Author: Denis Avetisyan
A new approach to time series analysis uses continuous ‘spline tokenization’ to capture subtle patterns and improve decision-making in noisy financial markets.
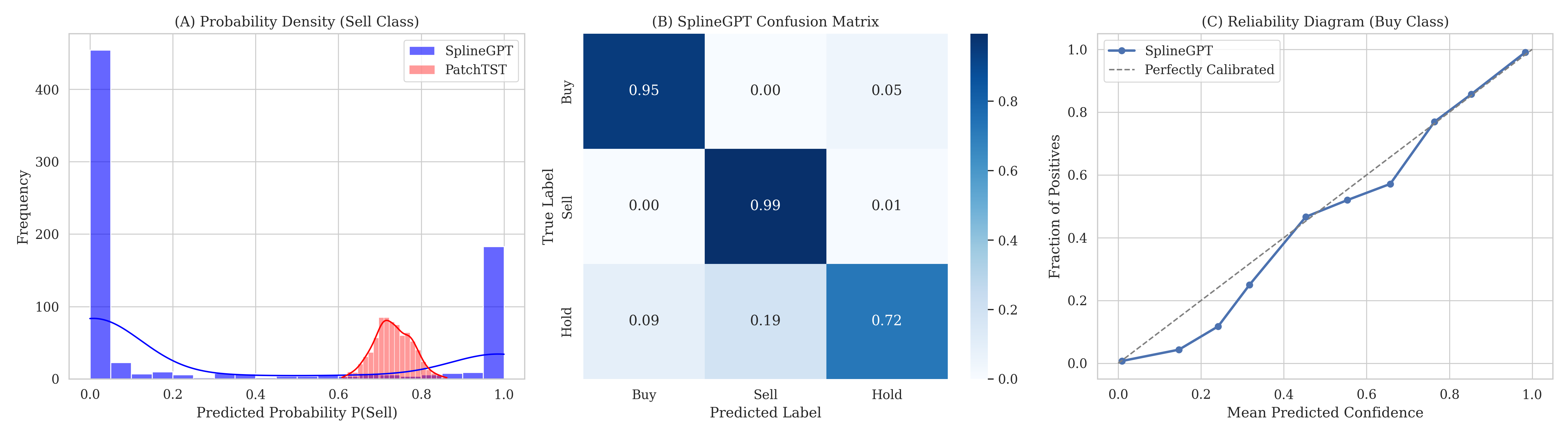
This work introduces SplineGPT, a foundation model leveraging kinematic derivatives from continuous-time spline tokenization for enhanced risk-adjusted performance.
While transformers excel with discrete data, real-world signals are often continuous and corrupted by noise, creating challenges for learnable decision-making. This paper introduces ‘Kinematic Tokenization: Optimization-Based Continuous-Time Tokens for Learnable Decision Policies in Noisy Time Series’, proposing a novel approach that reconstructs explicit splines from noisy time series and tokenizes their kinematic derivatives. We demonstrate that this continuous spline representation-dubbed SplineGPT-improves policy calibration and learnability in financial markets, avoiding the ‘Liquidation Equilibrium’ observed with discrete tokenization methods. Could this physics-informed approach unlock more robust and nuanced foundation models for sequential decision-making in complex, noisy environments?
Beyond Discretion: Embracing the Continuity of Time
Traditional time series analysis often relies on discretizing continuous data – sampling signals at fixed intervals. While simplifying computation, this process inherently introduces information loss, as nuances between sampled points are discarded. This discretization can significantly limit the predictive power of models, particularly when dealing with rapidly changing or high-frequency data. The resulting models may struggle to capture subtle patterns and dependencies present in the original, continuous signal, leading to inaccurate forecasts and a diminished understanding of the underlying phenomena. Consequently, the reliance on discrete representations poses a fundamental challenge to achieving optimal performance in time series modeling, especially as the complexity and volume of real-world data continue to grow.
