Author: Denis Avetisyan
New research introduces a method for automatically identifying mislabeled data points, boosting the accuracy of machine learning models.
This paper presents Adaptive Label Error Detection (ALED), a Bayesian approach utilizing feature space geometry and Gaussian mixture models to improve mislabeled data detection in deep learning datasets.
Despite advances in machine learning, classification systems remain vulnerable to even subtle inaccuracies in training labels, a critical issue as models are deployed in increasingly sensitive applications. This paper introduces a novel approach, ‘Adaptive Label Error Detection: A Bayesian Approach to Mislabeled Data Detection’, which leverages deep feature representations and Gaussian modeling to identify mislabeled samples with improved sensitivity and precision. By denoising feature embeddings and characterizing class manifolds, ALED demonstrably reduces test set errors when models are refined using corrected data-in one instance by over 33%. Could this data-centric method unlock more robust and reliable machine learning systems across diverse domains?
The Inevitable Decay of Data: A Foundation of Error
Machine learning models demonstrate a marked vulnerability to inaccuracies within training datasets, a phenomenon known as label noise, and this is particularly pronounced in the realm of medical image classification. Subtle errors in labeling – misidentifying a tissue type in a scan, for instance – can significantly derail a model’s learning process, leading to diminished diagnostic accuracy and unreliable predictions. Unlike typical data imperfections, label noise doesn’t stem from sensor errors or inherent ambiguity; rather, it originates from incorrect human annotation, and even a small percentage of mislabeled images can cascade into substantial performance degradation. This susceptibility arises from the model’s tendency to overfit to these incorrect labels, essentially learning the wrong patterns and propagating errors throughout its predictive framework, ultimately hindering its capacity to generalize to unseen data and deliver trustworthy results in critical healthcare applications.
The efficacy of machine learning models hinges on the quality of the data used for training, and even a small proportion of incorrectly labeled examples – known as label noise – can dramatically diminish performance and reliability. This degradation isn’t merely a statistical inconvenience; it manifests as reduced accuracy, unpredictable outputs, and a compromised ability to generalize to new, unseen data. Consequently, models trained on noisy datasets struggle in real-world applications, particularly in fields like medical diagnosis where misclassification can have serious consequences. The problem extends beyond simple errors; subtle inconsistencies or ambiguities in labeling can also introduce noise, leading to models that learn spurious correlations and fail to capture the underlying patterns. Addressing this issue is therefore paramount, not simply to improve metrics, but to ensure the practical utility and trustworthiness of machine learning systems.
Conventional machine learning pipelines frequently prioritize model architecture refinement while giving insufficient attention to the quality of the training data itself. This oversight proves particularly detrimental in the presence of label noise – instances where data is incorrectly categorized – as even sophisticated algorithms struggle to learn effectively from flawed foundations. Existing techniques, such as regularization or ensemble methods, often offer only marginal improvements when confronted with substantial label noise, necessitating a paradigm shift towards data-centric artificial intelligence. Robust solutions demand proactive strategies for identifying and correcting mislabeled instances, or for developing algorithms inherently resilient to data imperfections, ultimately paving the way for more trustworthy and dependable machine learning systems.
The pursuit of trustworthy artificial intelligence hinges significantly on the ability to identify and mitigate label noise within training datasets. Machine learning models, despite their increasing sophistication, learn directly from the data they are provided; consequently, inaccuracies in these labels-whether stemming from human error, ambiguous cases, or flawed data collection-can propagate throughout the learning process, leading to unreliable predictions and diminished performance. Addressing this challenge isn’t simply about improving algorithmic robustness, but rather about fundamentally enhancing data quality as a core principle of machine learning development. Effective mitigation strategies, ranging from statistical outlier detection to active learning techniques and consensus-based labeling, are therefore essential for building systems capable of consistently delivering accurate and dependable results, particularly in high-stakes applications like medical diagnosis and autonomous driving where errors can have severe consequences.
Mapping the Landscape of Error: Detection Strategies
Current methodologies for mislabeled data detection are broadly divided into model-centric and data-centric approaches. Model-centric techniques, such as the methods proposed by Reed et al. and Goldberger et al., as well as SCELoss, focus on analyzing model behavior and prediction consistency to identify potentially incorrect labels. Conversely, data-centric methods-including Confident Learning (CL), Mixup, and INCV-examine the inherent characteristics of the data itself, leveraging techniques like data augmentation, consistency training, and probabilistic modeling to detect label inconsistencies without primarily relying on complex model training dynamics.
