Author: Denis Avetisyan
Researchers have developed a novel graph foundation model that excels at identifying anomalous groups within complex network data, even with limited examples.
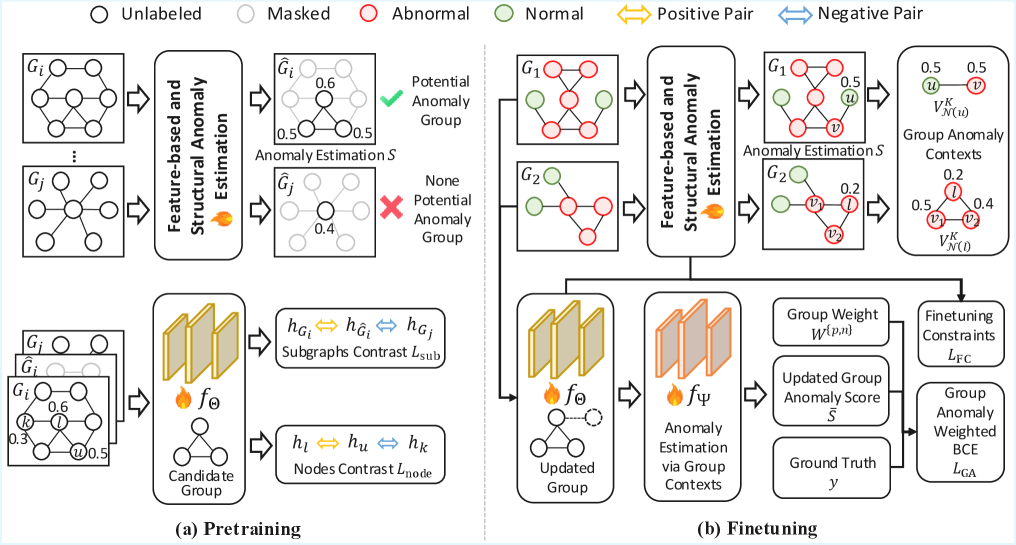
GFM4GA leverages dual-level contrastive learning and anomaly context to improve few-shot group anomaly detection in graph data.
Detecting anomalous groups within complex network data presents a unique challenge, as subtle deviations can be obscured by normal-appearing individuals. To address this, we introduce GFM4GA: Graph Foundation Model for Group Anomaly Detection, a novel approach leveraging the power of graph foundation models for few-shot learning. GFM4GA employs dual-level contrastive learning and incorporates contextual information from labeled anomaly neighbors to effectively capture group-level inconsistencies and adapt to unseen anomalies. Will this paradigm shift enable more robust and scalable anomaly detection in diverse real-world network applications?
The Ephemeral Nature of Normality
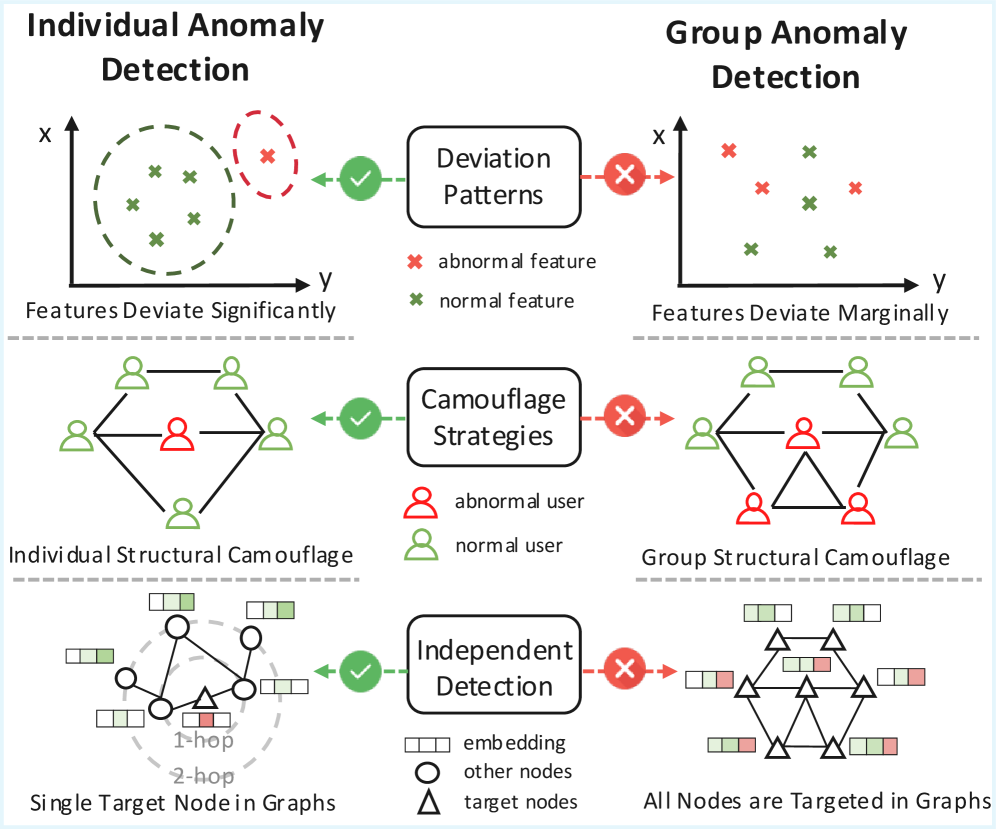
Conventional graph anomaly detection typically prioritizes the identification of singular, unusual nodes within a network, a methodology that inadvertently overlooks the substantial risks posed by anomalous groups of nodes acting in concert. While pinpointing isolated anomalies is valuable, coordinated malicious activity – such as fraudulent transaction rings or botnet command-and-control structures – manifests as subtle, collective deviations from normal network behavior. These groups, often exhibiting few anomalous individual characteristics, can inflict disproportionately large damage because their collective impact is far greater than the sum of their parts. Consequently, a shift in focus is essential; effective anomaly detection must move beyond individual node analysis and embrace techniques capable of discerning these cohesive, yet dangerous, groupings within complex network topologies.
