Author: Denis Avetisyan
Researchers are demonstrating a new method for training autonomous agents to use tools by extracting procedural knowledge directly from natural language text.

This work presents a technique for synthesizing multi-turn tool-use trajectories from text corpora, enabling scalable agent training without requiring predefined tools or extensive reinforcement learning.
Training increasingly capable autonomous agents demands substantial multi-turn interaction data, yet acquiring this remains a persistent bottleneck. This work, ‘Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text’, introduces a novel paradigm for generating such data by extracting implicit tool-use sequences directly from existing text corpora. We demonstrate that this approach, leveraging a pipeline called GEM and a specialized Trajectory Synthesizer, yields significant performance gains-surpassing models trained on curated datasets-and reduces computational costs. Could this text-based synthesis unlock a new era of scalable and generalizable agent training, moving beyond reliance on explicitly defined tools and environments?
The Fragility of Instrumental Action
While Large Language Models (LLMs) demonstrate impressive capabilities in natural language processing, consistently and reliably leveraging tools to solve complex problems presents a substantial challenge. LLMs often struggle to move beyond simple tool applications, failing to generalize to novel scenarios or adapt to tools not explicitly seen during training. This limitation stems from the difficulty in equipping these models with the reasoning and planning abilities necessary to decompose tasks, select appropriate tools, and interpret their outputs in a dynamic, iterative process. Achieving truly robust tool-use requires more than just recognizing tool names; it demands an understanding of how and when to apply them effectively – a level of cognitive flexibility that remains elusive for even the most advanced LLMs.
Current methods for equipping Large Language Models with tool-use capabilities are frequently constrained by the datasets used for training. These datasets are often painstakingly assembled and limited in scope, representing only a narrow range of possible scenarios and tool interactions. This reliance on manually curated data presents a significant bottleneck, as models struggle to generalize beyond the specific examples they’ve been shown. Consequently, performance degrades substantially when confronted with novel tools or unforeseen situations encountered in real-world applications. The lack of diversity in training data inhibits the development of truly adaptable systems, hindering the promise of widespread, reliable tool-augmented intelligence.
Effective tool-use by large language models isn’t simply about knowing what tools exist, but mastering the intricate dance of interaction required to achieve a goal. The challenge resides in generating conversations that aren’t just single requests, but rather complex, multi-turn exchanges – a back-and-forth where the model refines its queries, interprets tool outputs, and adapts its strategy based on the evolving situation. Current systems struggle with this dynamic process; they often falter when faced with tools that demand nuanced prompting or require the model to synthesize information across several interactions. This limitation prevents them from tackling tasks that necessitate genuine problem-solving and hinders their ability to function reliably in open-ended, real-world scenarios, where a single attempt rarely yields the desired outcome.

From Scarcity to Synthesis: The GEM Pipeline
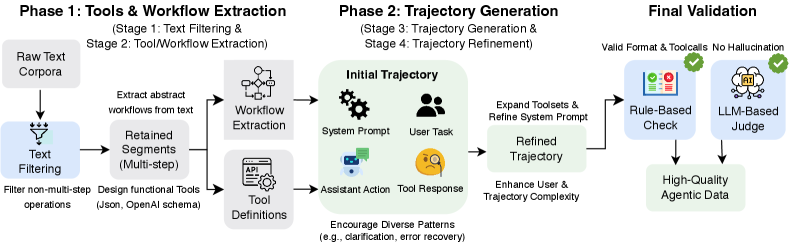
GEM is an automated pipeline designed to synthesize multi-turn trajectories demonstrating tool usage, directly from raw text corpora. This approach contrasts with manual data curation methods by programmatically generating complete dialogues consisting of multiple interactions with various tools. The system processes textual data to construct sequences of tool calls and associated messages, effectively creating simulated user interactions. This automated generation process allows for the creation of large-scale datasets suitable for training and evaluating models designed to interact with tools and APIs, without the limitations imposed by manual annotation efforts.
GEM utilizes a three-stage pipeline to synthesize tool-use trajectories. The process begins with workflow extraction, identifying common sequences of tool interactions from a corpus of text. This is followed by trajectory generation, where GEM constructs complete dialogue trajectories based on the extracted workflows, incorporating variability to create diverse examples. Finally, trajectory refinement ensures the generated trajectories adhere to structural constraints and maintain logical consistency, improving overall data quality and usability. This staged approach prioritizes both the validity of the synthesized interactions and the breadth of coverage within the generated dataset.
GEM addresses the limitations of manually curated datasets for tool-use trajectory analysis by providing a pipeline for automated data synthesis. The resulting datasets are significantly larger in scope and demonstrate increased complexity compared to existing resources; synthesized trajectories average 8.6 distinct tools utilized and 46 messages exchanged per dialogue. This represents a substantial increase over datasets like APIGEN-MT, which averages 18.5 messages per dialogue, and effectively removes the primary bottleneck associated with manual data creation and annotation.
Learning the Language of Action: The Trajectory Synthesizer
The Trajectory Synthesizer is a specifically trained model designed to establish a direct mapping between textual instructions and corresponding trajectories. This dedicated architecture allows for the efficient generation of synthetic data, bypassing the need for complex procedural generation or manual data creation. By internalizing the ‘text-to-trajectory’ relationship, the synthesizer can produce data points representing desired movements or actions based solely on textual prompts, significantly streamlining the data augmentation process for robotics and related fields. The model’s focused training facilitates a more predictable and controllable data synthesis pipeline compared to general-purpose generative models.