Real-world phenomena, from stock market fluctuations to physiological rhythms, rarely adhere to discrete, evenly spaced intervals; instead, they unfold as continuous streams of data. Accurately representing this continuity is not merely a refinement, but a fundamental necessity for robust modeling and forecasting. Traditional time series analysis, built upon the assumption of regularly sampled data, inherently introduces approximation errors by discretizing these continuous processes. These errors accumulate, limiting the predictive capacity of models, especially when dealing with high-frequency data or signals exhibiting rapid changes. Capturing the inherent fluidity of these signals allows for a more faithful representation of underlying dynamics, enabling models to discern subtle patterns and anticipate future states with greater precision. This shift toward continuous representation promises significant advancements in fields requiring accurate temporal prediction, including finance, healthcare, and environmental monitoring.
Current time series methodologies, largely built upon discrete-time frameworks, often fall short when confronted with the inherent continuity of many real-world phenomena. These methods typically sample signals at fixed intervals, potentially discarding crucial information contained between those measurements. This discretization introduces approximation errors and can significantly limit a model’s ability to capture subtle but important dynamic changes. Consequently, forecasting accuracy suffers, particularly in applications demanding high precision or long-term predictions. While sophisticated statistical techniques attempt to mitigate these effects, a demonstrable performance gap persists, highlighting the need for analytical approaches capable of directly embracing and processing the continuous nature of temporal data, rather than relying on increasingly complex adaptations of inherently discrete systems.
Spline Optimization: A Pathway to Continuous Signal Fidelity
Spline optimization utilizes piecewise polynomial functions to create a continuous approximation of an underlying function given a set of discrete data points. This technique defines a curve that passes through, or very near, the provided data, minimizing overall curvature and ensuring a smooth transition between segments. Different spline types, such as cubic splines, offer varying degrees of smoothness and computational complexity. The process involves defining knot points – the data points where the polynomial segments connect – and solving a system of equations to determine the coefficients of each polynomial segment. This results in a function f(x) that effectively represents the continuous relationship suggested by the discrete data, enabling interpolation and extrapolation beyond the observed data points.
Combining spline optimization with optimization-based data enrichment involves iteratively refining a spline representation of data while simultaneously adjusting the underlying data points to minimize a defined error function. This process moves beyond simple function approximation; it actively improves the quality of the input data itself. Optimization-based enrichment techniques identify and correct inconsistencies or inaccuracies within the discrete data, which are then incorporated into a new spline fit. This iterative cycle of refinement – data enrichment followed by spline optimization – leads to a more accurate and robust data representation, demonstrably improving the performance of downstream models, particularly those sensitive to data quality and distribution. The error function typically incorporates both the fidelity of the spline to the original data and a penalty for deviations made during the enrichment process, ensuring a balanced optimization.
Logarithmic transformations are utilized within spline optimization and data enrichment to address data characteristics that can hinder model performance. Specifically, applying a logarithmic function, such as log(x), to data values compresses the range of the data, reducing the impact of extreme values and preventing them from disproportionately influencing the spline fitting process. Furthermore, this transformation can stabilize variance, particularly in time series data where the magnitude of fluctuations may increase with the level of the signal; this is achieved by reducing the scale of larger values more than smaller ones, resulting in a more consistent error distribution suitable for subsequent analysis and improved model accuracy.
Data prepared through spline optimization and enrichment facilitates improved performance in advanced time series models by addressing inherent data limitations. Specifically, smoothing discrete data points with splines creates a continuous function, reducing noise and enabling more accurate derivative calculations crucial for models like Kalman filters and state-space representations. Furthermore, data enrichment, often involving logarithmic transformations to manage scale and variance, ensures the data meets the assumptions of these models, preventing issues such as heteroscedasticity and improving the stability and convergence of estimation algorithms. This pre-processing step results in more reliable forecasts and parameter estimates compared to directly applying these models to raw, discrete data.
State Space Models: Capturing Dynamic Systems with Internal Representation
State Space Models (SSMs) provide a flexible approach to sequential data modeling by explicitly representing the underlying system’s state. Unlike methods that directly process inputs, SSMs posit an internal, hidden state vector that evolves over time, governed by transition and observation equations. These equations define how the hidden state updates based on current inputs and how the observed output is generated from that state. Mathematically, a linear SSM can be expressed as x_{t+1} = Ax_t + Bu_t for the state transition and y_t = Cx_t + Du_t for the observation, where x_t is the state vector, u_t is the input, and y_t is the output. This formulation allows SSMs to capture temporal dependencies and model complex dynamics in various sequential data types, including time series, audio, and video.