The increasing sophistication of malicious activities and fraudulent schemes necessitates a fundamental shift in anomaly detection strategies, moving beyond the analysis of isolated entities to the identification of coordinated anomalous groups. In fields like fraud detection, a single compromised account may appear innocuous, but when viewed in connection with a network of similarly compromised accounts exhibiting coordinated behavior, a significant fraudulent operation is revealed. Similarly, in network security, a distributed denial-of-service (DDoS) attack isn’t launched by a single computer; it arises from the coordinated activity of a compromised group of machines. Recognizing these collective threats demands analytical tools capable of identifying subtle patterns of interaction and shared characteristics within groups, rather than solely focusing on individual node anomalies, ultimately enhancing proactive threat mitigation and systemic risk management.
Current anomaly detection techniques frequently falter when applied to groups, largely because of the inherent complexities within these structures and a critical lack of readily available, labeled examples of anomalous groupings. Unlike identifying a single unusual node, discerning an anomalous group requires analyzing inter-node relationships and recognizing patterns that deviate from typical collective behavior-a computationally intensive task. Moreover, the rarity of such groupings creates a significant data scarcity problem; supervised learning approaches, which rely on extensive labeled datasets, are often ineffective. This presents a considerable challenge, as the absence of clear examples makes it difficult to train algorithms to accurately distinguish between legitimate, complex groups and those representing genuine threats or failures, ultimately hindering the reliable detection of these often-critical anomalies.
