Author: Denis Avetisyan
Researchers have developed a novel reconstruction-based method to reliably detect deepfakes and other manipulated images, even when facing unseen generation techniques.
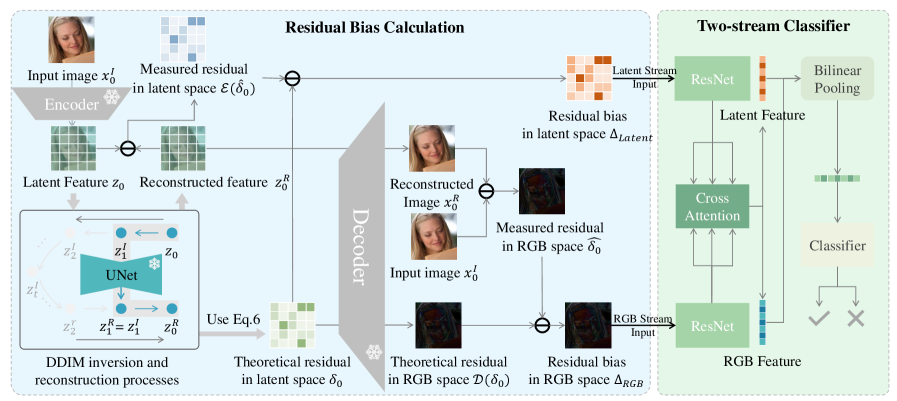
R$^2$BD leverages a paradigm-aware reconstruction model and residual bias analysis for improved generalization and efficiency in deepfake detection.
Despite recent advances, reliably detecting AI-generated images remains challenging due to limitations in generalization and computational efficiency. This paper introduces R$^2$BD: A Reconstruction-Based Method for Generalizable and Efficient Detection of Fake Images, a novel framework that addresses these issues through a unified reconstruction model and a streamlined residual bias calculation. R$^2$BD achieves superior detection accuracy with over 22× speedup compared to existing reconstruction-based methods, while also demonstrating strong cross-dataset performance across diverse generative paradigms. Could this approach pave the way for more robust and scalable deepfake detection systems in real-world applications?
The Evolving Threat of Synthetic Deception
The proliferation of deepfakes – synthetic media meticulously crafted using deep learning algorithms – poses an escalating threat to societal security due to their rapidly improving realism. These convincingly fabricated videos, audio recordings, and images blur the lines between authentic and artificial content, making it increasingly difficult for individuals to discern truth from deception. The potential for misuse is substantial, ranging from the spread of disinformation and political manipulation to damaging reputations and inciting social unrest. As the technology advances, deepfakes are becoming more accessible and easier to create, widening the scope of potential harm and demanding increasingly sophisticated countermeasures to mitigate the risks they present to trust, security, and public discourse.
Deepfake creation initially hinged on Generative Adversarial Networks (GANs), systems where two neural networks battled to generate and discriminate realistic imagery. However, a significant leap in convincing forgery now stems from Diffusion Models. Unlike GANs which directly generate images, diffusion models operate by progressively adding noise to an image until it becomes pure static, then learning to reverse this process – effectively denoising random data into a coherent and remarkably realistic image. This fundamentally different approach bypasses many of the telltale artifacts that previously flagged GAN-generated deepfakes, resulting in forgeries exhibiting greater fidelity and posing a substantially heightened challenge for detection systems. The shift to diffusion models represents not merely an incremental improvement, but a qualitative change in the landscape of synthetic media, creating a new generation of deepfakes that are increasingly difficult to discern from authentic content.
Initially, the fight against deepfakes centered on identifying telltale inconsistencies – subtle artifacts – left behind by Generative Adversarial Networks (GANs) during image and video creation. These methods exploited the limitations of early deepfake technology, searching for flaws in color consistency, blinking patterns, or facial warping. However, the emergence of Diffusion Models represents a paradigm shift in synthetic media generation. These models produce remarkably realistic forgeries by gradually refining images from random noise, a process that inherently avoids many of the characteristic artifacts previously exploited by detection algorithms. Consequently, techniques designed to flag GAN-generated content are proving increasingly unreliable against diffusion-based deepfakes, demanding the development of entirely new detection strategies focused on more subtle discrepancies or the underlying statistical properties of the generated content itself.
