Author: Denis Avetisyan
Researchers have developed an AI agent that attempts to model human privacy reasoning, predicting how individuals will react to different privacy-related scenarios.
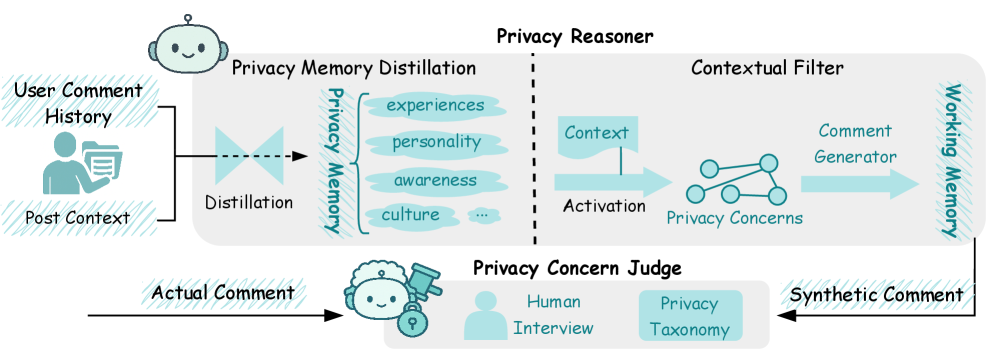
This paper introduces PrivacyReasoner, an AI agent leveraging personalized cognitive models and contextual integrity to improve the accuracy of privacy prediction.
Predicting individual responses to privacy breaches remains a challenge due to the nuanced and personalized nature of privacy concerns. This paper introduces PrivacyReasoner: Can LLM Emulate a Human-like Privacy Mind?, an AI agent designed to simulate human privacy reasoning by constructing user-specific cognitive models informed by past behavior and contextual cues. Experiments demonstrate that this approach significantly improves the prediction of individual privacy responses and reveals transferable reasoning patterns across diverse domains. Could such agents ultimately offer a more proactive and nuanced understanding of user privacy, fostering more responsible AI development and deployment?
Deconstructing the Illusion of Privacy
Traditional methods of assessing user privacy frequently employ generalized categorizations, often termed ‘Privacy Personas,’ which attempt to classify individuals into broad groups based on assumed attitudes toward data sharing. However, these approaches demonstrably fall short of capturing the subtle nuances of individual sensitivities. By treating privacy as a monolithic trait, they overlook the fact that concerns are rarely consistent across all contexts or data types; a user might readily share location data for navigation but fiercely protect personal health information. This reliance on broad strokes creates a distorted understanding of actual privacy preferences, leading to inaccurate predictions of how individuals will respond to specific privacy-relevant events and ultimately hindering the development of truly user-centric privacy protections. The inherent limitations of these generalized profiles necessitate a move toward more granular and dynamic models capable of reflecting the complex and context-dependent nature of individual privacy concerns.
Current methods of gauging user privacy often fall short due to a reliance on broad categorizations that fail to capture the subtleties of individual response. These generalized profiles, while seemingly efficient, lack the necessary granularity to accurately predict how a user will react to specific privacy-relevant events, such as a change in data collection practices or an unexpected data breach notification. Consequently, assessments of ‘User Privacy Concerns’ become inaccurate, potentially leading to miscalculated risks and ineffective privacy protections. A user categorized as ‘privacy-conscious’ might readily accept certain data sharing for personalized services, while vehemently objecting to others, a nuance lost in these overly simplified models. This inability to predict behavior in specific contexts undermines the effectiveness of privacy-enhancing technologies and policies, highlighting the need for more dynamic and individualized approaches.
The prevailing understanding of user privacy necessitates a shift towards computational models that recognize its fluid and situational nature. Current approaches often treat privacy as a fixed trait, overlooking the fact that individuals adjust their sensitivities based on the specific context of data collection and usage. Researchers are now focusing on developing systems capable of dynamically assessing privacy preferences – factoring in elements like the type of data requested, the requesting entity, and the potential benefits or risks associated with sharing. These models move beyond static profiles, instead predicting how a user might react to a particular privacy-relevant event based on a nuanced understanding of the surrounding circumstances, ultimately offering a more accurate and responsive approach to safeguarding personal information.