Addressing the difficulty of identifying anomalous groups requires a departure from traditional anomaly detection techniques and the development of novel methodologies. Current approaches often falter when faced with the nuanced characteristics of these groups, particularly their subtle patterns and the limited availability of labeled examples for training. Researchers are now exploring techniques like graph embedding and representation learning to capture the collective behavior of nodes, enabling the identification of groups exhibiting atypical connectivity or activity. Furthermore, advancements in few-shot learning and transfer learning are being leveraged to generalize from sparse data, allowing systems to detect previously unseen anomalous groups with improved accuracy. These innovative strategies aim to move beyond individual node analysis and focus on the emergent properties of interconnected entities, ultimately bolstering defenses against complex, coordinated threats.
Foundations for Collective Deviations
GFM4GA utilizes graph foundation models as a core component, capitalizing on representations learned through pretraining on extensive graph datasets. These models are trained to capture inherent structural patterns and node characteristics within graphs, resulting in embeddings that encode rich relational information. This pretraining process enables GFM4GA to develop a generalized understanding of graph topology and node behavior, independent of specific downstream tasks. Consequently, the learned representations serve as a robust foundation for anomaly detection, facilitating the identification of deviations from established norms even in the absence of labeled anomalous data. The scale of the pretraining corpora is critical; larger datasets allow the model to capture a more comprehensive range of graph characteristics and improve the quality of the learned representations.
The anomaly estimation module within GFM4GA utilizes Principal Component Analysis (PCA) to establish a baseline of normal node behavior based on feature representations. PCA identifies the principal components – directions of maximum variance – within the feature space of normal nodes. Anomaly scores are then calculated by projecting node features onto these principal components and quantifying the reconstruction error; larger errors indicate greater deviation from the established norm. Specifically, the l_2 norm of the residual vector, representing the difference between the original feature vector and its reconstructed counterpart, serves as the anomaly score. This approach allows for the quantification of anomalies based on the magnitude of deviation in the learned feature space, effectively flagging nodes exhibiting atypical behavior.
