIR employs Large Language Models (LLMs) for regeneration. This process leverages In-Context Learning, where the LLM is provided with a small number of example utterances paired with their clear and unambiguous paraphrases. This contextual priming guides the LLM to produce revised versions of the flagged ambiguous utterances, prioritizing clarity and relevance to the intended meaning. The LLM effectively learns to map potentially confusing phrasing to more easily understood alternatives, thereby improving the overall quality and utility of the synthetic data for downstream tasks.
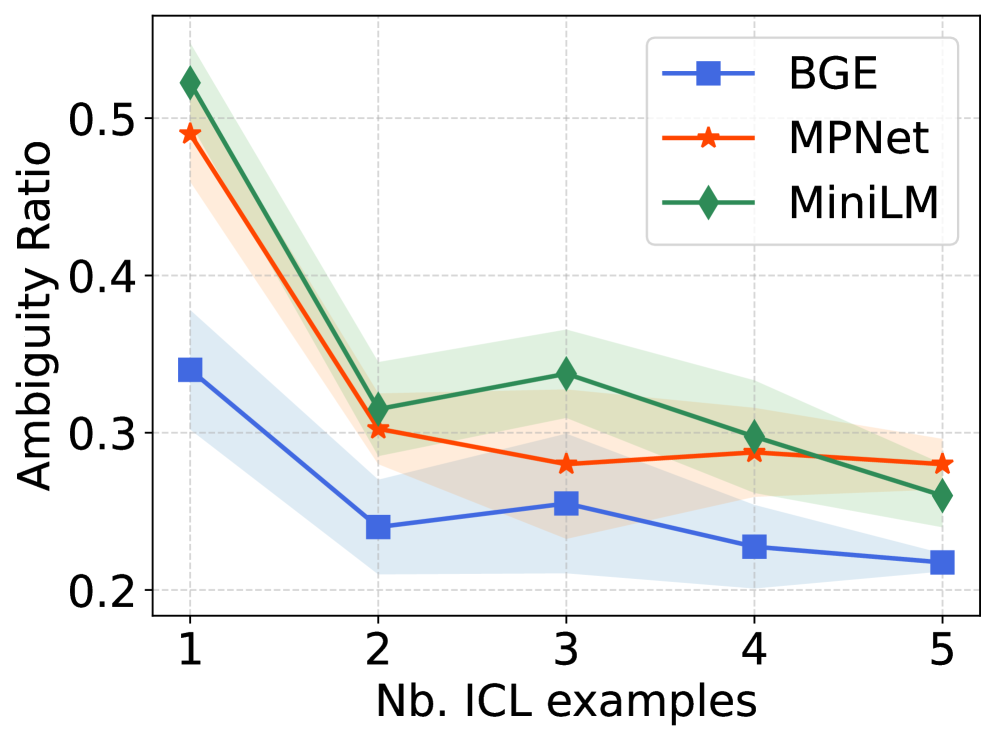
The DDAIR process demonstrably improves synthetic dataset quality through iterative disambiguation, directly impacting performance in few-shot learning scenarios. Each disambiguation step involves identifying and regenerating ambiguous utterances, resulting in a consistent reduction of ambiguity ratios as measured by the system. This reduction in ambiguity correlates with improved classification accuracy when the synthetic data is used to train models with limited labeled examples, effectively addressing the challenge of data scarcity and enhancing model generalization capabilities. Quantitative analysis demonstrates that successive iterations consistently lower ambiguity levels, providing a measurable metric for dataset refinement and predictive performance gains.
The Illusion of Completion: Measuring True Signal
Evaluating the fidelity of synthetically generated conversational data requires robust quality assessment, and the Silhouette Coefficient serves as a key metric in this process. This coefficient quantifies how well each generated utterance aligns with its designated intent, effectively measuring the compactness of intent-specific clusters within the generated data. A higher Silhouette Coefficient – ranging from -1 to 1 – indicates stronger similarity amongst utterances belonging to the same intent and clearer separation from those of differing intents. This internal cluster validation technique provides a quantifiable measure of data quality, ensuring that the synthetic data not only expands dataset size but also maintains the semantic integrity necessary for training accurate and reliable conversational AI models. By rigorously assessing the similarity of generated utterances to their intended meaning, researchers can confidently leverage synthetic data to overcome the limitations of scarce real-world data.