Model-centric methods for mislabeled data detection operate by analyzing the outputs and internal states of a trained or training model. These techniques commonly utilize prediction consistency; instances where a model produces varying predictions under minor perturbations are flagged as potentially mislabeled. Re-weighting schemes are frequently employed to mitigate the influence of suspected mislabeled data during subsequent training iterations. Examples include assigning lower weights to instances with low confidence scores or high loss values, or dynamically adjusting weights based on the agreement between predictions from multiple models or different training epochs. The complexity of these re-weighting schemes can range from simple thresholding to sophisticated optimization algorithms designed to minimize the impact of noisy labels without discarding potentially valuable information.
Data-centric methods for mislabeled data detection analyze the characteristics of the input data to identify inconsistencies. Consistency training techniques assess whether small perturbations to a data instance alter the model’s prediction, flagging instances where the prediction changes significantly as potentially mislabeled. Data augmentation strategies generate modified versions of existing data points; discrepancies between the original instance and its augmentations can indicate labeling errors. Probabilistic modeling approaches, such as those utilizing Bayesian networks or Gaussian mixture models, estimate the likelihood of a data point belonging to a specific class based on its features; low-probability assignments may suggest mislabeling. These techniques operate independently of the model being trained, directly examining the data’s internal consistency and statistical properties.
Mentor-Net implements a curriculum learning strategy where training samples are prioritized based on the certainty of their assigned labels. This is achieved by training a “mentor” model alongside the primary model; the mentor model predicts the learning difficulty of each sample, and this prediction is used to weight the contribution of each sample to the overall loss function. Specifically, samples with high label certainty, as determined by the mentor, receive greater weight, effectively focusing the training process on more reliable data initially and gradually incorporating potentially mislabeled or ambiguous instances. This approach aims to improve model robustness and generalization by mitigating the negative impact of noisy labels during the early stages of training.
ALED: Deciphering the Feature Space for Accurate Labels
Adaptive Label Error Detection (ALED) addresses data quality by directly examining the feature embeddings generated from input data to identify potentially mislabeled samples. Unlike traditional methods that focus on model adjustments, ALED operates as a data-centric technique, analyzing the inherent properties of the data itself. By representing each sample as a point in a high-dimensional feature space, ALED assesses the consistency of labels relative to the proximity of feature embeddings. This allows the method to flag samples where the assigned label appears inconsistent with the surrounding data distribution in feature space, indicating a likely labeling error. The approach avoids assumptions about the model or training process, focusing instead on identifying and correcting inaccuracies within the training dataset itself.
ALED employs dimensionality reduction techniques to improve the effectiveness of feature embeddings in identifying mislabeled data. Specifically, the method utilizes Fisher Linear Discriminant (FLD) to project high-dimensional feature vectors into a lower-dimensional space while maximizing class separability. FLD achieves this by finding the linear combination of features that best discriminates between classes, thereby enhancing the discriminatory power of the resulting feature representations. This process facilitates more accurate identification of outlier embeddings, which are indicative of potential mislabeled samples, as the enhanced separation makes these outliers more readily distinguishable within the feature space.
ALED identifies potential mislabeled samples by examining the distribution of feature embeddings within the feature space. The method operates on the principle that mislabeled data points frequently result in embeddings that are geometrically distant from the majority of their class, appearing as outliers. This is achieved by analyzing the spatial relationships between embeddings and identifying those that deviate significantly from established cluster patterns. Specifically, ALED assesses the proximity of each embedding to its assigned class centroid and considers the overall density of embeddings in its local neighborhood to determine the likelihood of a labeling error. Embeddings exhibiting low proximity and residing in sparse regions are flagged as potential mislabels, allowing for targeted dataset refinement.