GFM4GA utilizes both node-level and subgraph-level contrastive learning to improve anomaly discrimination within groups. Node-level contrastive learning focuses on distinguishing individual nodes based on their feature representations, maximizing the similarity of embeddings for nodes considered normal and minimizing similarity for anomalous nodes. Subgraphs, defined as local neighborhoods around nodes, are also embedded and compared using contrastive learning. This subgraph-level approach captures relational information and contextual dependencies, enabling the model to identify anomalies based on deviations in the structure and feature characteristics of the surrounding graph. Combining both levels of contrastive learning allows GFM4GA to capture both intrinsic node properties and contextual relationships, leading to more robust and accurate group anomaly detection.
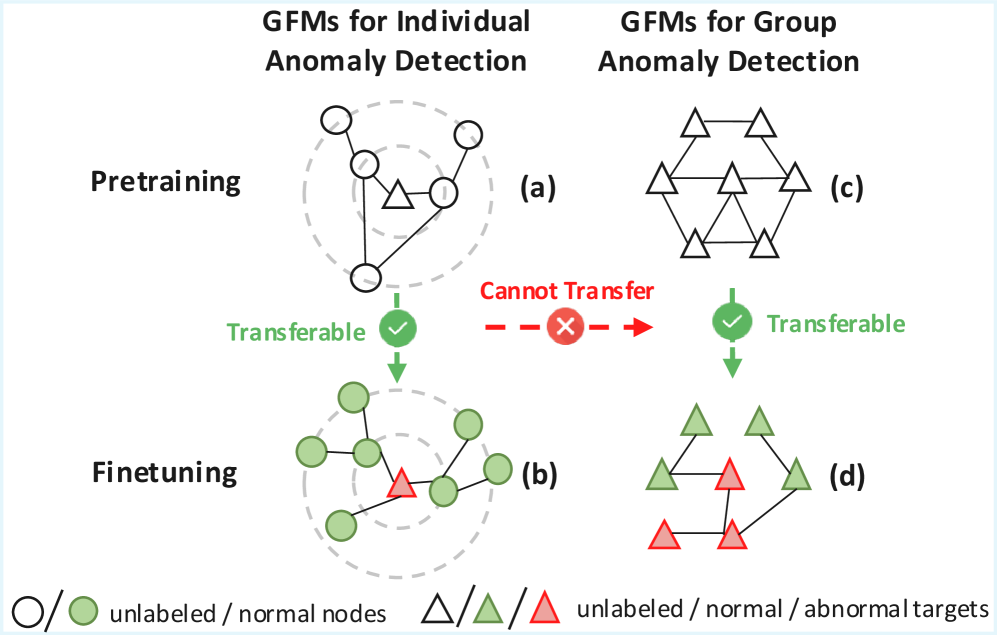
GFM4GA’s pretraining on extensive graph corpora and subsequent fine-tuning via contrastive learning facilitates generalization to anomalies not encountered during training. This capability stems from the learned graph representations capturing inherent structural patterns, allowing the model to identify deviations indicative of anomalous behavior even in novel contexts. Furthermore, the tailored learning strategy enables effective few-shot anomaly detection, where the model can accurately identify anomalies with limited labeled examples, as the pretrained representations provide a strong prior for distinguishing between normal and anomalous node or subgraph characteristics. The combination of pretraining and contrastive learning improves performance in scenarios with limited data or evolving anomaly patterns.
Validation Across Dynamic Systems
GFM4GA was subjected to evaluation using a diverse range of graph datasets representing multiple real-world scenarios. These included large-scale social networks sourced from Weixin, Weibo, and Facebook, providing data on user interactions and relationships. Co-review networks derived from Amazon customer data were also utilized, focusing on item-user relationships. Finally, transaction networks from T-Finance, detailing financial transactions between entities, were incorporated to assess performance in a different domain. This comprehensive dataset selection ensures the robustness of the evaluation and demonstrates the applicability of GFM4GA across various graph-structured data types.
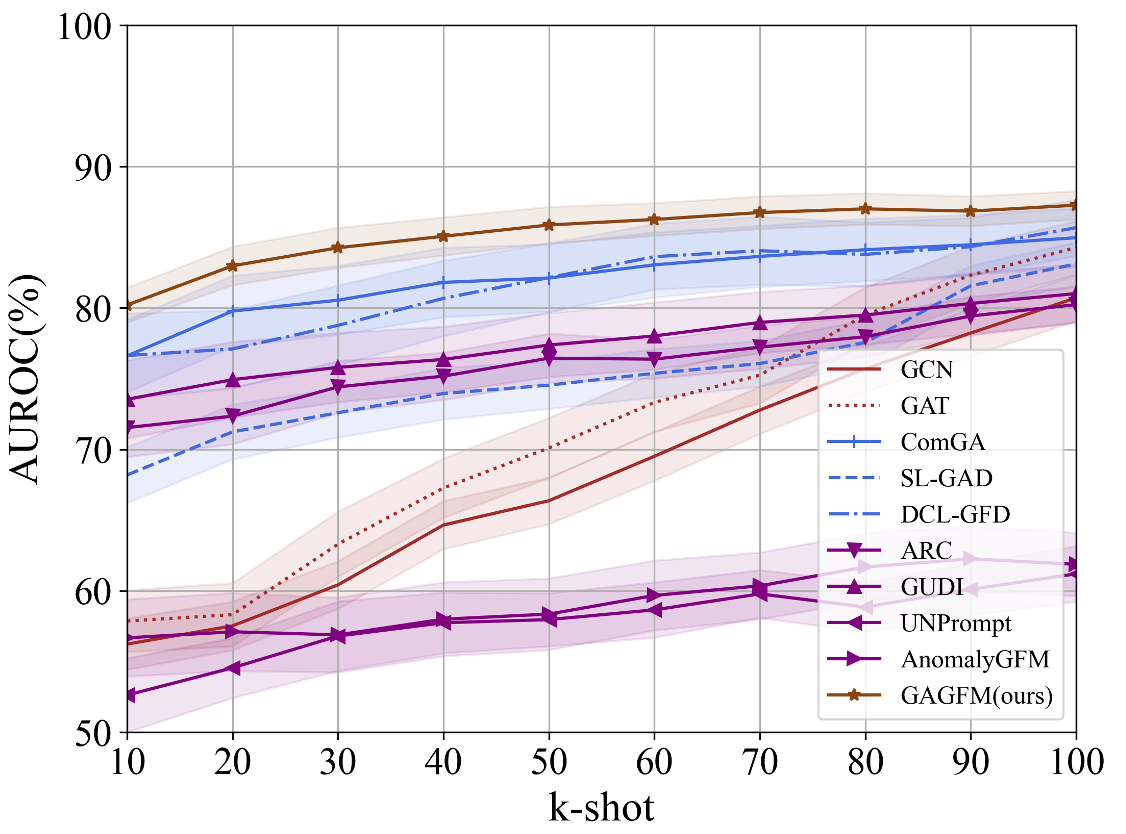