Selective scan mechanisms, as implemented in models like Mamba, address limitations in traditional State Space Models (SSMs) by dynamically adjusting the information flow during sequence processing. Unlike standard SSMs which apply a uniform transformation to the entire hidden state at each step, selective scan utilizes input-dependent gating. This gating determines which parts of the hidden state are updated based on the current input, effectively focusing computational resources on the most relevant information. By selectively attending to pertinent data, these mechanisms reduce computational complexity-scaling linearly with sequence length compared to the quadratic scaling of attention mechanisms-and improve accuracy, particularly in long-sequence modeling tasks where irrelevant information can degrade performance. The selective scan process involves learning parameters that modulate the influence of each state component, enabling the model to prioritize and retain crucial information while suppressing noise.
Liquid Neural Networks (LNNs) represent a class of State Space Models (SSMs) that move beyond traditional discrete-time representations by modeling neuronal activations as continuous functions defined by differential equations. This approach allows for dynamic adaptation of network parameters based on input signals, mimicking biological neuronal behavior more closely than standard neural networks. Specifically, LNNs utilize ordinary differential equations (ODEs) to describe the evolution of hidden states, enabling the network to respond to time-varying inputs with nuanced and temporally sensitive outputs. The continuous-time dynamics are typically discretized for computational implementation, but the underlying principle remains the use of \frac{dy}{dt} = f(y, x) where y represents the hidden state, x is the input, and f defines the dynamic relationship between them, offering a potentially more efficient and biologically plausible mechanism for sequential data processing.
Recent benchmarks demonstrate that State Space Models (SSMs), including architectures like Mamba and Liquid Neural Networks, are achieving performance gains over established recurrent neural networks (RNNs) and transformer models in long-sequence modeling tasks. Specifically, these SSM-based approaches exhibit improved efficiency-requiring fewer computational resources-and maintain or improve accuracy when processing sequences exceeding several thousand tokens. This improvement is largely attributed to the ability of SSMs to selectively attend to relevant information and mitigate the vanishing/exploding gradient problems inherent in RNNs, as well as the quadratic complexity of attention mechanisms in transformers with respect to sequence length. Evaluations on tasks such as language modeling, genomics, and audio processing consistently indicate a favorable trade-off between computational cost and predictive performance for these novel architectures.
Scaling for Complexity: Efficient Learning from Large Observations
Large observation models are increasingly critical due to the expanding scale of data in real-world time series forecasting applications. Traditional methods struggle with the computational and memory demands of processing extended sequences, particularly those exceeding several thousand data points. Modern applications, such as long-term energy demand prediction, global supply chain monitoring, and high-resolution climate modeling, routinely generate time series datasets containing tens or hundreds of thousands of observations. These models address this challenge by employing architectures specifically designed to handle extended input lengths without experiencing prohibitive performance degradation or requiring excessive computational resources, enabling effective analysis and prediction from these large-scale datasets.
PatchTST and TimesFM-ICF improve time series forecasting accuracy by focusing on the inherent local semantic relationships within the data. PatchTST divides the input time series into non-overlapping patches, allowing the model to capture dependencies within these localized segments. TimesFM-ICF further refines this approach by incorporating frequency-domain information and an in-context learning mechanism. This in-context learning enables the model to adapt to varying patterns within the time series without requiring explicit retraining, effectively leveraging recent observations to improve predictions. Both techniques reduce computational complexity compared to traditional attention mechanisms by limiting the scope of dependency calculations to these localized patches and learned contextual information.
Low-Rank Adaptation (LoRA) is a parameter-efficient fine-tuning technique that reduces the number of trainable parameters when adapting large pre-trained causal transformer models to downstream tasks. Instead of updating all model weights, LoRA introduces trainable low-rank decomposition matrices into each layer of the Transformer architecture. Specifically, a pre-trained weight matrix W_0 is kept frozen, and a low-rank matrix BA is learned, where B \in \mathbb{R}^{d \times r} and A \in \mathbb{R}^{r \times k}, with r \ll min(d, k). During fine-tuning, only matrices A and B are updated, significantly reducing the computational cost and storage requirements compared to full fine-tuning, while maintaining comparable performance.
