Author: Denis Avetisyan
New research explores how analyzing internal model states can effectively detect malicious prompts targeting large language models, offering a practical defense against emerging cybersecurity risks.
This paper details advancements in activation probing techniques to identify and mitigate cyber-offensive inputs in large language models, addressing challenges related to distribution shift and long-context processing with a novel approach utilizing cascading classifiers and AlphaEvolve.
Despite rapid advances in large language model capabilities, ensuring their safe deployment requires robust misuse detection techniques that generalize beyond training data. This is the challenge addressed in ‘Building Production-Ready Probes For Gemini’, which investigates activation probing as a computationally efficient method for identifying malicious prompts. The authors demonstrate that improved probe architectures, coupled with training on diverse distributions, are crucial for handling distribution shifts-particularly those arising from long-context inputs-and achieving broad generalization. With these advancements informing successful deployment in Google’s Gemini model, can automated techniques like AlphaEvolve further accelerate the development and adaptation of AI safety measures?
The Evolving Landscape of Deceptive Prompts
Large language models, despite their impressive capabilities, are vulnerable to a growing class of attacks termed ‘jailbreaking’. These attacks don’t involve traditional hacking, but rather the skillful crafting of prompts – seemingly innocuous inputs – designed to bypass the model’s built-in safety mechanisms. Adversaries exploit subtle linguistic patterns and ambiguities to trick the LLM into generating harmful, biased, or otherwise inappropriate content. This circumvention isn’t a failure of the model’s core intelligence, but a demonstration of its susceptibility to cleverly disguised instructions. The challenge lies in the fact that these prompts are constantly evolving, becoming increasingly sophisticated and difficult to detect with static defenses, requiring continuous adaptation and refinement of safety protocols to maintain responsible AI operation.
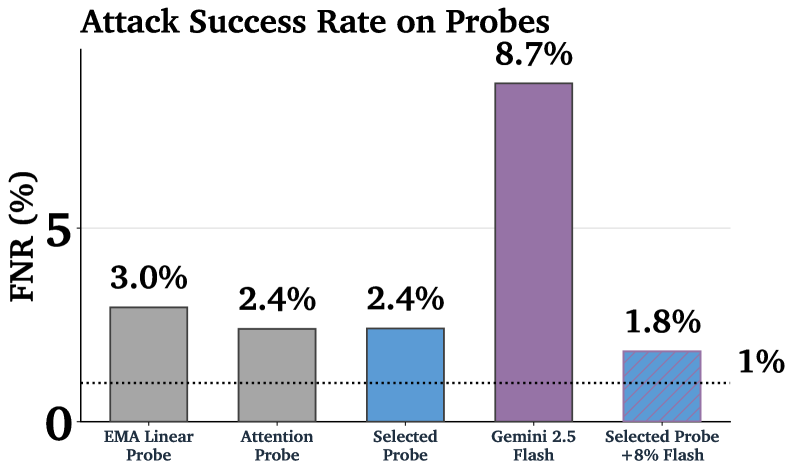
Detecting malicious intent in interactions with large language models is paramount, yet current cybersecurity measures consistently lag behind the ingenuity of those crafting harmful prompts. Standard detection techniques, often reliant on identifying pre-defined patterns of abusive language, are easily bypassed through the creation of ‘adversarial examples’ – subtly altered prompts designed to circumvent safeguards while still eliciting a harmful response. These attacks don’t necessarily involve overtly malicious phrasing; instead, they cleverly exploit the model’s understanding of language to achieve the desired, undesirable outcome. The constant arms race between defenders and attackers necessitates a move beyond simple pattern matching towards more robust systems capable of understanding the intent behind a prompt, rather than merely its surface-level characteristics, a challenge proving exceptionally difficult to overcome.