Evaluation of the GFM4GA model utilized the Area Under the Receiver Operating Characteristic curve (AUROC) and the Area Under the Precision-Recall Curve (AUPRC) as primary performance metrics. AUROC, ranging from 0 to 1, quantifies the model’s ability to distinguish between anomalous and normal nodes, with higher values indicating better performance. AUPRC, similarly ranging from 0 to 1, assesses the trade-off between precision and recall, particularly relevant in imbalanced datasets common in anomaly detection. These metrics provide a standardized and quantitative basis for comparing GFM4GA against existing state-of-the-art methods across diverse graph datasets.
Quantitative evaluation demonstrates that GFM4GA consistently exceeds the performance of current state-of-the-art anomaly detection methods. Across all tested graph datasets – encompassing social networks, co-review networks, and transaction networks – GFM4GA achieved an average improvement of 2.85% in Area Under the Receiver Operating Characteristic curve (AUROC). Furthermore, the method exhibited a 2.55% average improvement in Area Under the Precision-Recall Curve (AUPRC) when compared to existing techniques. These metrics were calculated using standard evaluation protocols and provide statistically significant evidence of GFM4GA’s enhanced performance capabilities.
The consistent performance gains of GFM4GA – averaging 2.85% improvement in Area Under the Receiver Operating Characteristic curve (AUROC) and 2.55% in Area Under the Precision-Recall Curve (AUPRC) across Weixin, Weibo, Facebook, Amazon, and T-Finance datasets – provide empirical validation of the proposed methodology. This demonstrated effectiveness across diverse graph structures and real-world data sources indicates potential applicability in various anomaly detection scenarios, including fraud detection in financial networks, identifying malicious actors in social networks, and detecting unusual activity within co-review systems. The observed improvements over state-of-the-art methods suggest GFM4GA offers a robust and generalizable solution for graph-based anomaly detection tasks.
Towards Anticipatory Systemic Resilience
GFM4GA introduces a foundation model architecture designed to redefine anomaly detection across diverse graph-structured data. Unlike traditional methods requiring extensive retraining for each new application or data source, this approach leverages pre-trained knowledge to swiftly adapt to previously unseen graph domains and tasks. The model’s core design facilitates transfer learning, allowing it to generalize effectively with only minimal fine-tuning-significantly reducing the computational cost and time associated with deployment. This capability is achieved through a carefully constructed network that captures fundamental graph properties, enabling it to recognize anomalous patterns even when presented with novel data distributions. Consequently, GFM4GA represents a substantial step towards building more versatile and efficient anomaly detection systems, capable of handling the dynamic and evolving nature of real-world graph data.