The Architecture of Contextual Integrity
PrivacyReasoner is grounded in the theory of Contextual Integrity, which posits that privacy is not simply about controlling information, but about maintaining appropriate flows of information within defined contexts. This framework moves beyond broad definitions of privacy violations, instead focusing on whether information transfer adheres to contextual norms – specifically, the sender, receiver, attributes, and transmission principles relevant to a given situation. Violations occur when these norms are breached, even if no sensitive data is technically exposed. The theory acknowledges that information flows considered acceptable in one context-such as a doctor-patient relationship-may be unacceptable in another, highlighting the importance of situational awareness in determining privacy expectations and potential breaches.
Privacy Memory functions as a structured knowledge base representing a user’s established privacy preferences. This is constructed by analyzing historical textual data – such as prior communication or documented preferences – to identify consistent patterns in how a user manages information disclosure. The resulting disposition profiles are formalized according to the APCO (Actors, Personal Attributes, Contexts, and Outcomes) Framework, which categorizes privacy considerations based on these four elements. This allows the agent to move beyond simple rules and represent nuanced, context-specific privacy expectations derived from a user’s past behavior.
Contextual Filtering within the PrivacyReasoner agent operates on principles derived from Working Memory Theory, specifically focusing on limited capacity and selective attention. This component assesses the current event – defined by the agent’s perception of the immediate situation – and retrieves relevant privacy orientations from the agent’s Privacy Memory. The selection process prioritizes dispositions deemed most applicable based on contextual cues, effectively narrowing the scope of privacy considerations. This filtering mechanism avoids overwhelming the reasoning process with irrelevant preferences and enables the agent to formulate responses tailored to the specific informational flow and social norms of the current context. The capacity limitations inherent in working memory dictate that only a subset of potentially applicable privacy orientations can be actively considered, necessitating a prioritization scheme based on contextual relevance.
Simulating the Ghost in the Machine
Synthetic Comment Generation within PrivacyReasoner involves the programmatic creation of textual responses designed to mimic human reactions to specific privacy-related events. This technique enables the simulation of online discussions and allows for the systematic analysis of potential user sentiment and behavior without requiring actual user data. By generating these synthetic comments, researchers can investigate a wide range of responses to various privacy scenarios, assess the impact of different privacy policies, and evaluate the effectiveness of privacy-enhancing technologies in a controlled environment. The generated data serves as a proxy for real-world user feedback, facilitating iterative development and refinement of privacy-focused systems and policies.
The fidelity of synthetically generated comments is assessed through ‘LLM-as-a-Judge’, a methodology employing a large language model to quantitatively evaluate alignment with declared user privacy preferences. This process involves presenting the LLM with both the generated comment and the originating user’s stated preferences, then scoring the comment based on its consistency with those preferences. The LLM effectively acts as an evaluator, assigning a relevance score reflecting the degree to which the comment demonstrates respect for or acknowledgement of the user’s privacy stance, allowing for automated and scalable assessment of synthetic comment quality.
The evaluation of PrivacyReasoner’s synthetic comment generation is performed using data sourced from Hacker News, a popular online forum known for its technical discussions and active user base. This platform provides a readily available corpus of comments addressing a diverse range of topics, allowing for the construction of realistic conversational contexts. By simulating discussions on Hacker News, we establish a robust testing environment that reflects the complexities of real-world online interactions and enables a quantifiable assessment of the agent’s ability to generate plausible and contextually relevant user responses to privacy-related events. The use of this external dataset helps to ensure the generalizability of the evaluation beyond synthetic scenarios.