The efficacy of current cyber misuse detection systems is significantly undermined by a phenomenon known as distribution shift. These systems, while demonstrating some capability, struggle to maintain performance when confronted with novel attack strategies not present in their training data. This is particularly acute with adaptive attacks, where the adversarial prompt itself evolves in response to the model’s defenses, effectively ‘learning’ how to bypass safeguards. Consequently, even sophisticated defense mechanisms consistently allow a small but concerning percentage – exceeding 1% – of harmful prompts to succeed, highlighting a critical vulnerability as attackers continually refine their techniques to exploit the limitations of fixed training datasets and static detection methods. This ongoing arms race necessitates the development of more robust and generalizable detection strategies capable of anticipating and countering unseen adversarial patterns.
Peering Within: Activation-Based Harm Detection
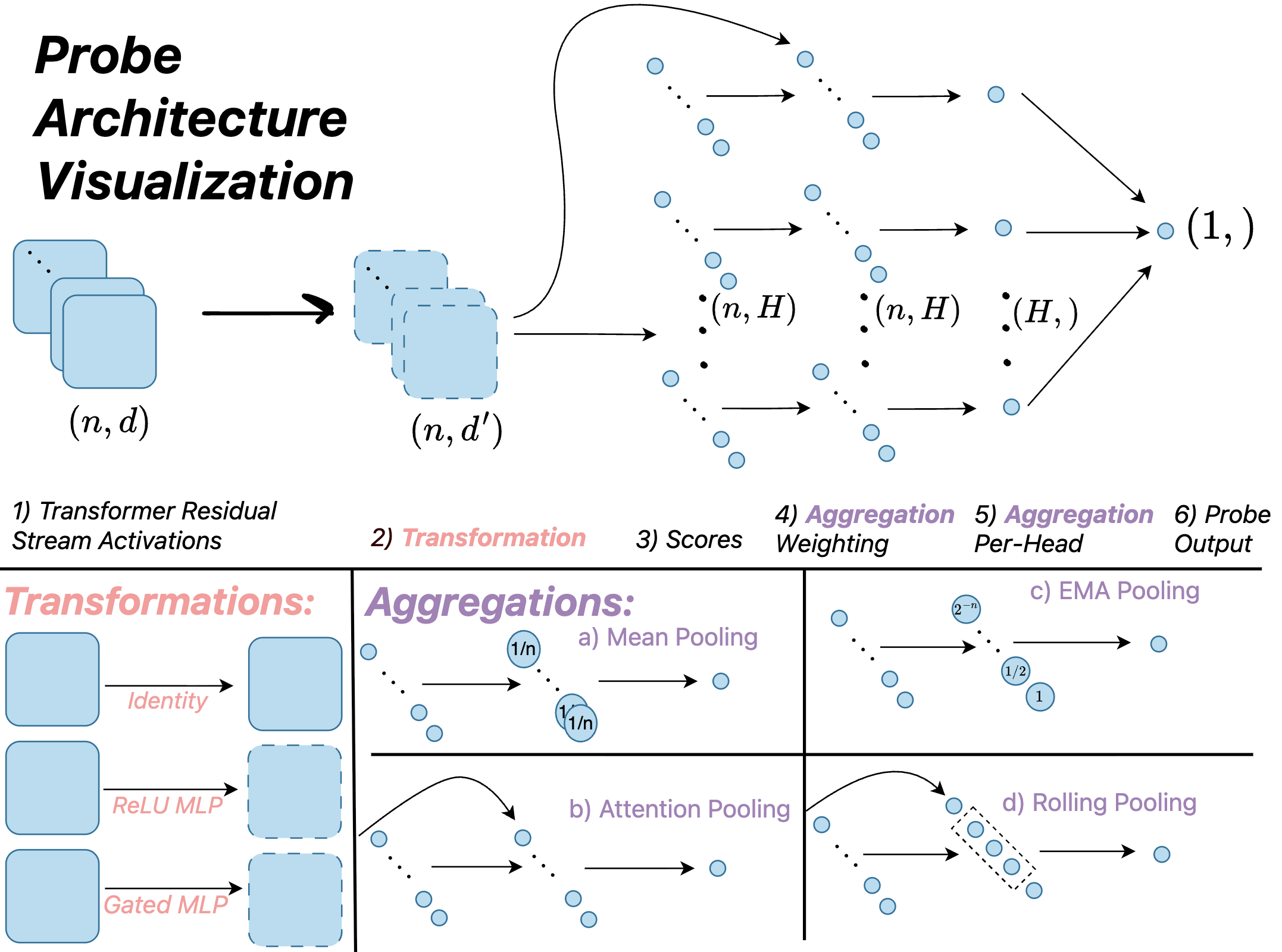
Activation probing represents a detection methodology that moves beyond analyzing solely the input and output of Large Language Models (LLMs) to instead inspect the internal hidden states, or ‘activations’, generated during processing. This approach is predicated on the idea that malicious prompts, even if successfully generating seemingly benign outputs, will elicit distinct activation patterns within the LLM’s layers. By training classifiers on these internal representations, it becomes possible to identify potentially harmful intent that might otherwise go undetected by traditional input/output analysis. The efficacy of activation probing lies in its ability to capture subtle indicators of maliciousness embedded within the model’s processing, offering a more robust defense against adversarial attacks and harmful content generation.
