Author: Denis Avetisyan
New research moves past simply detecting errors in large language models to diagnose why they occur and automatically generate training data to improve factual accuracy.
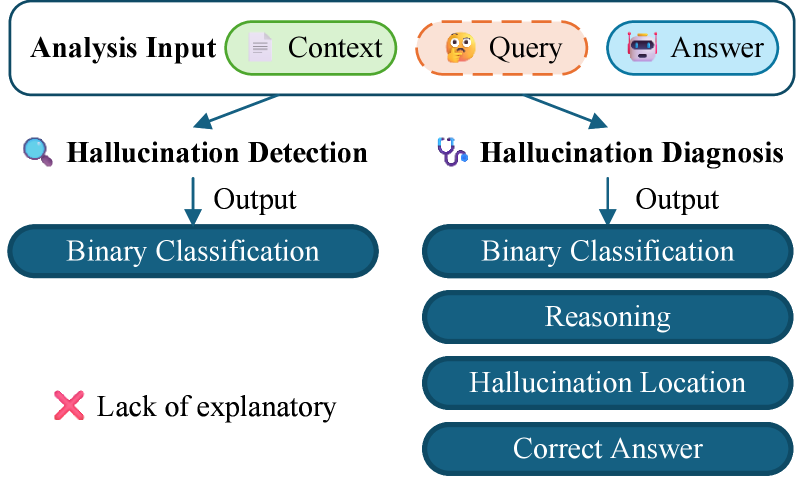
A novel ‘Hallucination Diagnosis’ pipeline, combined with reinforcement learning and data synthesis, enables a 4B parameter model to rival the performance of significantly larger models in assessing and mitigating factual inaccuracies.
Despite advances in large language models, the persistent generation of factually inconsistent content-hallucinations-remains a critical barrier to reliable deployment. This paper, ‘From Detection to Diagnosis: Advancing Hallucination Analysis with Automated Data Synthesis’, introduces a paradigm shift from simply detecting hallucinations to diagnosing their root causes through automated data synthesis and reinforcement learning. We demonstrate that a 4-billion-parameter model, trained on synthetically generated diagnostic data, can achieve competitive performance with significantly larger models on hallucination benchmarks. Could this diagnostic approach pave the way for more trustworthy and inherently faithful generative AI systems?
The Allure and Illusion of Language: Unveiling the Hallucination Problem
Large language models, despite their remarkable ability to generate human-quality text, frequently exhibit a phenomenon known as “hallucination,” where the model confidently presents information that is demonstrably false or unsupported by evidence. This isn’t a matter of simple error; the generated content often appears plausible and logically consistent, making it difficult to discern from truthful statements without external verification. The root of this issue lies in the probabilistic nature of these models – they predict the most likely sequence of words, not necessarily the most accurate one. While trained on massive datasets, these models can extrapolate, infer, or even fabricate details to complete a response, especially when faced with ambiguous prompts or limited information. Consequently, even the most sophisticated language model can, with convincing fluency, produce entirely fictitious narratives, misattribute facts, or confidently assert falsehoods as truth, creating a significant hurdle for applications demanding reliable and verifiable outputs.
The propensity of large language models to “hallucinate” – generating outputs that, while seemingly coherent, lack factual grounding – presents a substantial hurdle for real-world deployment in domains demanding accuracy. Applications such as medical diagnosis, legal research, and financial analysis cannot reliably function with information that may be fabricated, even if presented convincingly. Consequently, a growing body of research focuses on developing techniques to both detect these inaccuracies after they occur, through methods like fact verification and knowledge retrieval, and to mitigate them at the source, employing strategies such as reinforcement learning from human feedback and constrained decoding to steer model outputs towards verifiable truths. Addressing this challenge is not simply about improving performance metrics; it’s about building trust and ensuring these powerful tools are used responsibly and ethically where information integrity is paramount.
Faithfulness hallucination represents a particularly troubling facet of inaccuracies in large language models, extending beyond simple factual errors to direct contradictions of the provided source material. This isn’t merely a case of inventing details; the model actively conflicts with established information it was ostensibly designed to process and relay. Such discrepancies erode trust and render the output unreliable, especially in applications like summarization, question answering, or content creation where accuracy is paramount. The challenge lies in identifying these subtle but critical inconsistencies, as the generated text often maintains a plausible tone and grammatical structure, masking the underlying factual deviation. Addressing faithfulness hallucination requires sophisticated techniques capable of cross-referencing generated content with its origins, going beyond surface-level keyword matching to truly assess semantic alignment and ensure the model remains tethered to verifiable truth.