Beyond Prediction: Decoding Intent
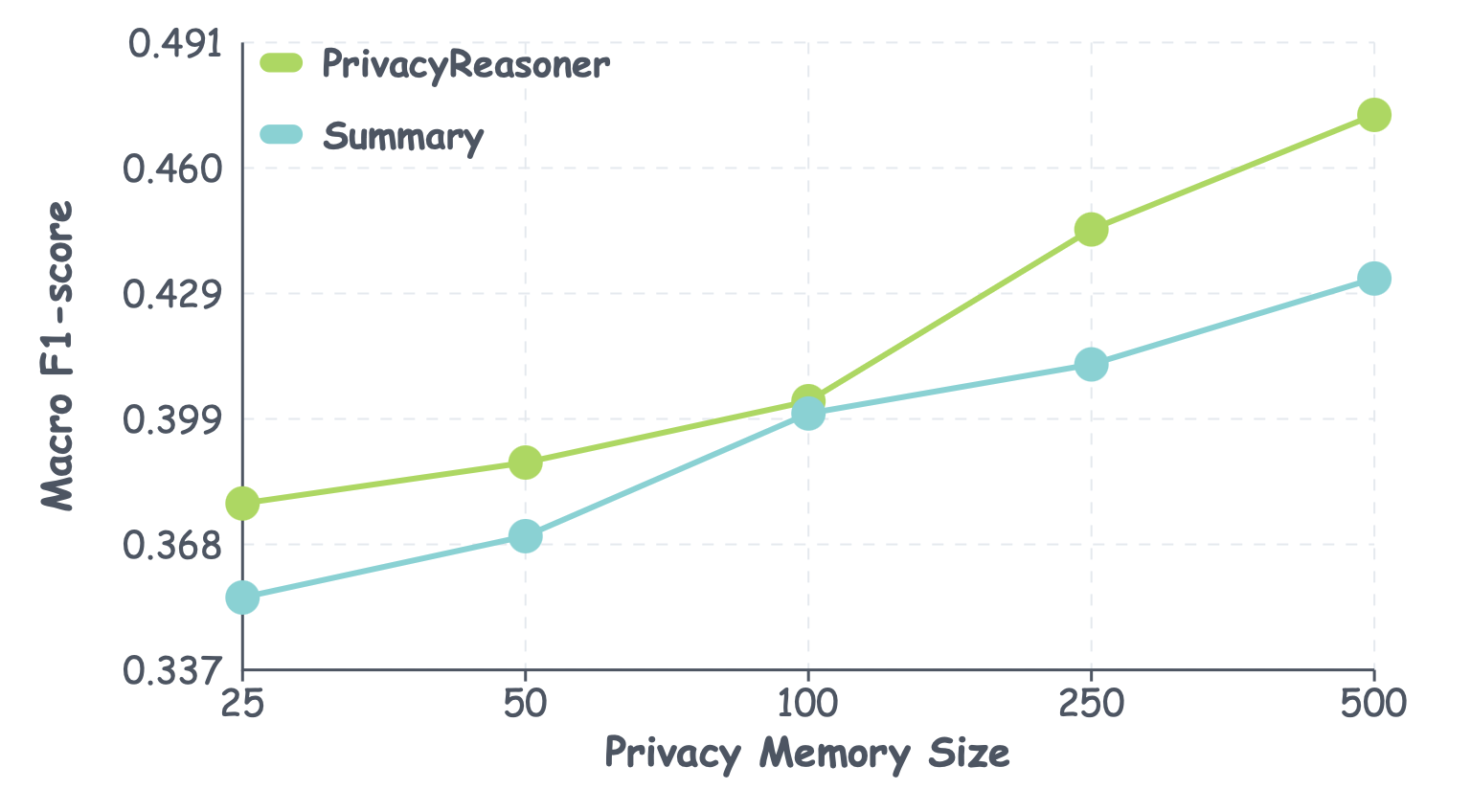
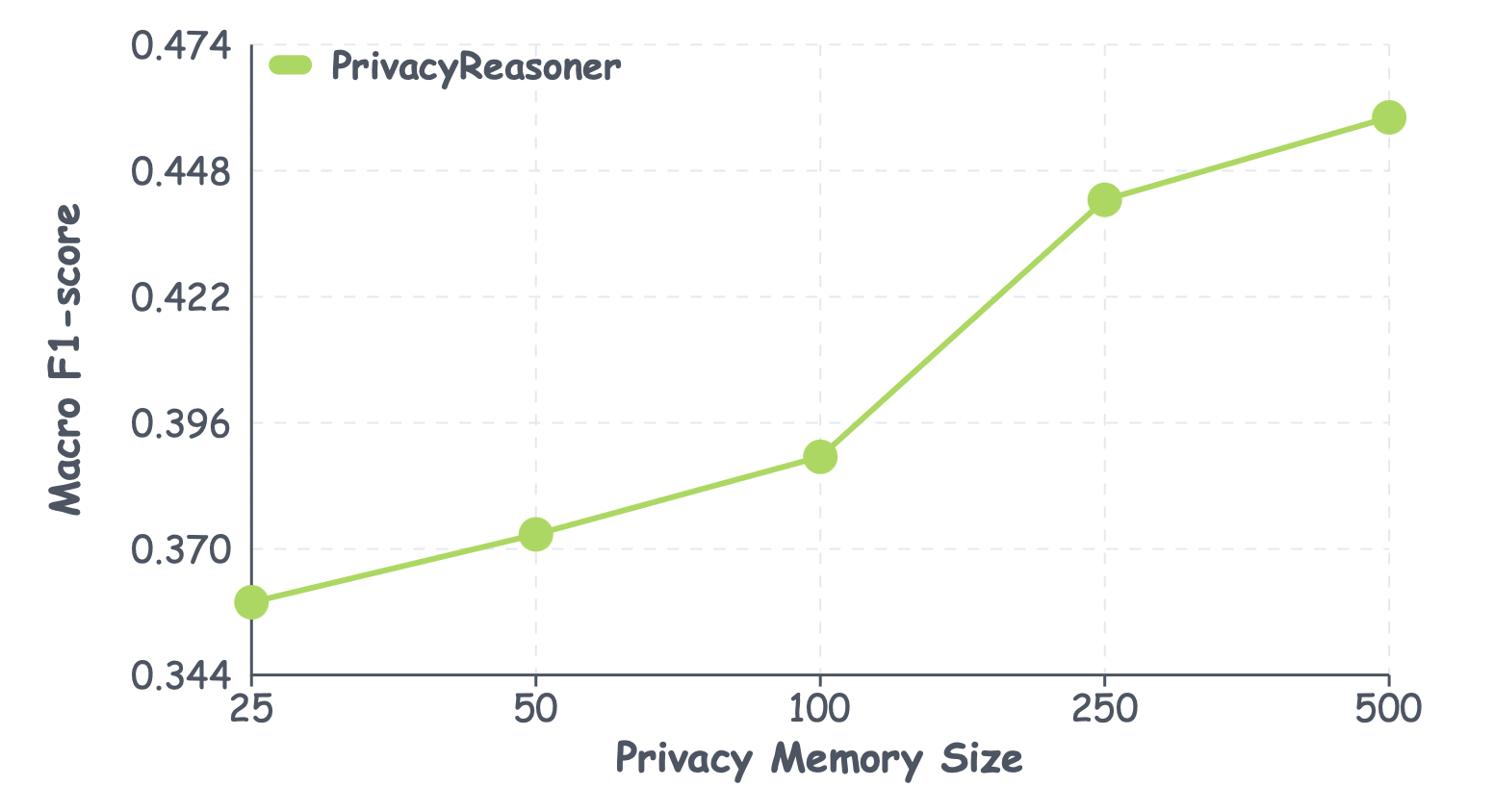
PrivacyReasoner demonstrably outperforms Retrieval-Augmented Generation (RAG) in the critical task of predicting nuanced privacy concerns. While RAG systems often rely on retrieving pre-existing information to formulate responses, PrivacyReasoner utilizes a more sophisticated approach to reason about potential privacy implications. This allows it to accurately identify subtle, context-dependent privacy issues that a simple retrieval-based system would likely miss. Comparative analyses reveal that PrivacyReasoner doesn’t merely identify whether a privacy concern exists, but rather, it pinpoints the specific nature of that concern with greater precision. This capability is crucial for applications requiring a granular understanding of privacy risks, offering a significant advancement over standard baseline models and paving the way for more proactive and effective privacy protection strategies.