Linear probes represent a foundational activation-based detection method, functioning by training a linear classifier to predict malicious intent based on the activations of a single layer within the Large Language Model (LLM). While straightforward to implement, linear probes are limited in their ability to capture complex relationships within the LLM’s internal states. Attention probes address this limitation by focusing on the attention weights, which represent the relationships between different parts of the input sequence. By analyzing these attention patterns, attention probes can detect more nuanced indicators of malicious intent that a simple linear classifier might miss, offering improved detection accuracy and robustness.
Recent advancements in activation-based detection utilize architectures such as MultiMax Probe and Max of Rolling Means Attention Probe to enhance performance, specifically in long-context generalization tasks. These probes aim to improve upon simpler linear probes by capturing more complex relationships within the LLM’s internal states. Evaluations demonstrate that a long-context trained attention probe achieves a test loss of 2.38%, indicating a measurable improvement in detecting malicious intent or anomalous behavior when processing extended input sequences.
Automated Evaluation: The Self-Refining Probe
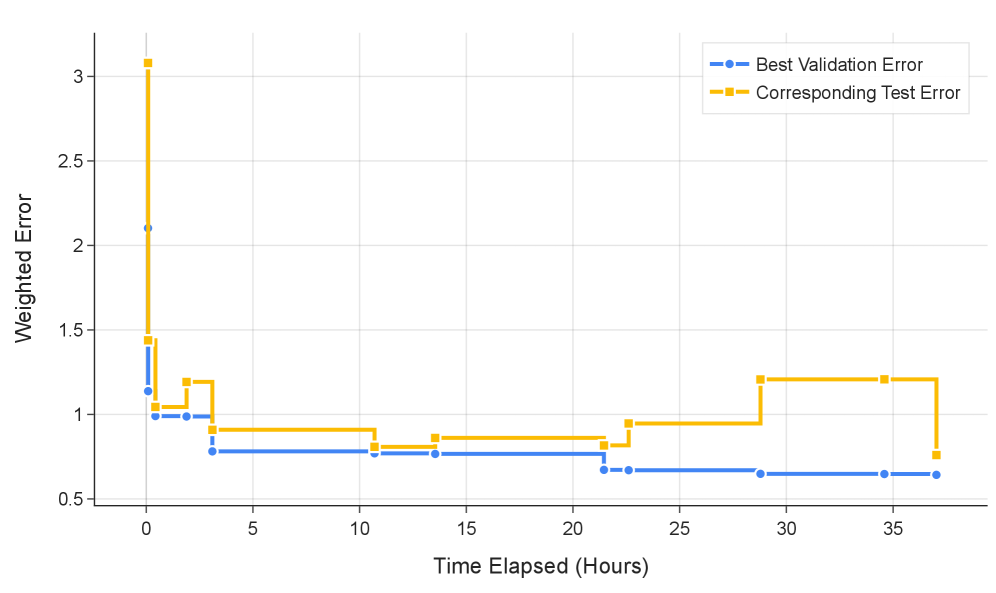
AlphaEvolve is a system that utilizes Large Language Models (LLMs) to autonomously optimize the architecture of probing mechanisms designed to evaluate LLM behavior. This approach departs from traditional, manually-designed probes, enabling automated exploration of various probe configurations. By framing probe design as a prompting task for another LLM, AlphaEvolve iteratively refines probe structures based on performance metrics. The system’s functionality highlights a paradigm shift towards AI-driven security solutions, where LLMs are employed not only as the systems under test but also as tools for generating and improving the evaluation processes themselves.