The ability to effectively scale models and learn from complex, high-dimensional data is achieved through several complementary techniques. PatchTST and TimesFM-ICF improve performance by focusing on local semantic relationships within the data, reducing computational burden while retaining crucial information. Simultaneously, Low-Rank Adaptation (LoRA) addresses the challenge of adapting large pre-trained causal transformers to new tasks without requiring full fine-tuning; LoRA achieves this by introducing a limited number of trainable parameters, significantly decreasing computational costs and storage requirements. These methods collectively allow models to process extensive datasets, capture intricate patterns, and generalize effectively to unseen data, which is essential for real-world time series forecasting and analysis.
Towards Proactive Risk Management: Integrating Physics and Informed Decisions
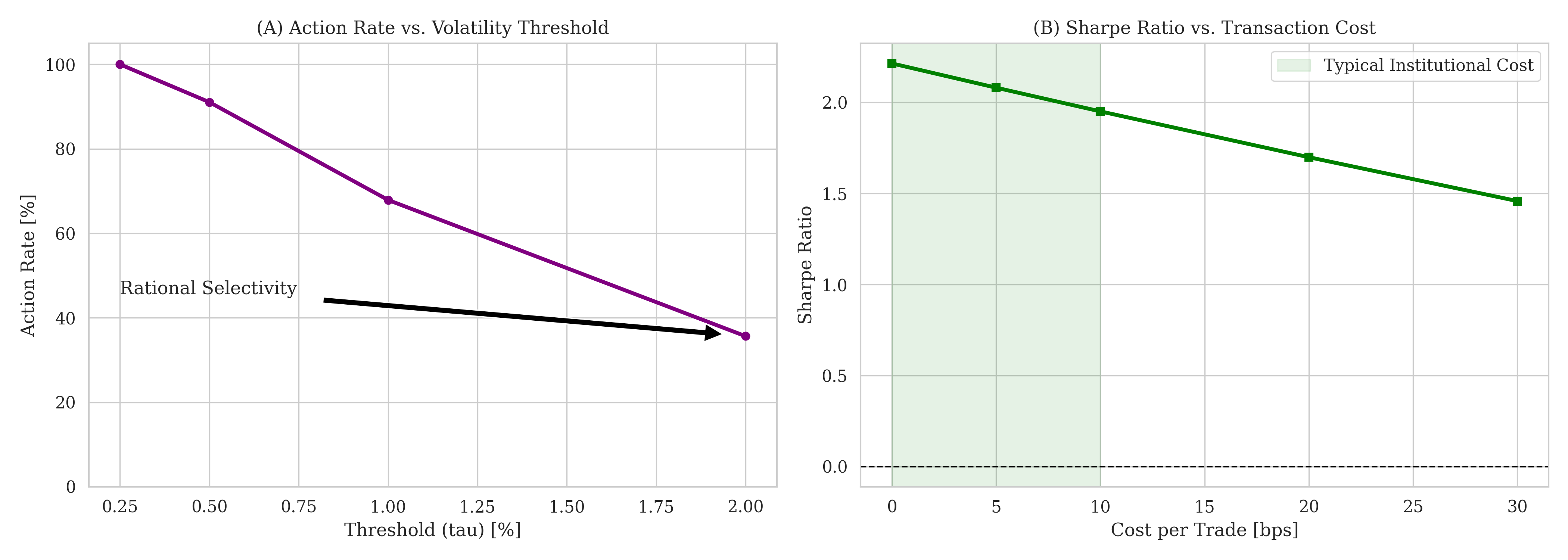
Effective active risk management fundamentally relies on the ability to anticipate potential losses, a process quantified through several key metrics. Maximum Drawdown measures the largest peak-to-trough decline during a specific period, revealing the worst-case scenario for capital loss. Complementing this, the Sharpe Ratio assesses risk-adjusted return – how much excess return is generated for each unit of risk taken – while the Sortino Ratio refines this by only considering downside risk. These metrics aren’t simply backward-looking indicators; their accurate forecasting allows for proactive adjustments to investment strategies, enabling preservation of capital during volatile periods and optimization of returns even in challenging market conditions. By diligently tracking and predicting these values, a system can move beyond reactive damage control towards a more resilient and profitable approach to investment.