Supervised fine-tuning of the Trajectory Synthesizer utilizes a dataset generated by GEM, enabling generalization beyond the initial training corpus. This dataset comprises a diverse range of text prompts paired with corresponding trajectory data, allowing the model to learn the mapping between natural language instructions and desired movements. The robustness of this dataset, characterized by its scale and variability, is critical for mitigating overfitting and enhancing the model’s ability to accurately synthesize trajectories from novel, unseen text inputs. This approach improves performance on tasks not explicitly covered in the initial training data, increasing the model’s overall adaptability and practical utility.
Evaluation of the Trajectory Synthesizer demonstrates successful implementation using both Qwen3-8B and Qwen3-32B base models. Training with data generated by the GEM synthesizer resulted in an accuracy of 28.38%. This performance level is statistically comparable to data generated by the GLM-4.6 model, indicating the Qwen models effectively learn and replicate trajectory data when paired with the GEM training methodology.
Beyond Benchmarks: Implications for Adaptive Intelligence
Rigorous evaluation on established benchmarks confirms the effectiveness of training models with data generated by GEM. Experiments on BFCL V3 reveal a substantial performance increase, with models achieving up to 44.88% accuracy – a marked improvement over those trained on conventional datasets. Furthermore, performance on the τ2-bench demonstrates strong generalization capabilities; models attain a Pass@4 rate of 86.84% within the Retail domain, effectively matching the performance of models trained directly on in-domain data. These results highlight GEM’s potential to not only enhance performance but also to reduce reliance on costly and limited, manually-labeled datasets, paving the way for more adaptable and robust artificial intelligence systems.
The true power of the GEM framework resides in its ability to distill knowledge from the vast, largely untapped reservoir of unstructured text. Unlike traditional methods, dependent on painstakingly curated datasets, GEM learns from the inherent patterns within raw text, fostering agents with heightened generalization abilities. This circumvents the limitations of narrow training data, allowing agents to adapt more readily to novel situations and tasks. Consequently, the framework facilitates the development of agents that aren’t simply proficient within a specific domain, but demonstrate a broader capacity for learning and problem-solving, representing a step towards more versatile and robust artificial intelligence.
The development of robust tool-use capabilities represents a pivotal step toward achieving Artificial General Intelligence, and this work directly addresses that need. Current AI systems often struggle with tasks requiring the flexible application of external tools – a limitation hindering their ability to generalize beyond narrowly defined parameters. By enabling models to effectively learn and utilize tools through data generated with GEM, this research demonstrates a pathway toward creating agents capable of adapting to unforeseen challenges and solving complex problems in dynamic environments. This isn’t merely about improving performance on specific benchmarks; it’s about building foundational intelligence that can reason, plan, and execute actions using available resources – a characteristic of general intelligence and a step toward more versatile and impactful AI systems.
The pursuit of autonomous agency, as detailed in this work concerning tool-use trajectory synthesis, inherently acknowledges the inevitability of system evolution through interaction. The article posits that agents can learn from unstructured text, essentially charting a course through a landscape of implicit experience. This mirrors a fundamental principle of resilient systems: maturity isn’t achieved through flawless design, but through navigating and correcting errors accumulated over time. As Marvin Minsky observed, “Questions are all a form of ignorance reduced to its essential components.” The very act of an agent attempting and refining tool use, derived from textual data, is a process of reducing that ignorance, incrementally building competence through iterative correction-a graceful aging of the system itself.
What Lies Ahead?
The extraction of agency from the static record of text-a fascinating endeavor. This work demonstrates a method for instantiating tool use without explicit definition, a clever sidestep of the limitations inherent in pre-programmed interaction. Yet, it merely shifts the burden. The ‘graceful decay’ of any system built on textual corpora will inevitably manifest as the erosion of contextual understanding. Every bug, every failed trajectory, is a moment of truth in the timeline, revealing the inherent fragility of inference from incomplete data. The question isn’t whether the agent can use a tool, but whether its understanding of why it uses it will resist the entropic pull of time.
The current approach effectively augments existing datasets, but relies on the past to inform the present. This creates a form of technical debt-the past’s mortgage paid by the present’s computational resources. The next iteration will require a mechanism for agents to actively challenge the assumptions embedded in the source text, to generate novel trajectories not merely extrapolated from existing patterns. True autonomy demands a capacity for creative deviation, a willingness to risk failure in the pursuit of a more robust understanding.
Ultimately, this field will be defined not by the sophistication of the models, but by their ability to acknowledge-and even embrace-their own limitations. The pursuit of perfect replication is a fool’s errand; the more interesting path lies in building systems that can adapt, learn, and ultimately, accept their own inevitable obsolescence.
Original article: https://arxiv.org/pdf/2601.10355.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Unmasking falsehoods: A New Approach to AI Truthfulness
- TV Shows That Race-Bent Villains and Confused Everyone
- Smarter Reasoning, Less Compute: Teaching Models When to Stop
- Palantir and Tesla: A Tale of Two Stocks
- How to rank up with Tuvalkane – Soulframe
- Gold Rate Forecast
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
2026-01-18 07:34