Reconstructing Truth: A Novel Detection Paradigm
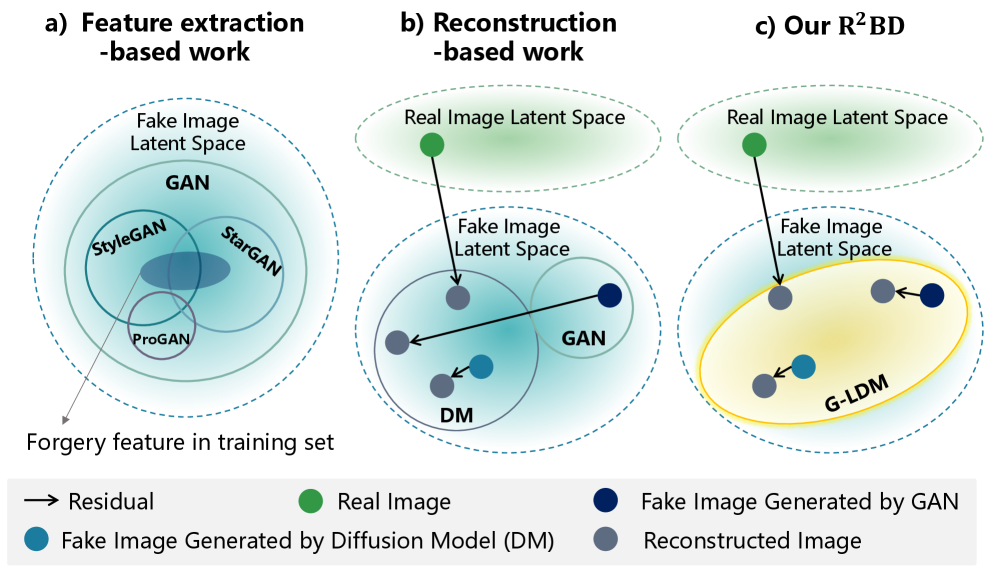
Reconstruction-based detection methods operate on the principle that any image, when decompressed or reconstructed from a latent representation, will not be perfectly restored; forged images, having undergone prior manipulation or generation, exhibit more pronounced reconstruction errors than authentic images. This approach contrasts with methods that search for specific artifacts of generative models. By leveraging the discrepancies between the original image and its reconstruction – often measured using pixel-wise differences or perceptual losses – these techniques aim to identify inconsistencies indicative of manipulation. The magnitude and distribution of these reconstruction imperfections provide a signal for detecting deepfakes, even when the forgeries are created using novel or unknown generative processes.
Traditional deepfake detection methods often target specific artifacts produced by particular generative models, such as GAN-based inconsistencies or frequency domain anomalies. This reliance creates a vulnerability as deepfake technology advances and new generative approaches emerge that circumvent these known weaknesses. Reconstruction-based detection, conversely, operates on the principle that any image, real or synthetic, will exhibit imperfections when reconstructed – for example, discrepancies between the original and reconstructed pixel values or inconsistencies in restored high-frequency details. By focusing on these fundamental reconstruction errors rather than model-specific fingerprints, this approach provides greater resilience to evolving deepfake techniques and a potentially longer lifespan of effectiveness as generative models continue to improve.
Current reconstruction-based deepfake detection methods, such as DIRE (Deep Image Reconstruction Examination) and ZeroFake, leverage the discrepancies between a forged image and its reconstructed counterpart to identify manipulation. DIRE utilizes an autoencoder to reconstruct input images and identifies inconsistencies in the residual layer, highlighting areas altered by deepfake techniques. ZeroFake, conversely, employs Stable Diffusion to reconstruct the facial region of a suspected deepfake; discrepancies between the original and reconstructed face, particularly in fine details and color consistency, serve as indicators of forgery. Both approaches avoid reliance on specific artifact patterns produced by particular generative models, improving generalizability and robustness against evolving deepfake technologies.