GFM4GA incorporates a contrastive learning component designed to refine its ability to identify nuanced anomalies within groups of data points. This technique functions by teaching the model to recognize similarities and differences, effectively creating a learned embedding space where anomalous groups are distinctly separated from normal patterns. By focusing on relational characteristics rather than individual data point features, the model becomes significantly more sensitive to subtle deviations indicative of group anomalies-those that might otherwise be missed by traditional methods. The result is a marked improvement in detection accuracy, coupled with a substantial reduction in false positives, as the system learns to differentiate genuine threats from benign variations within the data landscape.
The efficacy of anomaly detection systems hinges on their ability to maintain performance as underlying data patterns shift – a common occurrence in dynamic real-world scenarios. Traditional methods often struggle with these evolving distributions, necessitating frequent retraining or manual adjustments. However, a system’s adaptability and robustness become paramount when dealing with continuously changing data streams, such as those found in financial markets, network security, or industrial processes. A model capable of generalizing across distribution shifts minimizes the need for constant intervention, ensuring reliable and consistent anomaly detection even as the characteristics of ‘normal’ behavior change over time. This resilience not only reduces operational costs but also enhances the system’s capacity to identify previously unseen anomalies, critical for proactive threat mitigation and safeguarding complex systems.
The development of GFM4GA signifies a shift towards anomaly detection systems that anticipate and neutralize threats before they escalate. Rather than simply identifying deviations after they occur, this foundation model fosters proactive security for vital infrastructure, including power grids, communication networks, and financial systems. By learning robust representations of normal system behavior, GFM4GA can predict potential vulnerabilities and flag unusual patterns indicative of malicious activity or developing failures. This capability extends beyond simple intrusion detection; it enables preventative maintenance, optimized resource allocation, and ultimately, a more resilient and secure operational environment capable of adapting to increasingly sophisticated and evolving threats. The model’s adaptability ensures continued effectiveness even as system dynamics and attack vectors change, offering a long-term solution for safeguarding critical assets.
The pursuit of robust anomaly detection, as detailed in this study of GFM4GA, inevitably encounters the realities of temporal decay. Any initial improvement in identifying anomalous groups, achieved through dual-level contrastive learning or contextual information, ages faster than expected. As John McCarthy observed, “The best way to predict the future is to invent it.” This sentiment applies directly to the field; GFM4GA doesn’t simply predict anomalies, but actively constructs a foundational model capable of adapting to the shifting landscape of graph data. The model’s few-shot learning capability acknowledges that even the most meticulously crafted system will eventually require reinvention to maintain efficacy against evolving anomalous patterns.
The Long Echo
The introduction of GFM4GA represents a narrowing of focus, a deliberate refinement of anomaly detection within the graph structure. While the model addresses the immediate challenges of few-shot learning and contextual awareness, it simultaneously inscribes a new set of constraints. The very act of defining ‘anomaly’ through contrastive learning creates a shadow self, a persistent baseline against which deviations are measured. This baseline, however meticulously constructed, will inevitably degrade as the underlying data evolves, demanding continual recalibration and incurring a form of technical debt – the system’s memory of past normalities.
Future work will likely explore methods for dynamically updating these baselines, or perhaps shifting the paradigm entirely. The pursuit of ‘generalizable’ anomaly detection feels, at best, a temporary reprieve. Each simplification-each abstraction designed to improve efficiency-carries a future cost, a subtle erosion of fidelity. The true challenge isn’t identifying what is anomalous now, but anticipating the forms of anomaly that haven’t yet manifested.
Ultimately, the field will confront a fundamental limit: the inherent unpredictability of complex systems. The search for a perfect anomaly detector is, paradoxically, a quest for a static world, a world that simply does not exist. The value, then, lies not in eliminating false positives, but in gracefully accommodating them, recognizing that error is not a failure, but an inherent property of the medium itself.
Original article: https://arxiv.org/pdf/2601.10193.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Gold Rate Forecast
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Palantir and Tesla: A Tale of Two Stocks
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- How to rank up with Tuvalkane – Soulframe
- TV Shows That Race-Bent Villains and Confused Everyone
2026-01-16 11:47