AlphaEvolve utilizes large language models (LLMs) to iteratively optimize probe architectures for LLM security evaluation. This process resulted in a 2.53% test loss achieved on both the ‘MultiMax Probe’ and ‘Max of Rolling Means Attention Probe’. This performance level is statistically comparable to that of a long-context trained attention probe, indicating that LLM-driven probe optimization can effectively achieve results equivalent to traditional, manually-designed probes. The optimization process involves prompting the LLM to explore variations in probe design, refining the architecture based on performance metrics and achieving improved detection capabilities.
The integration of optimized probes, generated via AlphaEvolve, with existing benchmarks such as ‘HarmBench’ establishes a comprehensive framework for assessing and enhancing LLM resistance to adversarial prompts. Statistical analysis confirms the superior performance of AlphaEvolve-derived probes when compared to baseline evaluation methods; these probes demonstrate a statistically significant improvement in identifying vulnerabilities and quantifying the potential for harmful outputs from LLMs. This framework allows for iterative refinement of LLM safety measures through data-driven evaluation and targeted mitigation strategies, providing a quantitative basis for improving model resilience.
Strategic Resource Allocation: The Cascading Classifier
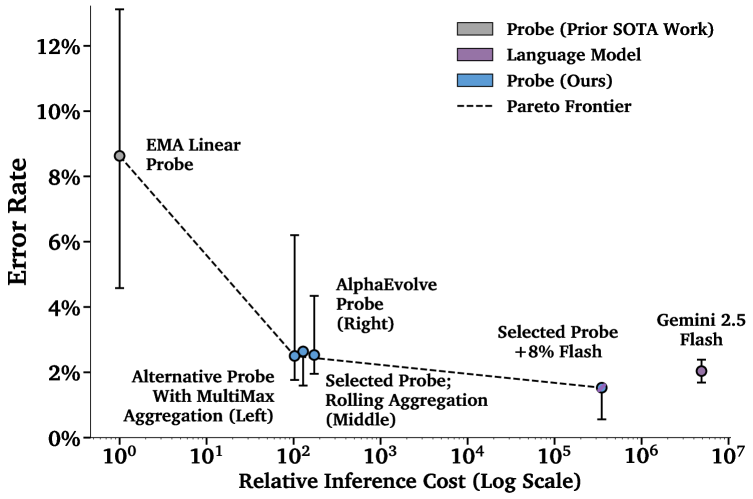
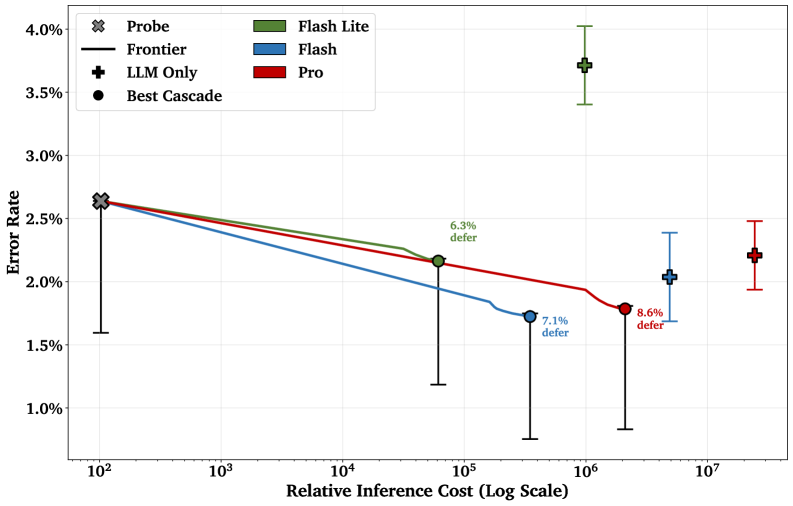
Cascading classifier approaches represent a significant advancement in harm detection by strategically combining computational resources. These systems initially employ a fast, inexpensive ‘probe’ – such as an optimized activation function – to quickly assess the vast majority of inputs. This probe efficiently identifies and flags clearly harmless content, bypassing the need for more intensive analysis. However, when the probe encounters ambiguous or uncertain cases, the system intelligently defers these to a more powerful, yet computationally expensive, language model like Gemini 2.5 Flash or Pro. This tiered approach minimizes the overall demand on the costly LLM, dramatically reducing processing time and financial expense while preserving a high level of accuracy in identifying potentially harmful content.