G-LDM: Harmonizing Strengths for Enhanced Fidelity
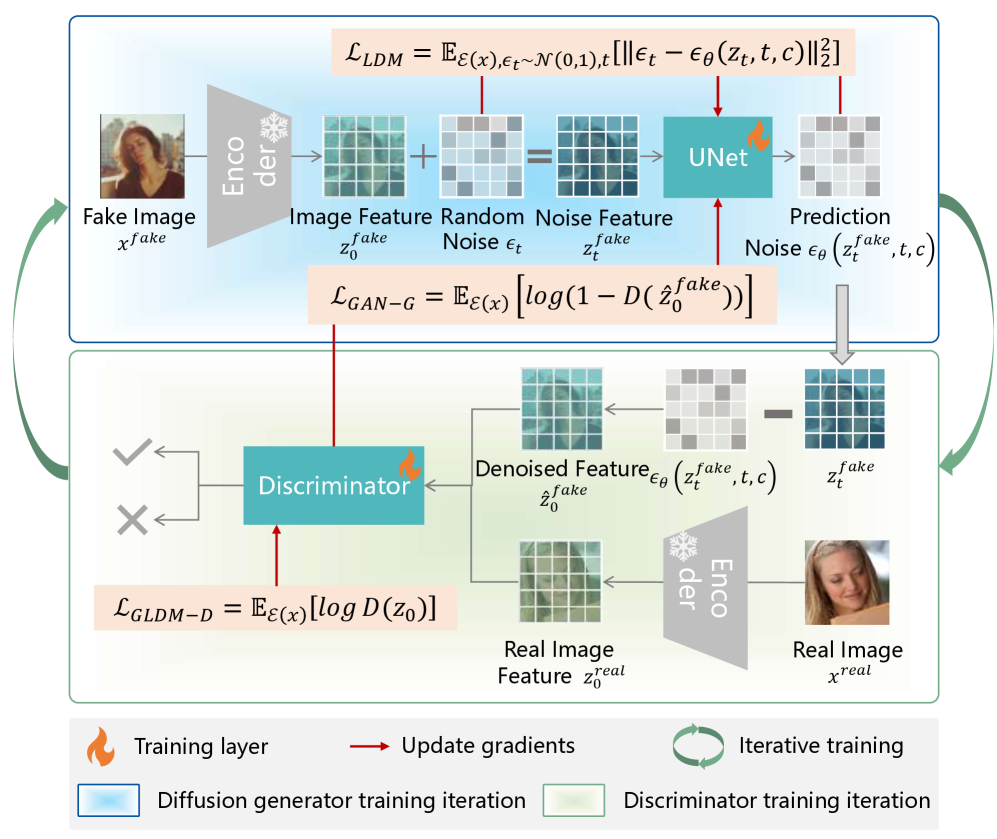
G-LDM (Generative Latent Diffusion Model) introduces a new approach to image reconstruction by integrating the advantages of both Generative Adversarial Networks (GANs) and Diffusion Models. Traditional GANs excel in generating content quickly but often struggle with mode collapse and generating high-fidelity details. Conversely, Diffusion Models produce high-quality samples but are computationally expensive and slower. G-LDM addresses these limitations by leveraging a latent space diffusion process guided by a GAN-based discriminator. This hybrid architecture enables rapid reconstruction comparable to GANs while retaining the superior image quality and diversity characteristic of Diffusion Models, resulting in a more efficient and robust reconstruction framework.
G-LDM addresses the limitations of traditional deepfake detection methods by integrating Generative Adversarial Networks (GANs) and Diffusion Models. GANs excel in rapid image generation and reconstruction, enabling quick processing speeds crucial for real-time applications. However, GAN-reconstructed images often lack high fidelity and can introduce noticeable artifacts. Conversely, Diffusion Models produce reconstructions with superior quality and detail, but are computationally expensive and slower. G-LDM combines these approaches; it utilizes a GAN-based reconstruction process for speed, while simultaneously employing a Diffusion Model to refine and enhance the reconstructed output, resulting in a framework that offers both efficiency and high-fidelity analysis for deepfake detection.
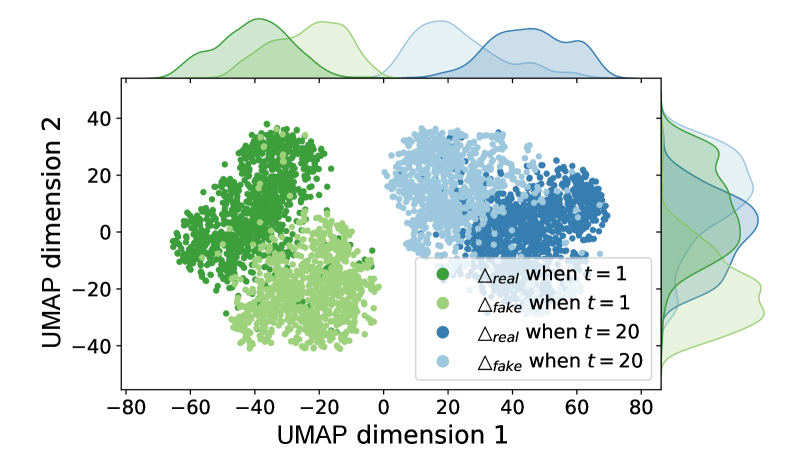
G-LDM’s efficacy stems from its identification and utilization of ‘Residual Bias’. This bias is quantified through the analysis of reconstruction residuals – the difference between an original image and its reconstructed counterpart generated by the G-LDM model. Real images, when reconstructed, exhibit a distinct residual pattern compared to forged or manipulated images. This consistent divergence in residual patterns provides a reliable signal for differentiating authentic content from deepfakes. The model analyzes these residuals to generate a ‘Residual Bias’ score, which correlates directly with the probability of an image being a forgery, leading to improvements in both detection accuracy and computational efficiency by focusing analysis on this key signal.