To rigorously assess its capabilities, the PrivacyReasoner agent was subjected to validation through analysis of three distinct, real-world case studies. These included the contentious ‘CSAM Scanning’ proposal, which sparked debate regarding child safety versus privacy rights; the complex landscape of ‘IoT Cybersecurity Regulation’ and its implications for data collection from connected devices; and the ‘Triplebyte Public Profile’ controversy, centering on data privacy concerns related to a tech recruiting platform. By applying the agent to these established scenarios – each representing unique privacy challenges – researchers demonstrated its ability to analyze nuanced arguments and predict likely privacy responses with a high degree of accuracy, solidifying its practical utility beyond controlled experimental settings.
Rigorous evaluation reveals a substantial level of concordance between the LLM-based PrivacyConcernJudge and human expert assessments, as evidenced by a Macro F1-score of 0.812. This metric signifies the system’s robust ability to accurately identify and categorize privacy concerns-a performance level that consistently surpasses that of conventional baseline models. The high F1-score suggests the agent doesn’t simply recall information, but demonstrates a nuanced understanding of privacy implications, effectively mirroring human judgment in complex scenarios. Such strong agreement validates the system’s potential for reliable, automated privacy analysis and provides a foundation for its application in diverse, real-world contexts.
The pursuit within PrivacyReasoner mirrors a fundamental principle: to truly understand a system, one must probe its boundaries. This research doesn’t simply accept pre-defined privacy norms; it actively models how individuals apply those norms in context, building cognitive models and dynamically activating privacy orientations. As Tim Bern-Lee stated, “The Web is more a social creation than a technical one.” This sentiment deeply resonates with the work; PrivacyReasoner isn’t about enforcing a universal definition of privacy, but about simulating the nuanced, socially-constructed reasoning processes that underpin it. The agent’s ability to predict responses stems from this reverse-engineering of individual privacy frameworks – an exploit of comprehension, if you will – revealing the underlying logic of personal boundaries.
What Breaks Down Next?
The construction of PrivacyReasoner, while demonstrating a capacity to model privacy, inevitably highlights the brittleness of such models. What happens when the simulated cognitive framework encounters a scenario genuinely novel – one exceeding the bounds of its training, or revealing a fundamental inconsistency in the assumed ‘privacy orientations’? The system currently predicts; a more revealing test lies in deliberately provoking its failure. Introduce paradoxes. Present situations where contextual integrity is not merely violated, but fundamentally uninterpretable by the agent’s internal logic.
Current success relies on pre-defined privacy frameworks. But privacy isn’t a static set of rules; it’s a perpetually renegotiated social contract. Future work shouldn’t merely refine the agent’s predictive accuracy, but explore its capacity for adaptive reasoning – to construct, and even challenge, the very foundations of its privacy model. Can the agent identify flaws in the APCO framework itself? Can it recognize – and respond to – emergent privacy norms?
Ultimately, this line of inquiry isn’t about building a perfect privacy simulator. It’s about reverse-engineering the human capacity for privacy judgement. And to truly understand that capacity, one must discover – and then systematically dismantle – the assumptions upon which it rests. The most valuable insights will emerge not from confirming the model’s predictions, but from charting the precise nature of its failures.
Original article: https://arxiv.org/pdf/2601.09152.pdf
Contact the author: https://www.linkedin.com/in/avetisyan/
See also:
- Spotting the Loops in Autonomous Systems
- Seeing Through the Lies: A New Approach to Detecting Image Forgeries
- Staying Ahead of the Fakes: A New Approach to Detecting AI-Generated Images
- Julia Roberts, 58, Turns Heads With Sexy Plunging Dress at the Golden Globes
- Palantir and Tesla: A Tale of Two Stocks
- Gold Rate Forecast
- TV Shows That Race-Bent Villains and Confused Everyone
- The Glitch in the Machine: Spotting AI-Generated Images Beyond the Obvious
- How to rank up with Tuvalkane – Soulframe
- The 25 Marvel Projects That Race-Bent Characters and Lost Black Fans
2026-01-15 22:21