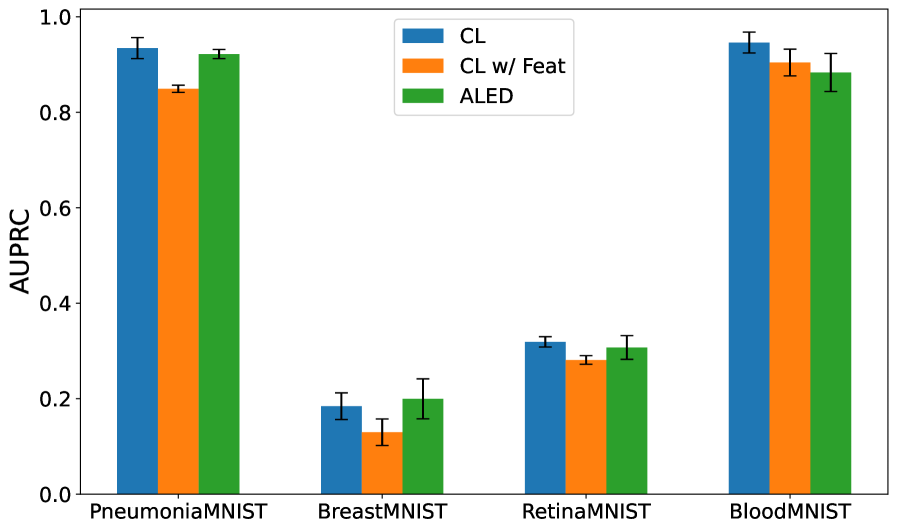
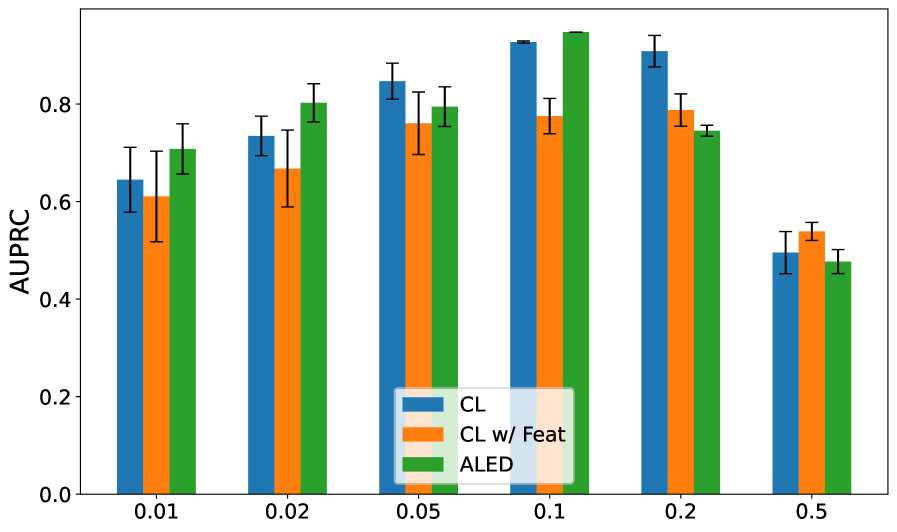
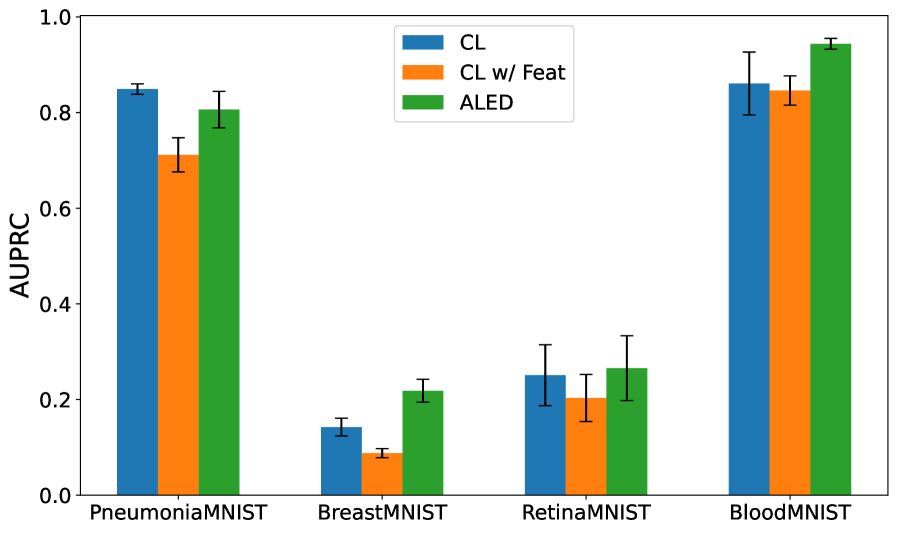
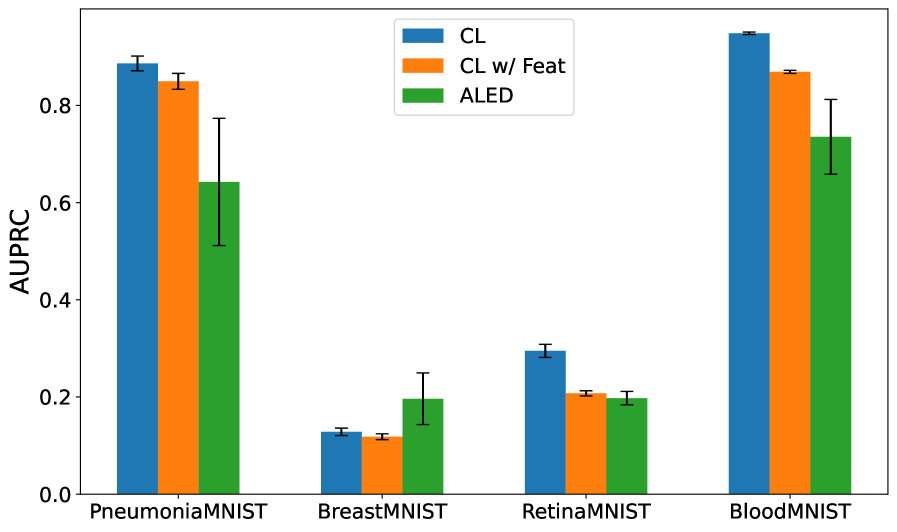
Adaptive Label Error Detection (ALED) utilizes a Gaussian Model to identify mislabeled samples by analyzing the distribution of feature embeddings in reduced dimensionality space. This approach allows for the quantification of embedding outliers, which are then flagged as potential labeling errors and removed from the training set. Experimental results demonstrate a 33.8% reduction in test error when employing this method. This represents a significant performance improvement, achieving approximately a 5x greater reduction in test error compared to feature-based Contrastive Learning (CL) techniques.
The Ripple Effect: Data Integrity and Model Reliability
Machine learning model performance isn’t solely dependent on complex architectures; the quality of the training data plays a crucial role. Techniques like ALED – a method focused on addressing label noise – directly enhance a model’s ability to generalize and perform reliably. By actively identifying and correcting inaccuracies within the dataset, ALED creates a more trustworthy foundation for learning. This proactive approach allows models to move beyond simply memorizing training examples and instead develop a deeper understanding of the underlying patterns, leading to improved performance on new, unseen data. The result is a system less prone to errors stemming from flawed input, and better equipped to handle the complexities of real-world applications.
The efficacy of any machine learning model is fundamentally linked to the quality of the data it learns from; a cleaner training dataset directly translates to enhanced learning and improved generalization. When models are exposed to mislabeled or inaccurate data, they struggle to discern true patterns, leading to suboptimal performance and unreliable predictions on new, unseen data. By systematically identifying and rectifying these inaccuracies, models can focus on learning the underlying relationships within the data, resulting in a more robust and accurate understanding of the problem space. This improved learning capacity not only boosts performance metrics but also fosters greater confidence in the model’s predictions, making it particularly valuable in applications where precision and reliability are non-negotiable.
The demand for unwavering accuracy extends beyond typical machine learning applications, becoming absolutely critical in high-stakes fields like medical image classification. Here, a misidentified anomaly in an X-ray or MRI could have severe consequences for patient care, potentially leading to delayed or incorrect treatment. Consequently, the robustness of these diagnostic tools hinges not simply on detecting patterns, but on confidently classifying them with minimal error. Techniques that address label noise, such as Automated Label Error Detection (ALED), are therefore invaluable, offering the potential to significantly reduce the risk of false positives or negatives, and ultimately improve patient outcomes by ensuring that medical professionals can rely on the insights generated by these advanced systems.