Constructing a Diagnostic Framework: Unraveling the Roots of Error
The Hallucination Diagnosis Task is a multi-faceted framework designed to address the problem of factual inaccuracies in large language model outputs. It moves beyond simple detection of hallucinations to incorporate four key components: detection, identifying instances of hallucination; localization, pinpointing the specific spans of text containing the inaccurate information; explainability, providing insights into why a hallucination occurred; and mitigation, developing strategies to reduce the frequency and severity of these errors. This holistic approach aims to provide a comprehensive understanding of hallucinations, facilitating the development of more reliable and trustworthy language models.
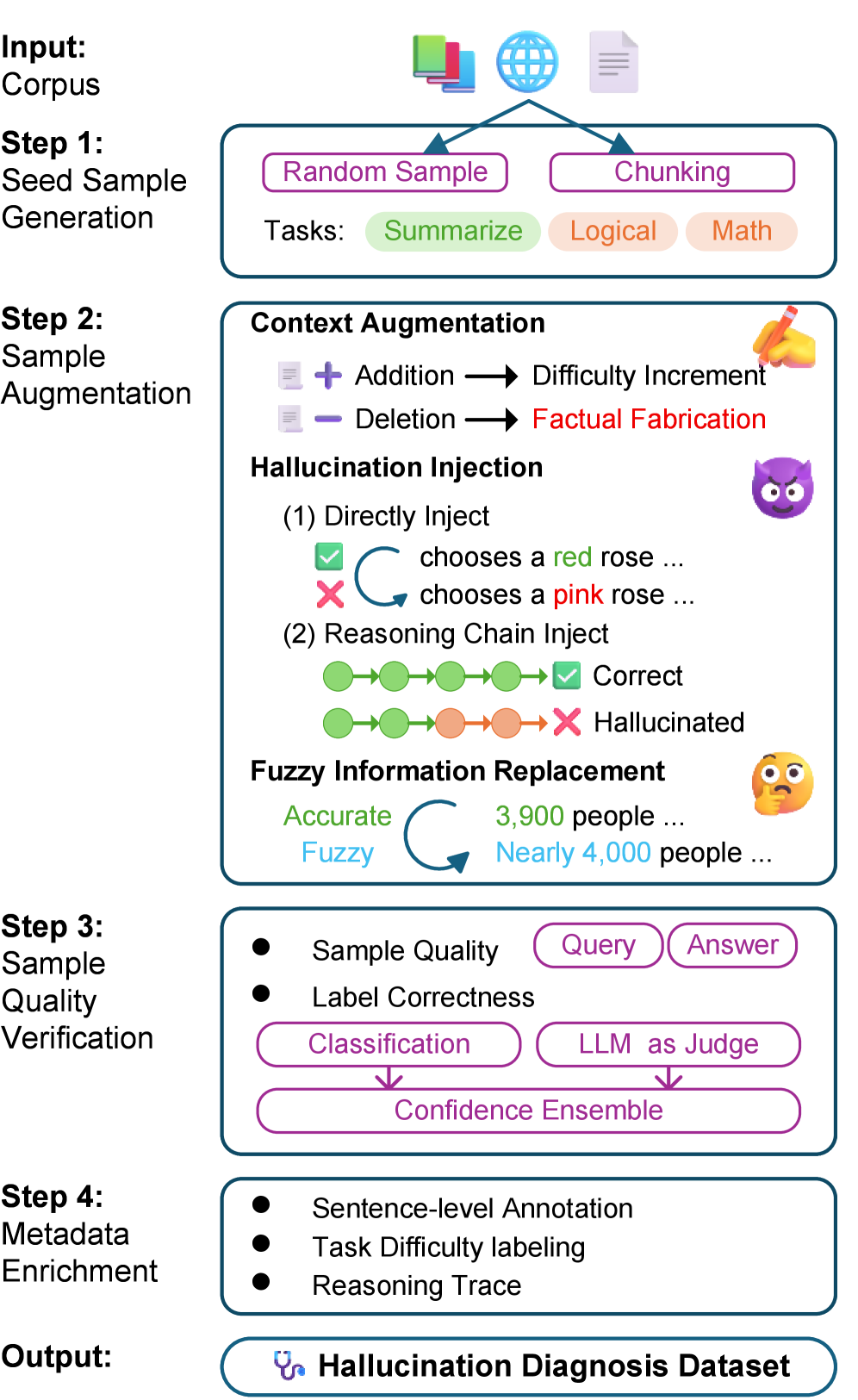
The Hallucination Diagnosis Generation (HDG) Pipeline is an automated system designed to create a large-scale dataset for evaluating and improving the reliability of large language models. Utilizing the entirety of the Wikipedia Corpus as source material, the pipeline programmatically generates question-answer pairs and accompanying rationales. This approach allows for the creation of a substantial and diverse dataset, crucial for training and benchmarking hallucination detection and mitigation techniques. The system’s automation ensures scalability and reproducibility in dataset creation, addressing a key limitation in manual data annotation efforts.