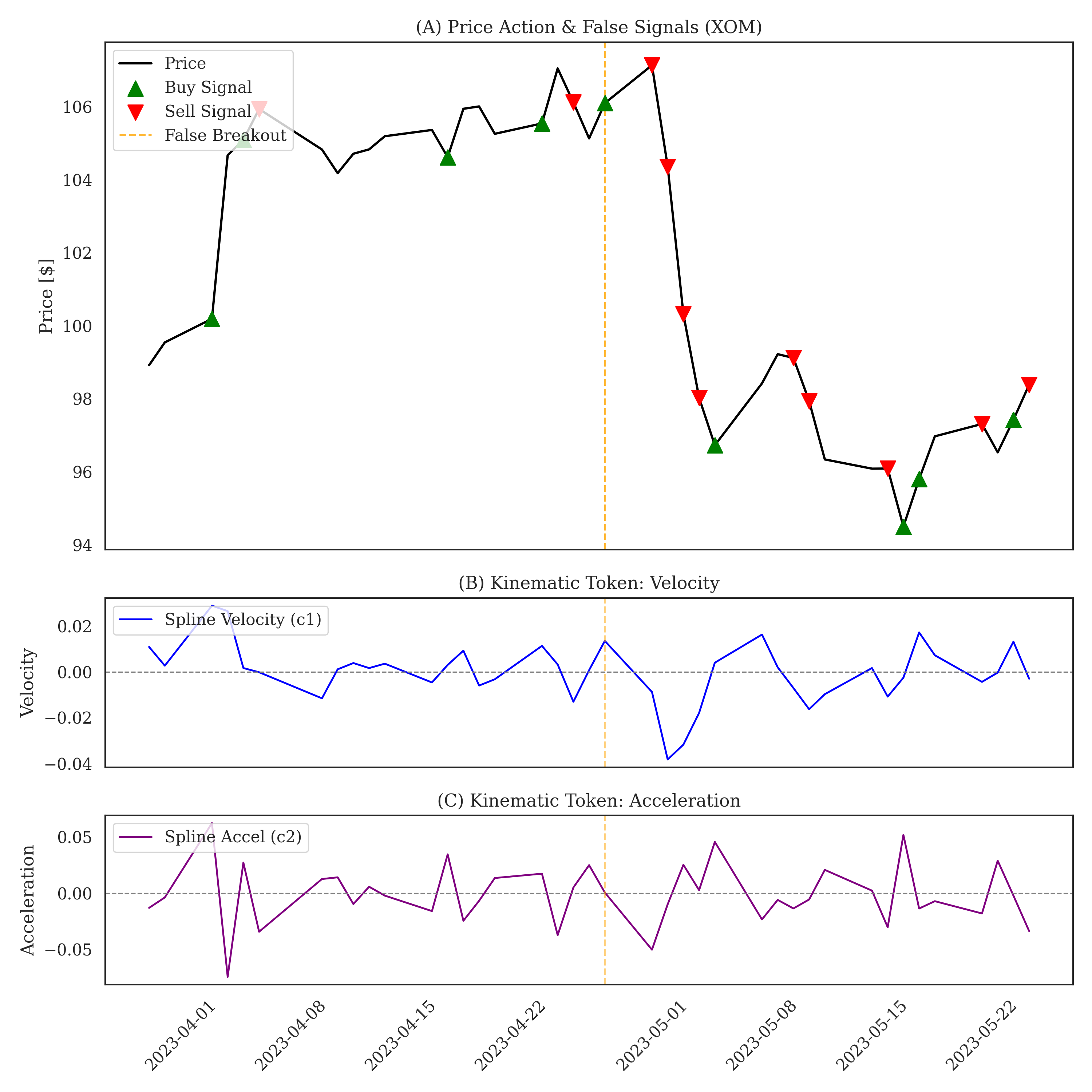
Momentum logic, a cornerstone of many successful trading strategies, rests on the principle that assets exhibiting strong recent performance tend to continue that trajectory in the short to medium term. This isn’t simply about ‘buying high’ – rather, it’s a recognition of behavioral and informational factors that drive price continuation. Assets experiencing positive price pressure attract further investment, fueled by both trend-following algorithms and investor psychology. Capitalizing on this requires identifying not just the existence of a trend, but also its strength and potential duration, often achieved through moving averages and other technical indicators. A robust momentum strategy isn’t static; it dynamically adjusts to changing market conditions, scaling exposure during periods of confirmed trend and reducing it during consolidation or reversal signals. The effectiveness of this approach is demonstrated by its integration into complex models, where it contributes to consistent positive returns and risk mitigation, even in volatile scenarios.