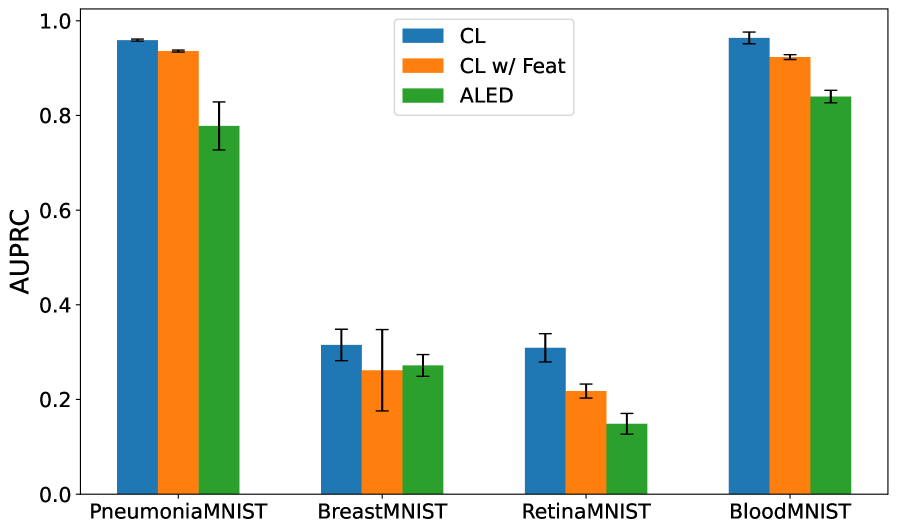
Rigorous evaluation reveals that the ALED methodology consistently surpasses comparative techniques, notably Contrastive Learning (CL) and CL enhanced with feature engineering, as measured by both F1 scores and Area Under the Precision-Recall Curve (AUPRC) across diverse datasets. These metrics demonstrate ALED’s enhanced capacity to not only identify, but also effectively rectify, instances of mislabeled data – a critical capability often overlooked in machine learning pipelines. This reliable correction of flawed data empowers models to generalize more effectively, leading to improved performance and unlocking their full potential in practical, real-world applications where accurate predictions are paramount and the cost of error is high.
The pursuit of robust systems, as highlighted in this work on Adaptive Label Error Detection, acknowledges the inevitable decay inherent in all datasets. Imperfections, like mislabeled samples, are not anomalies to be eradicated, but characteristics to be understood and mitigated. This research, by focusing on feature space geometry and Gaussian modeling, embodies a philosophy of graceful aging – adapting to data imperfections rather than striving for unattainable perfection. As Vinton Cerf aptly stated, “Any sufficiently advanced technology is indistinguishable from magic.” This applies here; the ‘magic’ isn’t eliminating label noise, but cleverly identifying and accommodating it to improve model resilience over time, reflecting a design prioritizing longevity and adaptability.
What Lies Ahead?
The pursuit of clean labels, as exemplified by Adaptive Label Error Detection, is less about achieving a static perfection and more about acknowledging the inevitable entropy of data. Every dataset, regardless of curation, is a decaying structure, susceptible to the distortions of time and the imperfections of measurement. Versioning, in this context, is a form of memory – a record of past states, but never a guarantee of future accuracy. The arrow of time always points toward refactoring, toward reassessment of what was once considered ground truth.
Future iterations will likely grapple with the geometry of uncertainty itself. Current approaches, while effective, often treat mislabeling as a discrete event. A more nuanced understanding might view it as a probabilistic phenomenon, a fuzzy boundary where the signal degrades. This necessitates exploring methods that quantify not just whether a label is wrong, but how wrong it is – a shift from binary classification to continuous estimation.
Ultimately, the field must confront the limitations of feature space geometry as a sole indicator of label correctness. The map is not the territory, and even the most detailed embedding can be misleading. The true challenge lies not in detecting errors, but in building systems resilient to them – systems that learn despite the noise, and evolve gracefully with the decay.
Original article: https://arxiv.org/pdf/2601.10084.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Unmasking falsehoods: A New Approach to AI Truthfulness
- TV Shows That Race-Bent Villains and Confused Everyone
- Smarter Reasoning, Less Compute: Teaching Models When to Stop
- Palantir and Tesla: A Tale of Two Stocks
- How to rank up with Tuvalkane – Soulframe
- 25 “Woke” Films That Used Black Trauma to Humanize White Leads
- Top 10 Coolest Things About Invincible (Mark Grayson)
2026-01-18 05:52