Towards Robustness and Generalization in Detection
G-LDM distinguishes itself through a remarkable capacity for Cross-Paradigm Generalization, a feat increasingly vital in the rapidly evolving landscape of generative AI. Unlike many detection methods tailored to specific generative models, G-LDM consistently exhibits strong performance across a diverse array of techniques – from Generative Adversarial Networks (GANs) to Variational Autoencoders (VAEs) and diffusion models. This adaptability stems from its focus on fundamental inconsistencies inherent in generated content, rather than relying on model-specific artifacts. Consequently, G-LDM demonstrates a robustness to emerging generative methods, offering a solution that remains effective even as the underlying technology advances, and promising a more sustainable approach to deepfake detection.
Historically, detecting image manipulations relied heavily on extracting specific features – textures, edges, and patterns – to discern forgeries. However, the increasing sophistication of generative models necessitates a shift in strategy, as these features become easily replicated or altered. While feature extraction remains a valuable component, its efficacy diminishes over time, demanding constant recalibration and updates to detection algorithms. Recent advancements demonstrate that integrating reconstruction-based techniques – methods that attempt to restore an image to its original state – significantly enhances the robustness of these systems. By analyzing the discrepancies between the original and reconstructed images, detectors can identify subtle inconsistencies indicative of tampering, offering a more resilient approach to forgery detection that complements and extends the capabilities of traditional feature analysis.
Evaluations reveal that the proposed G-LDM achieves a remarkable balance between speed and accuracy in detecting manipulated images. Processing images at a rate of 0.706 seconds per image, it significantly outperforms current reconstruction-based methods – exceeding the speed of approaches like DIRE and ZeroFake by a factor of over 22x. This efficiency is coupled with strong generalization capabilities, as demonstrated by a cross-dataset accuracy of 78.35% and an Area Under the Receiver Operating Characteristic curve (AUROC) of 92.30%. These results collectively establish G-LDM as a state-of-the-art solution, offering both practical speed and robust performance across diverse image datasets.

The pursuit of elegance in deepfake detection, as demonstrated by R$^2$BD, echoes a fundamental principle of good design: simplicity born from profound understanding. This reconstruction-based method doesn’t merely identify anomalies; it seeks to understand the generative process itself, mirroring the way a skilled artisan understands the material they shape. As Geoffrey Hinton once stated, “The key to AI is not to create machines that think like humans, but to understand how humans think.” R$^2$BD embodies this sentiment, moving beyond superficial feature extraction to a paradigm-aware reconstruction, effectively addressing the challenge of cross-paradigm generalization. The reduction in computational cost, achieved through optimized residual bias calculation, isn’t simply an efficiency gain; it’s an aesthetic refinement, streamlining the process to its essential form.
What’s Next?
The pursuit of detecting synthetic media, as demonstrated by R$^2$BD, increasingly resembles a game of asymptotic approach. Each refinement – a novel reconstruction technique, a more nuanced residual bias calculation – yields incremental gains, but the generative models themselves relentlessly evolve. The current emphasis on paradigm-aware reconstruction is a necessary, yet temporary, fortification. The true challenge isn’t merely identifying how an image was fabricated, but understanding the inherent limitations of any detection method against an adversary with unbounded computational resources.
A critical, and often overlooked, aspect is the very definition of “real.” As generative models blur the lines between captured and created, the concept of an authentic ground truth becomes increasingly fragile. Future work should investigate methods less reliant on identifying specific artifacts, and more focused on assessing the plausibility of an image within a broader contextual framework. The elegance of a solution, after all, isn’t merely in its accuracy, but in its ability to remain relevant as the landscape shifts.
Ultimately, the durability of any detection system hinges on its simplicity and consistency. A complex detector, riddled with heuristics, will inevitably succumb to adversarial examples. A system built on fundamental principles – a clear understanding of signal processing and statistical inference – possesses an inherent resilience. Aesthetics in code and interface is a sign of deep understanding; beauty and consistency make a system durable and comprehensible.
Original article: https://arxiv.org/pdf/2601.08867.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Gold Rate Forecast
- Unmasking falsehoods: A New Approach to AI Truthfulness
- Palantir and Tesla: A Tale of Two Stocks
- How to rank up with Tuvalkane – Soulframe
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- TV Shows That Race-Bent Villains and Confused Everyone
2026-01-16 05:03