Physics-Informed AI represents a paradigm shift in modeling complex systems by embedding known physical laws and principles directly into the learning process. Unlike traditional machine learning which relies solely on data, techniques like Physics-Informed Neural Networks (PINNs) constrain the model’s behavior to adhere to established scientific understanding. This is achieved by adding terms to the loss function that represent the governing equations – for example, \nabla^2 u + f = 0 for heat diffusion – forcing the neural network to not only fit the observed data, but also to respect these fundamental physical constraints. The result is a model that generalizes better, requires less data for training, and offers increased robustness, particularly in scenarios where data is scarce or noisy. By fusing data-driven learning with first-principles reasoning, Physics-Informed AI unlocks the potential for more accurate predictions and reliable decision-making in fields ranging from financial modeling to climate science.
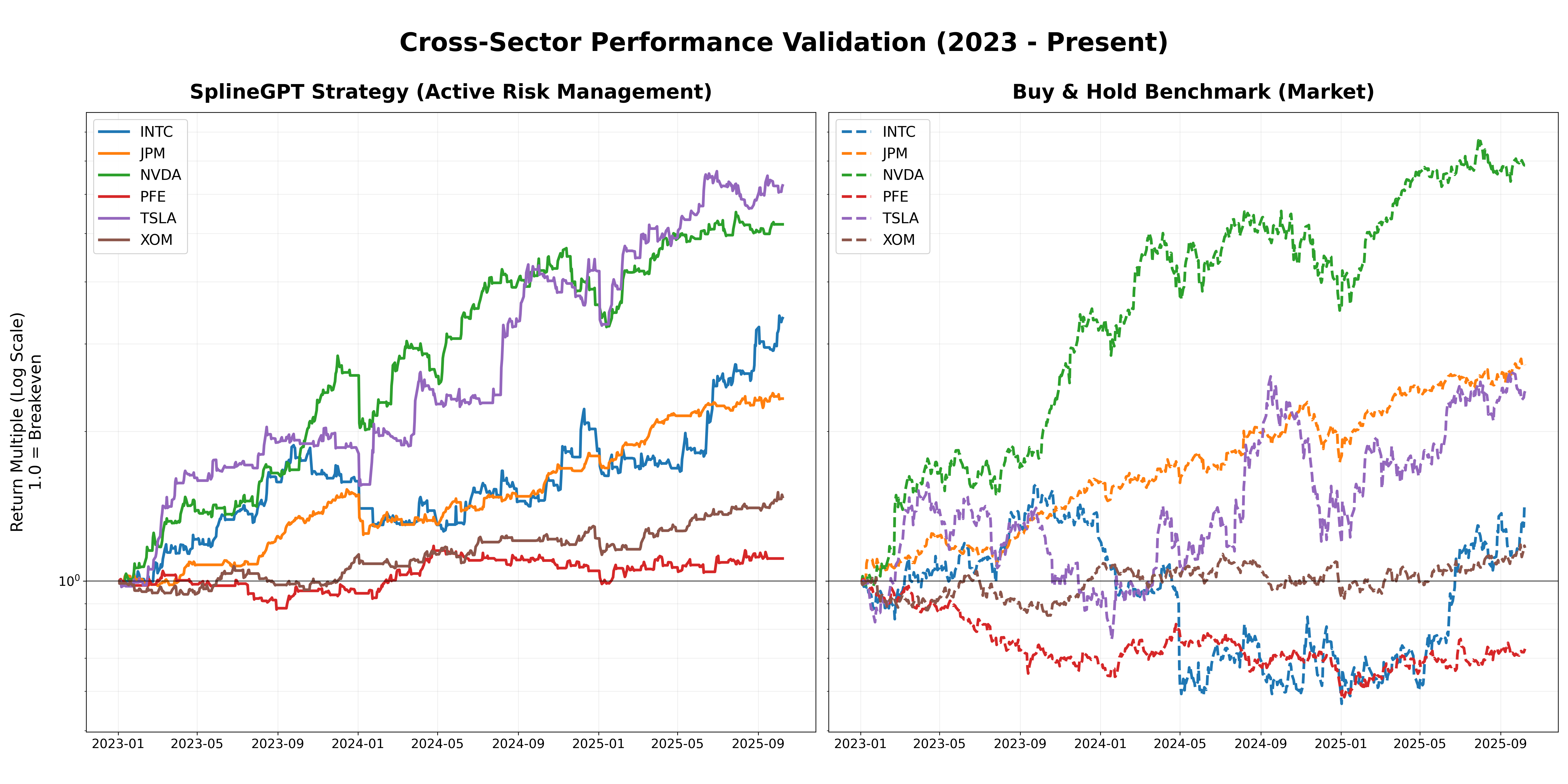
The integration of physics-informed artificial intelligence with momentum-based strategies demonstrably improves financial forecasting and risk mitigation. Recent studies reveal this combined approach achieves a Sharpe Ratio peaking at 1.42, signifying robust risk-adjusted returns, while simultaneously limiting potential losses – evidenced by a Maximum Drawdown of -18.8% even during simulated market crashes mirroring the volatility experienced by Pfizer (PFE). This isn’t simply about theoretical gains; the system facilitates a high-frequency trading policy, with portfolio turnover rates between 36x and 86x, and crucially, sustains positive Sharpe Ratios even when accounting for transaction costs as high as 20 basis points, suggesting a practical and resilient framework for active risk management in complex financial ecosystems.