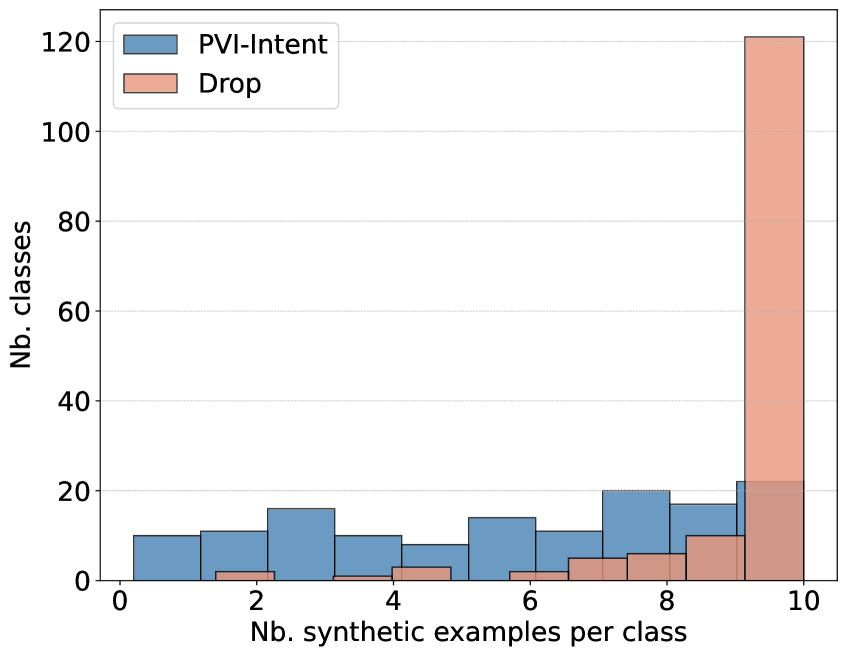
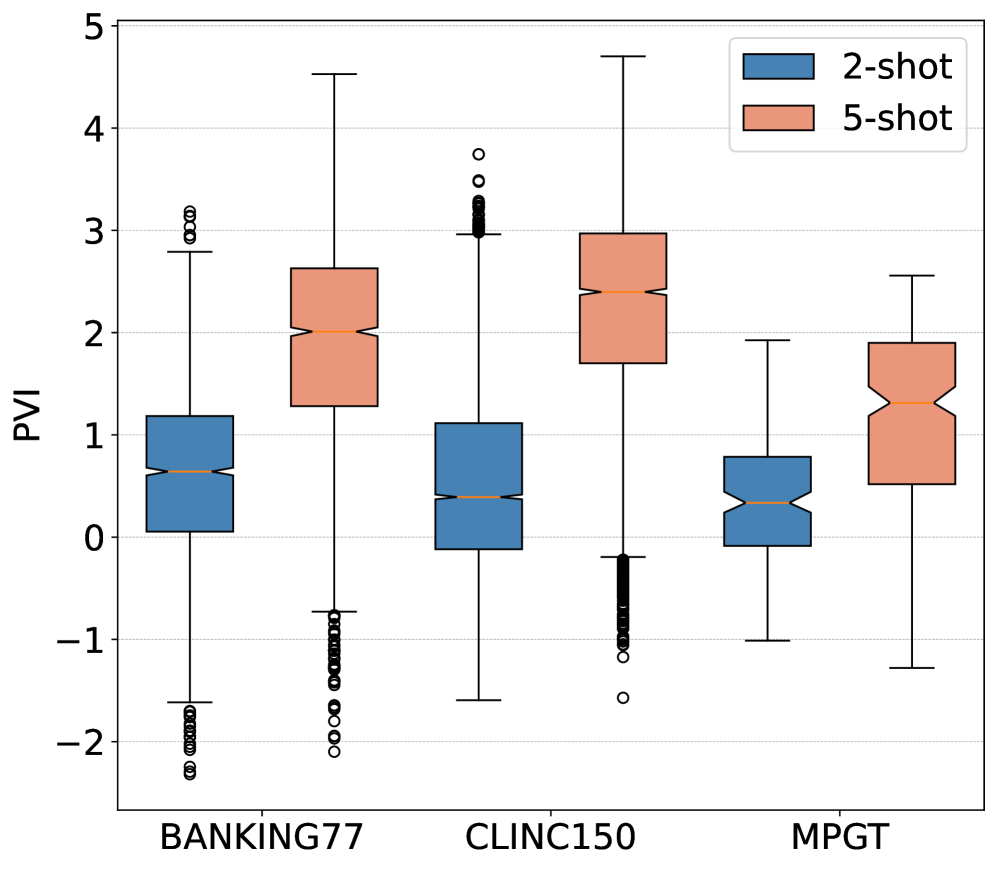
Pointwise V-Information (PVI) serves as a crucial diagnostic for evaluating the utility of synthetically generated data, specifically assessing how much information each generated utterance contributes to accurate intent classification. Unlike metrics focused on data similarity, PVI directly quantifies the informativeness of the synthetic examples – a high PVI score indicates the generated data effectively helps a classifier distinguish between different user intents. This is achieved by measuring the mutual information between the generated utterance and its associated intent label; essentially, it determines if the utterance reliably signals that specific intent. Consequently, a robust synthetic data generation process, like DDAIR, aims not just to mimic existing data, but to produce examples that maximize PVI, thereby boosting the performance of intent recognition models, especially when real-world training data is limited.
Evaluations confirm that DDAIR consistently produces synthetic data of demonstrably high quality, directly translating into gains in intent recognition performance. Specifically, the system exhibits a marked advantage in situations where training data is limited – a common challenge in natural language understanding. Benchmarking on the MPGT corpus revealed improvements of up to 6% in Macro-F1 scores, a key metric for evaluating classification accuracy. Further reinforcing this finding, the Silhouette Coefficient, which measures data cluster cohesion, consistently increased with each disambiguation step within DDAIR, indicating that the generated data becomes increasingly refined and representative of the intended intents. This suggests that DDAIR not only expands the available training data but also enhances its utility for building more robust and accurate intent recognition models.
The pursuit of robust intent recognition, as detailed in this work, mirrors a gardener tending to a complex ecosystem. One cannot simply build a system to flawlessly understand user intent; rather, it must be cultivated through iterative refinement. This paper’s DDAIR method, with its focus on disambiguation and regeneration of synthetic