Chain-of-Thought (CoT) prompting is integrated into the Hallucination Diagnosis Generation (HDG) Pipeline to improve the quality and variety of synthetic training data. Specifically, the HDG Pipeline employs CoT prompting when generating question-answer pairs from Wikipedia articles; instead of directly requesting an answer, the Large Language Model (LLM) is prompted to first articulate its reasoning process step-by-step before providing a final answer. This multi-step approach encourages the LLM to generate more nuanced and logically structured responses, leading to a more diverse range of hallucination types within the synthetic dataset. The resulting training examples, enriched with explicit reasoning chains, are then used to train and evaluate hallucination detection models, improving their ability to identify and localize inaccuracies in LLM outputs.
HDM-4B-RL: A Scalable Solution for Diagnostic Precision
HDM-4B-RL is a 4-billion parameter model designed for the diagnosis of hallucinations in large language model outputs. Training utilized a dataset generated by the HDG Pipeline, and the model is based on the Qwen3-4B foundational model. This approach allows for a comparatively lightweight solution to hallucination detection, contrasting with models requiring significantly more parameters, while maintaining competitive performance as demonstrated in evaluation metrics. The use of Qwen3-4B as a base provides a pre-trained starting point, enhancing the model’s ability to generalize and identify instances of inaccurate or fabricated information.
HDM-4B-RL’s training regimen utilizes Group Relative Policy Optimization (GRPO), a reinforcement learning algorithm designed to improve sample efficiency and stability. GRPO operates by learning a policy that maximizes cumulative reward, but it differentiates itself through the use of a group of policies trained concurrently. This approach allows for more robust exploration of the policy space and reduces the risk of converging on suboptimal solutions. By aggregating information across these policies, GRPO facilitates faster learning and more reliable performance gains during the training process, ultimately leading to a model better equipped for hallucination detection tasks.
HDM-4B-RL, a 4 billion parameter model, achieves a 79.65 F1 Score in hallucination detection tasks. This performance surpasses that of GPT-4.1, which attained a score of 75.37 on the same evaluation dataset. While HDM-4B-RL’s F1 Score is slightly lower than the 81.70 achieved by the larger Qwen3-32B model, it demonstrates competitive performance despite its significantly smaller size, indicating efficient utilization of parameters for this specific task.
HDM-4B-RL achieved an accuracy of 84.54% when evaluated on the FinanceBench benchmark. This result represents a 2.4% performance increase over the previously established state-of-the-art model, Lynx. FinanceBench is a challenging evaluation dataset designed to assess performance on financial reasoning and knowledge-intensive tasks, making this accuracy score a significant indicator of HDM-4B-RL’s capabilities in this domain.
Evaluation of HDM-4B-RL, as detailed in Table 5, indicates performance on hallucination localization – measured by Hit Rate – and hallucination mitigation – assessed using AlignScore – is comparable to that of significantly larger models. Specifically, the model achieves competitive results on these metrics, demonstrating its ability to both identify the presence of hallucinations and to align generated text with factual sources despite its relatively small 4 billion parameter size. This suggests that HDM-4B-RL offers an efficient alternative to larger models for applications requiring robust hallucination detection and correction.
HDM-4B-RL demonstrates a significant efficiency advantage in processing speed compared to larger 32B parameter models. Specifically, HDM-4B-RL achieves a runtime of 1x, indicating real-time or near real-time performance, while a representative 32B parameter pipeline method requires 4.9 times longer to complete the same task. This performance difference highlights the model’s ability to deliver comparable results with substantially reduced computational cost and latency, making it a viable option for resource-constrained environments and applications requiring rapid response times.

Towards Reliable Reasoning: A Future Anchored in Verifiable Truth
The development of HDM-4B-RL marks a significant advancement in the pursuit of reliable language models through its unique diagnostic capabilities. This system doesn’t simply identify inaccuracies – known as hallucinations – in generated text; it pinpoints where these errors occur and, critically, offers explanations for why they arose. By dissecting the reasoning process that led to a hallucination, researchers gain valuable insight into the model’s internal logic – or lack thereof. This granular level of analysis moves beyond mere error detection, enabling targeted improvements to model architecture and training data. Ultimately, HDM-4B-RL paves the way for language models that are not only capable of generating human-quality text, but also of justifying their responses and acknowledging the limits of their knowledge, fostering greater trust and accountability.