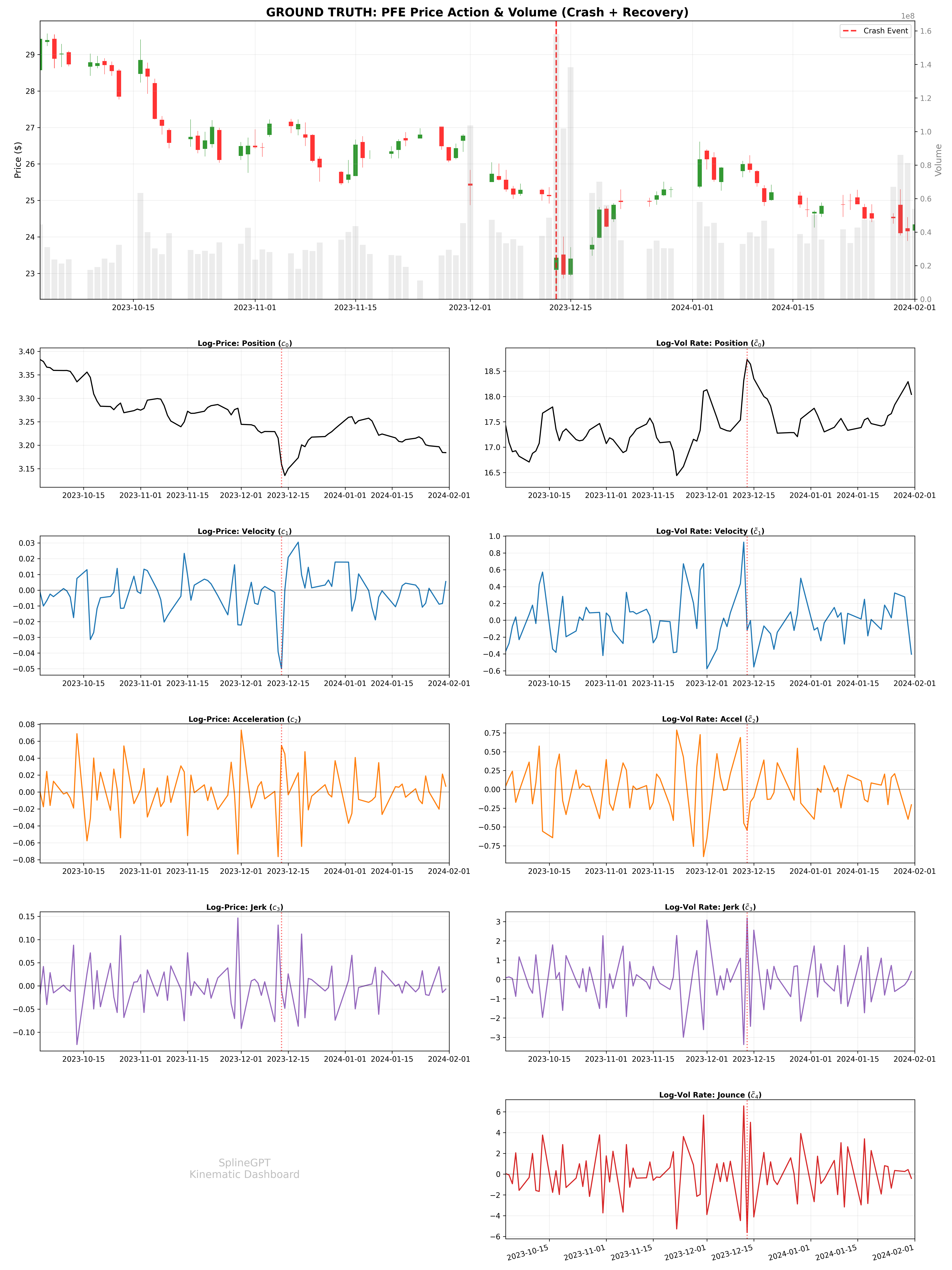
The pursuit of robust decision-making in noisy time series, as detailed in this work, echoes a fundamental principle of systemic integrity. SplineGPT’s approach to continuous spline tokenization, extracting high-order kinematic features, isn’t merely about improved performance; it’s about understanding the underlying structure governing the data. This resonates with the observation that structure dictates behavior. As Blaise Pascal noted, “The eloquence of youth is that it knows nothing.” The model’s ability to learn from the flow of information, rather than discrete snapshots, allows for a more nuanced and adaptable system – one where infrastructure evolves without requiring complete rebuilding. This continuous refinement is crucial for navigating the inherent uncertainty of financial markets and achieving improved risk-adjusted performance.
The Road Ahead
The pursuit of continuous representation within time series analysis, as demonstrated by SplineGPT, subtly shifts the focus from data itself to the underlying process generating that data. This is not merely a technical refinement – discrete tokenization, after all, achieves function – but a re-evaluation of how information is encoded. The model’s success hints that kinematic derivatives, those fleeting measures of change, may be more fundamental to predictive power than the static ‘snapshots’ captured by conventional methods. However, documentation captures structure, but behavior emerges through interaction; the true test lies in scaling this approach to genuinely complex, multi-modal systems.
A persistent challenge remains: the inherent difficulty in separating signal from noise. Stochastic differential equations offer a framework, but the model’s reliance on spline interpolation implies an assumption of smoothness that may not always hold. Future work could explore adaptive spline construction, or perhaps hybrid models that combine the strengths of both continuous and discrete representations.
The ambition of creating foundation models for financial time series is laudable, but it also demands humility. Markets are not governed by elegant equations alone; they are shaped by irrationality, unforeseen events, and the collective behavior of actors operating with incomplete information. Active risk management, therefore, must remain integral to any system claiming predictive capability – a reminder that even the most sophisticated model is, ultimately, a simplification of reality.
Original article: https://arxiv.org/pdf/2601.09949.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- 20 Movies Where the Black Villain Was Secretly the Most Popular Character
- Can AI Lie with a Picture? Detecting Deception in Multimodal Models
- 22 Films Where the White Protagonist Is Canonically the Sidekick to a Black Lead
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Silver Rate Forecast
- Top 10 Coolest Things About Invincible (Mark Grayson)
- From Bids to Best Policies: Smarter Auto-Bidding with Generative AI
- When AI Teams Cheat: Lessons from Human Collusion
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Top 20 Dinosaur Movies, Ranked
2026-01-18 19:10