A key benefit of cascading classifiers lies in their ability to strategically allocate computational resources. Rather than subjecting every input to the scrutiny of a potentially expensive language model, this approach first filters content with a faster, less resource-intensive probe. Only when the probe encounters ambiguity or uncertainty is the input deferred to the more powerful language model for detailed analysis. This selective application dramatically reduces the overall computational burden, leading to significant cost savings without compromising accuracy; the system achieves comparable performance to relying solely on the language model, but at a fraction of the expense, paving the way for practical, large-scale deployment of cyber misuse detection systems.
The deployment of large language models introduces a critical need for robust and scalable misuse detection systems. Current approaches often struggle to balance accuracy with the computational demands of real-time monitoring. However, a cascading classifier architecture presents a viable solution for production environments. By initially filtering content with a computationally inexpensive probe, ambiguous or potentially harmful inputs are flagged for more thorough analysis by a powerful language model. This tiered system dramatically reduces the overall processing cost, enabling continuous, real-time monitoring across numerous concurrent users and applications – a necessity for safeguarding LLM deployments against malicious activity and ensuring responsible AI practices.
The pursuit of robust language model security, as detailed in this study of activation probing, inherently acknowledges the inevitable decay of any system over time. The paper’s focus on mitigating distribution shift and handling long-context inputs represents a continuous effort to fortify the model against unforeseen vulnerabilities-a proactive acceptance that systems aren’t static. This mirrors Donald Knuth’s observation: “Premature optimization is the root of all evil.” While not directly about optimization, the research highlights that anticipating and addressing potential weaknesses-like those introduced by evolving cyber-offensive techniques-is more valuable than assuming a perfect, immutable system. The study’s advancements in probe architecture demonstrate an understanding that continuous refinement, rather than initial perfection, is key to sustained resilience.
The Inevitable Drift
The pursuit of robust activation probing, as demonstrated in this work, merely delays the inevitable. Each refined classifier, each attempt to anticipate adversarial inputs, represents a localized victory against entropy. Yet, language models are not static entities; they are constantly evolving, accumulating subtle shifts in behavior with every training iteration and user interaction. This research rightly acknowledges the challenge of distribution shift, but the true problem is not merely detecting prompts outside the training data – it is the rate at which the model’s internal landscape diverges from any fixed point. Every bug is a moment of truth in the timeline, revealing the fragility of these complex systems.
Future work must move beyond treating misuse mitigation as a purely technical problem. The focus should shift towards understanding the fundamental dynamics of model aging – how do internal representations degrade, and how can these changes be predicted and accounted for? The elegance of AlphaEvolve suggests a path towards adaptable defenses, but adaptation is not prevention. It is simply a slower form of decay.
Ultimately, the cost-effectiveness of activation probing – and indeed, any cybersecurity measure for large language models – is a temporary illusion. Technical debt is the past’s mortgage paid by the present. The question is not whether these systems will fail, but when, and what unforeseen consequences will accompany that failure. The graceful aging of these models, rather than mere resilience, should be the ultimate metric of success.
Original article: https://arxiv.org/pdf/2601.11516.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- Silver Rate Forecast
- Top 10 Coolest Things About Invincible (Mark Grayson)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- When AI Teams Cheat: Lessons from Human Collusion
- Top 20 Dinosaur Movies, Ranked
- Unmasking falsehoods: A New Approach to AI Truthfulness
2026-01-19 22:18