utterances, embodies this principle. It acknowledges that ambiguity isn’t a bug to be eradicated, but a natural element to be addressed through constant, forgiving adaptation. As Henri Poincaré observed, “It is through science that we obtain limited, but increasing, knowledge.” DDAIR doesn’t promise perfect understanding, but a measured, iterative approach to lessening the unknown – a garden carefully grown, not rigidly constructed.
The Turning of the Wheel
This work, in its attempt to refine the synthetic, reveals a truth often obscured by the pursuit of larger datasets: quality is not a property of data, but a negotiation with time. Every augmented utterance is a promise made to the past, a belief that current understanding will remain sufficient. The iterative disambiguation offered by DDAIR is a temporary reprieve, a slowing of entropy. It does not solve the fundamental problem – the inevitable drift between model and meaning – but merely delays the moment of reckoning.
The reliance on large language models for correction introduces a fascinating dependency. The system, striving for clarity, increasingly mirrors the biases and limitations of its oracle. Control, it seems, is an illusion that demands service level agreements, even with oneself. Future work will not be about achieving perfect augmentation, but about building systems that gracefully degrade, that recognize and adapt to their own internal inconsistencies.
One anticipates a shift in focus, from the creation of data to the cultivation of resilience. Everything built will one day start fixing itself. The true measure of success will not be intent recognition accuracy, but the capacity to learn from – and even embrace – ambiguity. The wheel turns, and the synthetic will always seek to become something other than what it was intended.
Original article: https://arxiv.org/pdf/2601.11234.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Top 20 Dinosaur Movies, Ranked
- Silver Rate Forecast
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Top 10 Coolest Things About Invincible (Mark Grayson)
- When AI Teams Cheat: Lessons from Human Collusion
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- Unmasking falsehoods: A New Approach to AI Truthfulness
2026-01-20 21:54