The pursuit of reliable reasoning in language models benefits significantly from dissecting how inaccuracies arise, not simply detecting their presence. Integrating distinct reasoning modes – such as causal, temporal, or spatial understanding – into a diagnostic framework allows for a granular analysis of errors. This approach moves beyond surface-level identification of hallucinations to pinpoint the specific cognitive process where the model falters. By categorizing inaccuracies based on the type of reasoning failure, researchers can then develop targeted interventions – refining training data, adjusting model architecture, or implementing specific reasoning constraints – to address the root cause and improve overall performance. Ultimately, understanding the ‘why’ behind an error is crucial for building language models that don’t just generate text, but genuinely reason with it.
The foundation of HDM-4B-RL’s reliability rests significantly on its deliberate use of Wikipedia (20231101.en) as a core knowledge source. This choice isn’t merely about accessing a large dataset; it’s a strategic move to ground the model in a collaboratively curated and consistently updated repository of established facts. By prioritizing information verifiable within Wikipedia’s extensive articles, the system minimizes reliance on potentially spurious or unconfirmed data often found across the broader internet. This grounding process doesn’t simply provide answers, but also offers a traceable path to verification, bolstering the model’s capacity to explain why a particular statement is considered accurate-or conversely, to flag statements lacking sufficient support within established knowledge. The result is a system less prone to generating unsubstantiated claims and more capable of discerning truth from fabrication, ultimately fostering greater trust in its outputs.
To assess the factual consistency of language model outputs, researchers are increasingly employing Natural Language Inference (NLI). This technique examines the logical relationship between a source document and the text generated by the model, determining if the generated content is entailed by, contradicts, or is neutral to the source material. By framing the verification process as an NLI task, inconsistencies can be systematically flagged; for example, if a model claims something that directly contradicts the source text, the NLI system will identify this as a contradiction. This allows for a quantifiable measure of factual accuracy and facilitates the development of methods to mitigate the generation of unsupported or incorrect statements, ultimately enhancing the reliability of language models and fostering greater trust in their outputs.
The pursuit of ‘Hallucination Diagnosis’ within large language models represents a necessary acknowledgement of systemic decay. Every system, even one predicated on the illusion of infinite knowledge, is subject to the pressures of time and internal inconsistency. This work, by focusing on not merely detecting hallucinations but pinpointing their origin and attempting mitigation through data synthesis and reinforcement learning, mirrors a refactoring process – a dialogue with the past errors to build a more robust future. As Bertrand Russell observed, “The good life is one inspired by love and guided by knowledge.” The article’s approach, striving for faithfulness and factuality, embodies this pursuit, acknowledging that even the most advanced systems require constant refinement and a rigorous engagement with the truth to avoid succumbing to the inevitable entropy of information.
What’s Next?
The pursuit of ‘hallucination diagnosis’ in large language models is, predictably, a race against the inevitable. This work demonstrates a capacity for localized error assessment and mitigation – a commendable effort to shore up defenses against the decay inherent in complex systems. However, framing the problem as one of ‘faithfulness’ implies a standard of truth these models were never designed to meet. The synthesis of data, while effective in the short term, is merely a postponement of the eventual divergence between representation and reality.
The success achieved with a comparatively small, four-billion parameter model is noteworthy, suggesting diminishing returns in sheer scale. It begs the question: are we approaching a point where architectural innovation and data efficiency offer more substantial gains than simply adding layers and parameters? Or is this a temporary reprieve, a moment of stability before the system’s inherent instability manifests in new and unforeseen ways?
Future work will undoubtedly focus on automating the data synthesis pipeline and refining the reinforcement learning strategies. Yet, the underlying tension remains: these models are not becoming ‘more truthful’; they are becoming more adept at appearing truthful. Time will reveal whether this distinction proves meaningful, or if even the most sophisticated diagnostic tools are ultimately destined to measure the rate of entropy, not prevent it.
Original article: https://arxiv.org/pdf/2601.09734.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Gold Rate Forecast
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Palantir and Tesla: A Tale of Two Stocks
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- How to rank up with Tuvalkane – Soulframe
- TV Shows That Race-Bent Villains and Confused Everyone
2026-01-16 15:29